文章目录
- 前言
- 一、Mycat server.xml作用:
- 1.1 server.xml 作用:
- 1.2 定义数据库逻辑模式:
- 二、Mycat schema.xml作用:
- 2.1 schema 标签:
- 2.1.1 schema 中table 标签:
- 2.2 dataNode 标签:
- 2.3 dataHost 标签:
- 2.3.1 `balance` 参数的可选值及其作用如下:
- 2.3.2 `dbType`:
- 2.3.3 `dbDriver`:
- 2.3.4 writeType:
- 2.3.5 `<writeHost>` 和 `<readHost>` 标签:
- 2.3.6 switchType:主从切换配置:
- 2.3.6,1 当前dataHost只配置了一个writeHost :
- 2.3.6,1 当前dataHost只配置了多个writeHost :
- 2.3.7 mycat 读写分离:
- 2.3.8 dataHost 节点下多个writeHost:
- 三、Mycat `rule.xml`:
- 3.1 `rule.xml`作用:
- 3.2 <tableRule>`标签:
- 3.3 rule.xml 中tableRule 标签中的name 和 schema.xml 中的rule 参数
- 3.2` <function>`标签:
- 总结
前言
提示:本文mycat 版本为 1.6:
在安装Mycat 后,我们怎么连到Mycat ,怎么配置数据库和表及其路由规则,本文对此进行说明。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Mycat server.xml作用:
1.1 server.xml 作用:
server.xml 是 MyCAT 的主要配置文件,用于配置 MyCAT 服务器的各项参数和功能。它包含了以下主要作用和功能:
- 配置全局参数和特性:server.xml 文件中的 元素用于配置全局参数和特性,比如线程池大小、连接池大小、SQL 日志、监控等。
- 定义数据库逻辑模式:server.xml 文件中的 元素用于定义数据库逻辑模式,指定逻辑数据库的名称、数据源配置、表规则配置等。
1.2 定义数据库逻辑模式:
user 标签用来定义逻辑数据库:
<!--逻辑数据库连接 用到的用户名和密码 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<!--逻辑数据库可以看到的数据库,可以配置多个 -->
<property name="schemas">TESTDB1</property>
<!--默认的逻辑数据库 -->
<property name="defaultSchema">TESTDB1</property>
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
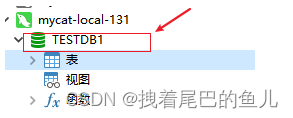
配置完成后当我们连接mycat后可以看到 逻辑的数据库:
二、Mycat schema.xml作用:
schema.xml 是 MyCAT 的配置文件之一,用于定义数据库的逻辑模式和映射关系。它的主要作用和功能如下:
-
定义逻辑数据库(schema)的结构:
schema.xml文件可以定义一个或多个逻辑数据库的结构。每个逻辑数据库通过<schema>元素定义,可以设置数据库名称、字符集、排序规则等属性。 -
配置数据源和数据节点:
schema.xml文件可以配置逻辑数据库的数据源和数据节点。通过<dataHost>元素设置数据源的主机、端口、用户名、密码等信息。通过<dataNode>元素设置数据节点的名称、数据源配置、存储库等信息。 -
配置数据表和映射规则:
schema.xml文件中可以配置逻辑数据库的数据表和映射规则。通过<table>元素设置数据表的名称、映射的数据节点、映射的物理表等信息。可以根据业务需求定义多个数据表,每个数据表可以指定它们映射的数据节点。
通过适当配置 schema.xml 文件,可以定义逻辑数据库的结构和映射关系,配置数据源和数据节点,定义数据表和映射规则,以及实现跨库查询和分片规则。 schema.xml 的配置对于 MyCAT 来说非常重要,它定义了数据库的逻辑结构和数据分布规则,使得 MyCAT 可以实现数据的分片存储和查询等功能。
2.1 schema 标签:
代码如下(示例):
<schema name="TESTDB1" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<!-- auto sharding by id (long) -->
<!--splitTableNames 启用<table name 属性使用逗号分割配置多个表,即多个表使用这个配置-->
<!--fetchStoreNodeByJdbc 启用ER表使用JDBC方式获取DataNode-->
<!--
<table name="customer" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-intfile" autoIncrement="true" fetchStoreNodeByJdbc="true">
<childTable name="customer_addr" primaryKey="id" joinKey="customer_id" parentKey="id"> </childTable>
</table>
-->
<table name="user" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="auto-sharding-by-mode" />
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
- name 声明的 TESTDB1 要和在server .xml 中定义的逻辑数据库保持对应;
- checkSQLschema:配置了 checkSQLschema 参数后,当执行查询时,MyCAT 会在查询语句中校验 SQL 中的 Schema 是否与配置的 Schema 匹配。如果匹配成功,则继续执行查询;如果匹配失败,则会返回错误信息。这样可以确保在执行查询之前进行额外的校验,避免错误的查询操作,提高数据安全性和正确性。如果将 checkSQLschema 参数设置为 false,则不会进行校验,直接执行查询;
- sqlMaxLimit:配置了 sqlMaxLimit 参数后,每个 SQL 查询的返回结果集的行数将被限制在配置的最大值之内。如果查询结果超过最大限制,MyCAT 将截断结果集,只返回最大限制内的行数;
这样可以防止一次查询返回过多的结果行,导致资源消耗过大或性能下降。通过限制每个查询的结果集大小,可以控制查询返回的数据量,提高查询的效率和可靠性。请注意,sqlMaxLimit 参数的默认值是 -1,表示不限制返回结果集的行数。如果将 sqlMaxLimit 设置为 0,表示禁止返回结果集; - randomDataNode:配置了 randomDataNode 参数后,当没有在 SQL 中指定数据节点的情况下,MyCAT 将随机选择一个数据节点来执行查询操作。这样可以充分利用各个数据节点之间的负载均衡,提高系统的性能和可靠性。如果没有配置 randomDataNode 参数或将其设置为 false,则在没有指定数据节点的情况下,MyCAT 将根据一定的规则选择一个默认的数据节点进行查询操作;
2.1.1 schema 中table 标签:
在 MyCAT 中, <table> 标签是用于配置 Schema 中的表的标签。下面列出了 <table> 标签中可以配置的参数及其作用:
-
name:定义表名 对应 实例中真实的表名; -
type:定义表的类型,可以是global或partitioned,用于区分全局表和分片表: -
- global:在 MyCAT 中,当表的
type参数设置为global,即采用全局表的分片策略时,DML(数据操作语句,如插入、更新、删除)语句会被发送到每个 DataNode 节点执行。
当执行一个 DML 操作(如插入一条数据)时,MyCAT 会将这个 DML 语句发送到所有 DataNode 节点的相同分片表上进行执行。这意味着每个 DataNode 节点都会执行一次相同的 DML 操作,以确保数据在整个集群中的一致性。
这种全局执行 DML 的方式适用于全局表中的数据需要在每个 DataNode 上都存在,且数据的操作会涉及整个集群的数据。例如,在 MyCAT 中建立的全局表用于在多个节点之间分享数据,并希望每个节点上的数据保持同步,这时会使用全局表以确保数据在整个集群中的一致性。
需要注意的是,当使用全局表时,DML 操作可能会带来更多的网络开销和延迟,因为需要将操作的请求发送到所有的 DataNode 节点并等待执行完成。因此,在选择分表策略时,需要根据具体的业务需求来评估和选择合适的分片策略。
- global:在 MyCAT 中,当表的
-
- partitioned:在 MyCAT 中,当表的
type参数设置为partitioned,即采用分区表的分片策略时,DML(数据操作语句,如插入、更新、删除)语句只会被发送到涉及到的特定 DataNode 节点进行执行。
当执行一个 DML 操作(如插入一条数据)时,MyCAT 会根据分区规则将这个 DML 语句发送到特定的分区节点上进行执行,而不会发送到每个 DataNode 节点。
在分区表中,数据被划分到不同的分区中,每个分区可以存储特定的数据范围。当执行 DML 操作时,MyCAT 会根据条件上的分区键信息来确定该操作应该发送到哪些分区节点上进行执行。这样可以减少数据传输和处理的开销,仅对受影响的分区进行操作,提高性能和效率。
需要注意的是,在分区表中,根据 DML 操作的条件和分区规则,MyCAT 可能会将 DML 语句发送到单个分区节点,也可能会发送到多个分区节点。这取决于操作的条件、分区规则和分区键的设置。
因此,在使用分区表时,DML 操作只会被发送到与操作相关的分区节点,而不会发送到每个 DataNode 节点。这样可以最大程度地减少跨节点的数据传输和处理,提高性能和效率。
- partitioned:在 MyCAT 中,当表的
-
- global 会被发送到每个节点,partitioned 只会被发送到其中给一个节点;
-
dataNode:定义表所属的数据节点。指定数据节点后,表的数据存放在该数据节点上:
dataNode 参数的作用是将表数据分布在不同的节点上,用于实现数据的分片和分布,以提高查询和操作的性能,并支持数据的水平扩展和并行处理。通过合理设置 dataNode 参数,可以让每个节点负责存储和处理一部分数据,从而实现数据的分布和分散。多个 DataNode 名称以逗号分隔:指定将数据存储在多个指定的 DataNode 上。 例如:
<table name="my_table" dataNode="dataNode1, dataNode2" /> -
rule:定义分片规则的名称,用于分片表,指定数据如何进行分片:
在 MyCAT 的<table>标签中,rule参数用于指定表的分片规则,即定义了数据分片的方式和策略。这个参数的作用是决定数据如何被分割和路由到不同的数据节点。rule参数的取值可以是以下几种形式之一: -
- 在 MyCAT 中,常用的几种分片规则包括:
-
-
mod(field, num):使用字段 field 的值进行取模操作,将数据分片为 num 个部分。适用于范围均匀的分片,比如将数据均匀地分布到多个节点中。
-
-
-
hash(field):使用字段 field 的哈希值进行分片。适用于数据分布较为均匀且分片粒度较小的情况。
-
-
-
range(field):根据字段 field 的值范围进行分片,将数据按照指定的范围划分到不同的节点中。适用于基于字段值范围进行区分的场景,如按照日期范围或者其他逻辑范围进行分片。
-
-
-
date_month(field):按照日期字段 field 的月份进行分片,适用于按照日期进行分片并且以月为粒度进行划分的场景。
-
-
-
date_date(field):按照具体日期字段 field 的日期进行分片,适用于按照日期进行分片并且以具体日期为粒度进行划分的场景。
-
-
-
- 这些分片规则都可以根据业务需求进行自定义操作,也可以根据不同的字段组合使用多个分片规则来定义表的分片策略。需要根据业务特点、数据量和负载情况来选择合适的分片规则,以实现数据的分布均衡和查询性能的优化。同时还需考虑数据增加和扩容时的可扩展性与数据平衡性。
-
-
keyColumns:定义分片表的分片键,指定参与分片的列或列的组合:
在 MyCAT 的 schema 配置文件中,<table>标签中的keyColumns参数用于指定用于分片的字段或字段组合keyColumns参数接受一个或多个字段名,多个字段名之间使用逗号分隔。这些字段将作为分片的关键列,用于确定数据被分配到哪个节点上。
示例:keyColumns参数指定了id字段作为分片的关键列,也即分片的依据。在执行查询 DML(Data Manipulation Language)操作时,MyCAT 将会根据id字段的值使用分片规则mod(id, 4)计算出一个分片结果(值为 0、1、2 或 3),然后将操作分配到对应的分片节点上。
keyColumns参数的作用是告诉 MyCAT 在执行查询 DML 操作时,根据指定的字段或字段组合来进行分片操作,从而实现在分布式环境下的数据拆分和负载均衡。
需要注意的是,keyColumns参数指定的字段必须是表中已经存在的字段,并且在分片规则中被使用或参考。同时,字段的顺序也会影响分片规则的计算结果。因此,在配置keyColumns时,需要根据具体业务需求和分片规则来合理选择和排列字段。
<table name="my_table" rule="mod(id, 4)" keyColumns="id" />
-
- 在 MyCAT 的 schema 配置文件中,
keyColumns和rule参数用于指定分片规则的关键列和实际的分片规则。它们之间的匹配规则如下:
- 在 MyCAT 的 schema 配置文件中,
-
-
keyColumns参数:指定用于分片的字段或字段组合。可以指定一个或多个字段,多个字段之间使用逗号分隔。这些字段将作为分片的关键列。
-
-
-
rule参数:指定实际的分片规则。使用一种支持的分片规则函数,并可以引用在keyColumns参数中指定的字段。
-
-
-
keyColumns参数中指定的字段与rule参数中使用的字段要一致。也就是说,keyColumns参数中的字段必须在rule参数中被使用或参考。
-
-
-
keyColumns参数中的字段顺序与rule参数中使用的字段顺序要一致。由于不同字段的值可能导致不同的分片结果,因此字段的顺序会影响分片规则的计算结果;
-
-
-
通过在标签中同时配置keyColumns和rule参数,可以确保分片规则的依据与实际规则的匹配,从而正确地将数据分布到各个分片节点上。需要注意的是,在配置分片规则时,要确保keyColumns参数指定的字段存在于表中,并且确保rule参数中使用的字段与keyColumns` 参数中指定的字段一致且顺序一致。否则,分片规则的计算结果可能不正确;
-
-
autoIncrement:定义自增列的名称,指定表中的自增列。用于在分片表中生成全局唯一的自增值,通常与 primaryKey (定义标准的主键)搭配使用; -
batchInsertSize:定义批量插入的大小,指定每次批量插入的数据行数:
在 MyCAT 的 schema 配置文件中,<table>标签中的batchInsertSize参数用于指定批量插入的大小阈值。batchInsertSize参数接受一个整数值,表示一次批量插入操作的最大插入记录数。需要注意的是,batchInsertSize参数作用于整个<table>标签,而不是每个具体的插入操作。也就是说,对于每次插入操作,只有插入记录数达到或超过batchInsertSize的阈值时,才会触发批量插入操作。如果插入记录数不足batchInsertSize,则会直接进行单条插入。
通过合理设置batchInsertSize参数,可以根据具体业务需求和系统资源状况来平衡插入操作的性能和资源消耗。
在 MyCAT 的 schema 配置文件中,<table>标签中的batchInsertSize参数默认值是 0。
当batchInsertSize参数的值为 0 时,表示不开启批量插入操作,即每条插入语句都将以单个记录的方式执行。 -
sequencedtrue/false 参数的作用如下: -
- 维持插入顺序:在某些业务场景下,需要保证插入操作按照提交的先后顺序依次执行,例如保存一串带有顺序关系的数据。通过设置
sequenced参数为true,确保插入顺序的一致性,避免乱序插入导致的数据混乱问题。
- 维持插入顺序:在某些业务场景下,需要保证插入操作按照提交的先后顺序依次执行,例如保存一串带有顺序关系的数据。通过设置
-
- 降低并发性能:由于插入操作需要按照顺序执行,
sequenced参数可能会降低系统的并发性能。因为并发插入操作无法并行执行,需要按顺序等待前一个插入操作完成后才能继续执行。
- 降低并发性能:由于插入操作需要按照顺序执行,
-
sequenced参数的默认值是false,而不是true。
-
- 如果在
<table>标签中没有显式地设置sequenced参数,那么默认情况下插入操作是不会按序列化方式执行的。这意味着插入操作可能会并发执行,并且不保证插入的顺序与客户端提交的顺序一致。
- 如果在
-
- 需要注意,当设置了
sequenced参数为true时,插入操作的执行顺序将严格按照客户端提交的顺序进行,可能会影响并发性能和吞吐量。因此,在开启sequenced参数之前,需要评估业务需求和性能要求,确保选择合适的配置。
- 需要注意,当设置了
-
ruleType:定义分片规则类型,可选值为partition、partition-2、string-hash和meta:
这些参数可以根据业务需求和系统架构的不同进行配置,以实现特定的数据分片和负载均衡策略。 -
- mycat schema 中 table标签中 ruleType,keyColumns,rule 参数的关系:
在 MyCAT 的 schema 配置文件中,<table>标签中的ruleType、keyColumns和rule参数相互关联,用于指定表的路由规则。
ruleType参数指定了该表的路由规则类型,可以是HASH、RANGE、PARTITION或GLOBAL。
- mycat schema 中 table标签中 ruleType,keyColumns,rule 参数的关系:
-
-
- 当
ruleType参数为HASH时,需要同时设置keyColumns和rule参数。keyColumns参数指定用于进行哈希分片的字段(可以是多个字段,以逗号分隔),rule参数指定对应的分片规则;
- 当
-
-
-
- 当
ruleType参数为RANGE时,也需要同时设置keyColumns和rule参数。keyColumns参数指定用于进行范围分片的字段(可以是一个字段或多个字段),rule参数指定对应的范围规则。
– - 当ruleType参数为PARTITION时,同样需要设置keyColumns和rule参数。keyColumns参数指定用于进行自定义分区的字段(可以是一个字段或多个字段),rule参数指定对应的自定义分区规则函数。
– - 当ruleType参数为GLOBAL时,不需要设置keyColumns和rule参数,表示该表是全局表,所有数据都存储在一个节点上。
– - 需要注意,具体的分片规则和函数需要在<function>标签中进行配置,而rule参数则是指定所使用的函数。具体的函数和规则配置方式可以在 MyCAT 的文档中进行查阅。
- 当
-
2.2 dataNode 标签:
在 MyCAT 的 schema 配置文件中,<dataNode> 标签用于定义数据节点(DataNode)及其相关配置。<dataNode> 标签可以设置以下参数:
<dataNode name="dn1" dataHost="localhost1" database="user" />
name:指定数据节点的名称,必须是唯一的。database:指定该数据节点要连接的数据库名称。tables:指定该数据节点上的表信息,可以是多个表,以逗号分隔。如果制定了表,则在
通过在 <dataNode> 标签中指定这些参数,可以定义和配置数据节点的信息,以便在 MyCAT 中进行数据路由和分片。需要注意的是,还需要在 <dataHost> 标签中定义数据主机的详细配置信息,如连接字符串和连接池设置等。详细的配置方式可以在 MyCAT 的文档中进行查阅。
2.3 dataHost 标签:
在 MyCAT 的 schema 配置文件中,<dataHost> 标签用于定义数据节点的主机信息和连接参数。<dataHost> 标签中的参数及其作用如下:
name:指定数据节点的名称,需要唯一。maxCon:指定该数据节点的最大连接数。minCon:指定该数据节点的最小空闲连接数。bal在 MyCAT 的标签中,balance` 参数用于指定负载均衡算法。
2.3.1 balance 参数的可选值及其作用如下:
balance 属性只决定 select(读)操作的负载策略。对于 update、insert 和 delete 等 write 操作,Mycat 默认总是将它们路由到 writeHost;
- 0 不启用读的分离: balance=0 时 所有读和写都发送到 第一个节点的writeHost;
- 1 启用读写分离,读操作从 第一个节点 的writeHost 下的所有 readHost 和 可读的所有writeHost 中随机选择一个进行读取
- 2 读操作 从所有的writeHost 及其下面所有readHost的,随机选择一个进行读取;
- 3 读操作从所有的readHost 随机选择一个进行读取;
2.3.2 dbType:
指定数据库类型,可选值有 MySQL、Oracle、SQLServer 等。
2.3.3 dbDriver:
指定连接数据库的驱动类。
2.3.4 writeType:
参数是用于指定负载均衡配置中读写分离模式的选择。 读写分离的配置,决定update、 delete、insert 语句的负载;
对于 标签中的 writeType 参数,它可以设置为以下值之一:
0:所有写操作都发送到可用的 writeHost 上 (默认第一个,第一个挂了以后发到第二个)。
1:所有写操作都随机的发送到 writeHost。
2.3.5 <writeHost> 和 <readHost> 标签:
在 MyCAT 的 <dataHost> 标签中,可以使用 <writeHost> 和 <readHost> 标签来定义主库和从库的数据节点。
<writeHost>标签用于定义主库数据节点,主要负责数据的写操作。通常情况下,只需定义一个主库数据节点。<readHost>标签用于定义从库数据节点,主要负责数据的读操作。可以定义多个从库数据节点,以实现读写分离和负载均衡。
这两个标签的参数及其作用如下:
host:指定数据节点的主机地址。url:指定连接数据库的 URL。user:指定连接数据库的用户名。password:指定连接数据库的密码。
示例配置:
<dataHost name="localhostdxfl1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="jdbc:mysql://192.168.75.128:3306" user="root"
password="123456">
<readHost host="hostS1" url="jdbc:mysql://192.168.75.129:3306" user="root" password="123456" />
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
在上述示例中,定义了一个数据节点 <dataHost>,名称为 localhostdxfl1。其中,使用 <writeHost> 标签定义了一个主库数据节点,主机地址为 hostM1,URL、用户名和密码等连接参数也有相应配置。同时,使用两个 <readHost> 标签定义了一个从库数据节点,主机地址分别为 hostS1 和 slave2.host,其他连接参数也有相应配置。
根据这些配置,MyCAT 将通过主库节点进行写操作,通过从库节点进行读操作。可以通过配置多个从库节点来实现读写分离和负载均衡,提高系统的容量和性能。
2.3.6 switchType:主从切换配置:
- -1:表示不自动切换;
- 1 :默认值,表示自动切换;
- 2 :基于 MySQL 主从同步的状态决定是否切换,心跳语句为 show slave status;
- 3:基于 MvsOLgalera cluster 的切换机制(适合集群)1.4.1),心跳语句为 show status like ‘wsrep%’。
2.3.6,1 当前dataHost只配置了一个writeHost :
如果只有一个 writeHost 且宕机了,此时 switchType 设为切换(1或2或3),那么读操作会被分配到 readHost(从库),但写操作会失败,因为 MySQL 从库默认是不接受写操作的。
switchType=“1” 的意思是基于 MySQL 主从同步的状态决定是否切换,如果主库宕机,MyCAT 会尝试将读操作切换到从库。但此时,如果有写操作请求,将无法写入,因为默认情况下,从库是只读的。
2.3.6,1 当前dataHost只配置了多个writeHost :
一般来说,如果设置的switchType参数能够触发切换(1或2或3),当 writeHost(主库)宕机后,Mycat 会将所有写入(write)和读取(read)的请求都转发到备用 writeHost(备用主库)上,它下面的readHost(从库)将会被忽视。也就是说,不会有读请求被发送到宕机主库下的从库。
这是因为在主从复制模式中,从库的数据同步依赖于主库。如果主库发生宕机,那么从库的数据将无法得到更新,因此为了数据的一致性,Mycat 会把所有操作都转到备用 writeHost。
2.3.7 mycat 读写分离:
读写分离是 MyCAT 自己内部实现的功能,无需额外的配置。MyCAT会根据配置的读写数据节点,自动将读请求路由到从库节点,写请求路由到主库节点,从而实现读写分离。
在 MyCAT 的配置文件中,通过 <dataHost> 标签定义主库和从库数据节点,并通过 <writeHost> 和 <readHost> 标签来具体配置主库和从库。
读写分离的实现可以通过以下两种方式之一:
- 在应用程序中指定查询语句的执行方式,将读操作的查询语句发送到从库节点,写操作的查询语句发送到主库节点。这种方式需要在应用程序中编码来实现读写分离策略。
- 使用 MyCAT 提供的注解(@readonlly / @write)或 SQL 注释(/*+MYCAT: mode=** */)来指定查询语句的执行方式。可通过将查询语句标记为只读或只写,让 MyCAT 自动将查询路由到相应的节点。
需要注意的是,MyCAT 提供了读写分离的功能,但在使用时需要保证从库与主库的数据一致性。在执行写操作后,需要确保数据会同步到从库,避免可能的读写不一致的情况发生。
2.3.8 dataHost 节点下多个writeHost:
在 Mycat 的配置中,dataHost 是可以设置多个 writeHost 的。writeHost 是待同步复制的主数据库。
设置多个 writeHost 主要是为了实现主-主复制,主-主复制中两个数据库服务器都可以进行读写操作,互为主备。在配置了多个 write 的情况下,虽然在 Mycat 中通常只有一个 writeHost 提供写服务(其他作为备用),但如果当前的写服务 writeHost 出现故障,可以迅速切换到备用的 writeHost 上,从而保证服务的可用性。
三、Mycat rule.xml:
3.1 rule.xml作用:
在 MyCAT 的 rule.xml 配置文件中,<tableRule> 标签用于定义表的分片规则;
3.2 `标签:
name:规则名称,用于标识该分片规则。可以自定义,但必须唯一。columns:分片键,即根据哪些列进行分片。可以指定一个或多个列,多个列之间使用逗号分隔。例如:id, create_time。- .
algorithm:分片算法,用于确定数据如何被分布到具体的分片节点上。可以使用内置的分片算法,如mod(取模计算),hash(哈希计算),range(范围判断),enum(枚举匹配)等。也可以自定义分片算法。
3.3 rule.xml 中tableRule 标签中的name 和 schema.xml 中的rule 参数
在 MyCAT 的配置中,rule.xml 和 schema.xml 是两个独立的配置文件用于不同的目的。
-
rule.xml文件用于定义数据库的分片规则和路由规则,包含<tableRule>标签用于定义表的分片规则。<tableRule>标签中的name参数是用于标识该分片规则的名称,只在rule.xml文件中有效。 -
schema.xml文件用于定义逻辑数据库(schema)的结构和映射,包含<schema>标签用于定义逻辑数据库的相关配置。<schema>标签中的rule参数用于指定适用于该逻辑数据库的分片规则,它的值是rule.xml文件中<tableRule>标签的名称。这样可以将逻辑数据库与特定的分片规则关联起来,实现数据的分片存储和查询。
在 MyCAT 的架构中,rule.xml 和 schema.xml 是相互关联的。在 schema.xml 文件中,可以通过指定 rule 参数,将逻辑数据库和对应的分片规则关联起来。这样在进行数据分片和路由时,MyCAT 将根据 schema.xml 中定义的规则,按照 rule.xml 中配置的分片规则进行数据的分片和路由。
因此,name 参数在 rule.xml 文件中唯一标识某个分片规则,而 rule 参数在 schema.xml 文件中指定适用于某个逻辑数据库的分片规则。它们共同协作,实现了数据库的分片和路由功能。
3.2 <function>标签:
在 MyCAT 的 rule.xml 配置文件中,<function> 标签用于定义路由函数,用于根据 SQL 条件判断将请求路由到对应的分片节点。下面是 <function> 标签中的主要参数的详细说明:
name:函数名称,用于标识该路由函数。可以自定义,但必须唯一。class:函数类名,指定实现路由函数的类名。可以是 MyCAT 内置的函数,也可以是自定义的函数。内置函数包括hash、mod、range等常用的函数。
通过配置 <function> 标签,可以定义路由函数,用于根据 SQL 条件判断将请求路由到合适的分片节点。可以使用内置的路由函数,也可以自定义路由函数,以满足业务需求。在 <tableRule> 标签中,可以指定使用哪个路由函数进行路由判断,以实现灵活的数据路由策略。
需要注意的是,函数在 rule.xml 文件中是全局定义的,可以在多个地方引用。在使用函数时,要确保函数的正确性和可用性,以避免路由判断错误产生的数据不一致问题。
总结
本文主要对mycat服务端配置文件的参数进行说明,server.xml 用来配置mycat 的服务端的参数;schema.xml 用来配置不同物理库中表的映射关系,rule.xml 用来制定具体的分片规则;