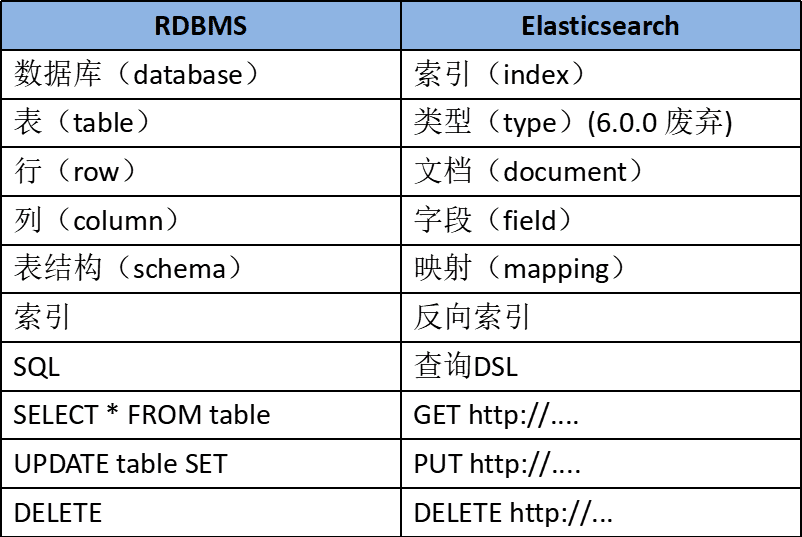
C/C++编程(1~8级)全部真题・点这里
第1题:红与黑
有一间长方形的房子, 地上铺了红色、 黑色两种颜色的正方形瓷砖。你站在其中一块黑色的瓷砖上, 只能向相邻的黑色瓷砖移动。 请写一个程序, 计算你总共能够到达多少块黑色的瓷砖。
时间限制: 1000
内存限制: 65536
输入
包括多个数据集合。 每个数据集合的第一行是两个整数 W 和 H, 分别表示 x 方向和 y 方向瓷砖的数量。 W 和 H 都不超过 20。 在接下来的 H 行中, 每行包括 W 个字符。 每个字符表示一块瓷砖的颜色, 规则如下
1)‘.’: 黑色的瓷砖;
2)‘#’: 白色的瓷砖;
3)‘@’: 黑色的瓷砖, 并且你站在这块瓷砖上。 该字符在每个数据集合中唯一出现一次。 当在一行中读入的是两个零时, 表示输入结束。
输出
对每个数据集合, 分别输出一行, 显示你从初始位置出发能到达的瓷砖数(记数时包括初始位置的瓷砖)。
样例输入
6 9
…#.
…#
…
…
…
…
…
#@…#
.#…#.
0 0
样例输出
45
下面是一个使用C语言编写的解决方案,根据题目描述,使用深度优先搜索算法来遍历所有相邻的黑色瓷砖。
#include <stdio.h>
#define MAX_W 20
#define MAX_H 20
int W, H; // 瓷砖的宽度和高度
char tiles[MAX_H][MAX_W]; // 瓷砖的颜色
int visited[MAX_H][MAX_W]; // 记录是否访问过
int dx[] = {1, -1, 0, 0}; // x 方向的偏移量
int dy[] = {0, 0, 1, -1}; // y 方向的偏移量
int count; // 计数器
void dfs(int x, int y) {
visited[x][y] = 1; // 标记为已访问
count++; // 计数器加一
int i;
for (i = 0; i < 4; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
// 判断相邻瓷砖是否在范围内且为黑色且未访问过
if (nx >= 0 && nx < H && ny >= 0 && ny < W && tiles[nx][ny] == '.' && !visited[nx][ny]) {
dfs(nx, ny); // 递归调用
}
}
}
int main() {
while (1) {
scanf("%d %d", &W, &H);
if (W == 0 && H == 0) break; // 输入为0 0时结束
int i, j;
int startX, startY; // 初始位置坐标
// 读取瓷砖颜色并找到初始位置
for (i = 0; i < H; i++) {
for (j = 0; j < W; j++) {
scanf(" %c", &tiles[i][j]);
visited[i][j] = 0; // 初始化visited数组
if (tiles[i][j] == '@') {
startX = i;
startY = j;
}
}
}
count = 0; // 初始化计数器
dfs(startX, startY); // 开始深度优先搜索
printf("%d\n", count);
}
return 0;
}
这个程序使用深度优先搜索算法来遍历所有相邻的黑色瓷砖。首先,我们读取输入的瓷砖颜色,并找到初始位置。然后,我们使用递归的深度优先搜索函数dfs来遍历与当前位置相邻的黑色瓷砖。在搜索过程中,我们使用visited数组来记录已经访问过的瓷砖,避免重复访问和陷入死循环。最后,我们输出计数器count的值,即从初始位置出发能够到达的瓷砖数。
请注意,这个程序假设输入的数据是合法的,即初始位置@在每个数据集合中唯一出现一次,并且输入的瓷砖数量不超过20。在实际应用中,你可能需要添加一些错误处理的代码来处理异常情况。
第2题:迷宫问题
定义一个二维数组:
int maze[5][5] = {
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
它表示一个迷宫, 其中的 1 表示墙壁, 0 表示可以走的路, 只能横着走或竖着走, 不能斜着走, 要求编程序找出从左上角到右下角的最短路线。
时间限制: 1000
内存限制: 65536
输入
一个 5 × 5 的二维数组, 表示一个迷宫。 数据保证有唯一解。
输出
左上角到右下角的最短路径, 格式如样例所示。
样例输入
0 1 0 0 0
0 1 0 1 0
0 0 0 0 0
0 1 1 1 0
0 0 0 1 0
样例输出
(0, 0)
(1, 0)
(2, 0)
(2, 1)
(2, 2)
(2, 3)
(2, 4)
(3, 4)
(4, 4)
下面是一个使用C语言编写的解决方案,使用广度优先搜索算法来找到从左上角到右下角的最短路径。
#include <stdio.h>
#include <stdbool.h>
#define ROWS 5
#define COLS 5
typedef struct {
int row;
int col;
} Point;
Point queue[ROWS * COLS]; // 队列,用于广度优先搜索
int front, rear; // 队列的前后指针
int maze[ROWS][COLS] = {
{0, 1, 0, 0, 0},
{0, 1, 0, 1, 0},
{0, 0, 0, 0, 0},
{0, 1, 1, 1, 0},
{0, 0, 0, 1, 0}
};
bool visited[ROWS][COLS]; // 记录是否访问过
Point prev[ROWS][COLS]; // 记录路径上各点的前驱点
int dx[] = {0, 1, 0, -1}; // x 方向的偏移量
int dy[] = {-1, 0, 1, 0}; // y 方向的偏移量
void enqueue(Point p) {
queue[rear++] = p;
}
Point dequeue() {
return queue[front++];
}
bool isQueueEmpty() {
return front == rear;
}
void printPath(Point p) {
if (p.row == 0 && p.col == 0) {
printf("(%d, %d)\n", p.row, p.col);
return;
}
printPath(prev[p.row][p.col]);
printf("(%d, %d)\n", p.row, p.col);
}
void bfs() {
Point start = {0, 0};
Point end = {ROWS - 1, COLS - 1};
front = rear = 0; // 初始化队列
enqueue(start);
visited[start.row][start.col] = true;
while (!isQueueEmpty()) {
Point current = dequeue();
if (current.row == end.row && current.col == end.col) {
printPath(current);
return;
}
int i;
for (i = 0; i < 4; i++) {
int newRow = current.row + dy[i];
int newCol = current.col + dx[i];
if (newRow >= 0 && newRow < ROWS && newCol >= 0 && newCol < COLS &&
maze[newRow][newCol] == 0 && !visited[newRow][newCol]) {
Point next = {newRow, newCol};
enqueue(next);
visited[newRow][newCol] = true;
prev[newRow][newCol] = current;
}
}
}
}
int main() {
bfs();
return 0;
}
这个程序使用广度优先搜索算法来找到从左上角到右下角的最短路径。首先,我们定义了一个点的结构体Point,用于表示迷宫中的坐标。然后,我们定义了一个队列queue,用于广度优先搜索。我们使用visited数组来记录已经访问过的点,避免重复访问。prev数组用于记录路径上各点的前驱点,以便最后打印出最短路径。
在bfs函数中,我们使用队列来进行广度优先搜索。我们从起点开始,将其入队,并标记为已访问。然后,我们循环执行以下步骤,直到队列为空或者找到终点:
-
出队一个点,记为
current。 -
如果
current是终点,说明已经找到最短路径,打印出路径并返回。 -
否则,对
current的四个相邻点进行判断:- 如果相邻点在迷宫范围内、为可通行的路且未访问过,将其入队,并标记为已访问。同时,记录该相邻点的前驱点为
current。
- 如果相邻点在迷宫范围内、为可通行的路且未访问过,将其入队,并标记为已访问。同时,记录该相邻点的前驱点为
最后,在main函数中调用bfs函数进行搜索,并输出最短路径。
第3题:二叉树的深度
给定一棵二叉树, 求该二叉树的深度
二叉树深度定义: 从根结点到叶结点依次经过的结点(含根、叶结点)
形成树的一条路径, 最长路径的节点个数为树的深度
时间限制: 1000
内存限制: 65535
输入
第一行是一个整数 n, 表示二叉树的结点个数。 二叉树结点编号从 1到 n, 根结点为 1, n <= 10 接下来有 n 行, 依次对应二叉树的 n 个节点。 每行有两个整数, 分别表示该节点的左儿子和右儿子的节点编号。 如果第一个(第二个) 数为-1 则表示没有左(右) 儿子
输出
输出一个整型数, 表示树的深度
样例输入
3
2 3
-1 -1
-1 -1
样例输出
2
下面是一个使用C语言编写的解决方案,使用递归方法来求解二叉树的深度。
#include <stdio.h>
typedef struct TreeNode {
int val;
struct TreeNode* left;
struct TreeNode* right;
} TreeNode;
int maxDepth(struct TreeNode* root) {
if (root == NULL) {
return 0;
}
int leftDepth = maxDepth(root->left);
int rightDepth = maxDepth(root->right);
return (leftDepth > rightDepth) ? leftDepth + 1 : rightDepth + 1;
}
int main() {
int n;
scanf("%d", &n);
TreeNode* nodes[n];
int i;
for (i = 0; i < n; i++) {
nodes[i] = (TreeNode*)malloc(sizeof(TreeNode));
nodes[i]->val = i + 1;
nodes[i]->left = NULL;
nodes[i]->right = NULL;
}
for (i = 0; i < n; i++) {
int left, right;
scanf("%d %d", &left, &right);
if (left != -1) {
nodes[i]->left = nodes[left - 1];
}
if (right != -1) {
nodes[i]->right = nodes[right - 1];
}
}
int depth = maxDepth(nodes[0]);
printf("%d\n", depth);
return 0;
}
这个程序使用了递归方法来求解二叉树的深度。首先,我们定义了一个结构体TreeNode来表示二叉树的节点。每个节点包含一个值val,以及左右子节点的指针left和right。然后,我们定义了一个递归函数maxDepth,用于计算二叉树的深度。
在maxDepth函数中,我们首先判断当前节点是否为空。如果为空,说明到达了叶节点,返回深度0。否则,我们递归调用maxDepth函数来计算左子树和右子树的深度,然后将左右子树中较大的深度加1作为当前节点的深度,并返回该值。
在main函数中,我们首先读取输入的节点个数n。然后,我们根据节点个数创建节点数组nodes,并初始化每个节点的值和指针。接下来,我们按照输入的节点信息构建二叉树,将节点的左右子节点指向对应的节点。最后,我们调用maxDepth函数计算二叉树的深度,并将结果输出。
第4题:表达式· 表达式树· 表达式求值
众所周知, 任何一个表达式, 都可以用一棵表达式树来表示。 例如,
表达式 a+b*c, 可以表示为如下的表达式树:
+
/ \
a *
/ \
b c
现在, 给你一个中缀表达式, 这个中缀表达式用变量来表示(不含数字), 请你将这个中缀表达式用表达式二叉树的形式输出出来。
时间限制: 1000
内存限制: 65535
输入
输入分为三个部分。 第一部分为一行, 即中缀表达式(长度不大于 50)。
中缀表达式可能含有小写字母代表变量(a-z), 也可能含有运算符(+、-、 *、 /、 小括号), 不含有数字, 也不含有空格。 第二部分为一个整数 n(n < 10), 表示中缀表达式的变量数。 第三部分有 n 行, 每行格式为 C x, C 为变量的字符, x 为该变量的值。
输出
输出分为三个部分, 第一个部分为该表达式的逆波兰式, 即该表达式树的后根遍历结果。 占一行。 第二部分为表达式树的显示, 如样例输出所示。 如果该二叉树是一棵满二叉树, 则最底部的叶子结点, 分别占据横坐标的第 1、 3、 5、 7……个位置(最左边的坐标是 1), 然后它们的父结点的横坐标, 在两个子结点的中间。 如果不是满二叉树,则没有结点的地方, 用空格填充(但请略去所有的行末空格)。 每一行父结点与子结点中隔开一行, 用斜杠(/) 与反斜杠(\) 来表示树的关系。 /出现的横坐标位置为父结点的横坐标偏左一格, \出现的横坐标位置为父结点的横坐标偏右一格。 也就是说, 如果树高为 m, 则输出就有 2m-1 行。 第三部分为一个整数, 表示将值代入变量之后,该中缀表达式的值。 需要注意的一点是, 除法代表整除运算, 即舍弃小数点后的部分。 同时, 测试数据保证不会出现除以 0 的现象。
样例输入
a+b*c
3
a 2
b 7
c 5
样例输出
abc*+
+
/ \
a *
/ \
b c
37
以下是一个使用C语言编写的解决方案,实现了将中缀表达式转换为表达式树的功能:
#include <stdio.h>
#include <stdlib.h>
struct Node {
char data;
struct Node* left;
struct Node* right;
};
// 创建一个新的表达式树结点
struct Node* createNode(char data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
// 判断一个字符是否是运算符
int isOperator(char c) {
if (c == '+' || c == '-' || c == '*' || c == '/')
return 1;
return 0;
}
// 构建表达式树
struct Node* buildExpressionTree(char* infixExpression, int* index) {
struct Node* root = NULL;
if (isOperator(infixExpression[*index])) {
root = createNode(infixExpression[*index]);
(*index)++;
root->left = buildExpressionTree(infixExpression, index);
(*index)++;
root->right = buildExpressionTree(infixExpression, index);
} else {
root = createNode(infixExpression[*index]);
}
return root;
}
// 后根遍历表达式树,得到逆波兰式
void postOrderTraversal(struct Node* root) {
if (root == NULL)
return;
postOrderTraversal(root->left);
postOrderTraversal(root->right);
printf("%c", root->data);
}
// 打印表达式树
void printExpressionTree(struct Node* root, int space) {
if (root == NULL)
return;
space += 4;
printExpressionTree(root->right, space);
printf("\n");
for (int i = 4; i < space; i++)
printf(" ");
printf("%c\n", root->data);
printExpressionTree(root->left, space);
}
// 获取变量对应的值
int getVariableValue(char variable, char* variables, int* values, int numVariables) {
for (int i = 0; i < numVariables; i++) {
if (variables[i] == variable)
return values[i];
}
return 0;
}
// 计算表达式树的值
int evaluateExpressionTree(struct Node* root, char* variables, int* values, int numVariables) {
if (root == NULL)
return 0;
if (!isOperator(root->data))
return getVariableValue(root->data, variables, values, numVariables);
int leftValue = evaluateExpressionTree(root->left, variables, values, numVariables);
int rightValue = evaluateExpressionTree(root->right, variables, values, numVariables);
switch (root->data) {
case '+':
return leftValue + rightValue;
case '-':
return leftValue - rightValue;
case '*':
return leftValue * rightValue;
case '/':
return leftValue / rightValue; // 整除运算
}
return 0;
}
int main() {
char infixExpression[51];
int numVariables;
// 读取输入
scanf("%s", infixExpression);
scanf("%d", &numVariables);
char variables[10];
int values[10];
// 读取变量及其值
for (int i = 0; i < numVariables; i++) {
scanf(" %c %d", &variables[i], &values[i]);
}
int index = 0;
struct Node* root = buildExpressionTree(infixExpression, &index);
// 输出逆波兰式
postOrderTraversal(root);
printf("\n");
// 输出表达式树
printExpressionTree(root, 0);
// 计算表达式的值
int result = evaluateExpressionTree(root, variables, values, numVariables);
printf("%d\n", result);
return 0;
}
请注意,上述代码假设输入的中缀表达式是合法的,并且变量的个数不超过10。同时,代码中使用了递归的方式构建表达式树,并通过后根遍历打印逆波兰式,使用中序遍历打印表达式树,并计算表达式的值。