小黑代码1
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
# 数组长度
n = len(nums)
# 双指针
head = 0
tail = 0
# 中间变量
sum_ = 0
# 结果变量
res = n+1
# 开始双指针迭代
while tail < n:
sum_ += nums[tail]
tail += 1
while sum_ >= target:
if tail - head < res:
res = tail - head
sum_ -= nums[head]
head += 1
return res if res != n+1 else 0

小黑代码2
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
# 数组长度
n = len(nums)
# 构造累加数组
arr = [0]
for i in range(n):
arr.append(arr[i]+nums[i])
if arr[-1] < target:
return 0
print(arr)
# 结果变量
res = n+1
# 对每个元素进行二分查找
for i in range(1, n+1):
if arr[i] < target:
continue
t = self.bin_search(arr, 0, i-1, arr[i]-target)
if arr[t] > arr[i]-target:
t -= 1
if i-t < res:
print(t, i)
res = i-t
return res
def bin_search(self, arr, start, end, target):
while start <= end:
mid = (start + end) // 2
if arr[mid] >= target:
end = mid - 1
else:
start = mid + 1
return start
二分法
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
# 数组长度
n = len(nums)
# 构造累加数组
arr = [0]
for i in range(n):
arr.append(arr[i]+nums[i])
if arr[-1] < target:
return 0
# 结果变量
res = n+1
# 对每个元素进行二分查找
for i in range(n):
end = self.bin_search(arr, i+1, n, arr[i]+target)
if end <= n:
res = min(res, end-i)
return res
def bin_search(self, arr, start, end, target):
while start <= end:
mid = (start + end) // 2
if arr[mid] >= target:
end = mid - 1
else:
start = mid + 1
return start
数据库练习
570. 至少有5名直接下属的经理(小黑独立做出)
by 小黑
# Write your MySQL query statement below
SELECT
name
FROM
Employee
WHERE
id IN
(SELECT
managerId
FROM
Employee
WHERE
managerId IS NOT NULL
GROUP BY
managerId
HAVING
COUNT(name) >= 5)
# Write your MySQL query statement below
SELECT
e1.name
FROM
Employee e1 INNER JOIN
(SELECT
managerId
FROM
Employee
WHERE
managerId IS NOT NULL
GROUP BY
managerId
HAVING
COUNT(*) >= 5
) AS e2 ON e1.id = e2.managerId
pandas练习
import pandas as pd
def find_managers(employee: pd.DataFrame) -> pd.DataFrame:
# 分组,求和
manage_data = employee.groupby('managerId').size().reset_index(name='count')
# 筛选符合条件的数据
manage_id = list(manage_data[manage_data['count']>=5]['managerId'])
# 通过manageId找到对应姓名
bool_ = employee['id'].apply(lambda x:x in manage_id)
return pd.DataFrame(data={'name':employee['name'][bool_].tolist()}, columns=['name'])
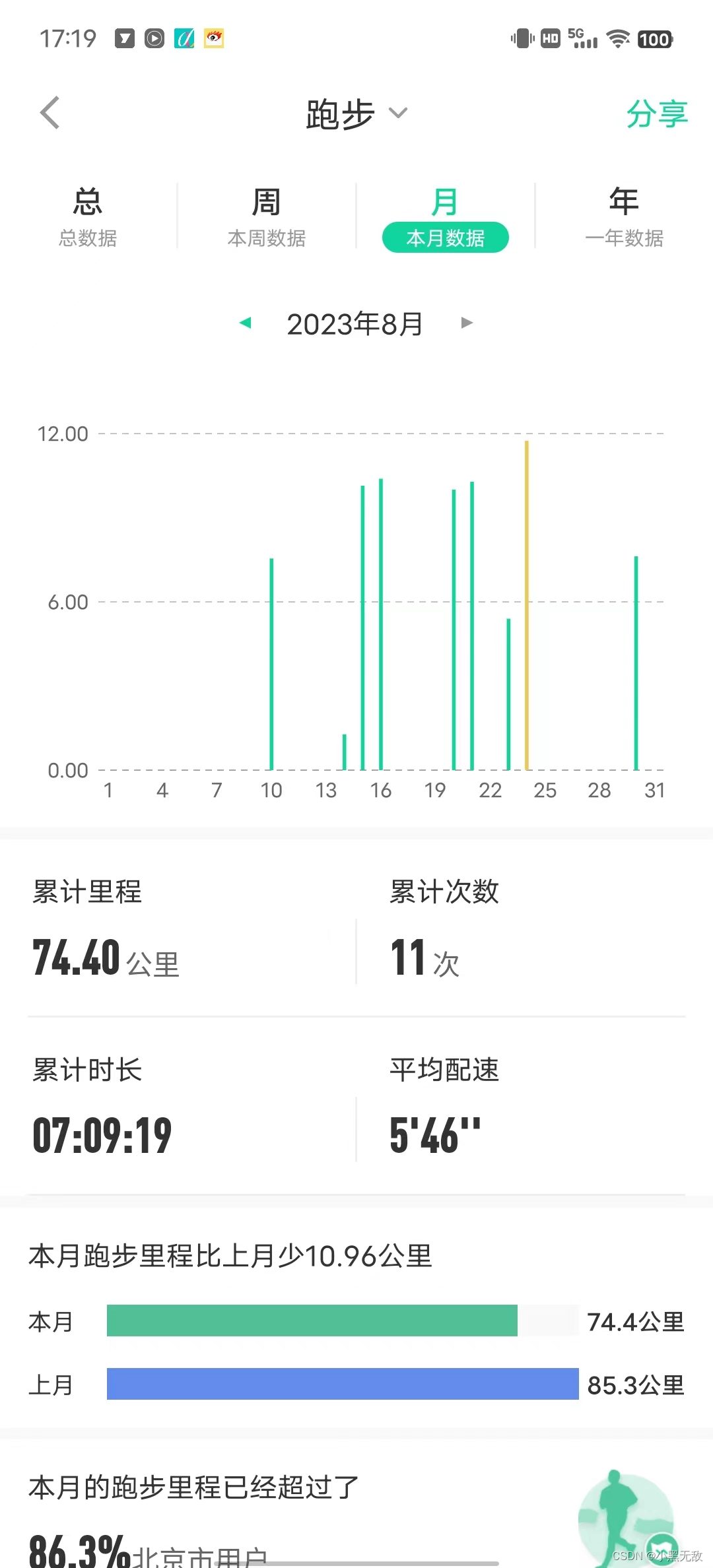
小黑生活
跑量少的可怜,工作以后要调整自己鸭
早餐干饭

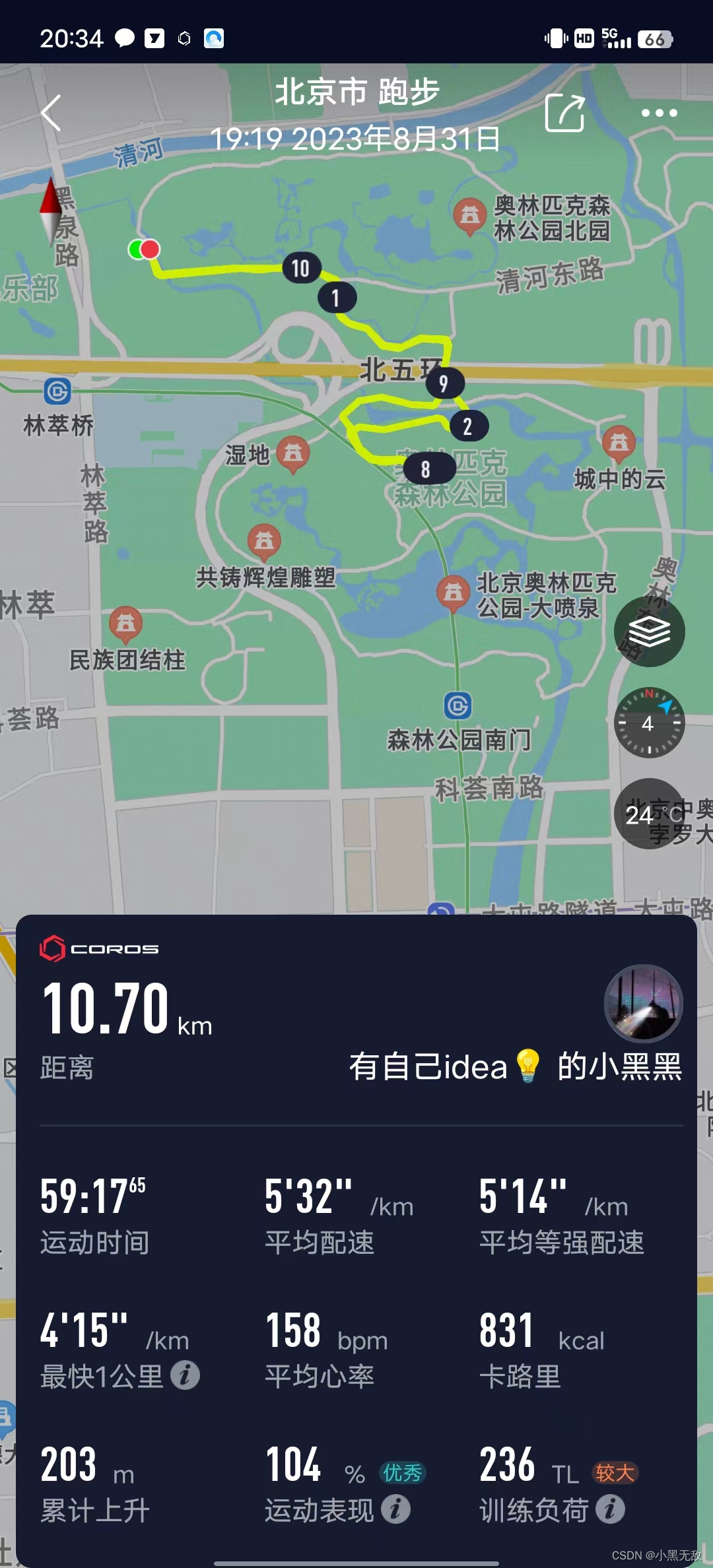
参加圣维拉的仰山跑爬坡赞助活动












早餐干饭