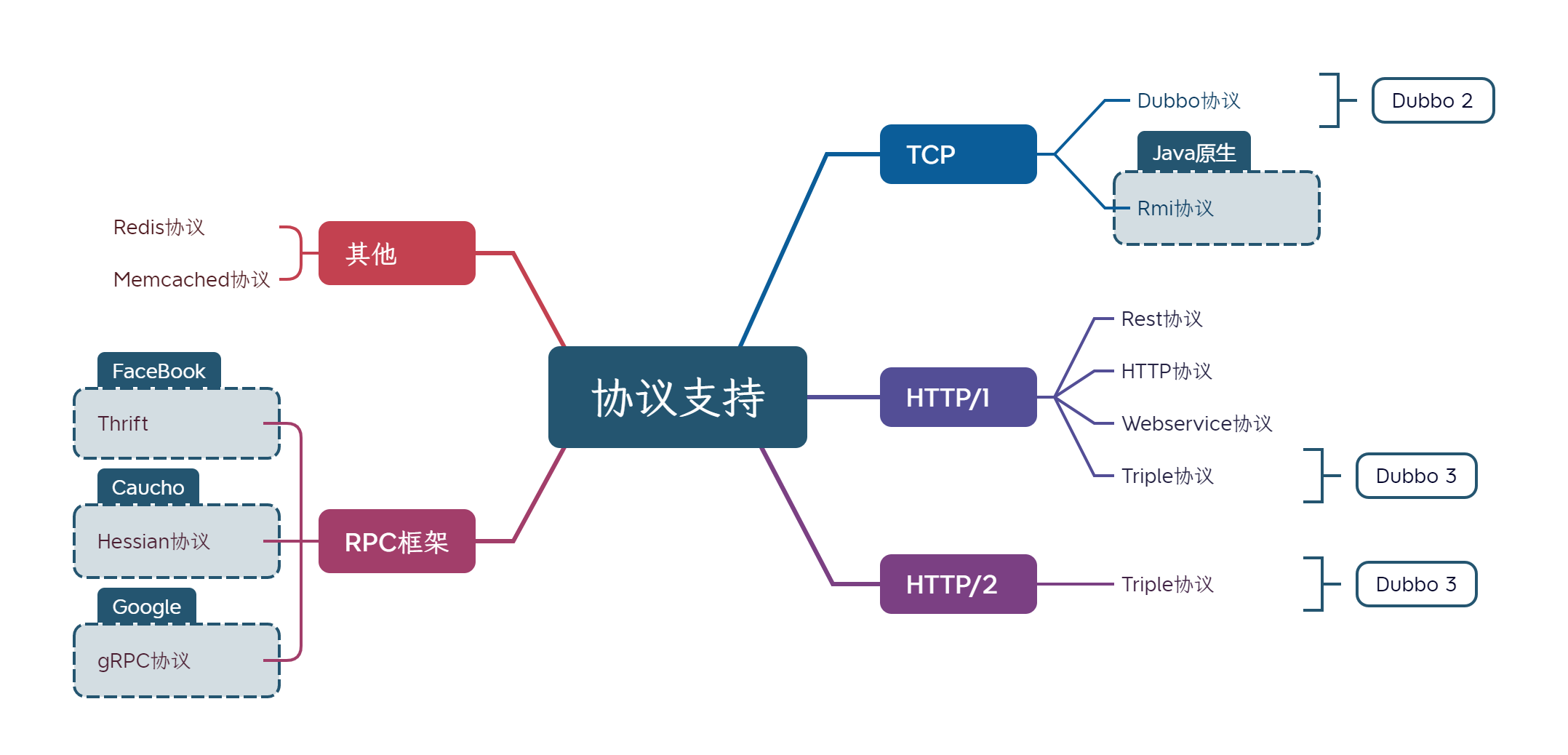
最近公司在搞新项目,由于是实验性质,且不会直接面对客户的项目,这次的技术选型非常激进,如,直接使用了Java 17。
作为公司里练习两年半的个人练习生,我自然也是深度的参与到了技术选型的工作中。不知道大家在技术选型中有没有关注过技术组件给出的基准测试?比如说,HikariCP的基准测试:

又或者是Caffeine的基准测试:

如果你仔细阅读过它们的基准测试报告,你会发现一项很有意思的技术:Java Microbenchmark Harness,简称JMH。
Tips:有些技术只需要学会如何使用即可,没有必要非得“卷”源码;有些“小众”技术你没有听过,也不必慌,没有人是什么都会的。
认识JMH
接触JMH之前,我通常用System.currentTimeMillis()来计算方法的执行时间:
long start = System.currentTimeMillis();
......
long duration = System.currentTimeMillis() - start;大部分时候这么做都很灵,但某些场景下JVM会进行JIT编译和内联优化,导致代码在优化前后的执行效率差别非常大,此时这个“土”方法就不灵了。那么该如何准确的计算方法的执行时间呢?
Java团队为开发者提供了JMH基准测试套件:
JMH is a Java harness for building, running, and analysing nano/micro/milli/macro benchmarks written in Java and other languages targeting the JVM.
JMH是用于构建,运行和分析Java和其它基于JVM的语言编写的程序的基准测试套件。JMH提供了预热的能力,通过预热让JVM知道哪些是热点代码,除此之外,JMH还提供了吞吐量的测试指标。相较于“土”方法,JMH可以支持更多种的测试场景,而且基于JMH得出的测试结果也会更全面,更准确。
使用JMH
项目中引入JMH的依赖:
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.36</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.36</version>
</dependency>引入依赖后就可以编写一个简单的基准测试了,这里使用简化后的JMH官方示例:
package org.openjdk.jmh.samples;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
public class JMHSample_02_BenchmarkModes {
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public void measureAvgTime() throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(100);
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(JMHSample_02_BenchmarkModes.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
}执行这个示例,会输出如下结果:
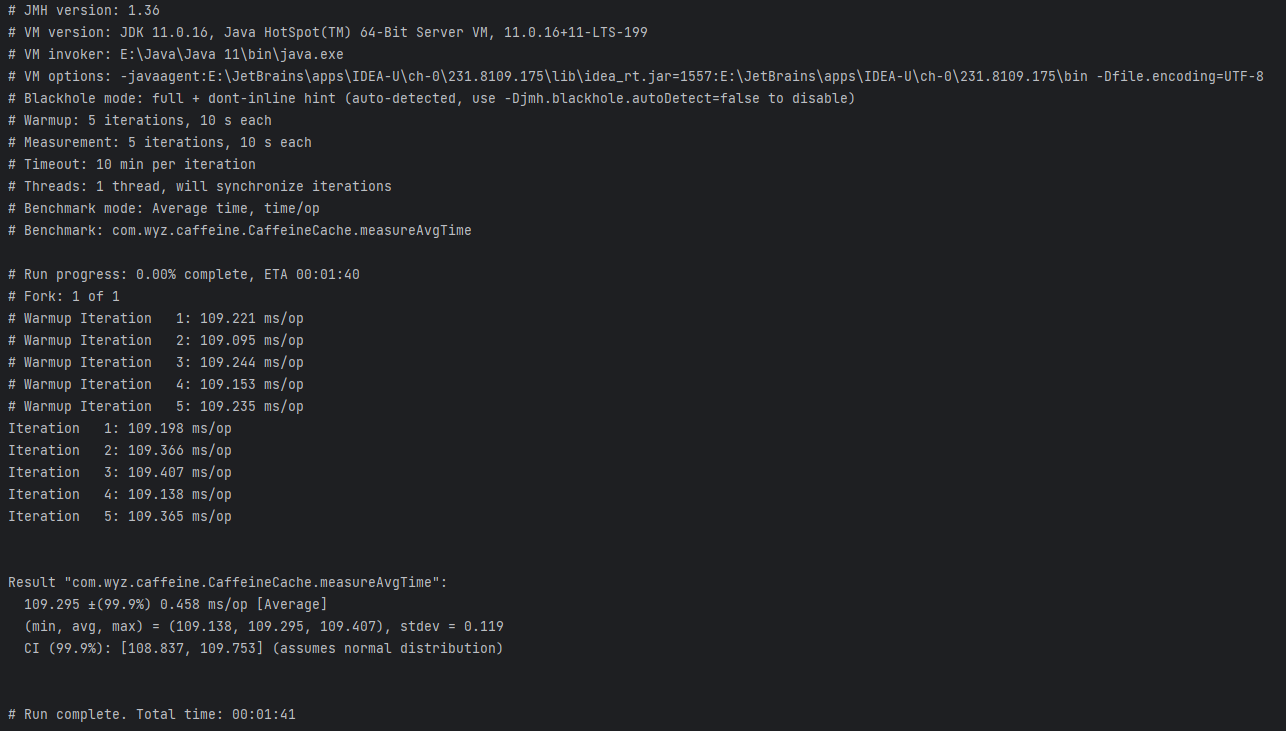
以空行为分割的话,JMH的输出可以分为3个部分:
- 基础信息,包括环境信息和基准测试配置;
- 测试信息,每次预热(Warmup)和正式执行(Iteration)的信息;
- 结果信息,基准测试的结果。
Tips:
- IDEA中不能使用DeBug模式运行,否则会报错;
- 注意依赖中的scope标签为test,在src\main\java路径下是无法访问到JMH的。
启动测试
从示例中不难发现,在IDEA中执行测试需要先构建Options,并通过Runner去执行。我们来构建一个最简单的Options:
Options opt = new OptionsBuilder().build();
new Runner(opt).run();这样的Options会执行散落在程序各处的基准测试方法(使用Benchmark注解的方法)。如果不需要执行所有的基准测试方法,通常在构建Options时会指定测试的范围:
Options opt = new OptionsBuilder().include(JMHSample_02_BenchmarkModes.class.getSimpleName()).build();这时基准测试仅限于Test类中的基准测试方法。除此之外,你可能还会嫌弃控制台输出样式丑陋,或者要提交的基准测试报告中需要用图示来直观的表达,这个时候可以控制输出结果的格式并指定结果输出文件:
Options opt = new OptionsBuilder()
.include(JMHSample_02_BenchmarkModes.class.getSimpleName())
.result("result.json")
.resultFormat(ResultFormatType.JSON)
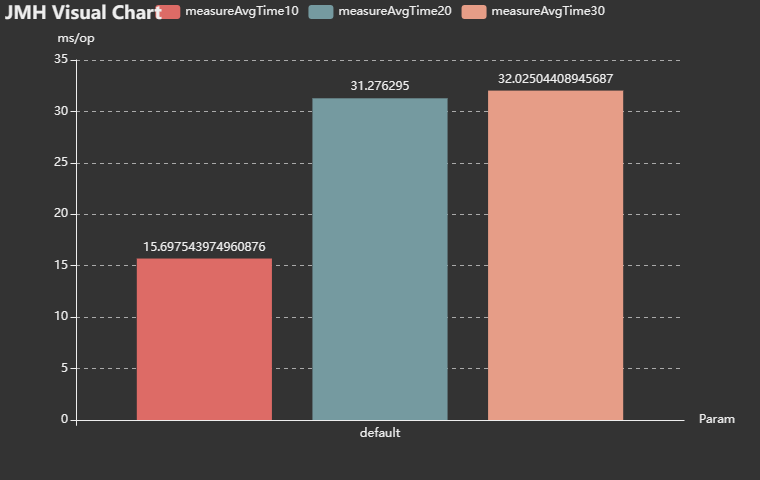
.build();再结合以下网站,可以很轻松的构建出测试结果图示:
- JMH Visual Chart (deepoove.com)
- JMH Visualizer (morethan.io)
例如,我通过JMH Visual Chart构建出的测试结果:
实际上,OptionsBuilder提供的功能远不止如此,不过其中大部分功能都可以通过下文中提到注解进行配置,在此就不进行多余的说明了。
常用注解
JMH可以通过注解非常简单的完成基准测试的配置,接下来对其中常用的15个注解进行详细说明。
注解:Benchmark
注解Benchmark的声明:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Benchmark {
}Benchmark用于方法上且该方法必须使用public修饰,表明该方法为基准测试方法。
注解:BenchmarkMode
注解BenchmarkMode的声明:
@Inherited
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface BenchmarkMode {
Mode[] value();
}BenchmarkMode用于方法或类上,表明测试指标。枚举类Mode提供了4种测试指标:
- Mode.Throughput,吞吐量,单位时间内执行的次数;
- Mode.AverageTime,平均时间,执行方法的平均耗时;
- Mode.SampleTime,操作时间采样,并输出结果分布;
- Mode.SingleShotTime,单次操作时间,通常在不进行预热时测试冷启动的时间。
我们来看下Mode.SampleTime的输出结果:

除单独使用以上测试指标外,还可以指定Mode.All进行全部指标的基准测试。
注解:OutputTimeUnit
注解OutputTimeUnit的声明:
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface OutputTimeUnit {
TimeUnit value();
}OutputTimeUnit用于方法或类上,表明输出结果的时间单位。好了,示例中的注解我们已经了解完毕,接下来我们看其它较为关键的注解。
注解:Timeout
注解Timeout的声明:
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface Timeout {
int time();
TimeUnit timeUnit() default TimeUnit.SECONDS;
}Timeout用于方法或类上,指定了基准测试方法的超时时间。
注解:Warmup
注解Warmup的声明:
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface Warmup {
int BLANK_ITERATIONS = -1;
int BLANK_TIME = -1;
int BLANK_BATCHSIZE = -1;
int iterations() default BLANK_ITERATIONS;
int time() default BLANK_TIME;
TimeUnit timeUnit() default TimeUnit.SECONDS;
int batchSize() default BLANK_BATCHSIZE;
}Warmup用于方法或类上,用于做预热配置。提供了4个参数:
- iterations,预热迭代的次数;
- time,每个预热迭代的时间;
- timeUnit,时间单位;
- batchSize,每个操作调用的次数。
预热的执行结果并不会被统计到测试结果中,因为JIT机制的存在某些方法被反复调用后,JVM会将其编译为机器码,使其执行效率大大提高。
注解:Measurement
注解Measurement的声明:
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Measurement {
int BLANK_ITERATIONS = -1;
int BLANK_TIME = -1;
int BLANK_BATCHSIZE = -1;
int iterations() default BLANK_ITERATIONS;
int time() default BLANK_TIME;
TimeUnit timeUnit() default TimeUnit.SECONDS;
int batchSize() default BLANK_BATCHSIZE;
}Measurement与Warmup的使用方法完全一致,参数含义也完全相同,区别在于Measurement属于正式测试的配置,结果会被统计。
注解:Group
注解Group的声明:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Group {
String value() default "group";
}Group用于方法上,为测试方法分组。
注解:State
注解State的声明:
@Inherited
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface State {
Scope value();
}State用于类上,表明了类中变量的作用范围。枚举类Scope提供了3种作用域:
- Scope.Benchmark,每个测试方法中使用一个变量;
- Scope.Group,每个分组中使用同一个变量;
- Scope.Thread,每个线程中使用同一个变量。
忘记了是在哪看到有人说Scope.Benchmark的作用域是所有的基准测试方法,这个是错误的,Scope.Benchmark会为每个基准测试方法生成一个对象,例如:
@State(Scope.Benchmark)
public static class ThreadState {
}
@Benchmark
@BenchmarkMode(Mode.SingleShotTime)
public void test1(State state) {
System.out.println("test1执行" + VM.current().addressOf(state));
}
@Benchmark
@BenchmarkMode(Mode.SingleShotTime)
public void test2(State state) {
System.out.println("test2执行" + VM.current().addressOf(state));
}这个例子中,test1和test2使用的是不同的State对象。
Tips:VM.current().addressOf()是jol-core中提供的功能。
注解:Setup
注解Setup的声明:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Setup {
Level value() default Level.Trial;
}Setup用于方法上,基准测试前的初始化操作。枚举类Level提供了3个级别:
- Level.Trial,所有基准测试执行时;
- Level.Iteration,每次迭代时;
- Level.Invocation,每次方法调用时。
Tips:一次迭代中,可能会出现多次方法调用。
注解:TearDown
注解TearDown的声明:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TearDown {
Level value() default Level.Trial;
}TearDown用于方法上,与Setup的作用相反,是基准测试后的操作,同样使用Level提供了3个级别。
注解:Param
注解Param的声明:
@Inherited
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface Param {
String BLANK_ARGS = "blank_blank_blank_2014";
String[] value() default { BLANK_ARGS };
}Param用于字段上,用于指定不同的参数,需要搭配State注解来使用。举个例子:
@State(Scope.Benchmark)
public class Test {
@Param({"10", "100", "1000", "10000"})
int count;
@Benchmark
@Warmup(iterations = 0)
@BenchmarkMode(Mode.SingleShotTime)
public void loop() throws InterruptedException {
for(int i = 0; i < count; i++) {
TimeUnit.MILLISECONDS.sleep(1);
}
}
}上述代码测试了程序在循环10次,100次,1000次和10000次时的性能。
注解:Threads
注解Threads的声明:
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Threads {
int MAX = -1;
int value();
}Threads用于方法和类上,指定基准测试中的并行线程数。当使用MAX时,将会使用所有可用线程进行测试,即Runtime.getRuntime().availableProcessors()返回的线程数。
注解:GroupThreads
注解GroupThreads的声明:
@Inherited
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface GroupThreads {
int value() default 1;
}GroupThreads用于方法上,指定基准测试分组中使用的线程数。
注解:Fork
注解Fork的声明:
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Fork {
int BLANK_FORKS = -1;
String BLANK_ARGS = "blank_blank_blank_2014";
int value() default BLANK_FORKS;
int warmups() default BLANK_FORKS;
String jvm() default BLANK_ARGS;
String[] jvmArgs() default { BLANK_ARGS };
String[] jvmArgsPrepend() default { BLANK_ARGS };
String[] jvmArgsAppend() default { BLANK_ARGS };
}Fork用于方法和类上,指定基准测试中Fork的子进程。Fork提供了6个参数:
- value,表示Fork出的子进程数量;
- warmups,预热次数;
- jvm,JVM的位置;
- jvmArgs,需要替换的JVM参数;
- jvmArgsPrepend,需要添加的JVM参数;
- jvmArgsAppend,需要追加的JVM参数。
将Fork设置为0时,JMH会在当前JVM中运行基准测试。由于可能处于用户的JVM中,无法反应真实的服务端场景,无法准确的反应实际性能,因此JMH推荐进行Fork设置。
另外可以利用Fork提供的JVM设置,将JVM设置为Server模式:
@Fork(value = 1, jvmArgsAppend = {"-Xmx1024m", "-server"})注解:CompilerControl
注解CompilerControl的声明:
@Target({ElementType.METHOD, ElementType.CONSTRUCTOR, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface CompilerControl {
Mode value();
enum Mode {
BREAK("break"),
PRINT("print"),
EXCLUDE("exclude"),
INLINE("inline"),
DONT_INLINE("dontinline"),
COMPILE_ONLY("compileonly");
}
}CompilerControl用于方法,构造器或类上,指定编译方式。其内部枚举类提供了6种编译方式:
- BREAK,将断点插入到编译后的代码;
- PRINT,打印方法及其配置;
- EXCLUDE,禁止编译;
- INLINE,使用内联;
- DONT_INLINE,禁止内联;
- COMPILE_ONLY,仅编译。
结语
关于JMH的使用,我们就聊到这里了,希望今天的内容能够帮助你学习并掌握一种更准确的性能测试方法。
最后提供一个练习使用JMH的思路:大家都看到了文章开头Caffeine给出的基准测试结果了,但由于是Caffeine作者自己提供的基准测试,难免有些“既当裁判又当选手”的嫌疑,或者说他选取了一些对Caffeine有利的角度来展示结果,那么可以结合你自己的实际使用场景,给Caffeine及其竞品做一次基准测试。
如果本文对你有帮助的话,还请多多点赞支持。如果文章中出现任何错误,还请批评指正。最后欢迎大家关注分享硬核Java技术的金融摸鱼侠王有志,我们下次再见!