前言
接上午的那一篇,下午我们学习剩下的RDD编程,RDD操作中的剩下的转换操作和行动操作,最好把剩下的RDD编程都学完。
Spark【RDD编程(一)RDD编程基础】
RDD 转换操作
6、distinct
对 RDD 集合内部的元素进行去重,然后把去重后的其他元素放到一个新的 RDD 集合内。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDDTransForm {
def main(args: Array[String]): Unit = {
// 创建SparkContext对象
val conf = new SparkConf()
conf.setAppName("spark core rdd transform").setMaster("local")
val sc = new SparkContext(conf)
// 通过并行集合创建RDD对象
val arr = Array("Spark","Flink","Spark","Storm")
val rdd1: RDD[String] = sc.parallelize(arr)
val rdd2: RDD[String] = rdd1.distinct()
rdd2.foreach(println)
//关闭SparkContext
sc.stop()
}
}
运行输出:
Flink
Spark
Storm可以看到,重复的元素"Spark"被去除掉。
7、union
// 通过并行集合创建RDD对象
val arr1 = Array("Spark","Flink","Storm")
val arr2 = Array("Spark","Flink","Hadoop")
val rdd1: RDD[String] = sc.parallelize(arr1)
val rdd2: RDD[String] = sc.parallelize(arr2)
val rdd3: RDD[String] = rdd1.union(rdd2)
rdd3.foreach(println)运行结果:
Spark
Flink
Storm
Spark
Flink
Hadoop8、intersection
对两个RDD 集合进行交集运算。
// 通过并行集合创建RDD对象
val arr1 = Array("Spark","Flink","Storm")
val arr2 = Array("Spark","Flink","Hadoop")
val rdd1: RDD[String] = sc.parallelize(arr1)
val rdd2: RDD[String] = sc.parallelize(arr2)
val rdd3: RDD[String] = rdd1.intersection(rdd2)
rdd3.foreach(println)运行结果:
Spark
Flink
"Spark"和"Flink"是两个RDD集合都有的。
9、subtract
对两个RDD 集合进行差集运算,并返回新的RDD 集合。
rdd1.substract(rdd2) 返回的是 rdd1有而rdd2中没有的元素,并不会把rdd2中有rdd1中没有的元素也包进来。
// 通过并行集合创建RDD对象
val arr1 = Array("Spark","Flink","Storm")
val arr2 = Array("Spark","Flink","Hadoop")
val rdd1: RDD[String] = sc.parallelize(arr1)
val rdd2: RDD[String] = sc.parallelize(arr2)
val rdd3: RDD[String] = rdd1.subtract(rdd2)
rdd3.foreach(println)运算结果:
Storm"Storm"是rdd1中有的二rdd2中没有的,并不会返回"Hadoop"。
10、zip
把两个 RDD 集合中的元素以键值对的形式进行合并,所以需要确保两个RDD 集合的元素个数必须是相同的。
// 通过并行集合创建RDD对象
val arr1 = Array("Spark","Flink","Storm")
val arr2 = Array(1,3,5)
val rdd1: RDD[String] = sc.parallelize(arr1)
val rdd2: RDD[Int] = sc.parallelize(arr2)
val rdd3: RDD[(String,Int)] = rdd1.zip(rdd2)
rdd3.foreach(println)运行结果:
(Spark,1)
(Flink,3)
(Storm,5)RDD 行动操作
RDD 的行动操作是真正触发计算的操作,计算过程十分简单。
1、count
返回 RDD 集合中的元素数量。
2、collect
以数组的形式返回 RDD 集合中所有元素。
3、first
返回 RDD 集合中的第一个元素。
4、take(n)
返回 RDD 集合中前n个元素。
5、reduce(func)
以规则函数func对RDD集合中的元素进行循环处理,比如将所有元素加到一起或乘起来。
6、foreach
对RDD 集合进行遍历,输出RDD集合中所有元素。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDDAction {
def main(args: Array[String]): Unit = {
// 创建SparkContext对象
val conf = new SparkConf()
conf.setAppName("spark core rdd transform").setMaster("local")
val sc = new SparkContext(conf)
//通过并行集合创建 RDD 对象
val arr: Array[Int] = Array(1,2,3,4,5)
val rdd: RDD[Int] = sc.parallelize(arr)
val size: Long = rdd.count()
val nums: Array[Int] = rdd.collect()
val value: Int = rdd.first()
val res: Array[Int] = rdd.take(3)
val sum: Int = rdd.reduce((v1, v2) => v1 + v2)
println("size = " + size)
println("The all elements are ")
nums.foreach(println)
println("The first element in rdd is " + value)
println("The first three elements are ")
res.foreach(println)
println("sum is " + sum)
rdd.foreach(print)
//关闭SparkContext
sc.stop()
}
}
运行结果:
size = 5
The all elements are
1
2
3
4
5
The first element in rdd is 1
The first three elements are
1
2
3
sum is 15
12345
Process finished with exit code 0文本长度计算案例
计算 data 目录下的文件字节数(文本总长度)。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object FileLength {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("spark core rdd transform").setMaster("local")
val sc = new SparkContext(conf)
val rdd1: RDD[String] = sc.textFile("data")
val rdd2: RDD[Int] = rdd1.map(line => line.length)
val fileLength: Int = rdd2.reduce((len1, len2) => len1 + len2)
println("File length is " + fileLength)
sc.stop()
}
}持久化
在Spark 中,RDD采用惰性机制,每次遇到行动操作,就会从头到尾开始执行计算,这对于迭代计算代价是很大的,因为迭代计算经常需要多次重复使用相同的一组数据。
- 使用cache() 方法将需要持久化的RDD对象持久化进缓存中
- 使用unpersist() 方法将持久化rdd从缓存中释放出来
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDDCache {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("spark core rdd transform").setMaster("local")
val sc = new SparkContext(conf)
val list = List("Hadoop","Spark","Hive","Flink")
val rdd: RDD[String] = sc.parallelize(list)
rdd.cache()
println(rdd.count()) //第一次行动操作
println(rdd.collect.mkString(",")) //第二次行动操作
rdd.unpersist() //把这个持久化的rdd从缓存中移除,释放内存空间
sc.stop()
}
}
分区
分区的作用
RDD 是弹性分布式数据集,通过 RDD 都很大,会被分成多个分区,分别保存在不同的节点上。进行分区的好处:
- 增加并行度。一个RDD不分区直接进行计算的话,不能充分利用分布式集群的计算优势;如果对RDD集合进行分区,由于一个文件保存在分布式系统中不同的机器节点上,可以就近利用本分区的机器进行计算,从而实现多个分区多节点同时计算,并行度更高。
- 减少通信开销。通过数据分区,对于一些特定的操作(如join、reduceByKey、groupByKey、leftOuterJoin等),可以大幅度降低网络传输。
分区的原则
使分区数量尽量等于集群中CPU核心数目。可以通过设置配置文件中的 spark.default.parallelism 这个参数的值,来配置默认的分区数目。
设置分区的个数
1、创建 RDD对象时指定分区的数量
1.1、通过本地文件系统或HDFS加载
sc.textFile(path,partitionNum)1.2、通过并行集合加载
对于通过并行集合来创建的RDD 对象,如果没有在参数中指定分区数量,默认分区数目为 min(defaultParallelism,2) ,其中defaultParallelism就是配置文件中的spark.default.parallelism。如果是从HDFS中读取文件,则分区数目为文件分片的数目。
2、使用repartition()方法重新设置分区个数
val rdd2 = rdd1.repartition(1) //重新设置分区为1自定义分区函数
继承 org.apache.spark.Partitioner 这个类,并实现下面3个方法:
- numPartitions: Int ,用于返回创建出来的分区数。
- getPartition(key: Any),用于返回给定键的分区编号(0~paratitionNum-1)。
- equals(),Java中判断相等想的标准方法。
注意:Spark 的分区函数针对的是(key,value)类型的RDD,也就是说,RDD中的每个元素都是(key,value)类型的,然后函数根据 key 对RDD 元素进行分区。所以,当要对一些非(key,value)类型的 RDD 进行自定义分区时,需要首先把 RDD 元素转换为(key,value)类型,然后再使用分区函数。
案例
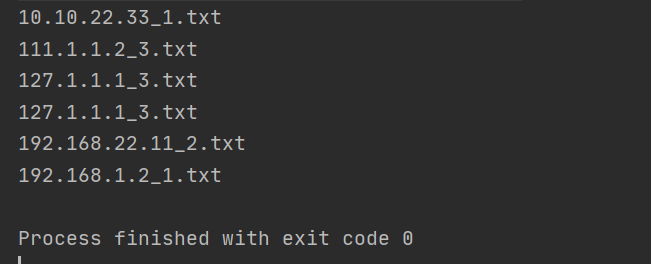
将奇数和偶数分开写到不同的文件中去。
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
class MyPartitioner(numParts: Int = 2) extends Partitioner{
//覆盖默认的分区数目
override def numPartitions: Int = numParts
//覆盖默认的分区规则
override def getPartition(key: Any): Int = {
if (key.toString.toInt%2==0) 1 else 0
}
}
object MyPartitioner{
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("partitioner").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val data: Array[Int] = (1 to 100).toArray
val rdd: RDD[Int] = sc.parallelize(data,5)
val savePath:String = System.getProperty("user.dir")+"/data/rdd/out"
rdd.map((_,1)).partitionBy(new MyPartitioner()).map(_._1).saveAsTextFile(savePath)
sc.stop()
}
}我们在代码中创建RDD 对象的时候,我们指定了分区默认的数量为 5,然后我们使用我们自定义的分区,观察会不会覆盖掉默认的分区数量:
运行结果:
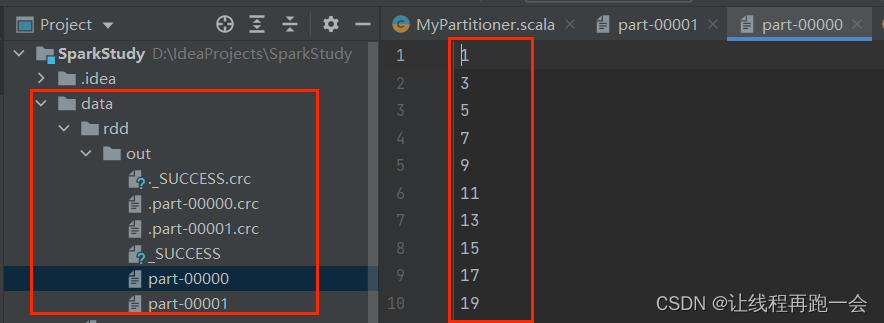
我们可以看到,除了校验文件,一共生成了两个文件,其中一个保存了1~100的所有奇数,一个保存了1~100的所有偶数;
综合案例
在上一篇博客中,我们已经做过WordCount了,但是明显篇幅比较长,这里我们简化后只需要两行代码:
//使用本地文件作为数据加载创建RDD 对象
val rdd: RDD[String] = sc.textFile("data/word.txt")
//RDD("Hadoop is good","Spark is better","Spark is fast")
val res_rdd: RDD[(String,Int)] = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//flatMap:
//RDD(Array("Hadoop is good"),Array("Spark is better"),Array("Spark is fast"))
//RDD("Hadoop","is",good","Spark","is","better","Spark","is","fast"))运行结果:
(Spark,2)
(is,3)
(fast,1)
(good,1)
(better,1)
(Hadoop,1)总结
至此,我们RDD基础编程部分就结束了,但是RDD编程还没有结束,接下来我会继续学习键值对RDD、数据读写,最后总结性低做一个大的综合案例。





![[二分查找] 旋转数组](https://img-blog.csdnimg.cn/dd9ea6066df2460192d8ad515acdc9a9.png)