LRU(Least Recently Use)算法,是用来判断一批数据中,最近最少使用算法。它底层数据结构由Hash和链表结合实现,使用Hash是为了保障查询效率为O(1),使用链表保障删除元素效率为O(1)。
LRU算法是用来判断最近最少使用到元素,常被用在缓存中数据清理、内存淘汰相关的场景,它底层是由Hash表和双向链表构成,Hash主要用来存储key和指向链表节点的指针,双向链表就是用来实现最近最少使用算法的数据结构,新访问的元素会加入到头部或者尾部(就看最终从哪个反向取了,我们这里定为头部),如果是已经访问的元素,并不会新添加到链表中,而是将链表中原来存在的这个节点移动到头部,最终链表中越靠近尾部的元素,代表最近最少使用的元素。
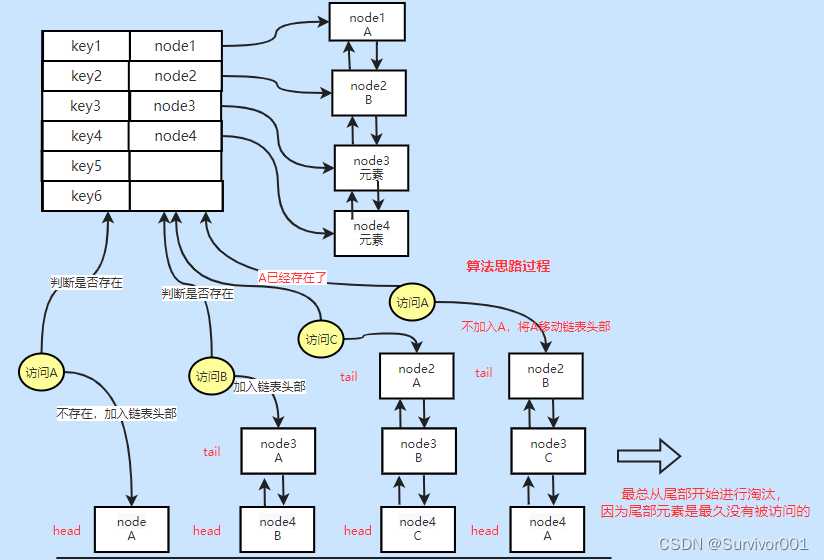
为什么要额外组合使用Hash和链表?单个数据结构也能完成不是吗?
为了提交效能,Hash的优势是查找元素为O(1),但是移动元素是O(n),链表查找元素复杂度是O(n),但是移动元素复杂度是O(1),所以为了提高效率,结构两种数据结构各自的优势,利用Hash的O(1),来查找元素是否存在,利用链表的O(1)来移动元素位置。
Redis近似LRU算法
什么是Redis近似LRU算法,为什么Redis不直接使用LRU算法?
近似LRU算法是Redis采用LRU算法思想,实现一个近似LRU的算法,在原LRU算法中需要维护一个Hash和链表,而Redis本身可以理解为一个大的字典,那就需要额外的去维护一个链表数据结构,Redis本身就是要经受大量数据的冲击的,所以这个链表将会占用更大的内存。Redis的宗旨就是高效,所以它没有使用这样的一个链表。它的做法如下:

Redis最开始的做法:
1、当设置了LRU回收策略之后,对元素进行访问时,会调用一次server.lruclock方法,获取Redis时钟时间戳(redis时钟默认1毫秒更新一次)并进行取模(防止时间戳递增,最后超过了24bit),记录在元素value中lru属性中。
2、当内存达到maxmemory时,会随机抽取5(可以通过maxmemory-policy设定)个样本key进行时间戳判断,淘汰时间戳最小的(也就是最久远的一个key)
优点:不用额外的维护一个链表,节省了内存,同时随机采样淘汰方式也避免了大数据量key遍历处理的耗时。
缺点:因为是随机采样删除,所以会出现更早key迟迟没有被采样删除的情况。钉子户。
Redis3.0 做了LRU算法升级
Redis在3.0之后对LRU算法做了升级,加入了候选池Pool(16字节),首次抽样5个会放入都Pool中,并按照时间大小lru排序,后续每次选取的Key的lru必须要小于pool的最小值(也就是key要比pool中的更早),才放入pool中,直到pool满,当有新元素加入时,只需要将pool中最万的key(也就是最大的)删除即可。
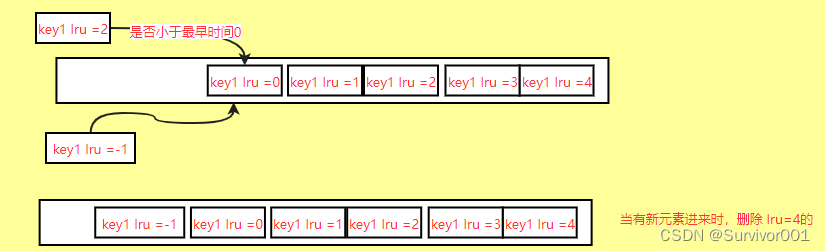
升级之后的算法,可以更大密度的将更久没有使用的key删除,减少了钉子户的存在。
RedisLFU算法
在Redis4.0 推出了LFU算法,这个是基于访问次数维护的回收算法,算法和LRU差不多,就是在lru中加入了请求次数的计数count维护。从时间和频次两个维度来计算key的热度。他的好处是,如果一个key很就没有被访问到,突然最近被访问了一次,在LRU算法中,它是不容易被淘汰的,但是在LRF算法中,会统计它访问频次,发现不足定位很热的key,所以还是会被删除。所以LFU算法很适合用于热点数据的删除策略。