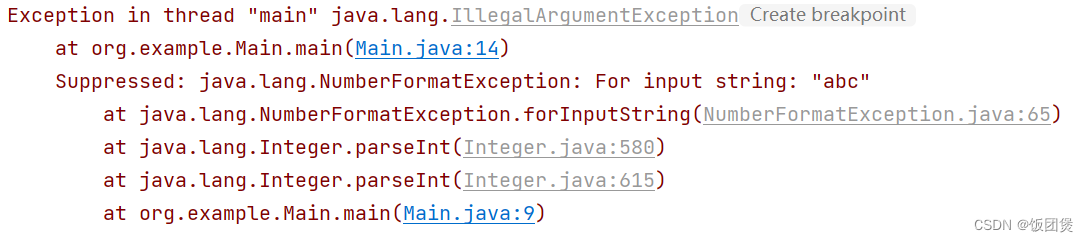
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出,默认分割符是水平制表符。 如果不指定 File 参数, cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
基础语法:
cut [参数选项] 文件名
参数:
- -b:按字节筛选;
- -n:与"-b"选项连用,表示禁止将字节分割开来操作;
- -c:按字符筛选;
- -f:列号,提取第几列;
- -d:指定字段分隔符,不写-d时的默认字段分隔符为"TAB";因此只能和"-f"选项一起使用。
- -s:避免打印不包含分隔符的行;
- --complement:反向选择或者说是补集;
- --output-delimiter:指定输出分割符;默认为输入分隔符
示例如下:
首先需要一个测试文件,内容如下:
测试1 1 11 测试2 2 22 测试333333
首先试下-b参数
cut -b 1 cut1.txt
预期结果是返回第一个字符 ”测“ ,但是可以看到返回的结果是乱码,原因是在linux系统中默认使用 utf-8 编码格式(可以使用 echo $LANG 进行查看),而一个中文字符占用三个3字节,如果想要达到预期效果我们可以显式指定字符长度,或者同时使用-n参数避免对字符进行分割,再或者使用 -c 参数,如下图:
cut -b 1-3 cut1.txt
cut -b 1 -n cut1.txt
cut -c 1 cut1.txt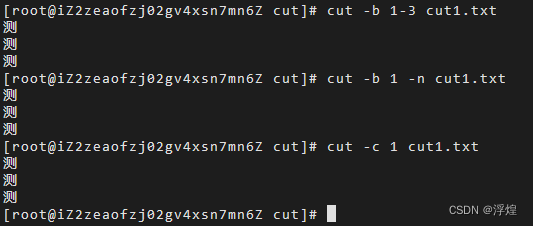
下面再看下 -d 参数
cut -d " " -f 1 cut1.txt
这里我们可以看到由于最后一排没有分隔符 ” “ 所以整个都获取到了,如果我们不想要这部分数据可以使用-s参数
cut -d " " -f 1 -s cut1.txt
complement
反向选择获取到的文本可以看到上面获取到的结果是分割符前的,在反选后变成后面两个。
cut -d " " -f 1 -s --complement cut1.txt
output-delimiter
分割符替换,可以看到分隔符有原本的空格被替换为 |。
cut -d " " -f 1-2 -s --output-delimiter "|" cut1.txt