原文链接:https://www.techbeat.net/article-info?id=4361
作者:钟程亮
3D特征点检测在物体识别、场景重建等任务中有着重要作用。然而由于点云数据采样的稀疏性,从中检测出3D特征点是一项很有挑战性的任务。虽然原始点云的获取方式有很多种,如通过RGB-D相机、立体匹配或LIDAR等,但点云仍还是物体(或场景)的连续形状的离散表示。这一现象促使我们去探索了联合重建3D形状任务是否有助于3D关键点检测。
因此,本文提出了名为SNAKE的方法,它是shape-aware neural 3D keypoint field的缩写。受近期基于坐标的神经辐射场和神经距离场的启发,SNAKE将3D坐标作为输入,同时预测该点的空间占有率和特征点显著性,从而自然地将3D特征点检测和形状重建任务耦合在一起。我们在多个公开的基准测试中展现了SNAKE的优越性能,包括物体数据集ModelNet40、KeypointNet,人体数据集SMPL和场景级数据集3DMatch和Redwood。

论文链接:
https://arxiv.org/abs/2206.01724
代码链接:
https://github.com/zhongcl-thu/SNAKE
一、研究背景
从点云数据中检测3D特征点的方法通常可以被分为基于手工设计和基于数据驱动的方法。前者大多基于局部的统计特性,例如,ISS[1]选择局部邻域内沿每个主轴有很大变化的点,Harris3D[2]利用一阶和二阶导数的特性确定特征点。基于手工设计的方法因缺乏对点云数据全局的感知能力,当输入点云的密度发生变化或受噪声干扰时,通常无法检测到一致的特征点。
基于数据驱动的方法是近几年流行的方法,因其可以从大量点云数据中学习到一致的特征点而备受关注。比如,USIP[3]利用特征点应在输入的几何变换下保持一致的原则,对特征点施加了几何约束,从而构建了一个自监督学习的框架。但是USIP仅考虑了多视角几何约束,未考虑语义一致的特征点的关联性。UKPGAN[4]采用的策略是预测输入点云中每个点的显著性分数,并以此筛选出有效的隐层表征特征,并将该特征送入全连接层以恢复出原来的输入点云。但UKPGAN特征点的数量受输入点个数的影响,且特征点必须从输入点集合中获取,因此其难以应对采样密度变化和噪声等影响。
我们在图1中比较了SNAKE和上述两种方法的差异。USIP网络根据输入点云直接输出特征点坐标。UKPGAN预测输入点云中每个点的显著性概率,并通过倒角距离重构出原输入的坐标。与上述两种方法不同,SNAKE预测每个查询点而不是输入点云的显著性概率,同时预测查询点的空间占有的概率。不同于UKPGAN,SNAKE期望学习到输入点云对应的连续形状表面而不是离散输入。这种做法的一个直接优势是紧密地耦合了形状重建和3D关键点检测两个任务。试想一下,若有一个飞机翼尖的隐层特征,如果它可以用来重建翼尖的尖锐曲率,它自然可以被检测成为具有高重复性的关键点。
因此,我们的特征点检测方法融合了对形状的感知,它有如下的几个优势:
- 高可重复性。可重复性是特征点检测重要的指标,即检测算法应该在多视角点云中检测到相同位置的特征点。如上所述,若嵌入特征能够成功地从多视角点云中重建相同的飞机翼尖,那么它们大概率对应着相似的显著性分数。
- 对点云密度鲁棒。当输入点云变稀疏时,类似UKPGAN的框架只能实现与输入同密度的重建。相比之下,SNAKE因采用了基于坐标的网络,可自然地以任何分辨率重建表面形状。
- 语义一致性。SNAKE通过跨同一类别不同实例的重建,使得特征点具备语义一致性,例如,因为人体形状本质上是相似的,嵌入特征也必须相似才能成功重建不同的人体。
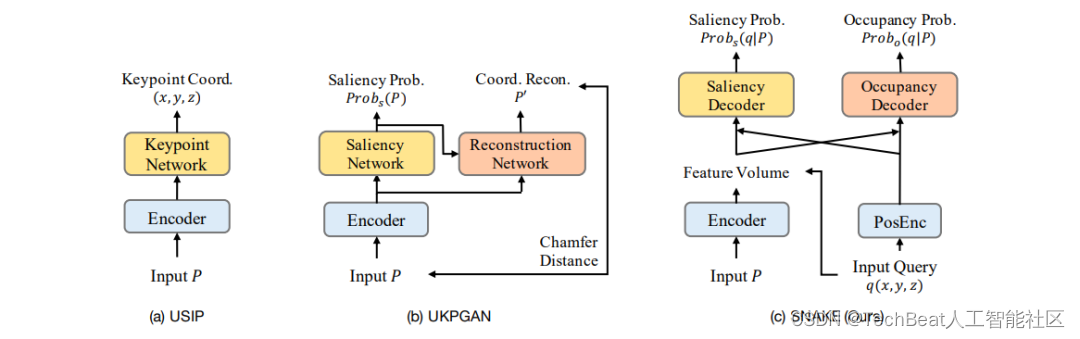
图1 现有3D特征点检测方法与我们新提出的方法的比较
二、解决方法
SNAKE模型架构
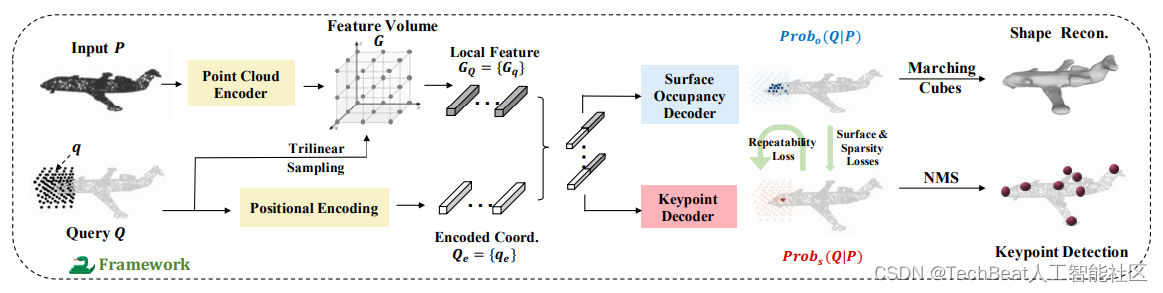
图2 SNAKE框架图
我们所提出的网络总体架构如图2所示,它主要包含了:
- 输入点云编码器。该模块同ConvONet[5]的输入点云编码器相似,目的是将输入点云 P ∈ R N × 3 P \in\mathbb{R}^{N\times 3} P∈RN×3 映射到一个体素化的高层特征空间 G ∈ R C 2 × H × W × D G \in \mathbb{R}^{C_2\times H \times W \times D} G∈RC2×H×W×D ,其中 N N N 表示输入点个数, C 2 C_2 C2 表示特征维度, H , W , D H,W,D H,W,D 分别代表了体空间的高,宽和深度。
- 形状隐式解码器。首先将任意输入的查询点 q ∈ R 3 q\in \mathbb{R}^3 q∈R3(查询集合为 Q Q Q )经坐标编码模块映射到 C e C_e Ce 维的向量 q e q_{e} qe 。然后,根据 q q q 的坐标,通过三线性插值从体特征 G G G 中检索出对应的局部特征 G q G_q Gq 。接着,融合 G q G_q Gq 和 q e q_{e} qe ,并将结果送入到形状解码器 f θ o f_{\theta_o} fθo 中,得到查询点的表面占用概率 P r o b o ( q ∣ P ) ∈ [ 0 , 1 ] Prob_o(q|P) \in [0, 1] Probo(q∣P)∈[0,1] 。如果 q q q 在输入表面上,则 P r o b o ( q ∣ P ) Prob_o(q|P) Probo(q∣P) 将为1,否则为0。在我们的定义中,表面内的点也被认为是未占用的。
- 特征点隐式解码器。该模块的大部分操作同上述解码器中描述的类似。唯一区别在于该解码器 f θ s f_{\theta_s} fθs 的目标是估计查询点的显著性 P r o b s ( q ∣ P ) ∈ [ 0 , 1 ] Prob_s(q|P) \in [0, 1] Probs(q∣P)∈[0,1] ,即是特征点的可能性。
隐式场优化目标
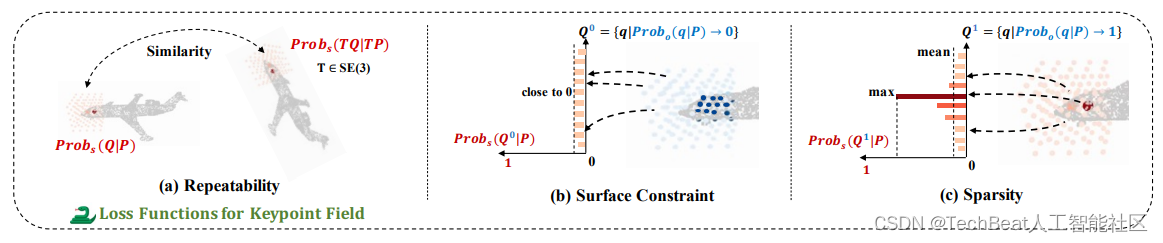
图3 隐式特征点场优化目标示意图
SNAKE通过多个自监督损失函数,同时优化表面占有率预测和显著性估计任务。与之前的相似的多任务学习架构不同,我们利用了形状的几何场来增强特征点场的性能,如图2的绿色箭头所示。具体来说,总损失由下式给出:
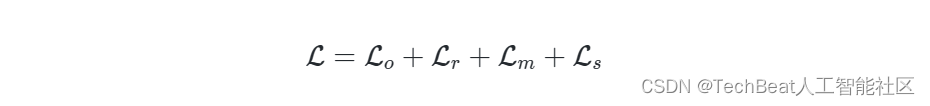
其中,
L
o
\mathcal{L}_o
Lo 鼓励模型从稀疏输入中学习连续的几何形状表面,采用标准的交叉熵损失函数。
L
r
\mathcal{L}_r
Lr 、
L
m
\mathcal{L}_m
Lm 和
L
s
\mathcal{L}_s
Ls 分别让预测的特征点是可重复的,位于物体/场景形状表面上并且是稀疏的。
如图3所示,我们重点介绍隐式特征点场的优化目标,它包括了:
- 可重复性损失。如背景中所述,可重复性是特征点应具备的重要性质。为了实现该目标,2D特征点检测方法[6,7]采用了让多视角下对应局部显著块尽可能相似的方式。受此启发,我们也可约束两个视角下对应的局部特征点场的相似性。但由于隐式场是连续的,我们需要从局部场中离散地采样一些值来表示局部的显著性分布。如图3(a)所示,我们构建了多个局部3D笛卡尔网格
{
Q
i
}
i
=
1
n
\{Q_i\}_{i=1}^{n}
{Qi}i=1n ,分辨率为
H
l
×
W
l
×
D
l
H_l \times W_l \times D_l
Hl×Wl×Dl ,大小为
1
/
U
1/U
1/U 。我们对输入点云和查询点同时施加一个刚性变换
T
T
T ,并构建如下的优化损失,其中cosine相似度简记为cosim:
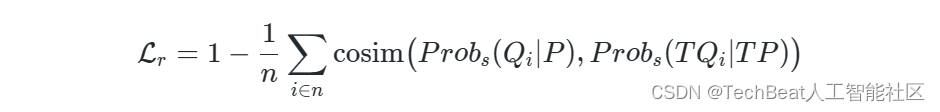
- 表面限制损失。如USIP所述,3D特征点应处于或接近物体的表面。因为表面占用概率与查询点和输入之间的距离成反比,因此,我们让远离输入的查询点的显著性应尽可能为0,如图3(b)所示。其可表示为:
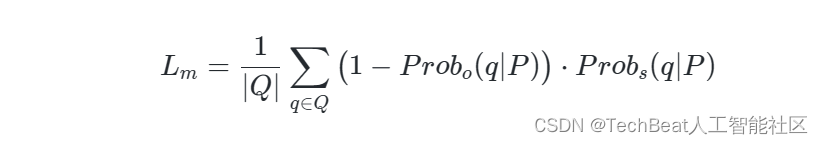
- 稀疏损失。受2D特征点检测方法的启发,我们通过最大化局部显著性网格的局部峰值来实现特征点的稀疏分布。由于非占有点的显著值被约束为0,因此我们只需对具有高表面占用概率的点施加稀疏损失,如图3©所示,又可表示为:

显式特征点的提取
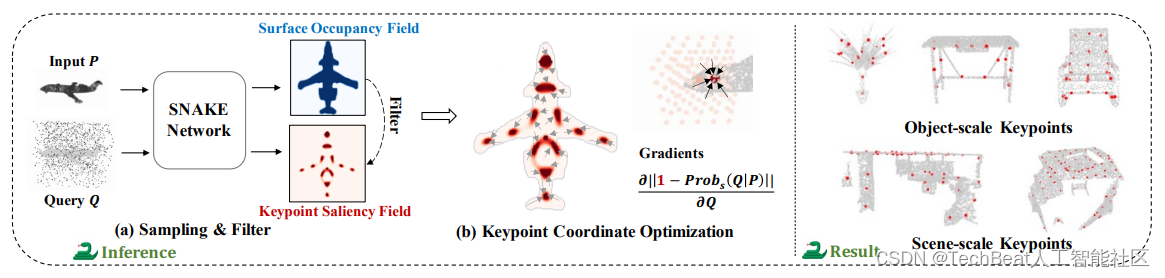
图4 显式特征点提取方法和结果示意图
在推理阶段,我们认为显著性高于预定义阈值
t
h
r
s
∈
(
0
,
1
)
thr_s\in (0,1)
thrs∈(0,1) 的查询点
q
q
q 应被选为特征点。虽然SNAKE可以获取任意查询点的显著性,但高分辨率的查询集会导致计算成本增加。因此,如图4所示,我们构建了一个在输入空间中均匀分布且相对低分辨率的查询集
Q
i
n
f
e
r
Q_{\rm infer}
Qinfer 。同时,通过基于梯度的能量函数进一步优化
Q
i
n
f
e
r
Q_{\rm infer}
Qinfer 的坐标,具体的算法如下所示:
 图5 特征点坐标优化算法图
图5 特征点坐标优化算法图
三、实验结果
首先,我们比较了特征点的语义一致性,即在相同类别且不同实例的物体之间特征点是否有语义上的相似性。按照UKPGAN论文中建立的实验设定和评价方式,我们在keypointNet数据集(刚性)和SMPL人体数据集(非刚性)上和其他方法做了比较。如图7(a,e)所示,我们的方法在大部分距离阈值下,取得了最好的性能。图6为可视化结果,其中第5列和第10列为三维特征点场的二维投影,可见其分布均匀、对称,且在不同实例间具备语义一致性。

图6 特征点语义一致性比较
其次,我们比较了特征点的可重复性,即对于同一个实例,在不同视角观测下特征点的一致性。同时,我们还比较了当输入点云被降采样或受到高斯噪声影响时,特征点的可重复性性能。图7(b,c,d)是在ModelNet40上的定量结果分析,图7(f,g,h)是在Redwood上的测试结果。他们展现了SNAKE在大多数情况都取得了最优的性能。图8为定性结果,它体现了我们的方法可以在输入点云采样密度发生变化或被噪声影响时,仍能检测出一致的特征点。
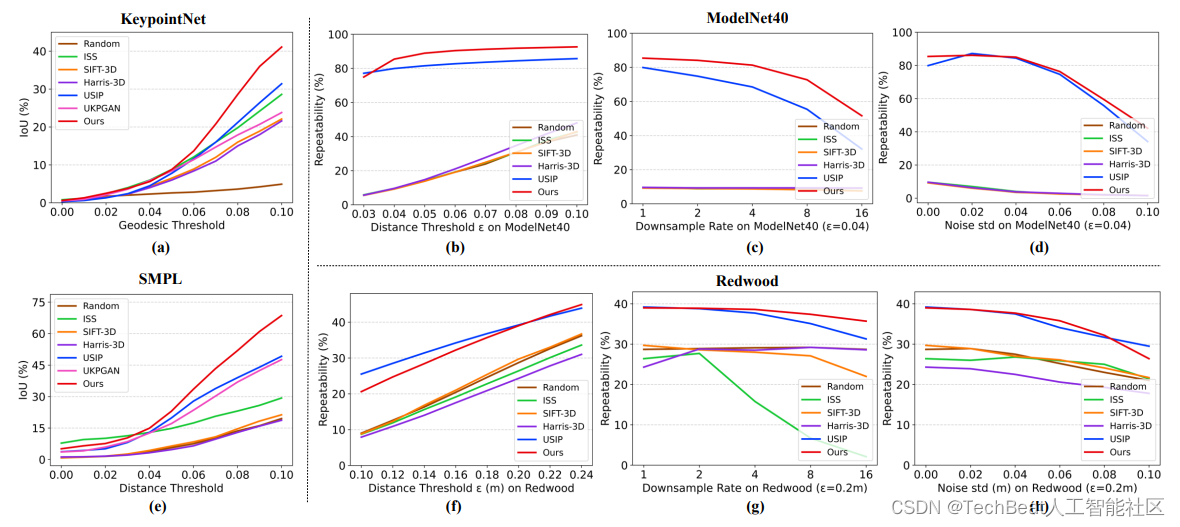
图7 在四个数据集上的定量结果
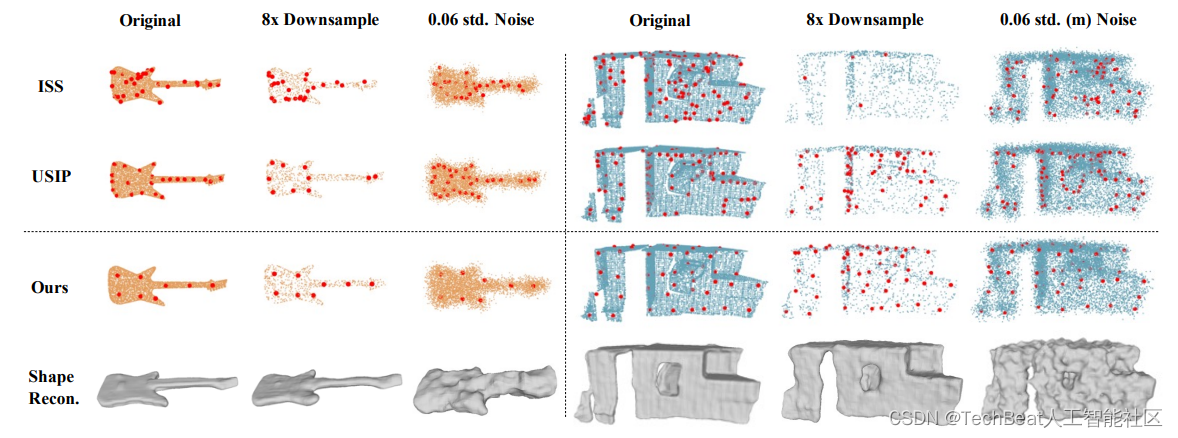
图8 输入点云受采样分辨率和噪声影响时特征点的一致性比较,黄色为物体数据,蓝色为场景数据。
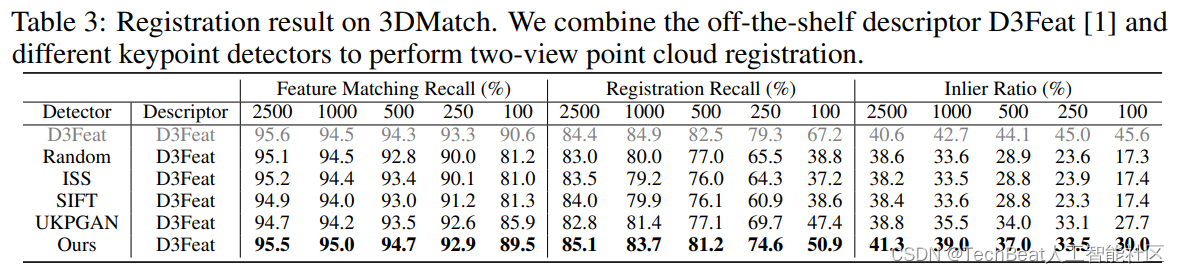
最后,我们仿照UKPGAN的设定,比较了特征点检测器的零样本泛化性能。任务设定为:在KeypointNet上训练特征点检测器后,将其直接在3DMatch数据集中评测点云配准的性能。我们选取了D3feat[8]描述子和各检测器提取的特征点作结合,通过匹配求出多视角下场景的空间变换关系。如下表所示,我们的方法取得了比UKPGAN和其他特征点检测器更好的结果。
四、总结
我们提出了SNAKE,一种基于隐式神经表示的3D关键点检测新范式。它同时解码物体的形状和特征点显著信息,使得特征点考虑了物体的几何形状信息,具备了诸多优势。通过大量的实验研究表明,我们的关键点在语义上是一致的、可重复的、对下采样和噪声具有鲁棒性,并且可推广到未见过的场景。当然,在推理过程中关键点提取的优化需要一定的计算成本和时间,这可能不适用于需要实时关键点检测的场景,这还需要进一步做深入研究。
参考文献
[1] Yu Zhong. Intrinsic shape signatures: A shape descriptor for 3d object recognition. In 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, pages 689–696. IEEE, 2009.
[2] Ivan Sipiran and Benjamin Bustos. Harris 3d: a robust extension of the harris operator for interest point detection on 3d meshes. The Visual Computer, 27(11):963–976, 2011.
[3] Jiaxin Li and Gim Hee Lee. Usip: Unsupervised stable interest point detection from 3d point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 361–370, 2019.
[4] Yang You, Wenhai Liu, Yanjie Ze, Yong-Lu Li, Weiming Wang, and Cewu Lu. Ukpgan: A general self-supervised keypoint detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
[5] Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks. In European Conference on Computer Vision, pages 523–540. Springer, 2020.
[6] Jerome Revaud, Cesar De Souza, Martin Humenberger, and Philippe Weinzaepfel. R2d2: Reliable and repeatable detector and descriptor. Advances in Neural Information Processing Systems, 32, 2019.
[7] Chengliang Zhong, Chao Yang, Fuchun Sun, Jinshan Qi, Xiaodong Mu, Huaping Liu, and Wenbing Huang. Sim2real object-centric keypoint detection and description. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 5440–5449, 2022.
[8] Xuyang Bai, Zixin Luo, Lei Zhou, Hongbo Fu, Long Quan, and Chiew-Lan Tai. D3feat: Joint learning of dense detection and description of 3d local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6359–6367, 2020.
Illustration by Manypixels Gallery from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com




![[ vulhub漏洞复现篇 ] GhostScript 沙箱绕过(任意命令执行)漏洞CVE-2018-19475](https://img-blog.csdnimg.cn/e3231fcc68bd43a5bc10e972c005b6eb.png)