目录
描述
题目分析
描述
合并 k 个升序的链表并将结果作为一个升序的链表返回其头节点。
数据范围:节点总数 0≤n≤5000,每个节点的val满足∣val∣<=1000
要求:时间复杂度 O(nlogn)
示例1
输入:[{1,2,3},{4,5,6,7}]
返回值:{1,2,3,4,5,6,7}示例2
输入:[{1,2},{1,4,5},{6}]
返回值:{1,1,2,4,5,6}
题目分析
方法一:归并排序思想(推荐使用)
知识点1:双指针
双指针指的是在遍历对象的过程中,不是普通的使用单个指针进行访问,而是使用两个指针(特殊情况甚至可以多个),两个指针或是同方向访问两个链表、或是同方向访问一个链表(快慢指针)、或是相反方向扫描(对撞指针),从而达到我们需要的目的。
知识点2:分治
分治即“分而治之”,“分”指的是将一个大而复杂的问题划分成多个性质相同但是规模更小的子问题,子问题继续按照这样划分,直到问题可以被轻易解决;“治”指的是将子问题单独进行处理。经过分治后的子问题,需要将解进行合并才能得到原问题的解,因此整个分治过程经常用递归来实现。
思路:
如果是两个有序链表合并,我们可能会利用归并排序合并阶段的思想:准备双指针分别放在两个链表头,每次取出较小的一个元素加入新的大链表,将其指针后移,继续比较,这样我们出去的都是最小的元素,自然就完成了排序。
其实这道题我们也可以两两比较啊,只要遍历链表数组,取出开头的两个链表,按照上述思路合并,然后新链表再与后一个继续合并,如此循环,知道全部合并完成。但是,这样太浪费时间了。
既然都是归并排序的思想了,那我们可不可以直接归并的分治来做,而不是顺序遍历合并链表呢?答案是可以的!
归并排序是什么?简单来说就是将一个数组每次划分成等长的两部分,对两部分进行排序即是子问题。对子问题继续划分,直到子问题只有1个元素。还原的时候呢,将每个子问题和它相邻的另一个子问题利用上述双指针的方式,1个与1个合并成2个,2个与2个合并成4个,因为这每个单独的子问题合并好的都是有序的,直到合并成原本长度的数组。
对于这k个链表,就相当于上述合并阶段的k个子问题,需要划分为链表数量更少的子问题,直到每一组合并时是两两合并,然后继续往上合并,这个过程基于递归:
- 终止条件: 划分的时候直到左右区间相等或左边大于右边。
- 返回值: 每级返回已经合并好的子问题链表。
- 本级任务: 对半划分,将划分后的子问题合并成新的链表。
具体做法:
- step 1:从链表数组的首和尾开始,每次划分从中间开始划分,划分成两半,得到左边n/2n/2n/2个链表和右边n/2n/2n/2个链表。
- step 2:继续不断递归划分,直到每部分链表数为1.
- step 3:将划分好的相邻两部分链表,按照两个有序链表合并的方式合并,合并好的两部分继续往上合并,直到最终合并成一个链表。
图示:
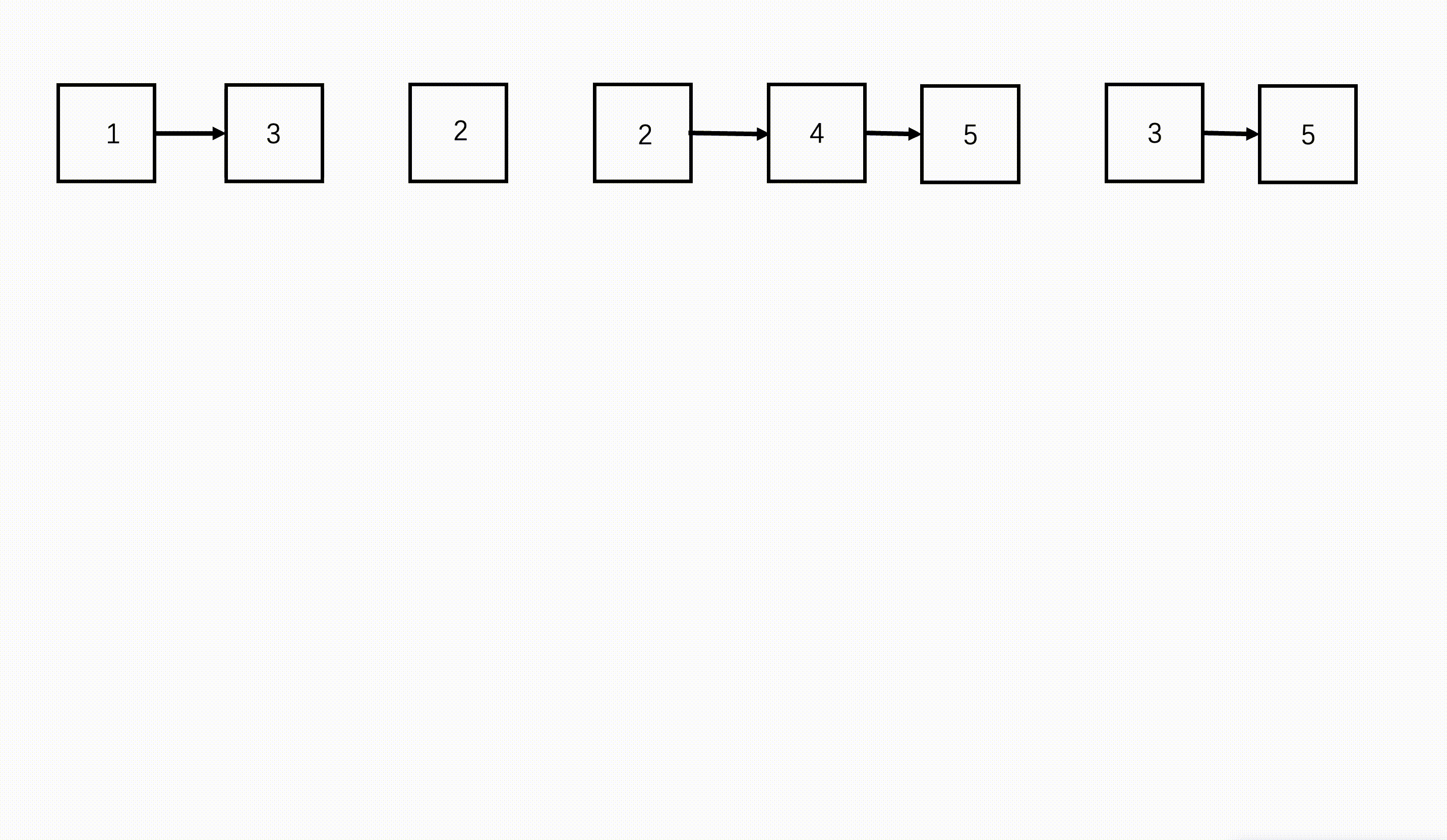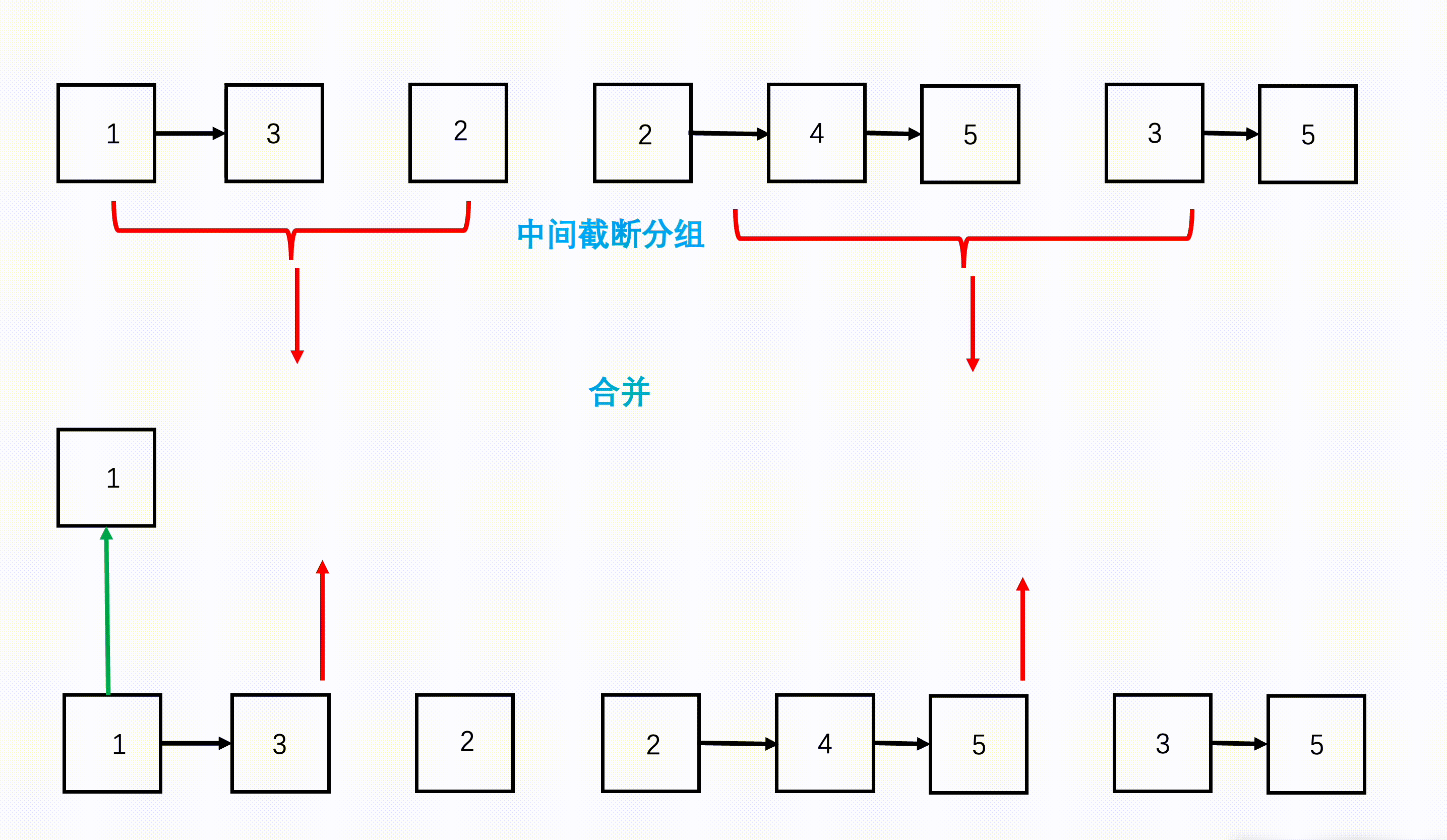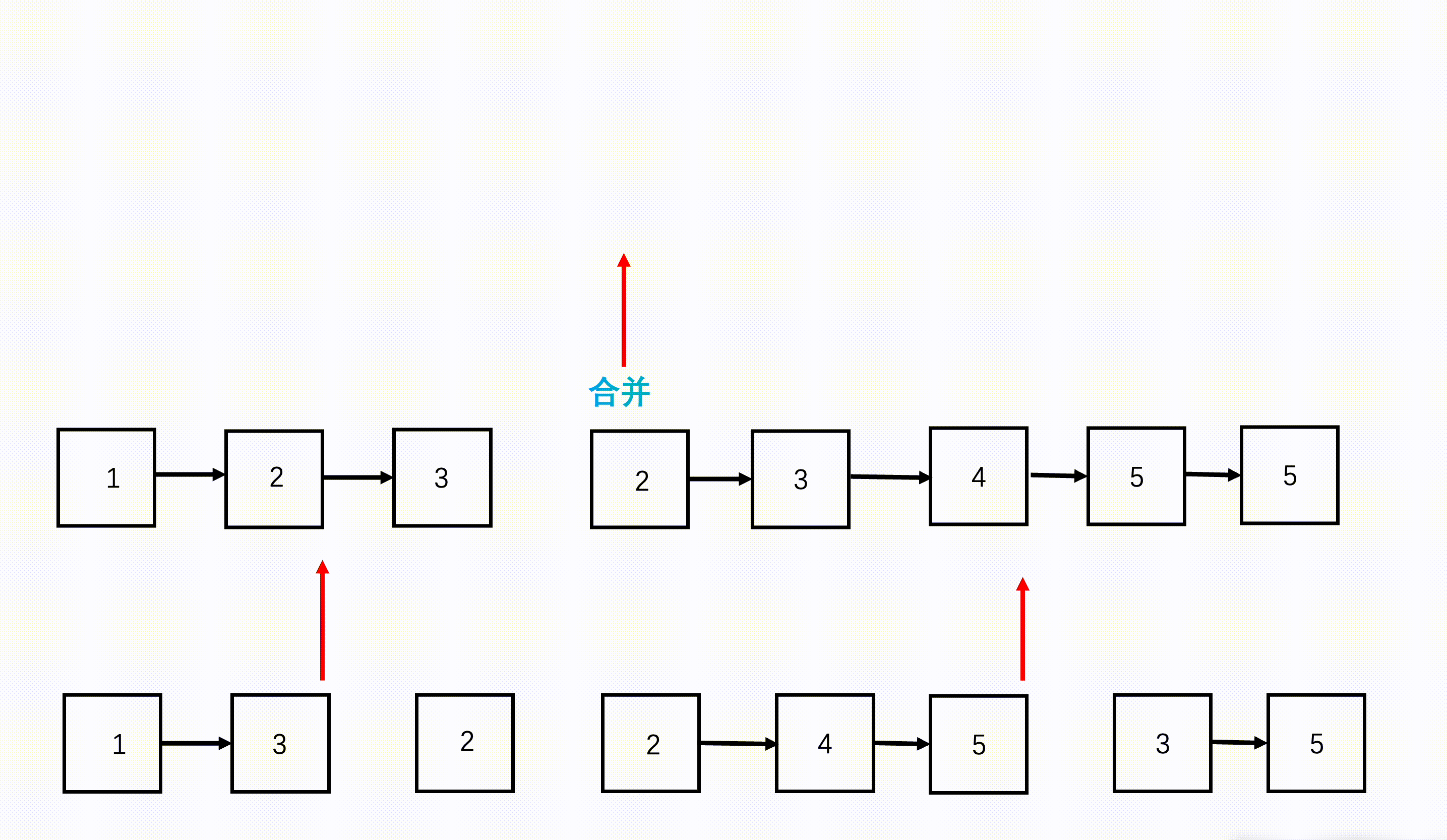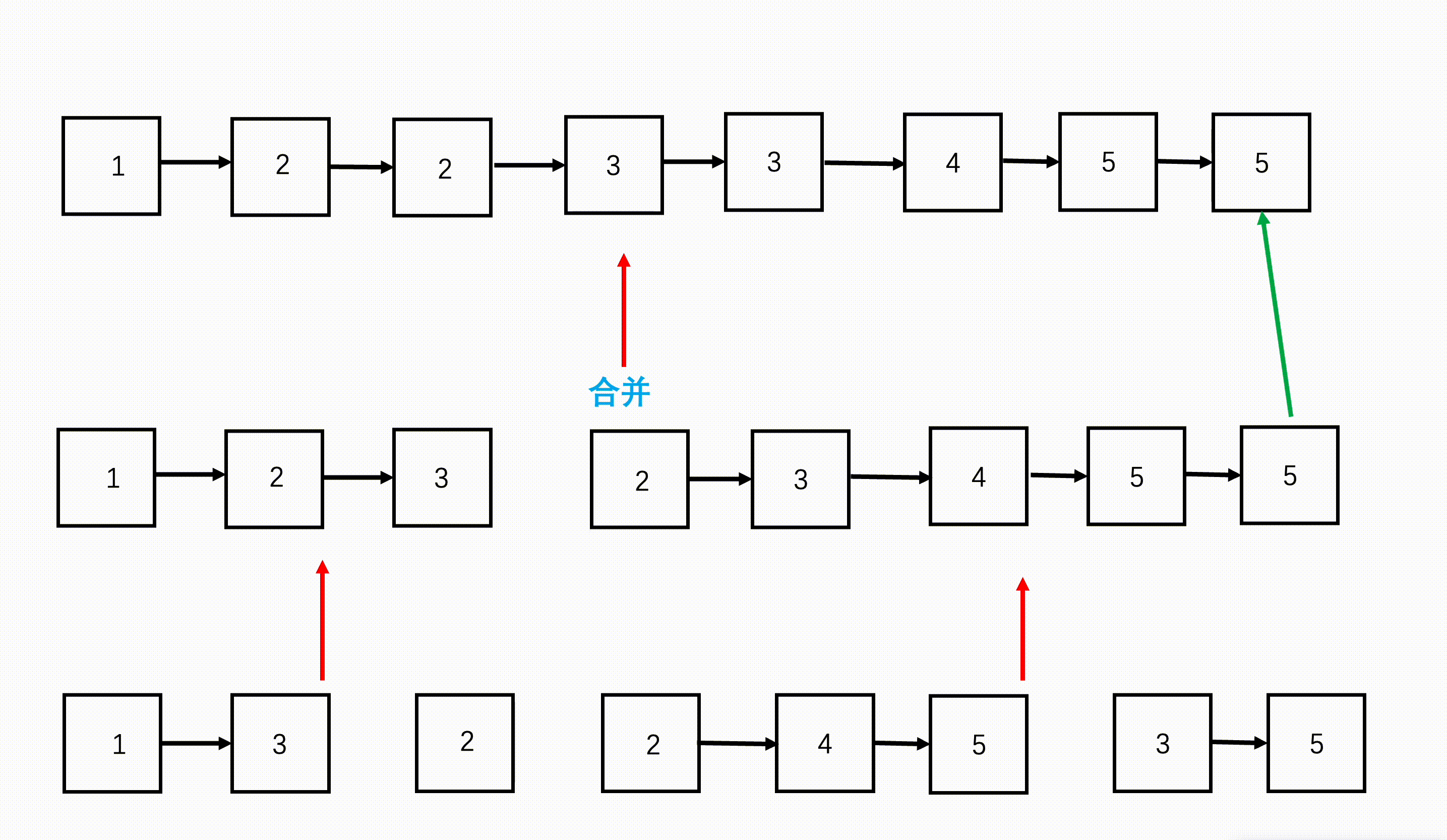
实现代码:
class Solution {
public:
//两个有序链表合并函数
ListNode* Merge2(ListNode* pHead1, ListNode* pHead2) {
//一个已经为空了,直接返回另一个
if(pHead1 == NULL)
return pHead2;
if(pHead2 == NULL)
return pHead1;
//加一个表头
ListNode* head = new ListNode(0);
ListNode* cur = head;
//两个链表都要不为空
while(pHead1 && pHead2){
//取较小值的节点
if(pHead1->val <= pHead2->val){
cur->next = pHead1;
//只移动取值的指针
pHead1 = pHead1->next;
}else{
cur->next = pHead2;
//只移动取值的指针
pHead2 = pHead2->next;
}
//指针后移
cur = cur->next;
}
//哪个链表还有剩,直接连在后面
if(pHead1)
cur->next = pHead1;
else
cur->next = pHead2;
//返回值去掉表头
return head->next;
}
//划分合并区间函数
ListNode* divideMerge(vector<ListNode *> &lists, int left, int right){
if(left > right)
return NULL;
//中间一个的情况
else if(left == right)
return lists[left];
//从中间分成两段,再将合并好的两段合并
int mid = (left + right) / 2;
return Merge2(divideMerge(lists, left, mid), divideMerge(lists, mid + 1, right));
}
ListNode *mergeKLists(vector<ListNode *> &lists) {
//k个链表归并排序
return divideMerge(lists, 0, lists.size() - 1);
}
};
复杂度分析:
- 时间复杂度:O(nlog2k),其中nnn为所有链表的总节点数,分治为二叉树型递归,最坏情况下二叉树每层合并都是O(n)个节点,因为分治一共有O(log2k)层
- 空间复杂度:O(log2k),最坏情况下递归log2k层,需要log2k的递归栈
注:题解来源牛客网分析,如有侵权,请告删之。