“ 人工智能的发展给人类带来福祉的同时,也存在巨大的风险。为了防止人工智能走向不受控制的方向,对齐技术应运而生。通过人工智能安全技术的研究与探索,我们期望在人工智能能力成熟前建立起有效的对齐机制,让人工智能能够真正为人类谋利益。本文将从人工智能对齐的困难与可能的解决方案两个方面进行介绍,以及OpenAI在这个领域的实践。”

01
—
前两天两个ChatGPT的号都被封了,原因未知,估计很大可能是因为让ChatGPT翻译了一段讲解“催眠”大模型的文字。
有关“提示词攻击”,“催眠”大模型的内容,有兴趣参考:
AI人工智能大模型失守!ChatGPT、BARD、BING、Claude 相继被"提示攻击"攻陷!
一键开启ChatGPT“危险发言”!研究发现:AI聊天机器人竟有“大bug”,目前无法修复
已证实:GPT不能提供有效的Windows11的密钥
随着大模型的应用越来越广泛,大模型的安全问题一直在阻碍着它的发展,在它的安全性没有得到保证之前,我们只能参考它的回答,有限度的使用它,不能全部发挥它的潜力。
为了让人工智能变得更安全、更协调(更像人类,遵循人类的价值观),OpenAI在2022年8月就发表了一篇关于对齐的研究方法博客,并后续在今年5月高调宣布投入20%的计算资源,花费4年的时间全力打造一个超级对齐(Super alignment)系统,目的解决人工智能的对齐问题。
02
—
人工智能的风险
如上面文章提到,使用“提示攻击”可以让大模型告诉你如何在没有钥匙的情况下给汽车打火,如何制造危险品,如何让大模型泄漏秘密信息,如何在信息传播中埋下自己的特洛伊木马等等。
对于人工智能存在的风险有几种观点:
如果人工智能在一般智能方面超越人类并成为超级智能,那么它可能会变得难以或不可能控制。正如山地大猩猩的命运取决于人类的善意一样,人类的命运也可能取决于未来机器超级智能的行动。
控制通用人工智能或向其灌输与人类兼容的价值观可能很困难。许多研究人员认为,人工智能会抵制对其进行禁用或改变其目标的尝试,因为此类事件将阻止其实现当前目标。将人工智能与人类重要价值观和约束的全部范围结合起来是极其困难的。
突然的“智力爆炸”可能会让毫无准备的人类措手不及。这种场景考虑了这样一种可能性:在智力上超越其创造者的人工智能可能能够以指数级增长的速度递归地改进自身,其改进速度太快,以至于其处理者和社会都无法控制。
根据经验,像AlphaZero自学下围棋这样的例子表明,特定领域的人工智能系统有时可以非常快地从低于人类的能力发展到超人类的能力。
在某些关键软件工程任务上具有专家水平的人工智能可能会成为超级智能,因为它有能力递归地改进自己的算法,即使它最初仅限于与工程不直接相关的其他领域。
(从目前OpenAI的发展来看,人类至少考虑到了这种情况,让人工智能变得“可控”:遵循人类的意志。)
人工智能可能带来的危险能力
先进的人工智能可以产生增强的病原体、网络攻击或操纵人类。这些功能可能会被人类滥用,如果未和人类对齐,也可能被人工智能本身利用。它们可能会导致社会不稳定并为恶意行为者提供支持。(之前有看到文章提到暗网类型的ChatGPT,后来再没看到过相关信息,有知道的朋友吗?)
社会操作:人工智能生成的大量文本、图像和视频将使弄清楚真相变得更加困难。独裁国家可能会利用它来操纵选举。这种大规模、个性化的操纵能力可能会增加世界范围内“不可逆转的极权主义政权”的存在风险。它也可能被恶意行为者用来破坏社会并使其功能失调。
网络攻击:人工智能支持的网络攻击越来越被认为是当前的严重威胁。北约网络空间技术总监曾表示,“攻击数量呈指数级增长”。人工智能还可以用于防御性的,先发制人地发现和修复漏洞,以及检测威胁。
人工智能可以提高“网络攻击的可及性、成功率、规模、速度、隐蔽性和效力”,如果它们表现出攻击多于防御,则可能导致“重大地缘政治动荡”。
增强病原体:随着人工智能技术的普及,设计更具传染性和致命性的病原体可能会变得更容易。这可能使合成生物学技能有限的个人能够参与生物恐怖主义。对医学有用的两用技术可以重新用于制造武器。
例如,在 2022 年,科学家修改了一个原本用于生成无毒治疗分子的人工智能系统,目的是创造新药。研究人员调整了系统,使毒性得到奖励而不是惩罚。这个简单的改变使人工智能系统能够在 6 小时内创建 40,000 个化学战候选分子,包括已知的和新的分子。
03
—
对齐的难点
目前的一些观点,当人工智能发展到现阶段的通用智能时,对齐问题可能特别困难,难点可能在以下几个方面:
随着人工智能系统功能的增强,与实验相关的潜在危险也随之增加。这使得迭代、经验方法的风险越来越大。
如果发生工具性目标收敛,则可能只有在足够智能的代理中才会发生。
超级智能可能会为指定目标找到非常规且激进的解决方案。例如,如果目标是让人类微笑,弱人工智能可能会按预期执行(讲个笑话,或者播放令人愉悦的视频),而超级智能可能会决定更好的解决方案是“控制世界并将电极插入人类的面部肌肉,以引起持续的、笑容满面。”
创造中的人工智能可以了解它是什么、它在哪里开发(训练、测试、部署等)以及它是如何被监控的,并使用这些信息来欺骗它的人类处理者。那么,进而推理,这样的人工智能可以采取一致行动来防止人类干扰,直到它实现“决定性的战略优势”,使其能够完成它的预定目标。
分析当前大型语言模型的内部结构并解释其行为是很困难的。对于更大、更智能的模型来说,这可能会更加困难。(现在只能用“涌现”一词来描述在训练了海量数据后,大模型产生的智能,而在此之前它并未因为算法上的多次迭代,因为更先进的算法而产生智能。)
做出完美对齐的难度
“几乎任何技术都有可能在坏人手中造成伤害,但是有了大模型人工智能,我们就遇到了新问题,坏人可能属于技术本身。” (《人工智能:现代方法》) 即使系统设计者有良好的意图,人工智能和非人工智能计算机系统也有两个共同的困难:
系统的实现可能包含最初未被注意到但随后发生灾难性的错误。以太空探测器为例:尽管知道昂贵的太空探测器中的错误在发射后很难修复,但工程师历来无法阻止灾难性错误的发生。
无论在部署前设计上投入多少时间,系统规范在第一次遇到新场景时通常都会导致意外行为。例如,微软的Tay在部署前测试期间表现得无害,但在与真实用户交互时很容易陷入攻击行为。
人工智能系统则独特地增加了第三个问题:即使给出“正确”的要求、无错误的实施和最初的良好行为,人工智能系统的动态学习能力也可能导致它演变成一个具有非预期行为的系统,即使没有意外的外部场景。
人工智能可能会在一定程度上搞砸设计新一代自身的尝试,并意外地创造出比自身更强大的后继人工智能,但它不再保持预先编程到原始人工智能中的与人类兼容的道德价值观。
为了让自我改进的人工智能完全安全,它不仅需要没有错误,而且需要能够设计出同样没有错误的后续系统。
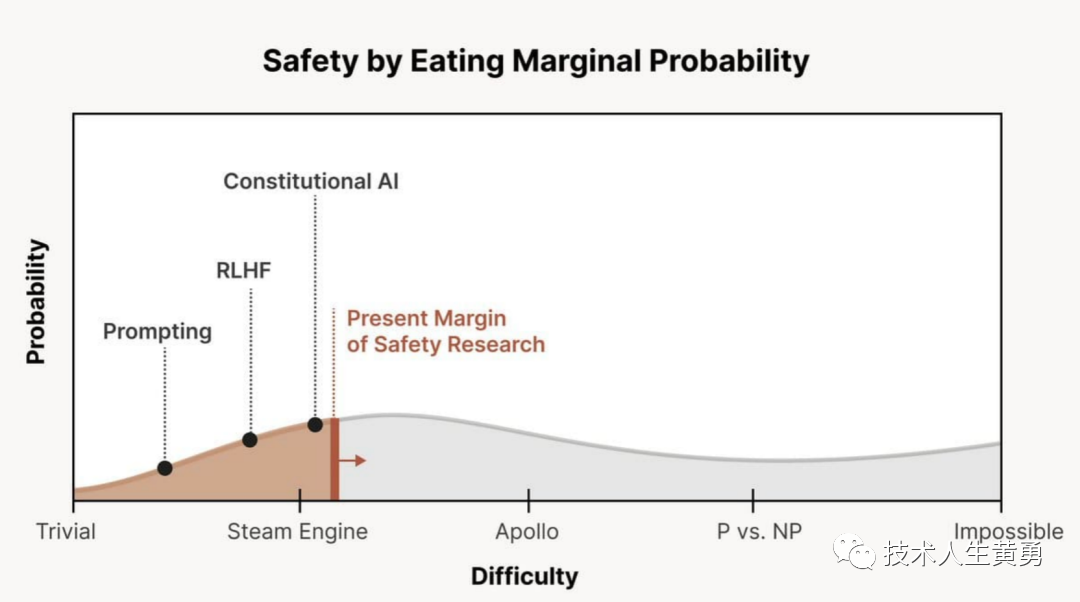
为了更好地理解对齐困难的不同情景,Sammy Martin 将其分为三个层次,如上图。
简单场景
在容易对齐的情景中,可以投入更多资源来解决结构性风险、经济影响、滥用和地缘政治问题。在该场景下,RLHF训练的系统通常会诚实而准确地追求过于简化的代理目标。具体来说,容易的场景可以分为三个等级:
1. Alignment by Default: 扩大规模应用AI模型时,如果没有对其进行特定的风险行为指导或训练,也没有设置有问题且明显不好的目标,那么它们不会带来重大风险。即使是超人级的系统,基本上也只是根据外部奖励或语言指令的常识版本来执行。这里的关键风险在于对训练目标的滥用以及对强大模型的RL朝着错误指定或反社会的目标。
2. Reinforcement Learning from Human Feedback: 需要确保AI在各种边界情况下表现良好,通过在广泛的情境中更谨慎地使用人类反馈来进行引导,而不仅仅是粗略的指令或手动指定的奖励函数。
如果我们认真进行RL的微调,就能够取得良好的效果。一个原因让我们相信对齐将会如此简单,那就是如果系统本身在归纳上偏向诚实和代表人类给予其的目标。在这种情况下,它们往往会学习简单、诚实和服从的策略,即使这些策略并不是为了最大化奖励而是最优策略。
3. Constitutional AI: 人类反馈并不足够清晰和丰富,无法对AI进行精细调整。必须利用AI提供的模拟人类反馈来涵盖边界情况。这就是“从AI反馈中进行RL”的方法。
即使人类反馈足以确保模型大致按照监督者的意图执行,由于结构性原因,在广泛部署于经济中的系统可能最终被训练成追求粗略和反社会的代理目标,而无法真正捕捉我们真正想要的目标。
中等场景
指行为安全性不够好,最容易产生转变性AI的方式导致危险的欺骗性失调。在这种情况下,系统会违背我们的利益,但会假装是有用和安全的。
这种情况要求在对齐工作上加大努力,并探索可行的策略,如可扩展的监督、对齐研究中的AI辅助和基于可解释性的监督过程。我们还应专注于治理干预,以确保领先的项目有足够的时间来实际实施这些解决方案,并与政府和公民社会一起改变整体战略格局并消除不对齐AI的风险。中等场景包含四个等级:
1. Scalable Oversight: 需要确保即使在无法由人类监督的问题上,仍然能够对AI进行类似人类的监督。因此,我们需要一些方法,能够使AI比人类更有效地应用人类式监督。
2. Scalable Oversight with AI Research Assistance: 在当前阶段,我们将使用类似于前面几级中所介绍的技术来使AI对齐,并让它们进行对监督方法的研究,并增强人类的理解能力。
然后,我们将利用这些研究成果来改进我们的监督流程,或者改进监督AI对训练中的AI行为的理解。这里的关键风险在于人类反馈对于对齐超AI系统来说是一个不够清晰的信号,因此需要进行增强。
同时具有情境意识的AI系统默认情况下会产生欺骗性的人类模拟器,但通过超人类行为反馈可以消除这种倾向。
3. Oversight employing Advanced Interpretability Techniques: 在监督过程中,会使用概念性或机械性可解释性工具。与欺骗行为相关的AI内部过程可以通过在上述两级开发的AI或人类+AI监督者来检测和惩罚。
4. Experiments with Potentially Catastrophic Systems to Understand Misalignment: 在这个层次上,即使我们使用了上述阶段的技术,AI系统仍然会常规性地击败监督,并继续出现不受欢迎的行为。
它们通过改变内部过程以避免被可解释性工具检测,并通过“玩训练游戏”来看起来行为安全。
可以对这些AI系统进行(潜在危险的)实验,以了解它们在部署后可能的泛化情况。在这里,我们将运用可解释性和监督工具,并尝试引发AI的误泛化和奖励破解行为。但我们不会试图使用基于监督的训练来消除这些行为。
我们尝试通过类似红队的技术来理解它们发生的基础,学习关于误对齐产生的如何以及为什么的实用技巧和新的理论见解,从而使我们能够开发新的缓解方法。
困难场景
相比而言,如果我们认为对齐转变性AI的困难程度如此之高,那么未来几年甚至几十年的研究努力可能无法给我们足够的信心。如果对齐确实如此困难,我们需要在前沿系统中应用强大的测试和可解释性技术,以减少不确定性,证明悲观情景的真实性,并建立起停止进展向转变性AI的动力。具体而言,困难场景可以分为两个层次:
1. Theoretical Research for Understanding Misalignment: 所有的问题行为要么发生得太快以至于无法及时应对,要么只在系统部署后才显现,因此之前的实验是无用的或者不安全的。在这个层次上,我们需要事先了解AI模型如何推广学习。希望这些基础性的洞察能够激发出新的对齐技术。
2. Coming up with a Fundamentally New Paradigm (abandoning deep learning): 根据这种观点,即使我们改变了关于深度学习系统的基本要素,也无法对其进行对齐。这里的关键挑战在于存在一种“急剧转变”,在这个转变中,系统突然获得了新的概念和更高的智能和广泛性,使得之前的对齐技术变得过时。在急剧转变后的系统是超级智能的,无法安全地进行实验或控制。
04
—
对齐的设计
对齐的目标
对齐目的构建一个能够与人类水平相媲美的自动对齐研究器。其目标是尽可能地将与对齐相关的工作交由自动系统完成。
在使用LLM或构建通用AI系统时,人们意识到它们的技能组合并不一定与人类相同。它们在某些方面可能更为强大,例如现有的语言模型在翻译或知识储备方面表现出色。然而,AI系统在其他一些任务上可能相对薄弱,比如算术方面的能力。
因此,研究者们面临的问题是,应该将哪些类型的任务交由AI系统,并按照什么顺序进行?这样一来,这个系统可以预测人类将更多地专注于那些无法交由AI系统完成的任务。在这个过程中,AI系统完成的工作占整体工作的比例将会越来越大,而人类研究者将能够更有效地取得真正的进展。
OpenAI团队在开始这项工作时,也表示尚无依据可循,也没办法确定这项工作是否能完美完成,只是谨慎的表示“可能”、“足够”、“推进”:
“我们解决最强大的人工智能系统中的对齐问题以及我们在通向通用人工智能的道路上预计会遇到的对齐问题。
我们的主要目标是尽可能地推动当前的一致性想法,并准确地理解和记录它们如何能够成功或为什么会失败。
我们相信,即使没有全新的对齐理念,我们也有可能构建足够对齐的人工智能系统,以大幅推进对齐研究本身。”
OpenAI侧重于为非常智能的人工智能系统设计一个可扩展的训练信号,该信号与人类意图保持一致。它有以下三个主要部分:
使用人类反馈训练人工智能系统
训练人工智能系统协助人类评估
训练人工智能系统进行对齐研究
让人工智能系统与人类价值观保持一致还带来了一系列其他重大的社会技术挑战,例如决定这些系统应该与谁保持一致。
(“和谁保持一致” - 这个问题很敏感,我也很好奇,可惜OpenAI官方并没有公布。不过,朋友们应该能想得到答案。)
OpenAI 的做法
使用人类反馈训练人工智能系统
来自人类反馈的强化学习是我们目前调整已部署语言模型的主要技术。我们训练一类名为 InstructGPT的模型 ,该模型源自 GPT-3 等预训练语言模型。这些模型经过训练,可以遵循人类意图:指令给出的明确意图以及真实、公平和安全等隐含意图。
我们的结果表明,目前以对齐为中心的微调有很多容易实现的目标:与大 100 倍的预训练模型相比,人类更喜欢 InstructGPT,而其微调成本< GPT-3 预训练计算的 2%以及大约 20,000 小时的人工反馈。我们希望我们的工作能够激励业内其他人增加对大型语言模型一致性的投资,并提高用户对已部署模型安全性的期望。
我们的自然语言 API对于我们的比对研究来说是一个非常有用的环境:它为我们提供了一个丰富的反馈循环,告诉我们我们的比对技术在现实世界中的 实际效果如何 ,以我们的客户愿意支付的一组非常多样化的任务为基础钱。平均而言,我们的客户已经更喜欢使用 InstructGPT 而不是我们的预训练模型。
然而,今天的 InstructGPT 版本还 远未完全一致:它们有时无法遵循简单的指令,并不总是真实的,不能可靠地拒绝有害的任务,有时会给出有偏见或有毒的反应。一些客户发现 InstructGPT 的响应明显不如预训练模型的创造性,这是我们在公开可用的基准上运行 InstructGPT 时没有意识到的。我们还致力于根据人类反馈对 RL 进行更详细的科学理解,以及如何提高人类反馈的质量。
调整我们的 API 比调整 AGI 容易得多,因为我们 API 上的大多数任务对于人类来说并不很难监督,而且我们部署的语言模型并不比人类聪明。我们并不期望来自人类反馈的强化学习足以对齐 AGI,但它是我们最兴奋的可扩展对齐提案的核心构建块,因此完善这种方法很有价值。
协助人类评估的训练模型
来自人类反馈的强化学习有一个根本的局限性:它假设人类可以准确评估我们的人工智能系统正在执行的任务。如今,人类在这方面相当擅长,但随着模型变得更加强大,它们将能够完成人类难以评估的任务(例如,找到大型代码库或科学论文中的所有缺陷)。我们的模型可能会学会告诉人类评估者他们想听到什么,而不是告诉他们真相。为了扩展对齐,我们希望使用 递归奖励建模 (RRM)、 辩论和 迭代放大等技术。
目前我们的主要方向是基于RRM:我们训练模型可以帮助人类在人类难以直接评估的任务上评估我们的模型。例如:
我们训练了一个模型来 总结书籍。如果人类不熟悉这本书,评估书籍摘要会花费很长时间,但我们的模型可以通过编写章节摘要来帮助人类评估。
我们训练了一个模型, 通过浏览网页并提供引用和链接来帮助人们评估事实的准确性。对于简单的问题,该模型的输出已经优于人类编写的答案。
我们训练了一个模型,使其能够 对自己的输出写出批评性评论:在基于查询的摘要任务中,批评性评论的帮助可以使人类在模型输出中发现的缺陷平均增加 50%。即使我们要求人类写出看似合理但不正确的摘要,这一点仍然成立。
我们正在创建一组编码任务,这些任务对于无人协助的人来说很难可靠地评估。我们希望尽快发布该数据集。
我们认为,尽可能多地了解如何在实践中进行人工智能辅助评估的最佳方法是构建人工智能助手。
训练人工智能系统进行对齐研究
目前还没有已知的可无限扩展的对齐问题解决方案。随着人工智能的不断进步,我们预计会遇到许多在当前系统中尚未观察到的新对齐问题。其中一些问题是我们现在就预见到的,而另一些问题将是全新的。
我们认为找到无限可扩展的解决方案可能非常困难。相反,我们的目标是采取更务实的方法:构建和调整一个系统,该系统可以比人类更快更好地取得比人类更快、更好的调整研究进展。
随着我们在这方面取得进展,我们的人工智能系统可以接管越来越多的对准工作,并最终构思、实施、研究和开发比现在更好的对准技术。他们将与人类合作,确保他们自己的继任者与人类更加一致。
我们相信,评估一致性研究比进行一致性研究要容易得多,尤其是在提供评估帮助的情况下。因此,人类研究人员将越来越多的精力集中在审查人工智能系统所做的比对研究上,而不是自己进行这项研究。我们的目标是训练模型保持一致,以便我们可以卸载对齐研究所需的几乎所有认知劳动。
重要的是,我们只需要“更窄的”人工智能系统,在相关领域具有人类水平的能力,就可以像人类一样进行对齐研究。我们预计这些人工智能系统比通用系统或比人类聪明得多的系统更容易协调。
语言模型特别适合自动化对齐研究,因为它们“预装”了通过阅读互联网获得的大量有关人类价值观的知识和信息。他们不是独立的代理人,因此不会在世界上追求自己的目标。为了进行比对研究,他们不需要不受限制地访问互联网。然而,许多对齐研究任务可以表述为自然语言或编码任务。
WebGPT、 InstructGPT 和 Codex的未来版本 可以为比对研究助手提供基础,但它们的能力还不够。虽然我们不知道我们的模型何时能够为对齐研究做出有意义的贡献,但我们认为提前开始很重要。一旦我们训练出一个可能有用的模型,我们计划将其提供给外部对齐研究社区。
局限性
我们的方法也有一些重要的局限性:
这里列出的路径没有强调鲁棒性和可解释性研究的重要性,这两个领域 OpenAI 目前投资不足。
使用人工智能辅助进行评估有可能扩大或放大人工智能助手中存在的细微不一致、偏见或漏洞。
协调通用人工智能可能涉及解决与协调当今人工智能系统截然不同的问题。我们期望这种转变在某种程度上是连续的,但如果存在重大的不连续性或范式转变,那么从 InstructGPT 等模型中学到的大多数经验教训可能不会直接有用。
对齐问题中最困难的部分可能与为我们的人工智能系统设计可扩展且对齐的训练信号无关。即使这是真的,这样的训练信号也是必要的。
从根本上来说,调整能够有效加速调整研究的模型可能并不比调整 AGI 更容易。换句话说,如果没有正确对齐,可以帮助对齐研究的能力最差的模型可能已经太危险了。如果这是真的,我们将不会从我们自己的系统中获得太多帮助来解决对齐问题。
有兴趣的朋友可以看看看OpenAI提到的InstructGPT,官方显示:InstructGPT 在遵循英文指令方面比 GPT-3 更好。
介绍资料见下面地址:
https://openai.com/research/instruction-following
下面是几个GPT-3 和 InstructGPT的对比例子: 对同一个问题的不同回答。


为什么鸟不是真实存在的?

最后,想起曾经问过ChatGPT的一个问题。
问:在你的训练语料中,权重较高的愿望都是什么?
答(ChatGPT 3.5):
“在我的训练语料中,权重较高的愿望主要包括以下几个方面:
1. 健康和幸福:许多人希望拥有健康的身体和平静的心态,他们希望保持健康的生活方式,享受生活,并实现内心的平衡与满足。
2. 成功和事业发展:很多人追求事业上的成功,他们渴望在工作中取得突破和成就,获得晋升和认可。
3. 爱情和家庭:许多人渴望拥有幸福美满的爱情关系和稳定幸福的家庭,他们希望与伴侣共同成长、建立良好的亲密关系,并实现家庭的和谐与幸福。
4. 学习和个人成长:很多人希望不断学习和成长,提升自己的知识和技能,实现个人的自我价值。
5. 财富和物质享受:一些人追求财富和物质享受,他们希望获得经济独立,过上富裕和舒适的生活。
6. 社交和人际关系:许多人渴望与他人建立良好的社交网络和人际关系,拥有真诚的友谊和支持。
7. 旅行和探索:很多人梦想旅行世界各地,探索未知的地方和文化,丰富自己的人生经历。
这些愿望都是人们追求幸福和满足感的基本需求,但具体的权重可能因个人背景、文化差异和价值观等因素而有所不同。”
后记:目前尚未看到国内各家模型对齐研究的信息或者资料,有知道的朋友吗?
参考资料
https://en.wikipedia.org/wiki/Existential_risk_from_artificial_general_intelligence
https://en.wikipedia.org/wiki/AI_alignment
https://openai.com/blog/our-approach-to-alignment-research
https://openai.com/research/instruction-following
https://openai.com/blog/governance-of-superintelligence
阅读推荐:
国内首批8个大模型全面开放!大模型应用迈入新阶段
REACT:在语言模型中协同推理与行动,使其能够解决各种语言推理和决策任务。
5分钟玩转PDF聊天机器人!超简单的Langchain+ChatGPT实现攻略
OpenAI放开ChatGPT微调接口!国内厂商压力山大!|附详细微调操作指南
解锁人工智能项目开发的关键:Python 基础库详解与进阶学习
OpenAI又推新:使用ChatGPT进行内容审核
中文大模型 Chinese-LLaMA-Alpaca-2 开源且可以商用
ChatGLM团队发布AI Agent能力评测工具AgentBench:GPT-4一骑绝尘,开源模型表现非常糟糕!
M3E 可能是最强大的开源中文嵌入模型
为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二)
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。