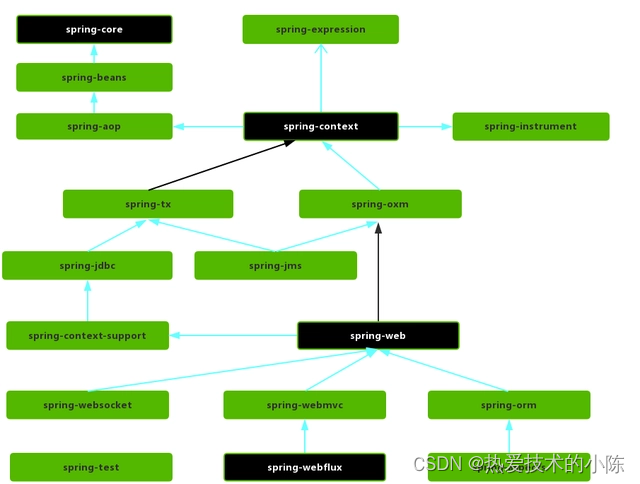
先讲一下mysql存储方式(innodb)
分为,聚簇索引和非聚簇索引。
聚簇索引,就是b+树的所有真实数据。
聚簇索引不是一种索引类型,而是一种数据存储方式。innoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。当表有聚簇索引时,它的行数据实际上存放在索引的叶子页中,因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。

插入操作时
每向表中插入一条记录,本质上就是向该表的[聚簇索引]以及所有二级索引代表的 B+ 树的节点中插入数据。
非聚簇索引,
就是b+树的所有带 主键的索引数据。
一、mysql锁介绍
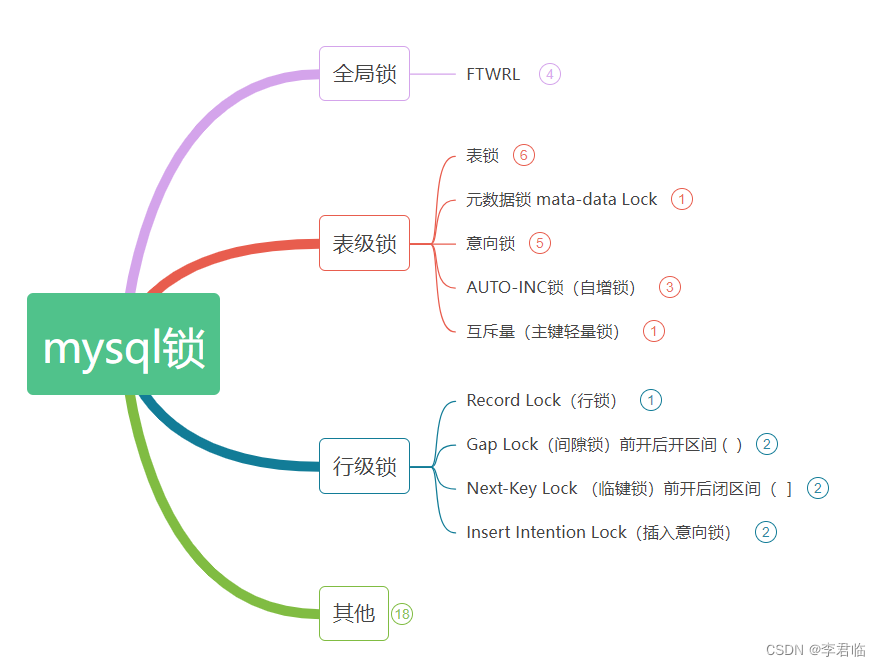
详细文件
mysql锁原图官网地址:
MySQL :: MySQL 5.7 Reference Manual :: 14.7.1 InnoDB Locking
二、mysql行锁机制
行级锁实际上是索引记录锁
2.1、示例数据如下

-- db01.user definition CREATE TABLE user ( id bigint NOT NULL AUTO_INCREMENT, name varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL, age int NOT NULL, no int NOT NULL COMMENT '编号', PRIMARY KEY (id), UNIQUE KEY user_un (no), KEY user_age_IDX (age) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=51 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; INSERT INTO db01.user (id, name, age, no) VALUES(0, '石昊', 0, 0); INSERT INTO db01.user (id, name, age, no) VALUES(5, '王林', 60, 50); INSERT INTO db01.user (id, name, age, no) VALUES(10, '叶凡', 70, 100); INSERT INTO db01.user (id, name, age, no) VALUES(15, '罗峰', 80, 110); INSERT INTO db01.user (id, name, age, no) VALUES(20, '萧炎', 100, 120); INSERT INTO db01.user (id, name, age, no) VALUES(25, '唐三', 130, 150);
2.2、主键索引 id
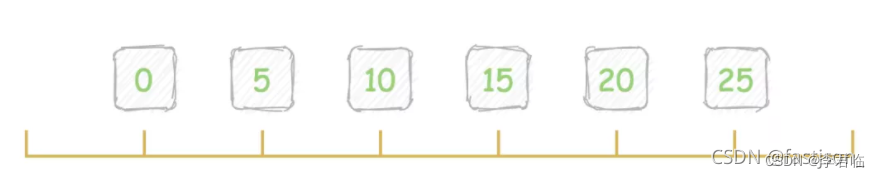
id 为 [0,5,10,15,20,25]
随时查询 锁情况 select * from performance_schema.data_locks
2.2.1 行锁 主键等值查询 —— 数据存在
select * from user where id = 10 for update;

2.2.2 间隙锁
2.2.2.1 间隙锁 主键等值查询 —— 数据不存在
select * from user where id = 11 for update;

这个在操作11,但是没有这个id=11的数据,避免其他事务冲突。
会去先加nextKey-Lock,(10,15],但是因为是等值查询,不需要锁15,所以会退化成间隙锁。
(10,15):10不需要锁,15也不需要锁,锁的是中间这些区间,所以是间隙锁。
tips 官网原话
默认情况下,在事务隔离级别InnoDB下运行 。
REPEATABLE READ在这种情况下,InnoDB使用下一键锁进行搜索和索引扫描,这可以防止幻像行(请参阅
第 15.7.4 节 “幻像行”)。为了防止幻像,请使用一种称为下一个键锁定的InnoDB算法,该算法将索引行锁定与间隙锁定相结合。 执行行级锁定的方式是,当它搜索或扫描表索引时,它会在遇到的索引记录上设置共享锁或独占锁。因此,行级锁实际上是索引记录锁。另外,索引记录上的下一键锁也会影响 索引记录之前的“间隙” 。也就是说,下一个键锁是索引记录锁加上索引记录之前间隙上的间隙锁。如果一个会话在记录上有共享锁或独占锁InnoDB`
R`R在一个索引中,另一个会话不能在索引顺序 之前的间隙中插入新的索引记录 。
MySQL 评估WHERE条件后,将释放不匹配行的记录锁。对于 UPDATE语句,InnoDB 是否进行“半一致”读取,从而将最新提交的版本返回给 MySQL,以便 MySQL 可以确定该行是否WHERE 符合UPDATE.
2.2.2.2 间隙锁 (当做问题)
select * from t where id >= 10 and id < 11 for update;
结果:
分析:
2.2.3 临键锁 主键范围查询
select * from user where id >= 10 for update;

2.3、非主键唯一索引

no 是唯一索引:[0,50,100,110,120,150]
2.3.1 行锁 唯一索引等值查询 —— 数据存在
select * from user where no = 100 for update;

问题:
select id from t where no = 100 for update;
会有变化吗? 答案是没有。
2.3.2 间隙锁 唯一索引等值查询 —— 数据不存在
select * from user where no = 111 for update;

非主键索引等值查询,数据不存在,相当于一个范围查询,仅仅会在非主键索引上加锁,加的还是间隙锁,左开右开区间;
2.3.3 临键锁 唯一索引返回查询
select * from user where no >= 110 and no < 115 for update;

- 120的临建锁(110,120] 110的临建锁(100,110] ,合并为(100,120]
- 对应的主键索引 15 也会加锁!
2.4、普通索引
age是普通索引。数据如下
[0,60,70,80,100,130]

2.4.1 行锁 普通索引等值查询 —— 数据存在
select * from user where age = 100 for update;

如果是:
select id from t where age = 100 for update; 效果一样
2.4.2 间隙锁
select * from user where age = 101 for update;

2.4.3 临键锁

select * from user where age > 70 and age <= 85 for update;
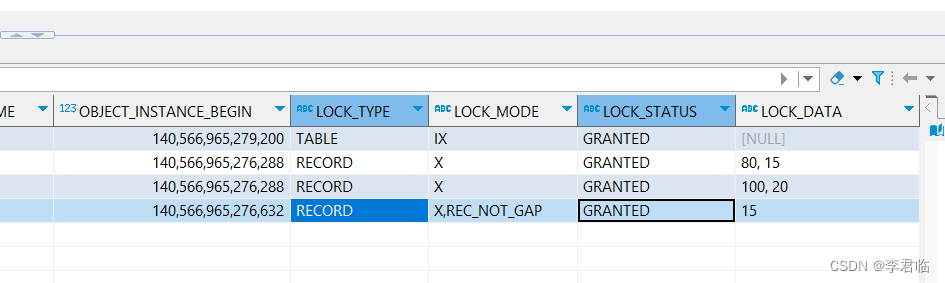
2.5、普通字段
对普通字段而言,无论是哪个查询,都需要扫描全部记录,所以这个锁直接加在了主键上,并且是锁住全部的区间。
begin; select * from user u where name = '石昊' for update commit; select id from user u where name = '石昊' for update; 也是一样。相当于一个事务。但是没有索引
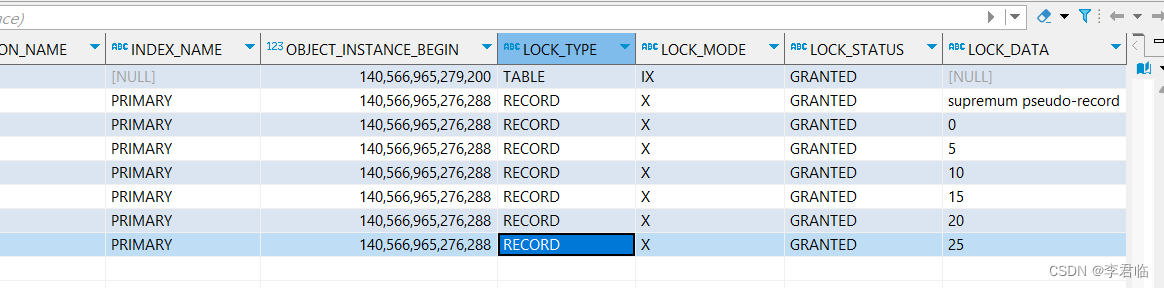
总结
如果规律记不住,可以直接通过分析 data_locks 的信息,进行判断加锁范围。
select * from performance_schema.data_locks;
| LOCK_MODE | LOCK_DATA | 锁范围 |
| X,REC_NOT_GAP | 15 | 15 那条数据的行锁 |
| X,GAP | 15 | 15 那条数据之前的间隙,不包含 15 |
| X | 15 | 15 那条数据的间隙,包含 15 |
- LOCK_MODE = X
- X,GAP
- X,REC_NOT_GAP
三、思考:
问题1:
针对id [0,5,10,15,20,25]
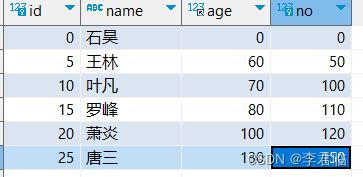
select * from user where id >= 10 and id < 11 for update;会生成什么样的锁。
结果:
分析:
问题2:
select id from user where no = 100 for share;
执行以下语句会怎么样:
update t set age = 1000 where id = 10; update t set no = 1101 where id = 10; update t set name = '小舞' where no = 100;







![[学习笔记]斜率优化dp 总结](https://img-blog.csdnimg.cn/d98657b1c36347b19239daabed7243be.png)