【半监督医学图像分割】2022-MedIA-UWI
论文题目:Semi-supervise d me dical image segmentation via a triple d-uncertainty guided mean teacher model with contrastive learning
中文题目:基于对比学习的三维不确定性指导平均教师模型的半监督图像分割
论文链接:https://www.sciencedirect.com/science/article/pii/S1361841522000925
作者单位:四川大学&成都信息工程大学
作者主页:周激流-计算机学院 (cuit.edu.cn)
引用:Wang Kaiping, Zhan Bo, Zu Chen, Wu Xi, Zhou Jiliu, Zhou Luping, Wang Yan. Semi-supervised medical image segmentation via a tripled-uncertainty guided mean teacher model with contrastive learning. Medical Image Analysis. 2022
引用数:14(截止时间2023年1月23号)

摘要
由于难以获取大量标记数据,半监督学习在医学图像分割中正成为一种有吸引力的解决方案。
为了利用未标记数据,目前流行的半变量方法(如时态集成、均值教师)主要对未标记数据施加数据级和模型级的一致性。
-
在本文中,我们认为除了这些策略之外,我们还可以
进一步利用辅助任务和考虑任务级一致性来更好地从未标记数据中挖掘有效的表示来进行分割。 具体来说,我们引入了两个辅助任务,即用于获取语义信息的前景和背景重建任务和用于施加形状约束的符号距离场(SDF)预测任务,并探讨了这两个辅助任务与基于均值教师架构的分割任务之间的相互促进作用。 -
此外,为了解决
教师模型由于注释不足而产生的潜在偏差,我们开发了一个三重不确定性引导框架,以鼓励学生模型中的三个任务从教师那里学习更可靠的知识。 在计算不确定度时,我们提出了一种不确定度加权积分(UWI)策略来产生教师的分段预测。 -
此外,在借
鉴无监督学习在利用未标记数据方面的进展的基础上,我们还引入了基于对比学习的约束来帮助编码器提取更多不同的表示,以提高医学图像分割的性能。
在公开的2017年ACDC数据集和Promise12数据集上进行的大量实验证明了我们方法的有效性。
1. 介绍
分割是医学图像处理和分析领域中一项基本而又必不可少的任务。 传统的人工绘制感兴趣区域(ROI)是以大量的时间为代价的。 另外,人工分割的质量在很大程度上依赖于医生的临床经验。 为了提高临床效率和获得可靠的分割结果,许多研究者致力于研究自动分割技术。
受益于深度学习的进步,卷积神经网络(CNN)及其不同的变体显示出强大的图像处理能力,在自动分割中得到了广泛的应用。
特别是全卷积网络(FCN)(Long et al.,2015)和U-Net(Ronneberger et al.,2015)的提出,在医学图像自动分割领域实现了量子飞跃,奠定了坚实的基础。
在此基础上,人们开展了大量的工作来进一步提高分割性能。 例如,考虑到边界在分割中的重要性,Fang等人。 (2019)和张等人 (2019)明确鼓励模型判别目标的边界,从而细化分割性能。
Cheng et al.,2020引入方向域来隐式约束分割结果的形状。 唐等人。 (2022)提出了结合不确定性估计和多尺度特征提取的统一的端到端医学图像分割框架。
上述方法获得了优良的性能和推广性。 然而,收益和成本总是相伴而生的。
它们的成功在很大程度上依赖于大量的注释数据,而这些注释数据在现实世界中是很难获得的,尤其是在医学图像分割领域,由于其昂贵和耗时的性质。
为了缓解注释不足,一个可行的方法是采用半变量学习(Kervadec et al.,2019;Bortsova et al.,2019),它利用标记和未标记数据来有效地训练深度网络。
半监督分割社区已经投入了大量的精力,它可以大致分为两个流行的群体。 第一组是指那些试图预测未标记图像上的伪标签并将其与地面真值标签混合以提供额外训练信息的方法(Zheng et al.,2020a;Park et al.,2018;Zheng et al.,2020b)。
然而,由于预测的伪标签质量参差不齐,这种基于自训练的方法的分割结果很容易受到影响。
第二组半监督分割方法在于一致性正则化,即对于同一输入,鼓励在不同扰动下的分割预测在数据层和模型层保持一致。
具体来说,数据级一致性要求对同一输入施加不同扰动所得到的结果之间的一致,而模型级一致性则需要通过不同模型对同一输入保证结果的一致。
一个典型的数据级示例是-model(Laine and Aila,2016),它最小化了使用不同正则化策略的两次向前传球结果之间的距离。
由于每个结果都是基于对网络的单一评估,因此在训练阶段可能存在噪声和不稳定。
为了提高稳定性,在-model的基础上进一步提出了一个时态集成模型(Laine and Aila,2016),该模型聚合了指数移动平均(EMA)预测,并鼓励集成预测与当前预测之间的一致性。
为了加速训练并支持在线学习,Mean Teacher(Tarvainen and Valpola,2017)进一步改进了时态集成模型,通过在具有不同噪声扰动的当前训练模型(即学生模型)和对应的EMA模型(即教师模型)之间加强预测一致性
另一方面,与上述半监督分割方法主要关注数据级或模型级扰动下的一致性不同,也有研究著作(Luo et al.,2020;Chen et al.,2019;Li et al.,2020;Jia et al.,2021)从另一个角度探索改进分割:多任务学习。 这些方法通过共享编码器在单个模型中联合训练多个相关任务。
例如,陈等人。 (2019)应用了一个重建任务来辅助医学图像的分割。
李等人。 (2020)提出了一个形状感知的半监督模型,通过引入符号距离图生成任务对分割结果施加形状约束。 通过研究主任务和辅助任务之间的任务级一致性,学习的分割模型可以绕过过拟合问题,从未标记数据中学习更多具有代表性的特征,提高分割性能。
除了半监督学习之外,自监督学习也是解决标签稀缺性问题的一种替代方案,其
作为一种重要的自监督学习方法,对比学习最近在图像分类(Chen et al.,2020a;Hassani and Khasahmadi,2020;Shi et al.,2022)、图像分割(Pandey et al.,2021,Sun et al.,2022)、图像翻译(Park et al.,2020)等计算机视觉任务中显示出了良好的效果。
一般说来,对比学习需要将当前样本的特征(即查询)与其变体以及其他样本的特征(即键)耦合起来,从而构建正对和负对(Shao et al.,2020)。
然后,训练一个模型来正确区分正对和大量的负对。
通过这种方法,预训练模型能够产生有效的视觉表征,从而进一步有利于下游任务的学习。
本文借鉴半监督学习、对比学习和多任务学习的成功经验,从三个高度相关的任务出发,提出了一种新的端到端半监督均值教师模型。
具体来说,考虑到半监督学习的性能高度依赖于从未标记数据中提取有效的特征表示(Rebuffi et al.,2020),我们利用多任务学习和对比学习来增强编码器的表示能力,并将学习到的表示转移到医学分割任务中。
对于多任务学习,除了分割任务外,我们引入了两个额外的辅助任务,即前景和背景重建任务以及符号距离场(SDF)预测任务。
重建任务可以帮助分割网络捕获更多的语义信息,而预测的SDF描述了对应像素在归一化后到其最近边界点的符号距离,从而约束了分割结果的全局几何形状。
遵循Mean教师架构的精神,我们构建了一个教师模型和一个学生模型,每个模型都针对以上三个任务。
此外,为了解决教师模型预测中的不可靠性和噪声,我们对三个任务都施加了不确定性约束,期望学生模型能够学习尽可能多的准确信息。
对于对比学习,我们遵循无监督的对比学习机制,对来自编码器的特征直接施加一致性约束,从而促进编码器学习样本的特定特征。
我们的主要贡献有四个方面:
(1)在Mean Teacher架构中注入了多任务学习的精神,通过挖掘分割任务、重建任务和SDF预测任务之间的相关性,使分割任务也能从增强的语义和几何形状信息中受益。 通过这种方式,我们的平均教师模型同时考虑了数据、模型和任务级别的一致性,以更好地利用未标记的数据进行分割。
(2)我们对所有任务进行不确定性估计,并建立了一个三重不确定性模型,以指导学生模型从教师模型中学习更可靠的预测。
(3)现有的方法往往通过对多个Monte Carlo(MC)采样结果进行平均来生成不确定性映射,而忽略了不同结果之间的差异。 相比之下,我们提出了一种不确定性加权积分(UWI)策略,为不同的采样结果分配不同的权值,产生更准确的分割预测。
(4)纯半监督学习主要集中在每前向一个样本的正则化。 相比之下,对比学习涉及多个样本的关系建模,挖掘更有代表性的数据分布。
因此,我们将对比约束集成到半监督模型中,帮助编码器学习更多不同的表征。 在公共2017 ACDC数据集(Bernard et al.,2018)和Promise12数据集(Litjens et al.,2014)上获得的实验结果证明了我们方法的先进性及其关键模块的有效性。
请注意,这项工作的初步版本早些时候在2021医学图像计算和计算机辅助干预(MICCAI)上提出(Wang et al.,2021)。
本文从以下几个方面对会议版本进行了扩展:
(1)引言:我们细化了研究背景,使研究的动机更加严谨和引人注目;
(2)相关工作:增加了相关工作部分,对相关研究进行了全面的回顾;
(3)方法:进一步对编码器施加对比约束,使同一图像中的特征相互靠近,而不同图像中的特征相互远离,以增强其特征表示能力。
此外,我们在算法1中提出了一个伪码,以清楚地显示我们的模型的训练过程;
(4)讨论:对对比实验和烧蚀实验的结果进行了分析和讨论,总结了本方法的局限性,并指出了今后的研究方向。
本文的其余部分组织如下。 我们在第2节简要回顾了相关的工作。 第三节详细介绍了该方法的体系结构和关键算法。 第四节给出了数据集和实验结果。 在第5节中,我们讨论了当前方法的结果、局限性和未来的改进。 最后,第六部分对全文进行了总结。
2. 相关工作
2.1 多任务
多任务学习是一种广泛使用的策略,它旨在联合学习多个相关任务,从而使任务中的知识可以被其他任务所利用,从而获得更好的推广性(Zhang and Yang,2021)。 在深度神经网络中,多任务学习通常是通过一个参数共享的体系结构和几个针对不同任务的独立头来实现的。 通常,参数共享策略有两种形式,即软参数共享和硬参数共享(Ruder,2017)。
软参数共享方法倾向于为不同的任务设计单独的体系结构,并对不同体系结构的相应参数进行约束,以鼓励它们之间的相似性。 Yang和Hospedales(2016)提出用迹范数正则化不同网络参数的相似性。 杜昂等人。 (2015)提出了两个语言解析器网络,并利用L2范数来保持两个网络的参数和权重之间的距离保持接近。 同样,郭等人。 (2018)引入了并行训练的多级软共享策略来完成句子简化任务。 他们认为,部分参数是层特定的,在训练期间将被保密。 反之,不同网络的相关参数用L2范数正则化。 尽管在性能上取得了进步,但软参数共享策略在涉及的任务扩展时可能会受到参数数量更大增加的影响(Sun et al.,2020)。
相比之下,硬参数共享策略是一种更流行的方法,它可以通过共享编码器参数轻松地将多个任务集成到一个网络架构中。
硬参数共享策略在不建立多个独立网络的情况下,将所有任务下层的参数绑定在一起,从而抑制了参数数目的增长,并大大降低了与软参数共享相比过拟合的风险。
一个著名的实践是两阶段对象检测(Girshick et al.,2014;Girshick,2015),其中基于共享编码器配备两个任务头,分别预测包围盒位置和类概率。
此外,分割任务也得益于这种硬参数共享策略,取得了像样的性能(Duan et al.,2019;Zhang et al.,2021a;Amyar et al.,2020;Bischke et al.,2019;Murugesan et al.,2019;Song et al.,2020)。
例如,段等人。 (2019)提出了一个多任务的Deep Neu RAL网络,该网络可以同时预测心脏磁共振体积的分割和解剖标志。 张等人。 (2021A)集成了肿瘤分割任务和分类任务,用于胃肿瘤的自动分割。
刘等人。 (2019)明确探索了肺结节良恶性分类任务与属性回归任务的关系。
由于硬参数共享策略的简单性和有效性,我们也选择了它来构建我们的多任务体系结构。
2.2 对比学习
近年来,对比学习在计算机视觉领域得到了广泛的关注。 如何有效地构建积极对和消极对是进行对比学习的一个关键问题。
一个通用可行的解决方案是对相同的输入样本应用不同的增强变换,从而产生不同的视图。
随后,来自同一输入样本的视图被绑定为正对,来自其他样本的视图形成负对。 之后,训练一个深层模型来判别正负对,从而学习隐藏在各种样本中的内在特征。 紧随其后,Hjelm等人。 (2018)从一个小批处理中选择了局部特征和全局表征,以导出正对和负对。 然而,最近的研究表明,训练批中负对的数量可能会影响训练成绩(Kalantidis et al.,2020)。 为此,吴等人。 (2018)提出利用存储体来存储先前的特征,从而可以扩大负对的数量。
更极端的是,SIMCLR(Chen et al.,2020a)直接采用足够大的批量来容纳更多的阴性样本,并引入非线性投影来更好地学习表征。
然而,记忆库倾向于保留网络的早期特征,这些特征对网络进化过程中的对比学习贡献很小。
此外,更大的批处理意味着需要消耗更多的计算资源。 为了缓解这个问题,他等人。 (2020)提出了动量对比(MOCO)模型,该模型保持较小的队列来存储以前的特征,删除过时的特征,保证了存储特征的一致性,减少了计算量。
而且,Khosla等人。 (2020)将先验监督信号引入到对比学习中,并对不同类之间的距离进行正则化,而不是随机选择的实例,避免了可能出现的假阴性对。
2.3 半监督分割
半监督分割的目的是利用大量未标记数据为有限标记数据的训练提供额外的信息,从而提取更广义的表示来进行分割,并缓解可能存在的过拟合问题。
一种典型的半监督分割策略可以分为伪标记,它利用一个预先训练的模型为未标记的数据生成伪标记,以扩展标记数据集。
例如,Bai等人。 (2017)采用交替更新方式,利用条件随机场优化网络参数和伪标签,细化分割结果。 彭等人。 (2020)提出了一种协同训练方法,该方法同时训练两个模型,并鼓励它们对未标记数据的预测相互提供伪监督信号。 陈等人。 (2020b)认为训练一个同时具有强标签和伪标签空间的模型可能会导致无序的反向传播。 因此,他们设计了一种针对强标记和伪标记数据的两个分支的方法,并利用从伪标记中提取的可靠信息来辅助强标记学习。 然而,对于这些方法来说,伪标签的质量很难得到保证,这可能会给模型带来很大的噪声,导致性能下降。
生成对抗网络(GAN)不仅在医学图像合成领域大放异彩(Wang et al.,2018a;Wang et al.,2018b;Zhan et al.,2021;Luo et al.,2021;Li et al.,2022),在半监督分割领域也颇受欢迎。
例如,张等人。 (2017)引入了鉴别器来区分分割预测是来自有标记还是无标记的数据,从而缩小了有标记和无标记预测之间的分布差距。
聂等人。 (2018)提出了一种对抗式信任网络来辅助分割模型从未标记数据中学习知识。
李等人。 (2020)采用了对抗学习,鼓励标记和未标记预测的符号距离图接近,从而充分利用未标记数据的形状信息。
近年来,基于一致性的半监督方法因其强大的性能而受到众多研究者的青睐(Kervadec et al.,2019;Luo et al.,2020;Chen et al.,2019)。
一般说来,这些方法试图设计合适的辅助任务,并对主辅助任务的输出进行一致性正则化。
例如,Kervadec等人。 (2019)纳入了一个更简单的图像级特征回归任务,如预测目标的大小,并鼓励其输出接近主分割任务的输出。
两个任务之间的一致性约束有助于从未标记数据中补充更多有用的信息。
同样,罗等人。 (2020)通过保证分割输出与符号距离图预测的一致性,对未标记数据进行了探索。 此外,模型级和数据级的一致性也受到了广泛关注。
(Laine and Aila,2016)提出了A-模型,以鼓励不同扰动下预测之间的数据级一致性。
此外,为了提高训练的稳定性,他们在模型的基础上提出了一个时间集成模型,该模型将先前的输出作为正则化的目标。 受此启发,(Tarvainen and Valpola,2017)设计了一个均值教师模型,该模型考虑集成先前参数的指数移动平均值(EMA)而不是输出,并确保了学生模型和集成教师模型之间的模型级一致性。
为了缓解来自教师模型的噪声,不确定性估计(Zheng et al.,2020a;Wang et al.,2020;Hu et al.,2021;Sedai et al.,2019)也被广泛应用于强制学生模型从教师模型中学习更可靠的知识。
例如,Hu et al.(2021)利用不确定性估计对均值教师的预测进行加权,确保了半监督鼻咽癌的可靠性
除了上述方法外,还有一些其他的工作从熵最小化(Kalluri et al.,2019;Hang et al.,2020)、互信息正则化(Peng et al.,2020;Xi,2019)和图构造(Huang et al.,2021;Zhang et al.,2021b)等角度处理未标记数据。
例如,Hang等人。 (2020)将熵最小化原理引入学生模型,对未标记数据产生高自信预测。
彭等人。 (2020)对原始和变换后的未标记图像的预测进行互信息正则化,以提高分割性能。
黄等人。 (2021)在语义分割任务和边界检测任务中,采用双边图卷积的方法捕获远程依赖关系,细化视觉表示。
在这项工作中,我们把重点放在对Mean教师架构的持续探索上。
3. 方法
我们提议的网络的概述在图得到说明 1、由教师模型和学生模型组成,遵循中等教师的理念。 学生模型是要训练的目标模型,它在训练的每一步都将其权重的指数移动平均值(EMA)分配给教师模型。 另一方面,教师模型的预测将被视为学生模型学习的额外监督。 这两个模型采用了类似的编码器-解码器结构,编码器在不同的任务之间共享,而解码器是特定于任务的。 在我们的问题集中,我们给出了一个包含n个标记数据和m个未标记数据的训练集,其中n m.标记集定义为d l={x i,y i}n i=1,未标记集定义为d u={x i}n+m i=n+1,其中x i∈R h×w是强度图像,y i∈{0,1}h×w是相应的分割标记。 对于标号数据,我们还可以通过(Shue et al.,2020)中的SDF函数从Y i中得到符号距离场(SDF)的地面真值Z i∈R h×w。 同样地,对于重建任务,前景和背景Gi∈R2×H×W的基础真值可以由y i[xi]i和(1-y i)[xi]i得到,其中i指元素相乘。 我们的目标是利用对比学习来增强编码器的代表性能力,通过对比学习可以从两个辅助任务中充分学习语义信息和几何形状知识,即SDF预测任务和前景背景重建任务,从而提高D L和D U上的分割性能。 总之,在给定D L和D U的情况下,通过最小化1)标记数据上的监督分割损失L S;2)在D L和D U上学生模型和教师模型之间的模型间一致性损失L模型CSL;3)在D L和D U上不同任务之间的任务间一致性损失L任务CSL来优化学生模型
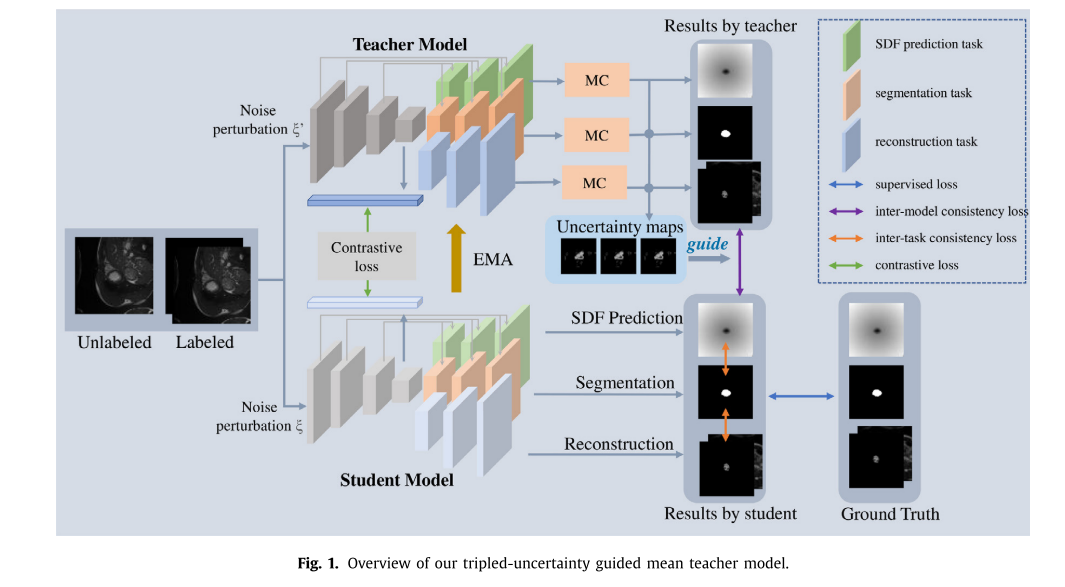
3.1 学生模型
U-NET(Ronneberger et al.,2015)是一个重要的编码器-解码器风格框架,最初被提出用于医学分割分析领域。
由于其高性能和良好的泛化能力,我们的学生模型采用U-NET作为三个任务的主干,即分割任务、重构任务和SDF预测任务。 请注意,学生模型的编码器由具有相同参数的三个任务共享,而特定于任务的解码器中的参数是不同的,以适应不同的任务。 以这种方式,通过优化三个高度相关的任务,迫使编码器捕获与语义信息和几何形状信息相关的特征,导致输出分割结果与地面真实值之间的低差异。 另外,考虑到重构任务旨在学习有效的高层语义表征,需要对输入的空间特征进行浓缩。 然而,U-NET采用的跳过连接使得网络无需降维就可以直接从早期层复制特征,这可能导致该任务无效。 因此,跟随(Chen et al.,2019),我们在重建任务中放下了跳过连接。
具体来说,编码器由四个不同特征尺度的卷积块组成。 在前三个块中,每个块由核大小为3×3的两个卷积层组成,然后是批归一化层和RELU激活层。 将第二卷积层的步幅设为2,对特征图进行下采样,以获取压缩的空间信息。 对于第四块,采用两个步长为1的3×3卷积层来获得编码器的特征表示。 对于三个特定于任务的解码器,每个解码器包含三个上采样块和一个特定于任务的头。 上采样块的结构与编码器中前三个卷积块的结构对称。 分割头采用Softmax激活,重建头和SDF头采用Sigmoid激活。
给定输入图像Xi,三个任务可以生成分割结果Y~Is、重建结果G~Is、SDF结果Z~Is,如下所示:
Y
~
S
i
=
f
seg
(
λ
i
;
θ
seg
,
ξ
)
,
G
~
S
i
=
f
rec
(
λ
i
;
θ
rec
,
ξ
)
,
Z
~
S
i
=
f
sdf
(
λ
i
;
θ
sdf
,
ξ
˙
)
,
\begin{array}{c}\mathbf{\tilde{Y}}_{S}^{i}=f_{\textrm{seg}}\big(\boldsymbol{\lambda}^{i};\theta_{\textrm{seg}},\xi\big),\\ \\ \mathbf{\tilde{G}}_{S}^{i}=f_{\textrm{rec}}\big(\boldsymbol{\lambda}^{i};\theta_{\textrm{rec}},\xi\big),\\ \\ \mathbf{\tilde{Z}}_{S}^{i}=f_{\textrm{sdf}}\big(\boldsymbol{\lambda}^{i};\theta_{\textrm{sdf}},\dot{\xi}\big),\end{array}
Y~Si=fseg(λi;θseg,ξ),G~Si=frec(λi;θrec,ξ),Z~Si=fsdf(λi;θsdf,ξ˙),
其中f seg,f rec,f sdf表示分割网络,重构网络和sdf预测网络,相应参数θseg,θrec,θsdf,ζ是学生模型的噪声扰动。
3.2 教师模型
我们的教师模型的网络是从学生模型中复制出来的,但他们有不同的更新参数的方法。 学生模型以梯度下降的方式更新参数θ={θseg,θrec,θsdf},教师模型以学生模型参数θ在不同训练阶段的均方根值更新参数θ={θseg,θrec,θsdf}。 特别是,在训练步骤t处,教师模型的参数,即θt,根据以下内容更新:
θ
t
′
=
τ
θ
t
−
1
′
+
(
1
−
τ
)
θ
,
\boldsymbol{\theta_{t}^{'}}=\tau\boldsymbol{\theta_{t-1}^{'}}+(1-\tau)\boldsymbol{\theta},
θt′=τθt−1′+(1−τ)θ,
其中τ为EMA衰减系数,以控制更新速率。
此外,由于D u上没有标签,教师模型的结果将被用作学生模型的伪标签。 然而,结果中可能存在的不良偏差可能会带来噪声,误导学生模型,从而导致较差的分割性能。 为了最大限度地减少这种不可靠性,我们在教师模型中引入了不确定性估计,引导学生学习更可靠的知识。 具体来说,我们使用蒙特卡罗(MC)dropout执行k次前向传递,从而获得所有任务关于输入x i的k个初步结果,即{~y ij t}k j=1,{~g ij t}k j=1,{~z ij t}k j=1。 随后,由这些初步结果可以得到教师模型的结果和相应的不确定性图。
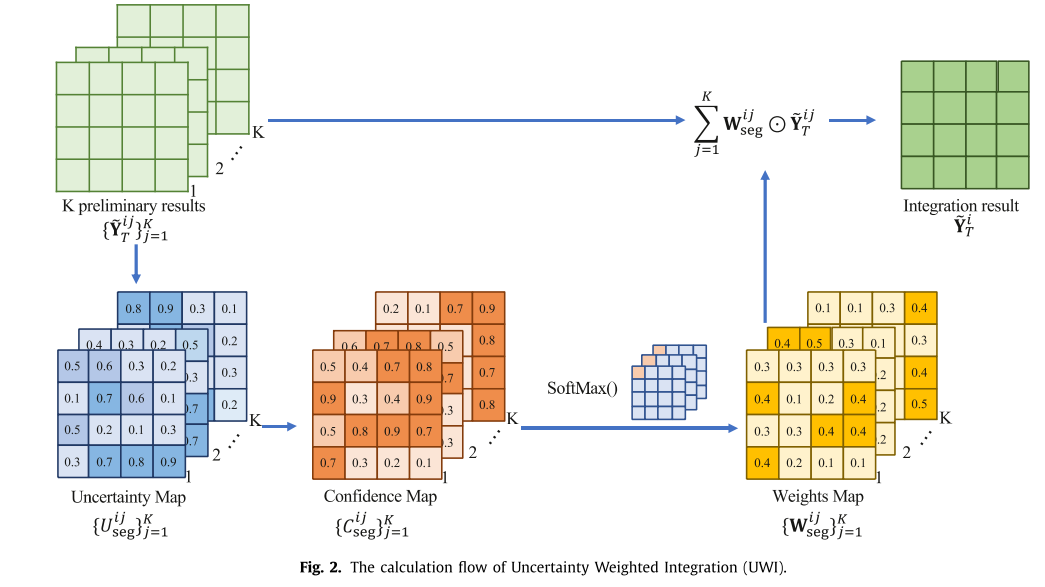
传统的基于不确定性的分割方法,如(Yu et al.,2019;Wang et al.,2020;Sedai et al.,2019),往往通过对初步结果进行简单的平均来生成最终的集成结果,而忽略了它们的特殊性。 不同的是,对于主分割任务,我们创新性地设计了一种不确定性加权积分(UWI)策略,为不同的采样结果分配不同的权值。 本文以图为例说明了UWI的发展过程 2. 首先,接收由绿色网格表示的k个初步分割结果{~y ij t}k j=1作为输入。 考虑到这些结果之间的不确定性,我们计算了每个初步结果的不确定性映射{uijseg=-c∈cyijctlo g cyijct}k j=1,其中c是待分割类的个数,这里设为2,c是第c类。
这样,不确定度映射的取值范围在0到1之间,较大的值表示较高的不确定度。 由于这些不确定映射隐含了教师模型学习中的不确定区域,我们进一步构造了k个置信度映射{c ij seg=1-u ij seg}k j=1,其中每个像素对应一个长度为k的向量,然后通过Softmax运算将该向量的值归一化为[0,1],表示为e{c ij seg}k j=1}/kj=1 e{c ij seg}。
然后,我们得到了K个初始结果对应的K个权值映射{W ij seg}K j=1,其中权值较高(不确定性较低)的像素对最终结果的贡献较大,从而引导教师模型以较高的置信度注意结果之间的区域。
最后,综合分割预测y~it可以由~yit=kj=1wijseg~yijt导出。
对于另外两个辅助任务,值得注意的是,它们预测的是真实的回归值,而不是作为分割任务的概率值。 因此,熵不适合于它们的不确定度估计。 因此,我们直接通过平均运算得到聚合结果,即G~t=1Ikkj=1gijt,Z~t=1Ikkj=1zijt。 出于同样的原因,我们利用方差而不是熵作为这两个辅助任务聚合结果的不确定性,如下(Kendall and Gal,2017)。 总而言之,利用三个任务的聚合结果,我们可以通过以下方法获得所有任务的三倍不确定性映射:
4. 实验
4.1 实验设置
数据集:我们在2017 ACDC Challenge(Bernard et al.,2018)用于心脏分割和Promise12(Litjens et al.,2014)用于前列腺分割的公共数据集上评估我们的方法。 关于这两个数据集的详细数据统计列于表1和表2。
2017年ACDC数据集包含100名受试者,分别属于五种情况:健康、既往心肌梗死、扩张型心肌病、肥厚型心肌病和异常右心室。 每种类型包含20个受试者。 我们的目标是分割左心室区域。 为了公平的训练和评估,75个被试被分配到训练集,5个被分配到验证集,20个被分配到测试集。
Promise12数据集收集了50幅横向T2加权磁共振成像(MRI)图像,这些图像来自四个中心:挪威豪克兰大学医院(HK)、美国贝丝以色列女执事医疗中心(BIDMC)、英国伦敦大学学院(UCL)和荷兰拉德布德大学奈梅亨医疗中心(RUNMC)。 我们随机选取了35个样本作为训练集,5个样本作为验证集,10个样本作为测试集。 为了研究不同数量的标记和未标记数据对模型性能的影响,我们进一步将训练集分为标记集和未标记集的不同组合,表示为N/M,其中N和M分别为标记和未标记样本数。
评价:为了定量地评价系统的性能,我们使用了两个标准的评价指标,即DICE系数( D i c e = 2 ∗ ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ Dice=\frac{2*|X\cap Y|}{|X|+|Y|} Dice=∣X∣+∣Y∣2∗∣X∩Y∣)和JACCARD指数( J I = ∣ X ∩ Y ∣ ∣ X ∪ Y ∣ \mathbf{JI}={\frac{|X\cap Y|}{|X\cup Y|}} JI=∣X∪Y∣∣X∩Y∣)。 DICE和JI都评估预测和地面真相之间的重叠区域。 较高的分数表明两个指标的分割性能都较好。 此外,我们还将分割结果可视化,以直观地比较不同的分割方法。
4.2 超参数折中研究
我们有四个超参数来平衡损失项,即EQ中的α1、α2。 (4)方程中的μ1、μ2。 (5)。 为了研究它们的最优值,我们在2017年ACDC数据集上进行了基于五重交叉验证策略的实验。 具体而言,参考(阮等,2021),我们首先粗略定位了[0.2,4]区间内的α1,α2,μ2,[0.05,1]区间内的μ1。 然后,我们交替搜索一个超参数的最优值,并固定其余的超参数,直到遍历所有四个超参数。 结果在图给出 4. 在图 4(a),α2固定为1,μ1固定为0.2,μ2固定为1。 我们可以看到,当α1从0.2增加到1时,骰子和ji与α1呈正相关关系,但一旦α1超过1,骰子和ji就减少了。 因此,我们确定α1为1。 接下来,在图 4(b),研究了当α1为1,μ1固定为0.2,μ2固定为1时,不同α2值的影响。 很明显,当α2达到1时,骰子和吉的性能达到顶峰,表明预测是准确的。 对μ1和μ2的调查进行了类似的操作,结果显示在图 4©和(d)。 根据这些结果,我们可以确定这些折衷超参数的最优选择,即α1=1,α2=1,μ1=0。 2,μ2=1,将在后面的实验中得到应用。
4.3 对比实验
2017 ACDC的比较:为了证明所提出的方法在利用未标记和标记数据方面的优越性,我们将我们的方法与几种方法进行了比较,包括U-Net(Ronneberger et al.,2015)、Curruction(Kervadec et al.,2019)、Mean Teacher(Tarvainen and Valpola,2017)、UA-MT(Yu et al.,2019)、Multi-Task Attention-based半监督学习(MASSL)(Chen et al.,2019)、Shape-Aware(Shue et al.,2020)和基于互信息的半监督分割(MISSS)(Peng et al.,2021)。 值得注意的是,只有U-NET是在有限的标记数据下进行全监督训练的,其他的都是半监督训练。 表3是2017年ACDC数据集在不同N/M设置下的定量结果摘要。 正如所观察到的,我们提出的方法在所有N/M设置中以最高的骰子和JI值优于所有比较的方法。 具体而言,与全监督U-网相比,当n=5时,该方法能够充分利用未标记数据,并将DICE和JI分别从60.1%和47.3%提高到86.4%和77.6%。 对于半监督方法,UA-MT可以看作是一个原型,它也将不确定性集成到均值教师模型中。 与UA-MT相比,我们的方法在所有N/M情况下都产生了更好的结果。 即使对于次优方法,如形状感知和MISSS,我们的方法仍然提高了2%-5%的定量度量,尤其是在标记数据很少的情况下。
然而,在比较全监督U-NET和半监督方法的性能时,我们发现一些半监督方法,如课程、平均教师等,甚至比U-NET的性能更差。 其原因可能是当标记知识获取不足时,这些半监督方法往往会在未标记的数据学习中引入更多的非预期噪声,从而降低性能。 而UA-MT、MASSL、Shape-Aware和MISSS等方法在未标记数据的学习中引入了不确定性估计、注意力、形状约束和互信息正则化,提高了相应模型的鲁棒性。 因此,即使在只有6%和13%的标签水平上,这些半监督方法也可以以很大的差距超过U-NET。
为了检验我们的方法与其他方法相比的改进是否有统计学意义,我们对所有的比较结果进行配对Ttest。 从表3中可以看出,当标记数据很少时,我们提出的方法比所有对应的方法有显著的统计学改进,P<0.05,证明了所提出的方法的优越性。 随着标签数据的增加,所有方法都接近更多的监督,并呈上升趋势,差距逐渐缩小,但我们的方法仍然排名第一。 标准偏差也在表3的括号中提供,我们可以看到建议的方法实现了最小的标准偏差,表明我们的方法的优秀和稳健性。
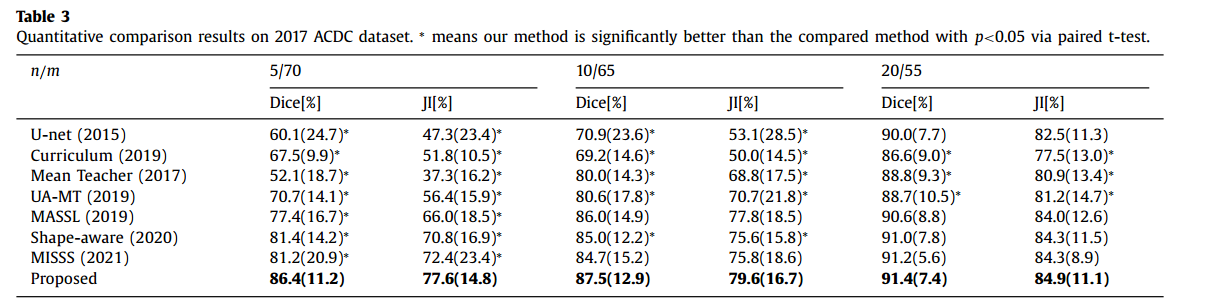
我们也在图5中给出了2017年ACDC数据集的定性比较结果。从图中可以看出,我们的方法可以更好的勾画出目标区域,边界更精确。相比之下,当可用的标记数据较少时,其他方法的结果总是包含更多的过度分割或未分割区域(分别用绿色和黄色标记)。这种错误预测在非UA-MT方法中尤为严重,这可以解释为UA-MT方法的不确定性估计有效地绕过了可信度降低较差的预测区域。在定量结果较高的Shape-aware和MISSS方面,也始终表现出良好的视觉效果。然而,与所有方法相比,我们的方法产生的假阳性和假阴性预测最少,从而在所有比较方法中产生的分割结果与基础事实最相似。这表明该方法可以更有效地利用大量未标记数据。
PROMISE12上的对比:为了检验我们的模型对其他数据集的泛化能力,我们进一步在PROMISE12数据集上进行了对比实验。统计结果和可视化结果分别见表4和图6。同样,在表4中,我们可以看到我们提出的方法在Dice和JI度量中都达到了最佳性能,并且在统计上比大多数方法都有显著的改进。与全监督方法相比,我们的方法显著提高了性能,当n=5时,Dice从56.7%上升到67.4%,JI从47.3%上升到51.9%,这支持了半监督学习的好处。在半监督方法中,Shape-aware在10个标签和15个标签的情况下分别以65.4%的Dice和68.3%的Dice排名第二。
然而,它仍然落后于我们的方法2.0%和2.1%。我们的方法始终以最小的标准差排名第一。
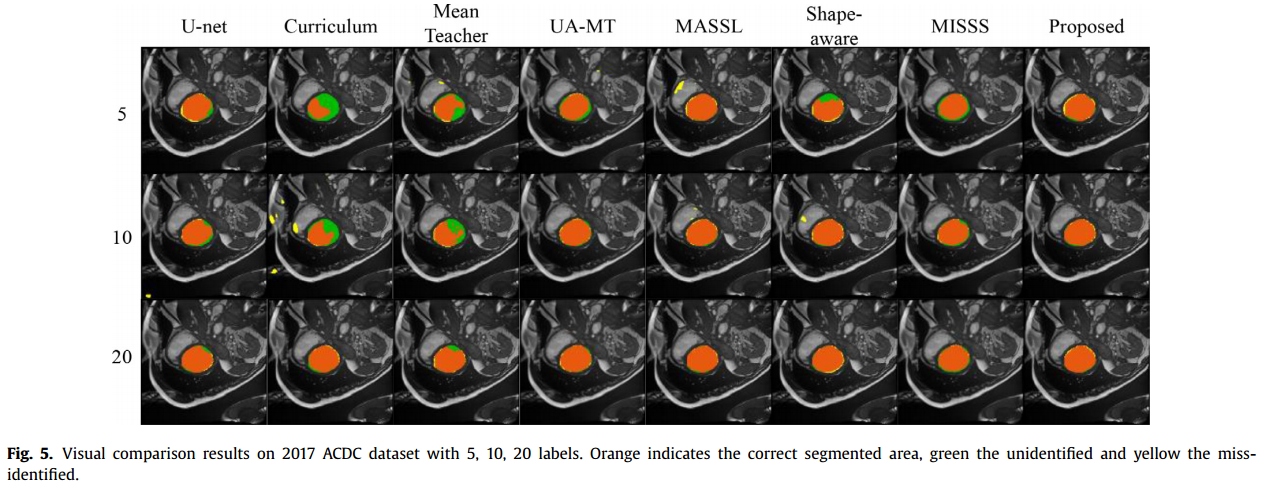
从图6的视觉结果不难发现,Unet只能分割一小部分目标区域,这是由于监督式训练方式,标签很少。相比之下,半监督方法可以在一定程度上缓解这一问题,将训练数据集扩展到未标记的数据,为网络的学习提供更多的知识。尽管如此,不同方法的结果仍然存在较大的波动。与表4中Dice和JI的最大值一致,我们的方法覆盖了最大的橙色区域和最小的黄色和绿色区域,这意味着我们的方法可以更准确地区分目标区域。
总而言之,无论是在2017年ACDC数据集还是在PROMISE12数据集上,我们的方法都能产生最好的定量结果,并且呈现出最接近地面事实的视觉分割效果,展示了我们方法的压倒性优势。
4.4 消融实验
为了考察该方法关键模块的贡献,我们进一步在2017年ACDC数据集上进行了一系列不同模型设置的实验。同样,我们也使用配对t检验来检验各成分所带来的改进的统计显著性。
两个辅助任务的贡献:首先,为了验证两个辅助任务的有效性,我们比较了(1)单独分割任务(Seg),(2)分割任务和SDF预测任务(Seg+ SDF)和(3)三个任务(Seg+ SDF +Rec)的模型。注意,教师模型没有被纳入这三个模型的实现。 定量结果如表5上半部分所示,从中我们可以看出SEG模型表现出最差的性能。 随着SDF预测任务和重建任务的加入,DICE和JI都有不同程度的提高,显示了这两个辅助任务对分割性能的积极影响。 特别是当n较小时,SDF的改进是显著的,表明它对未标记数据的利用有很大的贡献。
UWI模块的贡献:第二,由于UWI模块只应用在分割任务中,这里我们排除了其他因素的影响,在学生模型(S)和教师模型(T)中只保留了SEG模型。 为了研究UWI模块的影响,我们首先将学生模型和教师模型结合为原始平均教师模型(S+T),然后将不确定性估计与平均策略(UCA)和不确定性估计与UWI策略(UCN)结合到S+T模型中,并定量比较它们的结果。 表5的中间部分提出了详细的结果。 当n=5时,S+T模型的DICE和JI分别比S降低8.0%和10%。 这可以解释为当标记数据较少时,教师模型容易受到噪声的影响,从而降低了性能。 但考虑不确定度估计,当n=5时,S+T+UNCA模型的DICE和JI分别显著提高了18.7%和21.5%。 当n=5时,我们提出的S+T+UNCA模型比S+T+UNCA模型提高了DICE和JI的8.5%和11.7%。 较高的度量值证明了所提出的UWI策略的有效性,这可以归因于它对不同的MC采样结果赋予不同的权重。
三倍不确定性的贡献:第三,为了验证三倍不确定性的指导作用,我们首先从所提出的模型中去除对比损失(CTL),然后比较带有和不带有三倍不确定性(Tri-U)的裁剪模型,即所提出的w/o。Tri-U和CTL vs.建议的w/o。CTL。结果显示在表5的底部。结果表明,三不确定性的结合效果较好,Dice值分别为84.6%、87.1%、91.3%,JI值分别为75.6%、78.8%、84.9%,均超过了建议的w/o。Tri-U和CTL模型。研究表明,不确定性图可以有效地引导学生从老师那里学习到更可靠的知识,从而获得更高的分割性能。
对比学习的贡献:接下来,我们将提出的完整模型与不含CTL的模型进行比较,即提出的模型与不含CTL的模型进行比较。CTL,评价对比损失的有效性。结果也可以在表5的底部找到。在对比损失的帮助下,当n=5、10和20时,我们的模型在Dice上的性能分别提升了1.8%、0.4%、0.1%,证明了对比损失的积极作用。
模型级一致性损失的贡献:最后,我们在n=5的极端情况下进行了消融实验,以验证我们模型中提出的一致性损失的有效性。在本节中,我们将重点研究模型级一致性损失的贡献。为了实现这一点,我们分别将它们从完整的模型中分离出来,以检查它们对最终分割结果的影响。具体来说,在SDF预测任务、重建任务和分割任务上不存在一致性损失的模型分别记为Proposed w/o sdf_CSL、Proposed w/o rec_CSL和Proposed w/o seg_CSL。结果报告在表6的上半部分。我们可以看到,去除不同模型级别的一致性损失会导致不同程度的性能下降,特别是对于分割任务的一致性损失,在Dice中从86.4%显著下降到82.3%。这些结果表明,模型级一致性损失确实有助于增强学生模型。

任务级一致性损失的贡献:除了模型级一致性损失外,我们还研究了任务级一致性丢失。具体来说,我们将完整的模型与其变体模型进行了比较,后者抛弃了SDF预测任务与分割任务(表示为proposed w/o sdf_seg_CSL)之间的一致性损失,或者重建任务与分割任务(表示为proposed w/o rec_seg_CSL)之间的一致性损失。从表6的中间部分,我们可以发现,在这两种情况下,任务级一致性损失可以使性能提升3.4% Dice和0.7% Dice,这表明约束相关任务之间的一致性可以帮助挖掘更多有利于分割的信息。
4.5 图像级对比损耗与像素级对比损耗
考虑到我们的分割任务实际上是通过逐像素分类来完成的,我们进一步研究了像素级对比度损失是否比图像级对比度损失更有优势。具体来说,我们尝试用(Zhong et al ., 2021)中提出的像素级对比度损失取代图像级对比度损失。结果如表7所示,从中可以看出,像素级对比损耗的性能与图像级对比损耗的性能相当。造成这个结果的原因可以解释如下。与自然图像相比,医学图像的不同类别区域(通常是肿瘤像素)由于其在整个图像中所占的比例较小,并且因人而异,因此识别难度较大。为了准确区分不同类别的像素,需要高水平的专业知识进行监督。然而,在我们的论文中,我们解决了一个更具挑战性的情况,大多数监督是不可用的。这可能会给需要明确区分不同类别像素的像素级对比损失带来障碍。因此,降低了像素级对比损耗的性能。同时,考虑到像素级的比较损失会消耗大量的计算资源,因此我们将对比学习保持在图像级的形式。