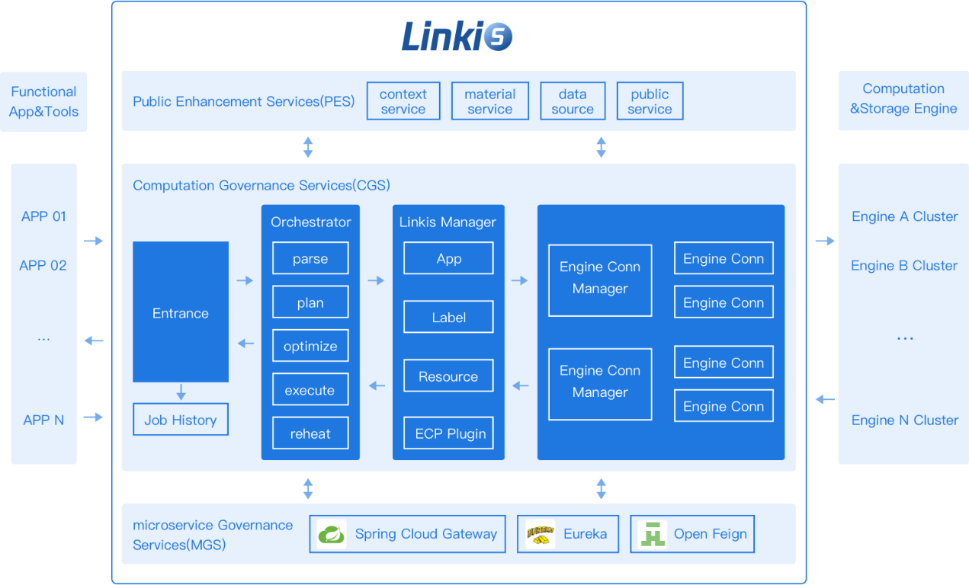
1、Flink概述
1.1 Flink是什么
Flink的官网主页地址:https://flink.apache.org/
Flink的核心目标是“数据流上有状态的计算”(Stateful Computations over Data Streams)。
具体说明:Apache Flink是一个“框架和分布式处理引擎”,用于对无界和有界数据流进行有状态计算。
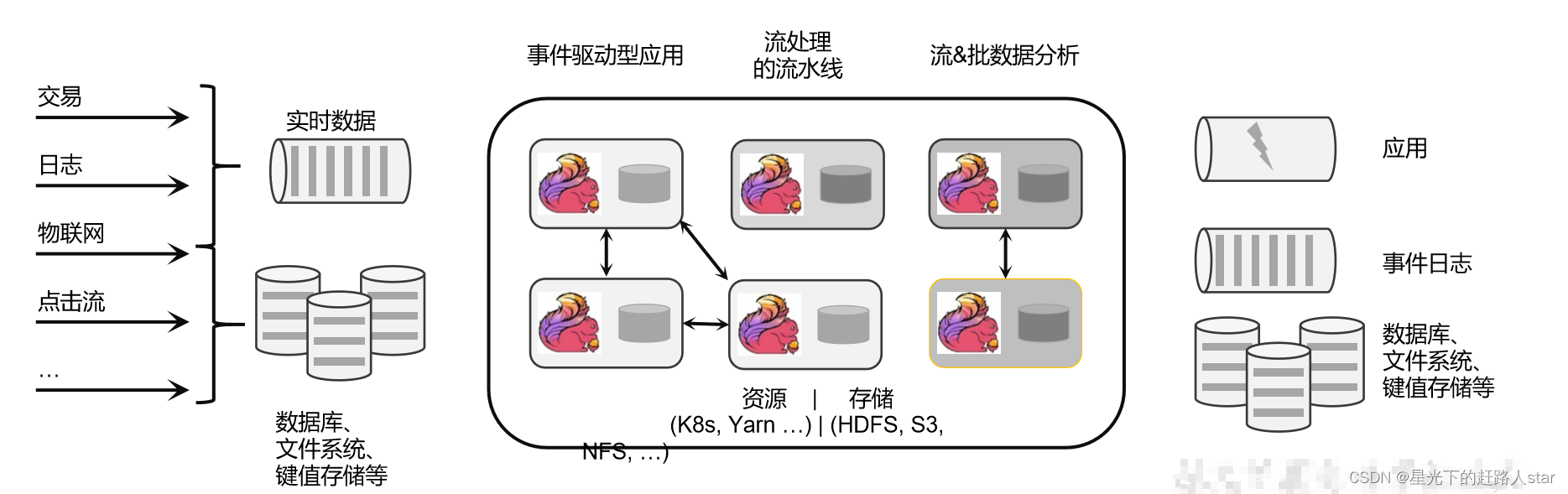
1.1.1 无界数据流
- 有定义流的开始,但是没有定义流的结束
- 它们会无休止的产生数据
- 无界流的数据必须持续处理,即数据被摄取后需要立即处理。我们不能等到所有数据都到达再处理,因为输入时无限的。
1.1.2 有界数据流
- 有定义流的开始,也有定义流的结束
- 有界流可以在摄取所有数据后再进行计算
- 有界流所有的数据可以被排序,所有并不需要有序摄取
- 有界流处理通常被称为批处理
1.1.3 有状态流处理
把流处理需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态,这就是所谓的“有状态的流处理”。
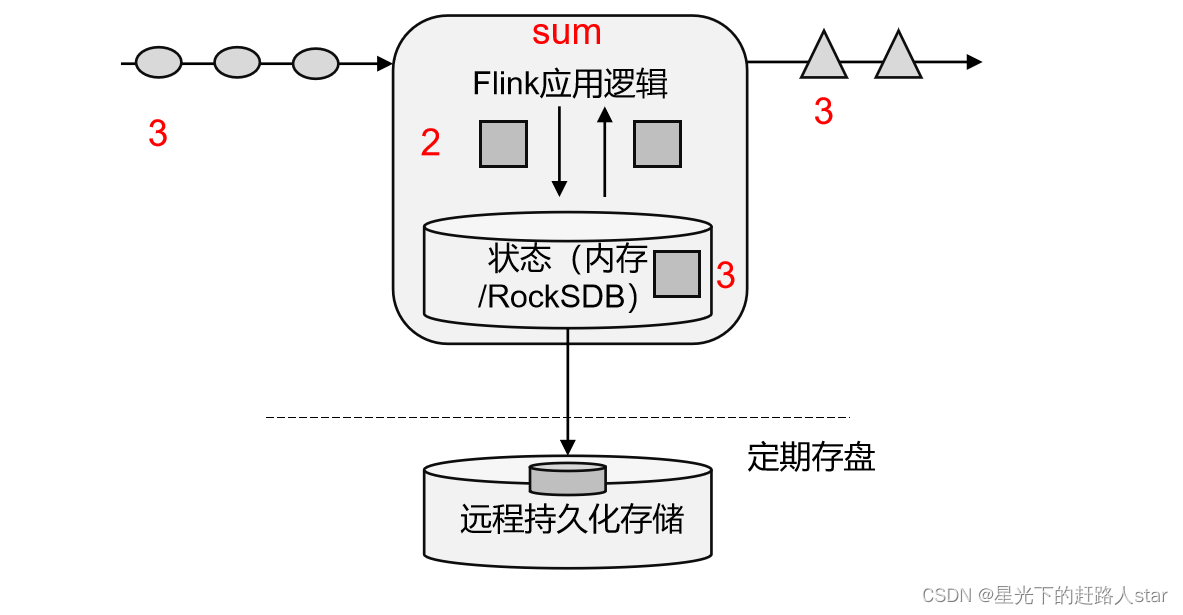
- 状态在内存中:优点:速度快;缺点:可靠性差
- 状态在分布式系统中:优点:可靠性高;缺点:速度慢
1.1.4 Flink发展历史

1.2 Flink特点
我们处理数据的目标是:低延迟、高吞吐、结果的准确性和良好的容错性。
Flink主要特点如下:
- 高吞吐和低延迟:每秒处理数百万个事件,毫秒级延迟
- 结果的准确性:Flink提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-once)的状态一致性保证
- 可以连接到最常用的外部系统,如kafka、Hive、JDBC、HDFS、Redis等
- 高可用:本身高可用的设置,加上K8S,Yarn和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7x24全天候运行。
1.3 Flink和SparkStreaming(说实话没有比较的必要)
1、Spark是以批处理为根本。
2、Flink是以流处理为根本。
1.4 Flink的应用场景
1、电商和市场营销
2、物联网(IOT)
3、物流配送和服务业
4、银行和金融业
1.5 Flink分层API

- 有状态流处理:通过底层API(处理函数),对原始数据加工处理。底层API和DataStreamAPI相集成,可以处理复杂的计算。
- DataStreamAPI(流处理)和DataSetAPI(批处理)封装了底层处理函数,提供了通用的模块,比如转换(transformations,包括map,flatMap等),连接(joins),聚合(aggregations),窗口(Windows)操作等。注意:Flink1.12后,DataStreamAPI已经实现真正的流批一体,所以DataSetAPI已经过时。
- TableAPI是以表为中心的声明式编程,其中表可能会动态变化。TableAPI遵循关系模型;表有二维数据结构,类似于关系数据库中的表,同时API提供可比较的操作,例如select、project、join、group by、aggregate等。我们可以在表与DataStream/DataSet之间无缝切换,以允许程序将TableAPI与DataStream以及DataSet混用。
- SQL这一层在语法与表达能力上与TableAPI类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与TableAPI交互密切,同时SQL查询可以直接在TableAPI定义的表上执行。
2、Flink快速上手
2.1 创建项目
在准备好所有的开发环境之后,我们就可以开始开发自己的第一个Flink程序了。首先我们要做的,就是在IDEA中搭建一个Flink项目的骨架。我们会使用Java项目中常见的Maven来进行依赖管理。
1、创建工程
(1)打开IntelliJ IDEA,创建一个Maven工程。
2、添加项目依赖
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
2.2 WordCount代码编写(大数据常用的例子)
需求:统计一段文字中,每个单词出现的频次
环境准备:创建一个com.zhm.wordcount包
2.2.1 批处理
批处理的基本思路:先逐行读入文件数据,然后将每一行文子拆分成单词;接着按照单词分组,统计每组数据的个数,就是对应单词的频次。
1、数据准备
(1)在工程根目录下新建一个data文件夹,并在下面创建文本文件words.txt
(2)在文件中输入一些单词
hello hello hello
world world
hello world
2、代码编写
(1)在com.zhm.wordcount包下新建一个Demo01_BatchProcess类
/**
* @ClassName Batch
* @Description 利用Flink批处理单词统计
* @Author Zouhuiming
* @Date 2023/9/3 9:58
* @Version 1.0
*/
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
计算的套路:
(1) 计算的环境
Spark:SparkContext
MR:Driver
Flink:ExecutionEnvironment
(2) 把要计算的数据封装为计算模型
Spark:RDD(Spark Core)
DateFrame|DataSet(SparkSQL)
DStream(SparkStream)
MR:k-V
Flink:DataSource
(3)调用计算API
RDD.转换算子()
MR:自己去编写Mapper、Reducer
Flink:DataSource.算子()
*/
public class Demo01_BatchProcess {
public static void main(String[] args) throws Exception {
//创建支持Flink计算的环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//使用环境去读取数据,封装为计算模型
DataSource<String> dataSource = env.readTextFile("data/words.txt");
//调用计算API
dataSource.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = s.split(" ");
for (String s1 : split) {
collector.collect(new Tuple2<String,Integer>(s1,1));
}
}
}).groupBy(0)
.sum(1)
.print();
}
}
运行结果:
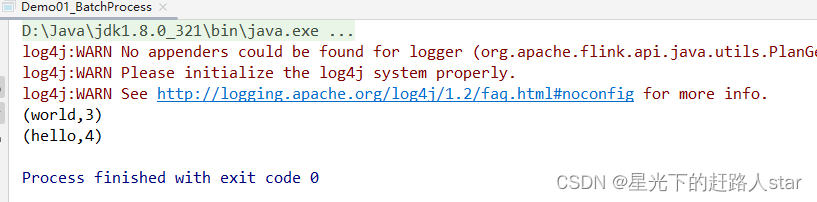
注意:这种实现是基于DataSetAPI的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。所以从Flink1.12开始,官方推荐的做法是直接使用DataStreamAPI,在提交任务时通过将执行模式设为BATCH来进行批处理;
bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
这样,DataSetAPI就没有用了,在实际应用中我们只要维护一套DataStreamAPI就可以。这里只是为了方便大家理解,我们依然用DataSetAPI做了批处理的实现。
2.2.2 流处理
对于Flink而言,流才是整个处理逻辑的底层核心,所以流批一体之后的DataStreamAPI更加强大,可以直接处理批处理和流处理的所有场景。
下面我们就针对不同类型的的输入数据源,用具体的代码来实现流处理。
1、读取文件(有界流)
我们同样试图读取文档words.txt中的数据,并统计每个单词出现的频次。整体思路与之前的批处理非常类似,代码模式也基本一致。
在com.zhm.wordcount包下新建一个Demo02_BoundedStreamProcess类
package com.zhm.wordcount;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @ClassName Demo02_BoundedStreamProcess
* @Description 有界流
* @Author Zouhuiming
* @Date 2023/9/3 10:26
* @Version 1.0
*/
public class Demo02_BoundedStreamProcess {
public static void main(String[] args) throws Exception {
//1、创建支持Flink计算的环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.1 设置一个线程处理这个流(默认是根据你的cpu数和单词种类个数,取最小值)
// env.setParallelism(1);
//2、获取数据源
FileSource<String> source = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("data/words.txt")).build();
//3、利用环境将数据源的数据封装为计算模型
DataStreamSource<String> streamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "myfile");
//4、调用API对数据进行计算
//4.1 将每行数据按照给定的分割符拆分为Tuple2类型的数据模型(word,1)
streamSource.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = s.split(" ");
for (String s1 : split) {
collector.collect(new Tuple2<>(s1,1));
}
}
//4.2 根据word分组
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
//4.3 根据分组之后,按照元组中的第二列聚相加
}).sum(1)
// 4.4 打印结果
.print();
//5、提交job
env.execute();
}
}
运行结果:
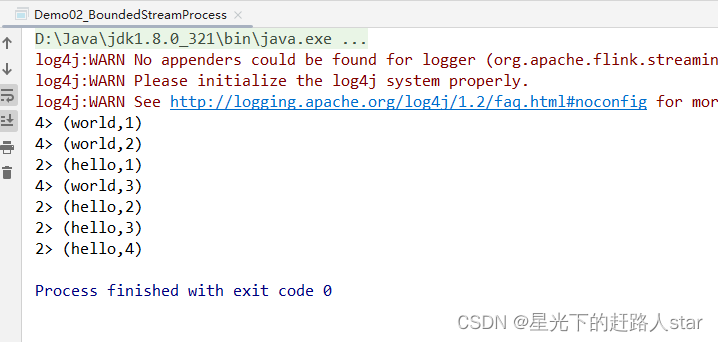
和批处理程序BatchWordCount的不同:
- 创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment。
- 转换处理之后,得到的数据对象类型不同
- 分组操作调用的方法是keyBy方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key是什么。
- 代码末尾需要调用env的execute方法,开始执行任务。
2、读取Socket文本流(无界流)
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要持续的处理捕获的数据。为了模拟这种场景,可以监听Socket端口,然后向该端口不断地发生数据。
(1)将StreamWordCount代码中读取文件数据的readTextFile方法,替换成读取Socket文本流的方法socketTextStream。具体代码实现如下:
package com.zhm.wordcount;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @ClassName Demo03_UnBoundedStreamProcess
* @Description 无界流
* @Author Zouhuiming
* @Date 2023/9/3 10:39
* @Version 1.0
*/
public class Demo03_UnBoundedStreamProcess {
public static void main(String[] args) throws Exception {
//1、创建支持Flink计算的环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.1 设置一个线程处理这个流
env.setParallelism(1);
//2、获取数据源
DataStreamSource<String> streamSource = env.socketTextStream("hadoop102", 9999);
//3.1 将每行数据按照给定的分割符拆分为Tuple2类型的数据模型(word,1)
streamSource.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = s.split(" ");
for (String s1 : split) {
collector.collect(new Tuple2<>(s1,1));
}
}
//3.2 根据word分组
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
//3.3 根据分组之后,按照元组中的第二列聚相加
}).sum(1)
// 3.4 打印结果
.print();
//4、提交job
env.execute();
}
}
(2)在Linux环境的主机hadoop102上,执行下列命令,发送数据进行测试(前提是要安装netcat)
nc -lk hadoop102 9999
(3)启动Demo03_UnBoundedStreamProcess程序
我们会发现程序启动之后没有任何输出、也不会退出。这是正常的,因为Flink的流处理是事件驱动的,当前程序会一直处于监听状态,只有接受数据才会执行任务、输出统计结果。
(4)从hadoop102发送数据

(5)观察idea控制台
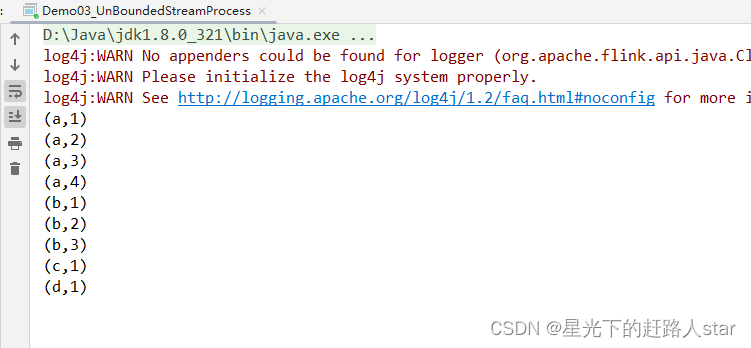
说明:Flink还具有一个类型提前系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于java中泛型擦除的存在,在某些特殊情况下(比如Lambda表达式中),自动提取的信息是不够精细的–只告诉Flink当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显示地提供类型信息,才能使得应用程序正常工作或提高其性能。
因为对于flatMap里传入的Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple<String,Long>。只有显示地告诉系统当前的返回类型,才能正确的解析出完整数据。
2.2.3 执行模式
从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理。不建议使用DataSet API。
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamAPI执行模式包括:流执行模式、批执行模式和自动模式。
- 流执行模式(Streaming)
这是DataStreamAPI最经典的模式,一边用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。 - 批执行模式(Batch)
专门用于批处理的执行模式 - 自动模式
在这种模式下,将由程序根据输入数据源是否有界来自动选择执行模式。
批执行模式的使用:主要有两种方式:
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
在提交作业时,增加execution.runtime-mode参数,指定值为BATCH。
(2)通过代码设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用setRuntimeMode方法,传入BATCH模式。
实际应用中一般不会在代码中配置,而是使用命令行,这样更加灵活。
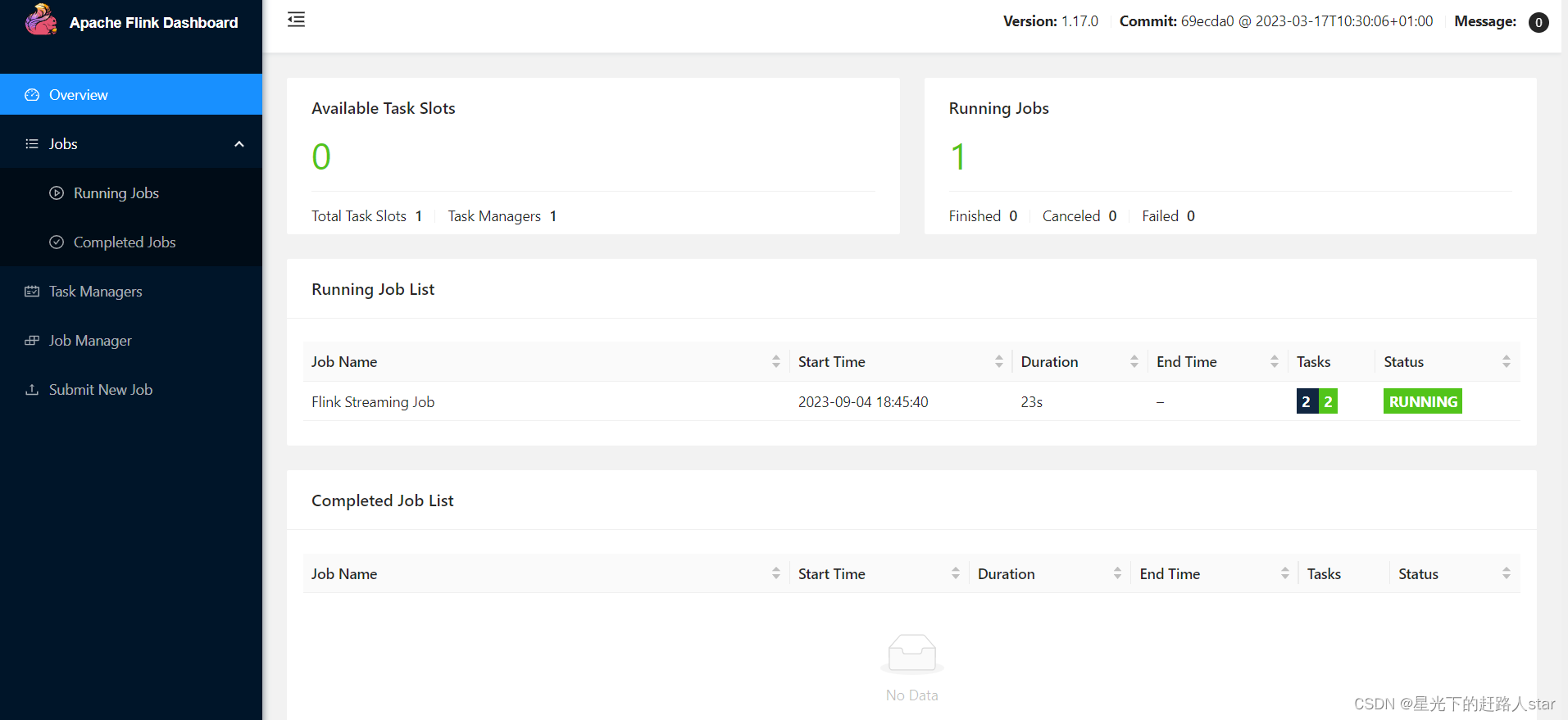
2.2.4 本地WebUI
在Idea本地运行程序时,可以通过添加本地WebUI依赖,使用WebUI界面查看Job的运行情况。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
添加后,在代码中可以指定绑定的端口:
Configuration conf = new Configuration();
conf.setInteger("rest.port", 3333);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
之后,在程序启动后,打开本地浏览器,访问localhost:3333即可查看job的运行情况。
![java八股文面试[JVM]——JVM性能优化](https://img-blog.csdnimg.cn/img_convert/944a51e6faf749f92a3778a203c66a1b.png)