今天涉及的内容如下,下面都会使用例子一一讲解使用,
1.1 utilities:langchain的python解析器
1.2 LLMMathChain:可以处理计算的链,内部用python解释器处理
1.3 LLMRequestsChain:通过一个 HTTP 请求来得到问题的答案
1.4 TransformChain:可以定义代码用来统一数据格式转换
1.5 VectorDBQA:qa方式向量数据库问答
我们用OpenAI来实现简单数字计算,然后对比python的数字计算
#! pip install openai
#! pip install langchain
import openai, os
os.environ["OPENAI_API_KEY"] = ""
openai.api_key = os.environ.get("OPENAI_API_KEY")
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.chains import LLMChain
llm=OpenAI(model_name="text-davinci-003", max_tokens=2048, temperature=0.5)
multiply_prompt=PromptTemplate(template="请计算一下{question}是多少?", input_variables=["question"])
math_chain=LLMChain(llm=llm,prompt=multiply_prompt,output_key="answer")
answer=math_chain.run({"question":"352乘以493"})
print("OpenAI API 说答案是:", answer)
python_answer = 352 * 493
print("Python 说答案是:", python_answer)结果:很明显,AI给了个错误答案,
OpenAI API 说答案是:
352 x 493 = 174096
Python 说答案是: 173536不过,有人很聪明,说虽然 ChatGPT 直接算这些数学题不行,但是它不是会写代码吗?我们直接让它帮我们写一段利用 Python 计算这个数学式子的代码不就好了吗?的确,如果你让它写一段 Python 代码,给出的代码是没有问题的。
multiply_prompt=PromptTemplate(template="请你写一段python代码,计算{question}", input_variables=["question"])
math_chain=LLMChain(llm=llm,prompt=multiply_prompt,output_key="answer")
answer=math_chain.run({"question":"352乘以493"})
print("OpenAI API 说答案是:", answer)结果:
answer = 352 * 493
print(answer)1.utilities
这样还需要将代码复制到可以执行python脚本的地方,我们可以再调用下python解释器,让整个过程自动完成。使用langchain的utilities就可以做到将代码进行处理执行操作,如下代码所示:
# 可以实现对 Python 解释器的调用。
from langchain.utilities import PythonREPL
python_repl =PythonREPL()
result=python_repl.run(answer)
print("结果:",result)需要有上下文的哦,结果是:
结果: 1735362.LLMMathChain
你会发现上面先调用openai得到代码,再调用解析器执行代码其实也是一种链式调用,而LangChain 就把这样的过程封装成了一个叫做 LLMMathChain 的 LLMChain。不需要自己去生成代码,再调用 PythonREPL,只要直接调用 LLMMathChain,它就会在背后把这一切都给做好,代码如下:
# 使用LLMMathChain
from langchain import LLMMathChain
llm_math=LLMMathChain(llm=llm,verbose=True)
result=llm_math.run("请计算一下352乘以493是多少?")
print(result)结果如下:
> Entering new LLMMathChain chain...
请计算一下352乘以493是多少?```text
352 * 493
```
...numexpr.evaluate("352 * 493")...
Answer: 173536
> Finished chain.
Answer: 173536LangChain 也把前面讲过的 utilities 包里面的很多功能,都封装成了 Utility Chains。比如,SQLDatabaseChain 可以直接根据你的数据库生成 SQL,然后获取数据,LLMRequestsChain 可以通过 API 调用外部系统,获得想要的答案。
3.通过 RequestsChain 获取实时外部信息
之前通过文本数据进行索引和向量,这些都是因为内容固定不需要时效性,如果需要时效性,则这类问题就不好这样处理因为我们可能没有必要不停地更新索引。
我们可以使用 LLMRequestsChain,通过一个 HTTP 请求来得到问题的答案。可以得到有时效性的问题。
下面的代码,prompt中则表示将请求url的谷歌天气数据的html动态加载到{requests_result},再根据{query}内容,从数据里搜索出来相关内容,
然后将prompt模版传入LLMRequestsChain里,最后把要查询的问题以及url传入LLMRequestsChain对象并调用(运行下)LLMRequestsChain对象即可。
from aiohttp.client import request
from tempfile import template
from langchain.chains import LLMRequestsChain
#定义从谷歌网页中搜索出想要信息的模版
template="""在 >>> 和 <<< 直接是来自Google的原始搜索结果.
请把对于问题 '{query}' 的答案从里面提取出来,如果里面没有相关信息的话就说 "找不到"
请使用如下格式:
Extracted:<answer or "找不到">
>>> {requests_result} <<<
Extracted:
"""
PROMPT=PromptTemplate(
input_variables=["query","requests_result"],
template=template,
)
# 将把PROMPT传给LLMRequestsChain
request_chain=LLMRequestsChain(llm_chain=LLMChain(llm=OpenAI(temperature=0),prompt=PROMPT))
# 对应的搜索词语,通过query参数传入,对应的原始搜索结果默认放入requests_result,有对应的占位符替换
question="今天北京天气怎么样?"
inputs={
"query":question,
"url":"https://www.google.com/search?q="+ question.replace(" ", "+")
}
# 运行一下就会通过OpeenAI提取搜索结果
result=request_chain(inputs)
print(result)
# print(result['output'])结果:
{'query': '今天北京天气怎么样?', 'url': 'https://www.google.com/search?q=今天北京天气怎么样?', 'output': '今天白天最高气温30℃,阴有阵雨或雷阵雨,上午东部局在中到大雨2、3级,北转南风;今天夜间最低气温22℃,阴。'}每个人的结果都不一样,我这个结果不太好解析,咱们按作者的结果进行解析处理下,其实这个也可以解析,就是会费劲些,或者说没有规律些,作者使用的是chatGPT4,可能会比我们好,接下来我们按原作者的output处理。
{'query': '今天北京天气怎么样?', 'url': 'https://www.google.com/search?q=今天北京天气怎么样?', 'output': '小雨; 10℃~15℃;东北风 风力4-5级'}我们先解析output内容,并形成规范,按照字典key,value形式展示出来,好方便统一封装。
用代码解析下返回天气的数据,很简单的代码,就是根据字符串内容拆出数据,并封装到字典里,
import re
# 定义一个接收weather_info字符串参数,返回字典类型结果
def parse_weather_info(weather_info: str) -> dict:
# 将天气信息拆分成不同部分
parts=weather_info.split(';')
# 解析天气
weather=parts[0].strip()
# 解析温度范围,并提取最小和最大温度
temperature_range=parts[1].strip().replace('℃','').split('~')
temperature_min=int(temperature_range[0]);
temperature_max=int(temperature_range[1]);
#解析风向和风力
wind_parts=parts[2].split(' ')
wind_direction=wind_parts[0].strip()
wind_force=wind_parts[1].strip()
# 返回解析后的天气信息字典
weather_dict={
'weather':weather,
'temperature_min':temperature_min,
'temperature_max':temperature_max,
'wind_direction':wind_direction,
'wind_force':wind_force
}
return weather_dict
weather_info="小雨; 10℃~15℃;东北风 风力4-5级"
weather_dict=parse_weather_info(weather_info)
print(weather_dict)结果:
{'weather': '小雨', 'temperature_min': 10, 'temperature_max': 15, 'wind_direction': '东北风', 'wind_force': '风力4-5级'}4.通过 TransformationChain 转换数据格式
将上面的解析代码与当前的TransformationChain结合到一起封装,我们就能把结果解析成 dict,供后面其他业务使用结构化的数据。
from langchain.chains import TransformChain, SequentialChain
def transform_func(inputs: dict) ->dict:
# 请求谷歌天气返回的结果数据
text=inputs["output"]
# 将结果数据放入解析
return {"weather_info":parse_weather_info(text)}
#
transformation_chain=TransformChain(input_variables=["output"], output_variables=["weather_info"], transform=transform_func)
# langchain链式调用将上面的request_chain和本次数据转换transformation_chain放入一个调用链条里
final_chain=SequentialChain(chains=[request_chain,transformation_chain],
input_variables=["query","url"], output_variables=["weather_info"])
# 将查询的问题和天气的url传入得到最终的结果
final_result = final_chain.run(inputs)
print(final_result)然后将request_chain和transformation_chain组成一个final_chain这样的链条,变成一个新的叫做 final_chain 的 LLMChain。在这三步完成之后,未来我们想要获得天气信息,并且拿到一个 dict 形式的输出,只要调用 final_chain 的 run 方法,输入我们关于天气的搜索文本就好了。
它的流程我们给出下面的一张图,就可以很清晰了解它的内部流程了
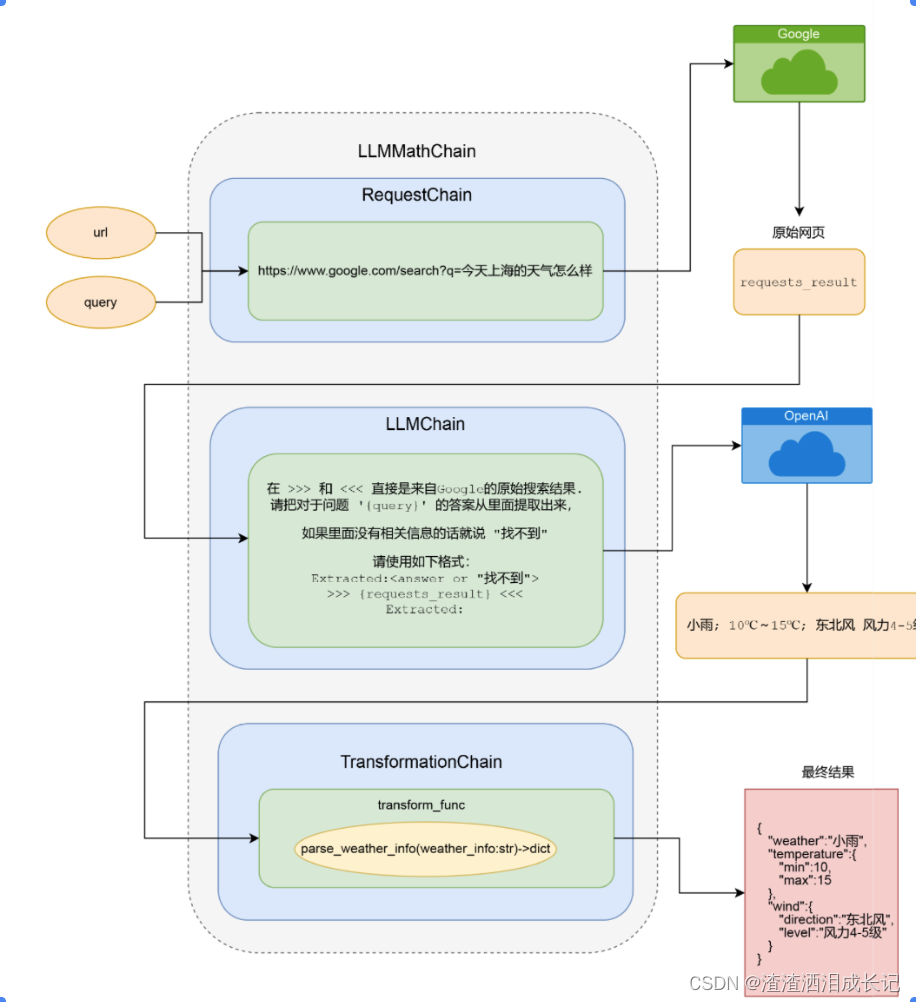
5.通过 VectorDBQA 来实现先搜索再回复的能力
我们这次的案例是之前使用的电商faq内容文件用VectorDBQA方式处理,之前我们预先把资料库索引好,然后每次用户来问问题的时候,都是先到这个资料库里搜索,再把问题和答案一并交给 AI,让它去组织语言回答。
下面的代码则创建了一个基于 FAISS 进行向量存储的 docsearch 的索引,以及基于这个索引的 RetrievalQA 得到这个 LLMChain。也是可以实现之前的电商faq问答的。
跟之前的代码差不多,将文件数据加载进来,进行分块处理,然后转换为向量,在下一步根据转换后的数据在次转换为faq的chain链条,然后根据链条调用查询就可以了
#!pip install spacy;
#!python -m spacy download zh_core_web_sm
#!pip install tiktoken
#!pip install faiss-cpu
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import SpacyTextSplitter
#from langchain import OpenAI, VectorDBQA
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
llm=OpenAI(temperature=0)
# 通过一个 TextLoader 把文件加载进来
loader=TextLoader('./data/ecommerce_faq.txt')
documents=loader.load()
# SpacyTextSplitter 给文本分段,确保每个分出来的 Document 都是一个完整的句子。
text_splitter=SpacyTextSplitter(chunk_size=256,pipeline="zh_core_web_sm")
texts=text_splitter.split_documents(documents)
# 定义了使用 OpenAIEmbeddings来给文档创建 Embedding
embeddings=OpenAIEmbeddings()
# 用embeddings将文本数据 "texts" 转换为嵌入向量
# 使用这些嵌入向量创建了一个名为 "docsearch" 的 FAISS 对象
docsearch=FAISS.from_documents(texts,embeddings)
# 通过 FAISS 把它存储成一个 VectorStore,通过 RetrievalQA 的 from_chain_type 定义了一个 LLM
# faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)10.3
faq_chain=RetrievalQA.from_chain_type(llm=llm,retriever=docsearch.as_retriever())根据chian搜索:
question = "请问你们的货,能送到三亚吗?大概需要几天?"
result = faq_chain.run(question)
print(result)结果:
我们支持全国大部分省份的配送,包括三亚。一般情况下,大部分城市的订单在2-3个工作日内送达,偏远地区可能需要5-7个工作日。根据chian搜索:
question = "请问你们的退货政策是怎么样的?"
result = faq_chain.run(question)
print(result)结果:
自收到商品之日起7天内,如产品未使用、包装完好,您可以申请退货。某些特殊商品可能不支持退货,请在购买前查看商品详情页面的退货政策。我们看到,chain也可以处理这种faq的文本数据,也会根据文档的内容查询出来数据,没有的话就会去搜索AI。
好了以上就是今天的全部内容,
本章视频说明:深入使用LLMChain,给AI连上Google和计算器_哔哩哔哩_bilibili
本节知识资料感谢徐文浩老师的《AI大模型之美》,让我们可以感受它是真的美!