目录
一:机器学习概述
二:机器学习算法
三:机器学习模型
四:机器学习过程
五:机器学习模型验证
六:sklearn模块
一:机器学习概述
程序化处理和机器学习处理;
主观思维和客观思维;
下面举一个例子:我们现在帮小明决定明天到底要不要去看球赛
考虑因素: 天气、价格、朋友、球星
1 程序化:
if ...
else if ...
else if ...
else if ...
2 那么机器学习呢?
现在提供这样一种情境
天气:下雨
门票价格:100
同伴情况:没人一起
球星:有他喜欢的球星
那么可以做出这样一种分析:小明肯定会去,因为只要他喜欢的球星来了,无论怎么样他都会去的
由上述,机器学习示例,有了简单的概念
经验 + 思考 = 结果
经验也称为数据(样本)分为特征和标签:
特征:指的是在某些特定的外在条件或者内在条件下的一个反应,比如上述的天气、价格、是否有喜欢的球星等 (考虑因素)
标签:指的是在特征发生后,等到的一个结果,比如去看球赛和不去看球赛
经验/数据,如下示例 特征(天气等考虑因素) + 标签(结果)
| 天气 | 价格 | 朋友 | 球星 | 结果 |
| 晴天 | 150 | 有 | 有 | 去 |
| 阴天 | 200 | 没有 | 没有 | 不去 |
| 晴天 | 500 | 有 | 有 | 不去 |
| 多云 | 180 | 有 | 没有 | 去 |
| 多云 | 130 | 有 | 有 | 去 |
此时,若是再给出一组数据,来决定是否去看球赛,根据这样的经验的不断累积,就类似是机器学习的一整个过程
二:机器学习算法
线性回归
Logistic回归
决策树
朴素贝叶斯
K近邻算法
支持向量机(SVM)
...
对于机器学习算法,举个例子
比如,一个母亲在教孩子识字的过程 (算法),那么最终会识字的孩子(模型)
三:机器学习模型
机器学习模型 = 数据 + 算法
数据的特征决定了机器学习的上限 (收集到的数据量),而算法只是无限逼近于这个上限 (不断训练模型,调优算法)
模型训练过程
机器学习算法被描述为学习一个目标函数f,该函数将输入变量X最好地映射到输出变量Y:Y=f(X) X:模型数据 Y:结果
最常见地机器学习算法是学习映射Y=f(x)来预测新X的Y;这叫做预测建模或预测分析,我们的目标是尽可能做出最准确的预测
模型训练过程 + 模型预测过程
训练 图示如下

每一个特征x,分别有各自的w(权重) ,算法是每一个特征与其对应权重的结合,然后求和,预测结果
预测 图示 如下

输入对应特征值,模型以及存在(W权重 值已知),模型在训练成功后(预期值已知 如上图3就是该模型临界点)
四:机器学习过程
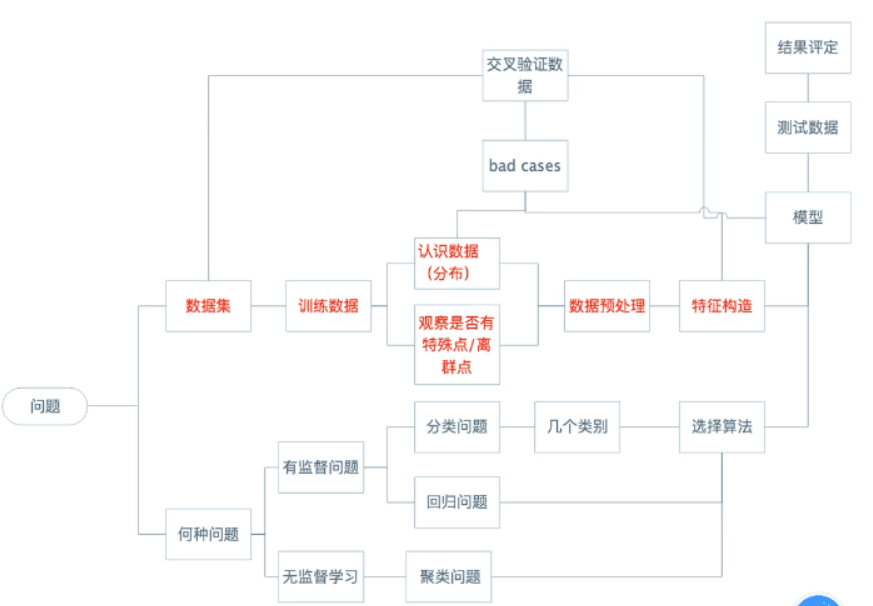
首先:问题的产生
需要准备数据集,数据集需要提纯优化,接下来训练数据,需要认识数据的分布以及观察是否有特殊点/离散点,之后进行数据预处理(数据清洗),经过这样一系列操作才比较完整,特征构造
算法的选择:首先考虑是有监督问题还是无监督问题
无监督学习(少,结果需要自己去整合分析,无监督模型会分类,把有相似特征的归为一类,准确率也不是很高),目前比如模仿人脑神经网络的,世界上做这类研究的也寥寥无几,不仅耗费大量成本时间,而且不一定能取得结果;因此,绝大多数做的都是有监督学习
有特征、有标签 -- 有监督学习
有特征、无标签 -- 无监督学习
分类问题 :分类统计
回归问题 :预测走向
五:机器学习模型验证
拟合(Fitting):就是说这个曲线能不能很好的描述某些样本
过拟合(Overfitting):就是太过贴近于训练数据的特征了,在训练集上表现非常优秀,近乎完美的预测/区分了所有的数据,但是在新的测试集上却表现平平,不具泛化性,拿到新样本后没有办法去准确的判断
欠拟合(UnderFitting):测试样本的特性没有学到,或者是模型过于简单无法拟合或区分样本
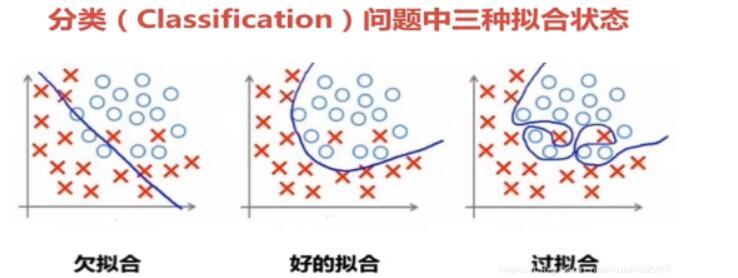
分类,如上图,好的拟合 如中间图所示
欠拟合就相当于摆烂,随意分类,过拟合就相当于超级认真,精确分类

回归,如上图,好的拟合 如中间图所示
欠拟合就相当于摆烂,随意回归曲线,过拟合就相当于超级认真,精确回归曲线
六:sklearn模块
Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习算法进行的封装和实现,它自带一些训练数据集供用户使用
Sklearn datasets
Sklearn提供一些标准数据,我们不必再从其他网站寻找数据进行训练
鸢尾花数据集:load_iris()
手写数字数据集:load_digits()
波斯顿房价数据集:load_boson()
....
安装:
pip3 install sklearn -i https://pypi.mirrors.ustc.edu.cn/simple/安装sklearn后,即可使用鸢尾花数据集,
如下博主使用鸢尾花数据集,提取特征数据、标签数据并对数据集划分

1 :sklearn - datasets - data下包含有训练数据集供用户使用
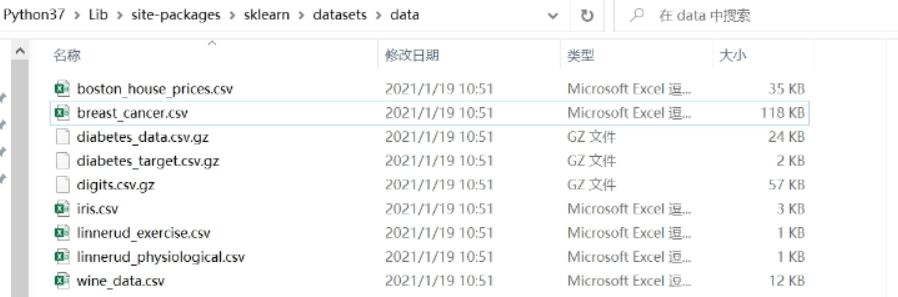
2 :cv2 - data 下包含有人脸识别相关训练模型