目录
- 一、什么是缓存
- 缓存的优缺点
- 缓存的优点
- 缓存的缺点
- 二、Redis缓存
- 三、缓存的更新策略
- 主动更新策略
- 四、缓存穿透
- 解决方案
- 五、缓存雪崩
- 解决方案
- 六、缓存击穿
- 解决方案
一、什么是缓存
我们都知道在计算机中内存的速度比磁盘要快非常多,如果每次都要去磁盘获取数据,是不是每次的速度都很慢。如果有一个数据是我们要经常使用的,如果每次都从磁盘获取数据,那速度是每次都是那么慢。所以就想到是不是可以把数据放到内存中,这样在第一次获取之后将数据存放在内存中,这样速度就快很多。
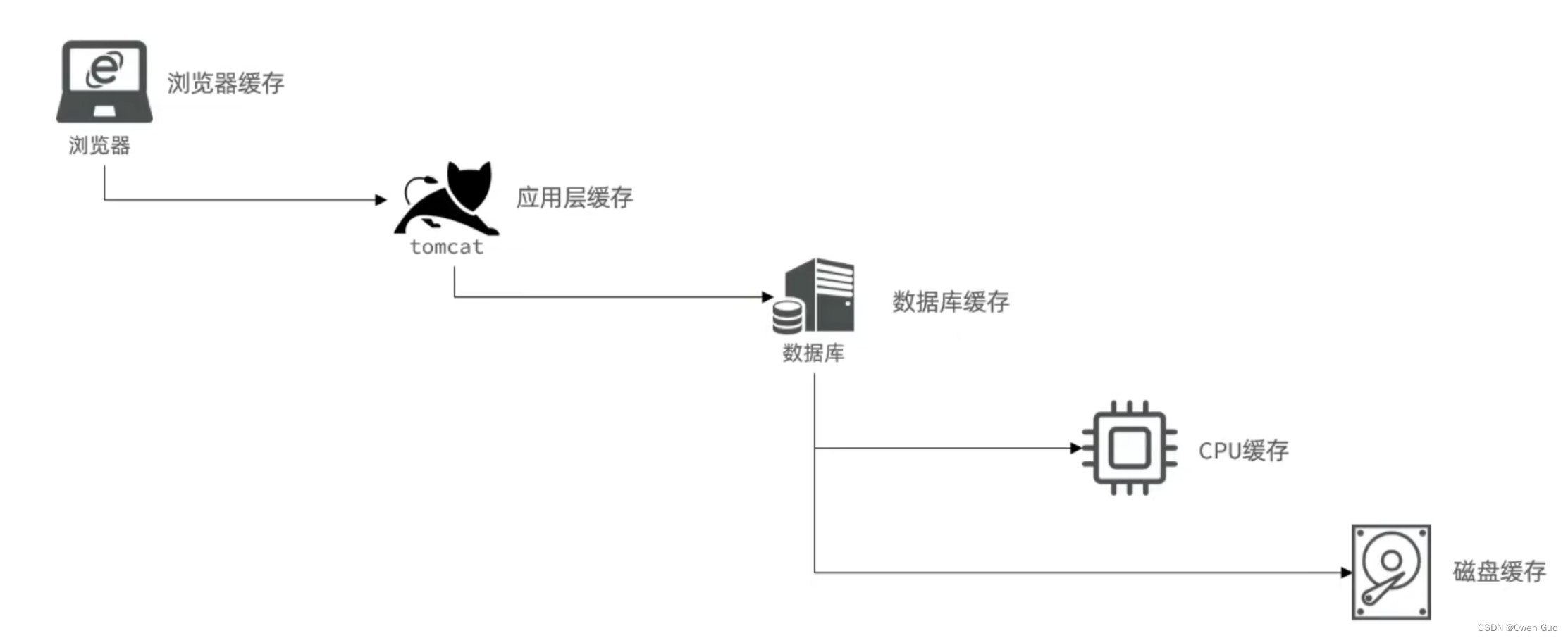
现在的计算机世界中到处都用到了缓存技术。并且缓存也不一定是要放在速度快的介质中才是缓存,应该是只要能提升速度的方法都可以称作缓存,例如一个文件非常大,每次查询一条一条遍历下去很慢,是不是可以把常用的记录单独存放在一个文件中,这样每次先查这个缓存文件就可以大大提高性能。
缓存的优缺点
缓存既然可以大大提升性能,那是不是什么都可以使用缓存?
凡事都是有优缺点的,缓存也不例外,如果他的缺点我们可以接受,那缓存就是适合的技术。
缓存的优点
- 降低后端负载
例如:后端数据库可以可以接受的请求是有一定的瓶颈的,请求太多就会导致服务无法处理后续的请求,如果有些数据可以直接放在客户端,那用户就不需要请求服务器了。 - 提高读写效率、降低相应时间
例如:有些数据是非常常用的数据,如果每次都要去磁盘找这些数据,那速度是一致的,非常慢。但其实可以将这些常用数据放在缓存中,每次先从缓存中找,就可以提升大多数请求的性能。
缓存的缺点
- 数据一致性问题
例如:缓存往往都是将数据复制了一份放在缓存中的,用户看到的都是复制的数据,如果原数据更新了,复制的数据不能及时同步,导致原数据和缓存数据不一致 - 代码维护成本变高
例如:有了缓存就要维护缓存,每次查询都要先查缓存再查磁盘,也要判断要不要维护缓存数据等各种情况 - 运维难度变高
例如:使用Redis缓存,运维就要保证Redis应用不能宕机,否则就要重大事故等
二、Redis缓存
Redis应用是一个基于内存的NoSQL数据库,它具有非常高的读写性能,所以在Web应用开发中非常适合用来做缓存,去承接高并发的用户请求。
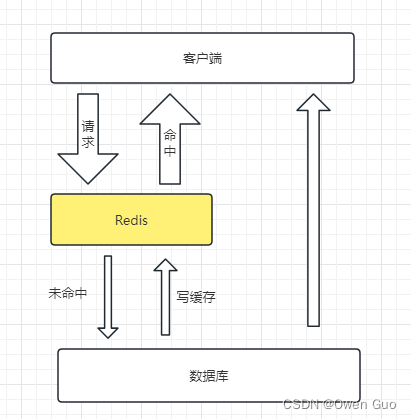
例如上面这样典型的业务场景,客户端的请求先请求Redis,如果查询到数据了则直接返回,如果没有查询到数据,则查询数据,然后将数据放到Redis缓存中并返回给客户端。
三、缓存的更新策略
前面分析到缓存是有数据一致性的问题的,所以使用缓存的数据要是那些更新频率不高的数据,否则维护缓存的成本将会变高,使用缓存也就没什么意义了。
就算是更新频率不高的数据也会发生变更,那应该如何更新缓存的数据呢?有什么策略呢?
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 利用Redis应用自己的内存淘汰机制,在内存不足时自动淘汰部分数据,下次查询时更新缓存 | 给数据加过期时间,过期自动删除,下次查询更新缓存 | 编写业务逻辑,在修改数据的同时也更新缓存 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
看了这个表格,我们其实发现不同的更新策略各有优略,这就需要根据不同的业务场景来进行选择了。
例如有些业务数据几乎就不会发生改变,就算变化了也不会有什么较大的影响就可以选择内存淘汰策略,好处就是完全不需要维护,但是如果数据要经常发生变化,就需要使用主动更新策略,但是也有有一定难度。
主动更新策略
在实际业务场景中,基本都是在更新数据库的同时更新缓存,再加上超时剔除来作为兜底方案的更新策略。
但是会存在三个问题:
-
更新数据库后是删除缓存还是更新缓存?
一般都是选择删除缓存,然后用户查询时再将数据库的数据保存到缓存中。不选更新缓存是因为每次更新数据库都更新缓存,无效写操作太多。但是也要根据实际业务场景来进行选择。 -
如何保证缓存与数据库操作是同时成功或者失败的?
单体引用就将缓存操作和数据库操作放在一个事务中,这样可以保证从缓存操作失败数据库操作回滚。分布式系统使用分布式事务来解决,但是所有的都无法保证缓存回滚。 -
先操作缓存还是先操作数据库?
一般都是先操作数据再操作缓存,因为缓存操作比较快。基本都是选择先操作数据库再操作缓存,详细看如下两张图。
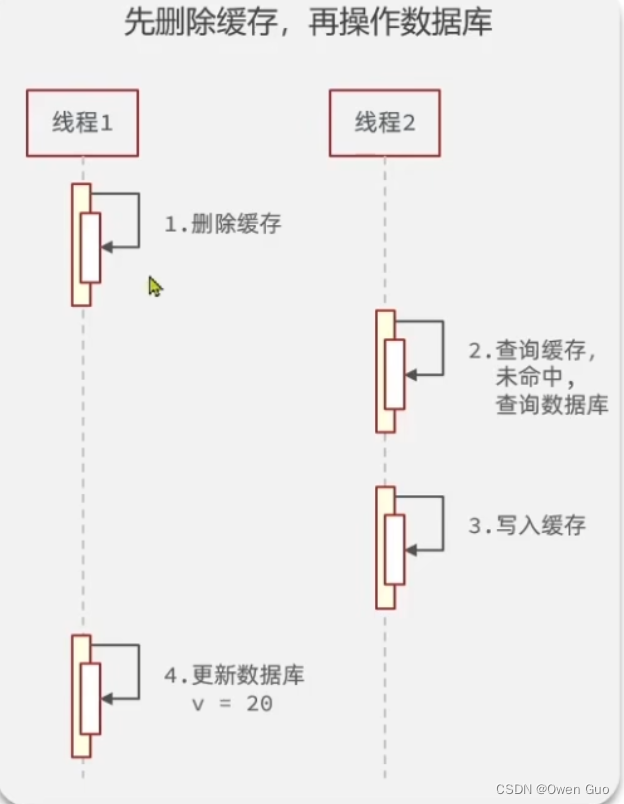
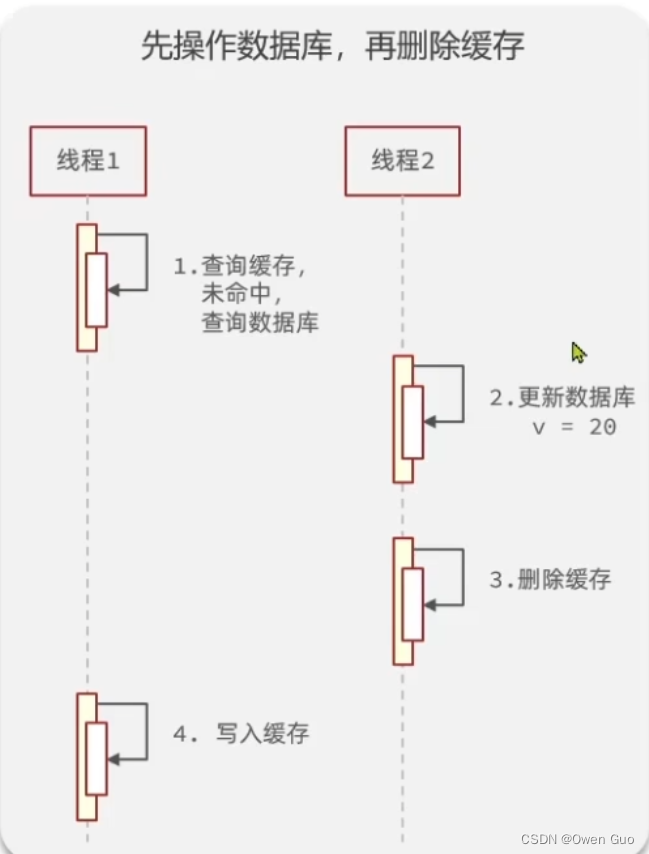
对比这两张图,我们可以发现如果先操作缓存再操作数据库,缓存里的值有可能是过时的数据。先操作数据库再操作缓存,可以保证缓存的值是最新的值。
并且如果先操作数据库,如果执行失败回滚了,对缓存完全无影响,但是如果先操作缓存,则会导致很多缓存失效。
其实缓存更新还有一种策略,就是先操作缓存,然后再开启一个异步线程将缓存的值更新到数据库中
四、缓存穿透
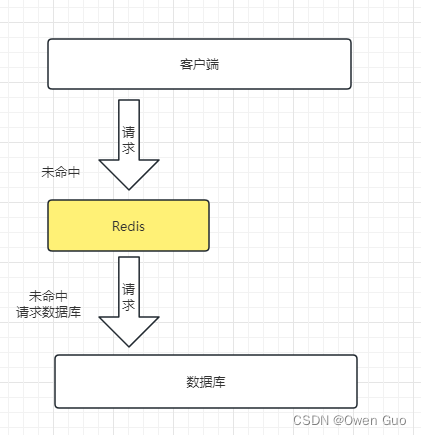
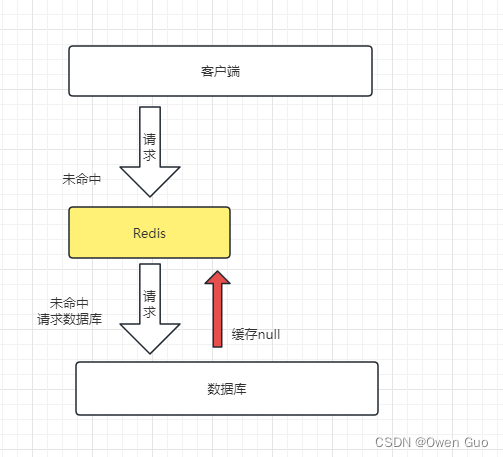
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在(大量请求访问一个不存在的值),这样缓存永远都不会生效,请求全部都会打到数据库。如果请求量过大,很容易造成数据库服务宕机。如下图:
解决方案
1、缓存空对象
缓存空对象就是将不存在的值保存一个空值在缓存中,这样后续的请求查询缓存就会返回一个空值给客户端。
但是这样虽然可以防止缓存穿透的问题,但是还会带来其他问题:
- 额外的内存消耗
- 可能造成短期的不一致
2、布隆过滤器
将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
还有一些主动解决缓存穿透的方案:
1、增强id的复杂度,避免被猜测到id的规律
2、做好数据基础格式的校验
3、加强用户权限管理
4、做好热点数据库限流
五、缓存雪崩
缓存雪崩是指在同一个时间段大量的可缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
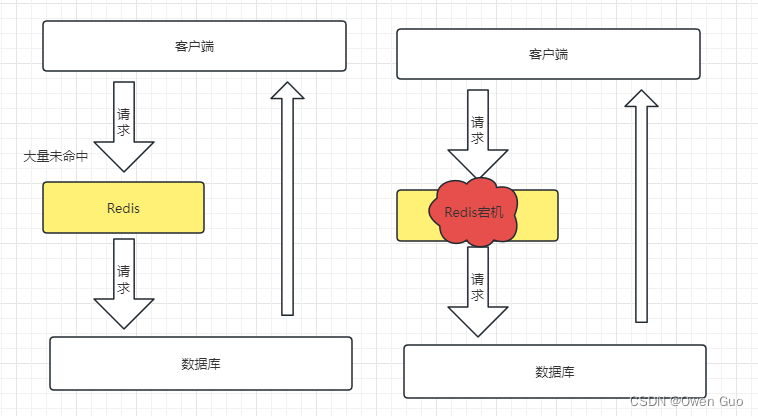
解决方案
如果是因为同一时间段大量缓存key过期导致的
- 给不同的key设置随机均匀的过期时间
如果是因为Redis宕机
- 利用Redis集群提高服务可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
六、缓存击穿
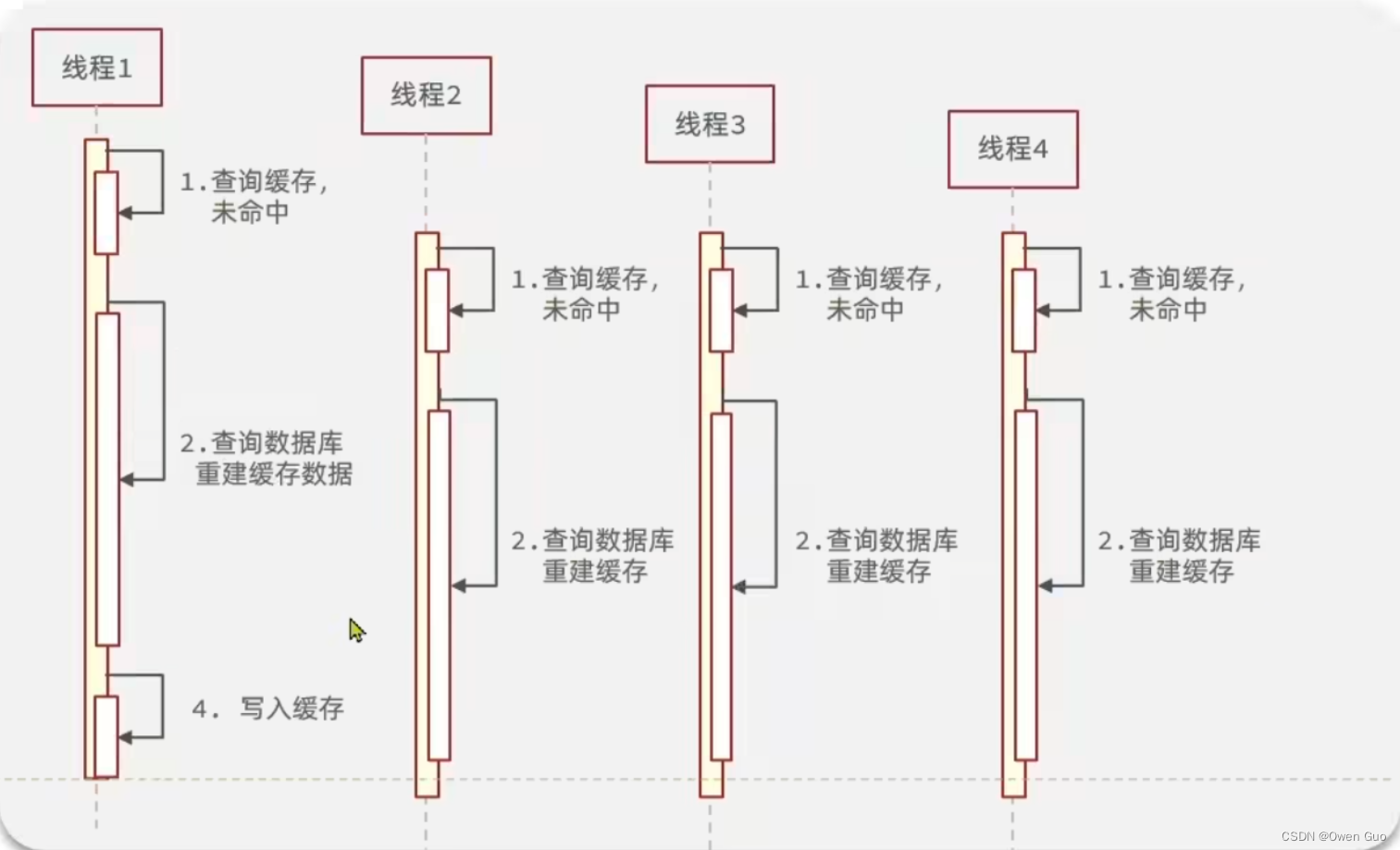
缓存击穿问题也叫热点key问题,也就是一个高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会瞬间给数据库带来巨大的冲击。
解决方案
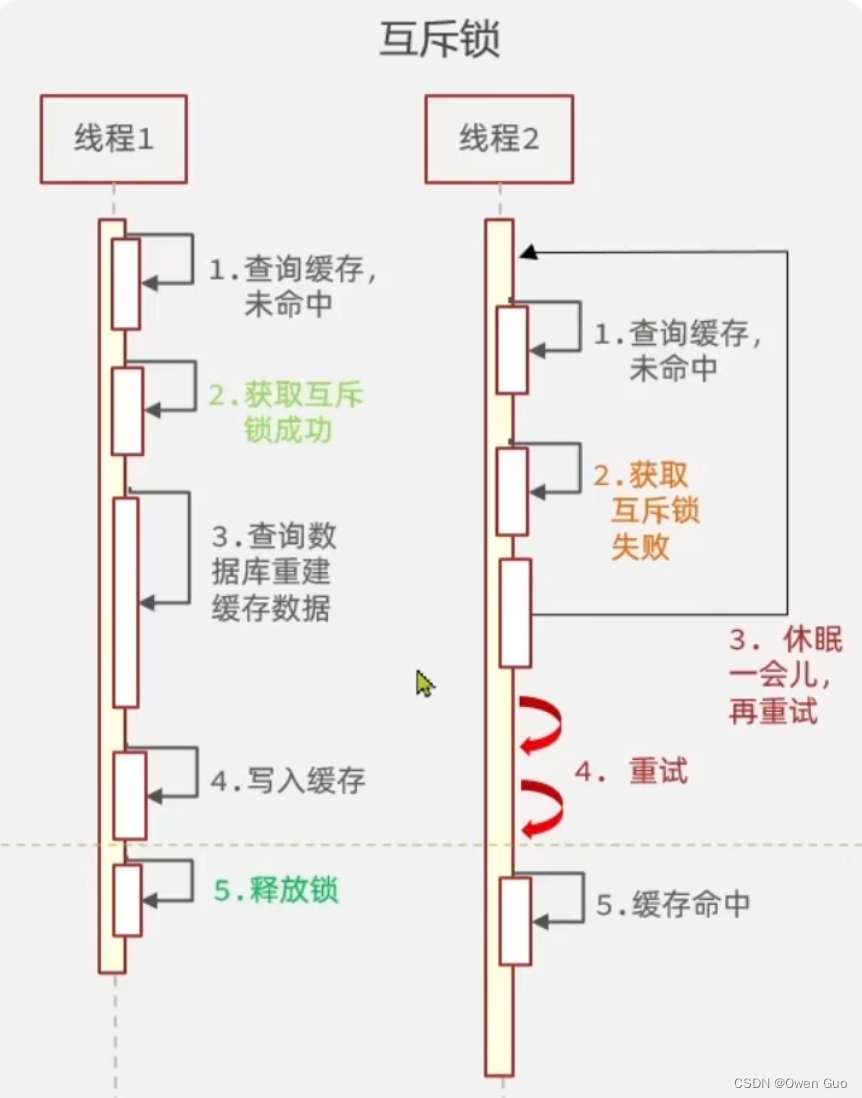
1、利用互斥锁
就是在缓存重建时只有一个线程去重建,其他线程都阻塞等待。
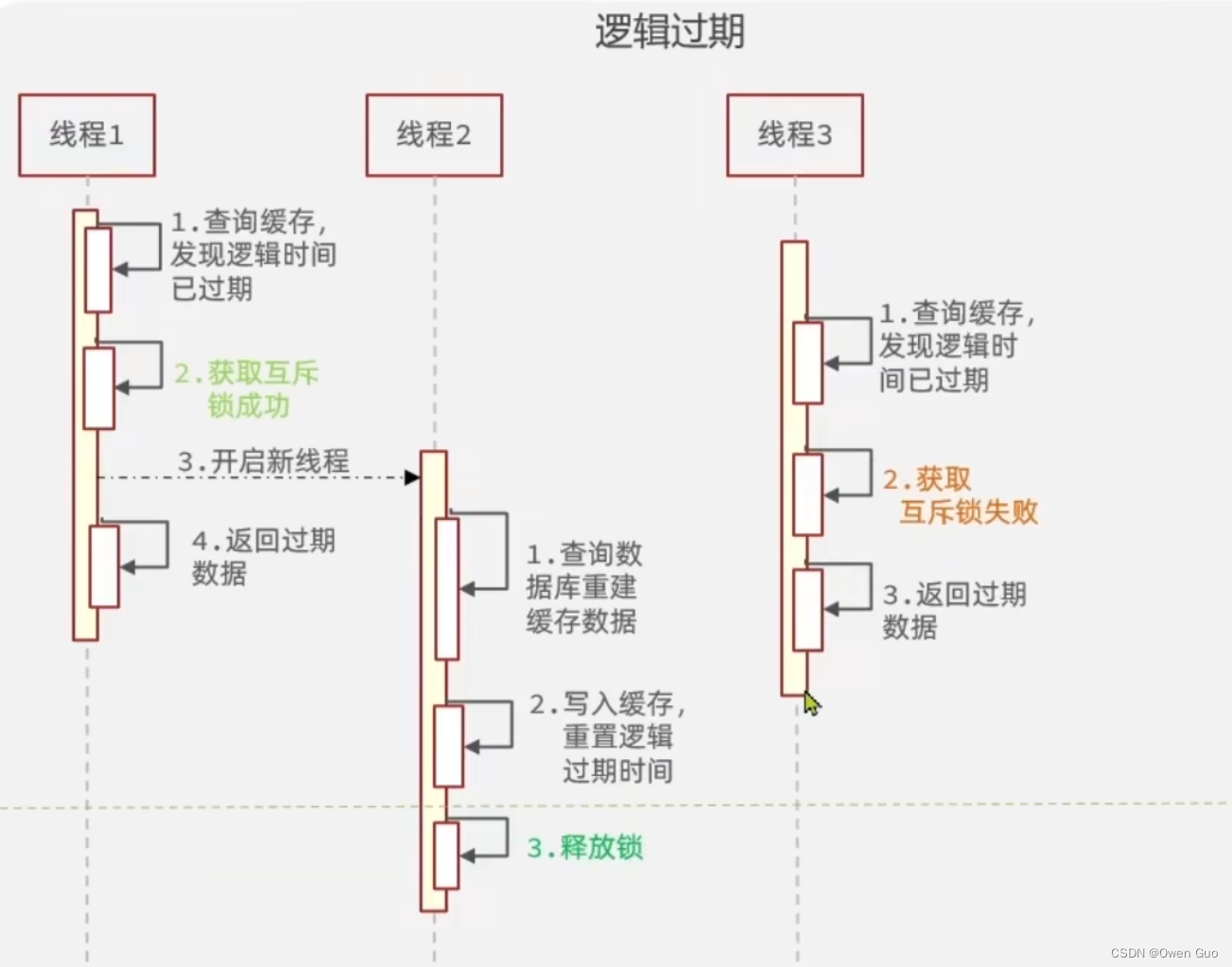
2、利用逻辑过期
就是缓存key是永不过期的,key的value值会保存业务数据和一个逻辑过期时间,请求访问数据主动判断数据是否过期,如果过期了则返回过期值并创建一个异步线程来更新缓存。