1. 部署grafana的配置文件修改
因为要采用发送邮件的方式通知告警内容所以,在部署grafana时要先配置好SMTP / Emailing的内容:
[smtp]
enabled = true # 开启smtp
host = smtp.mxhichina.com:465 #设置邮箱服务器地址
user = test@test.com #设置邮箱用户
password = test123456 #设置邮箱密码或授权码
from_address = test@test.com #设置邮箱发送方地址
from_name = Grafana #设置邮箱发送name
2. 配置contact points(告警通道)
使用contact points定义在告警发生时如何通知联系人。包括创建message template和contact points。
2.1 创建message template(消息模板)
grafana的消息模板基于go语言的模板系统。如下模板数据表列出了可用于模板的变量
| Name | Type | Notes |
|---|---|---|
| Receiver | string | Name of the contact point that the notification is being sent to. |
| Status | string | firing if at least one alert is firing, otherwise resolved. |
| Alerts | Alert | List of alert objects that are included in this notification (see below). |
| GroupLabels | KeyValue | Labels these alerts were grouped by. |
| CommonLabels | KeyValue | Labels common to all the alerts included in this notification. |
| CommonAnnotations | KeyValue | Annotations common to all the alerts included in this notification. |
| ExternalURL | string | Back link to the Grafana that sent the notification. If using external Alertmanager, back link to this Alertmanager. |
Alerts类型是一个过滤告警的函数:
Alerts.Firingreturns a list of firing alerts.Alerts.Resolvedreturns a list of resolved alerts.
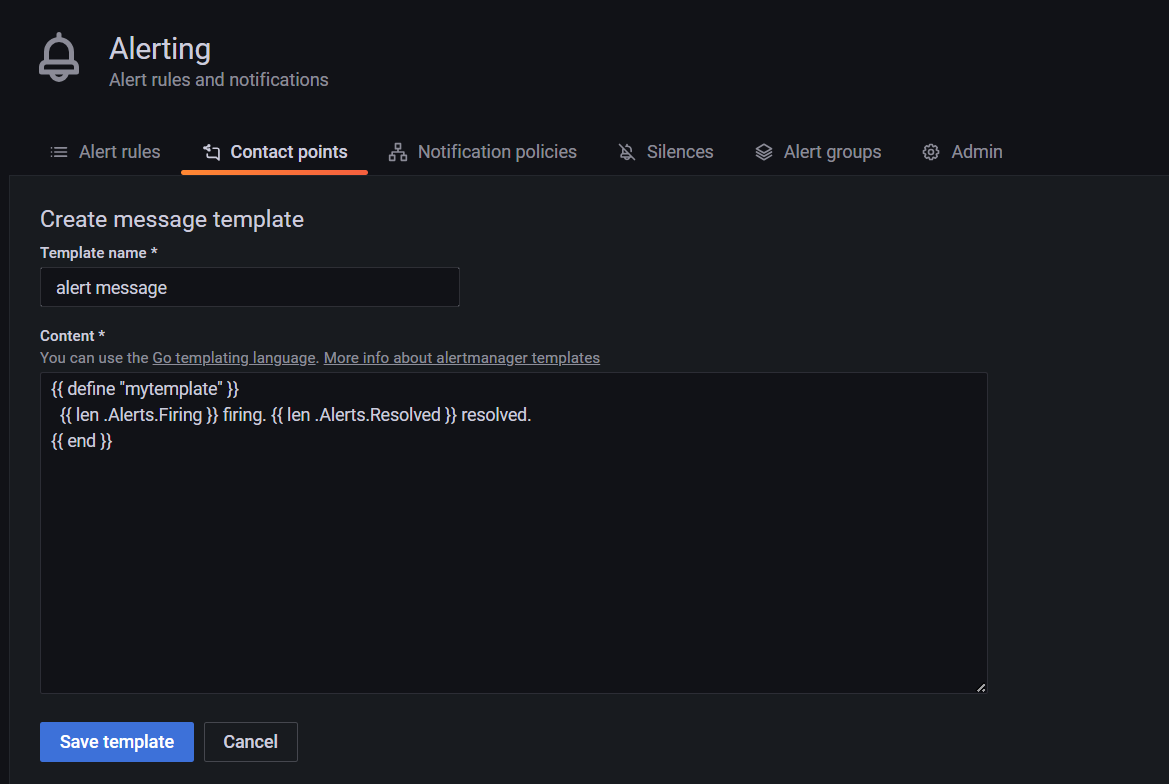
define用来设置模板名,是可选的,如果不设置默认采用Template name,最佳实践时与Template name 保持一致。
2.2 创建 contact point
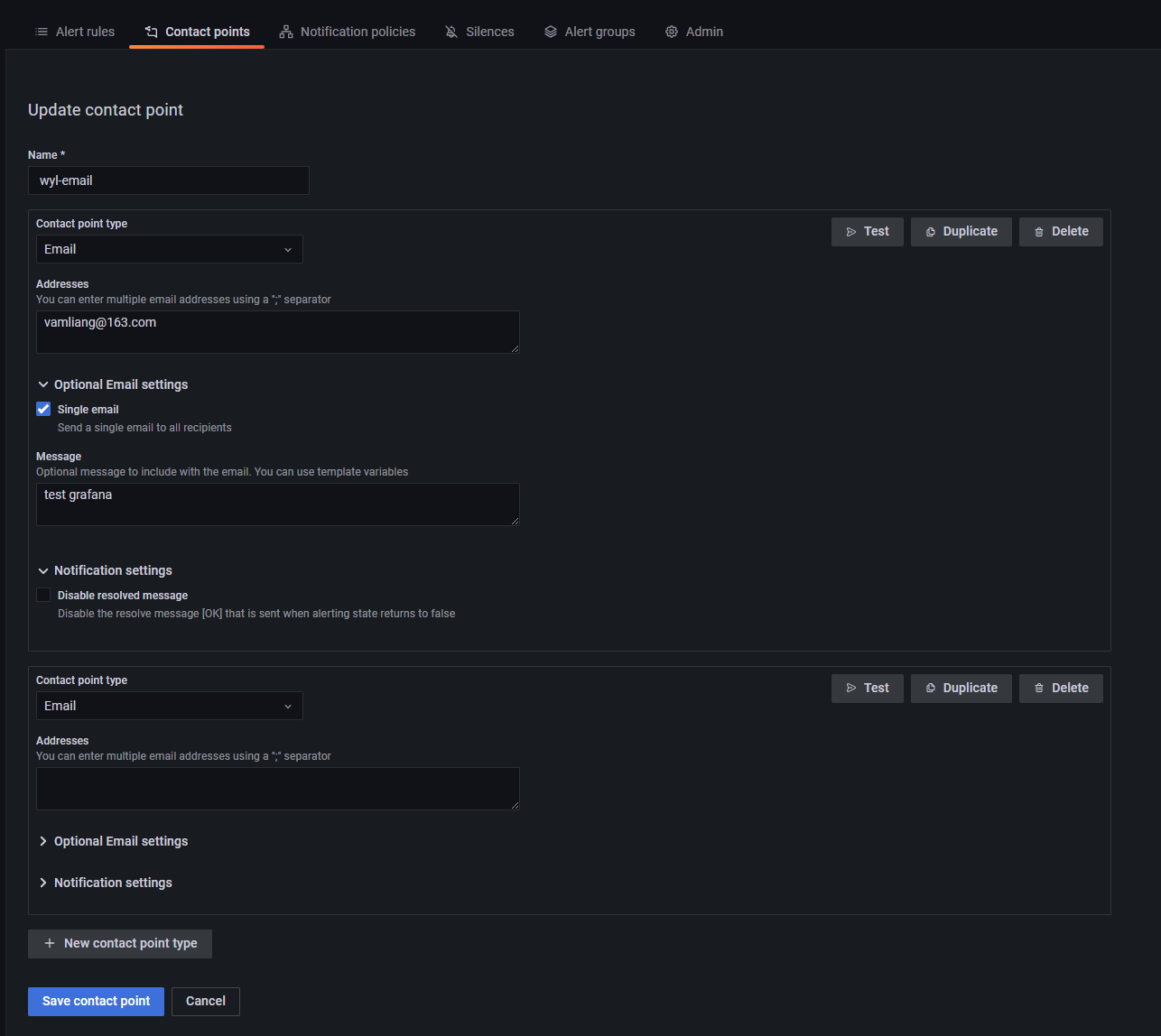
创建name和不同类型的contact,包括邮箱,钉钉等,同一个name下可以添加多个contact。详细说一下邮箱类型的tact:
-
Addresses: 接收通知的邮件地址,可以写多个,用英文分号(;)隔开。
-
Single email: 勾选表示发送一个邮件给所有的接受者。
-
message: 可以通过模板变量引用前面创建的模板:
{{template "alert message" .}} -
Disable resloved message: 是否关闭告警解决通知。
3. 创建通知策略(Notification policies)
通知策略通过label配置告警,通知指定 contact point设置接收告警通知的对象。
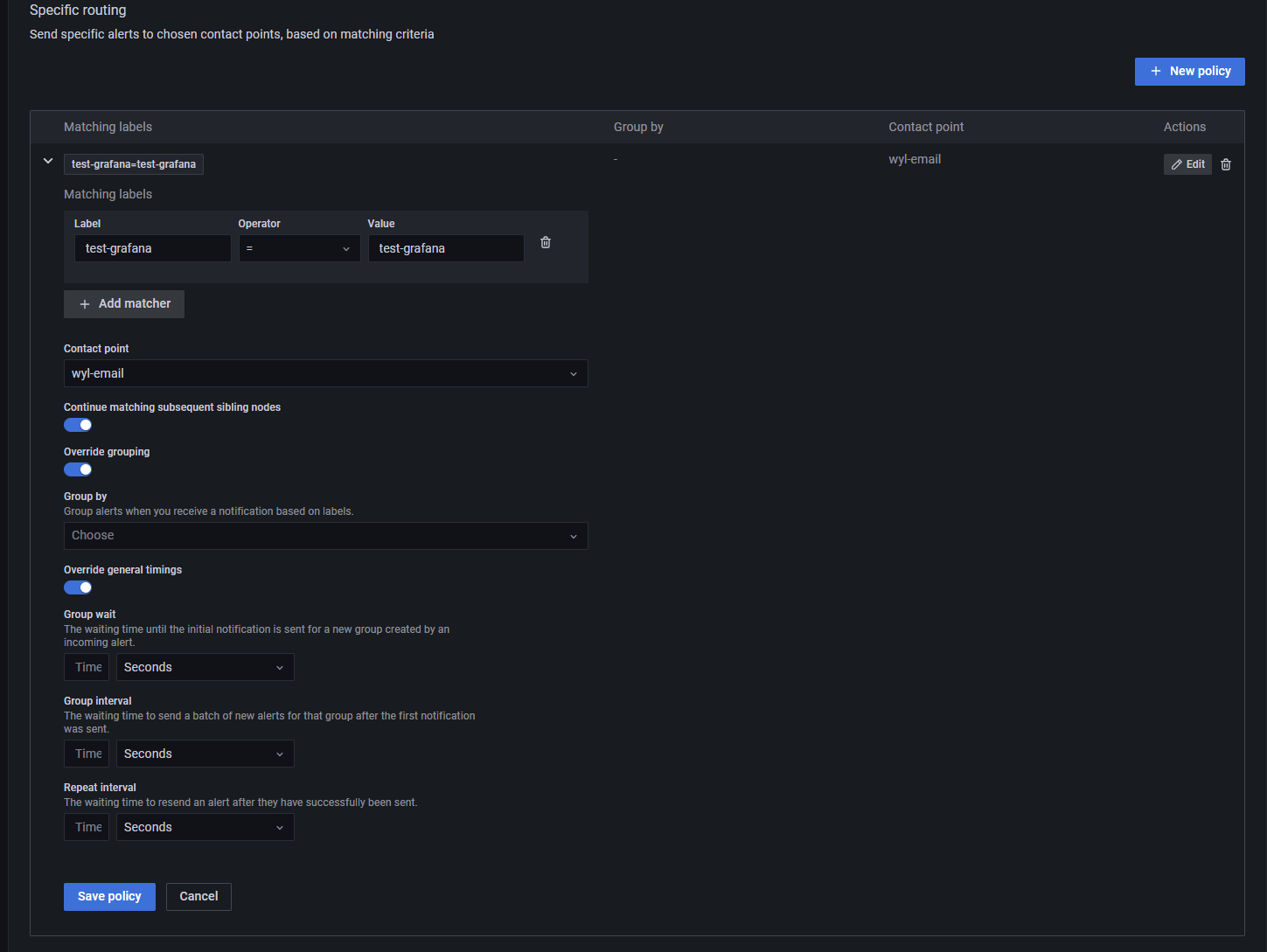
-
matching labels: 添加指定的匹配label用于匹配alerts。
-
contact point: 设置创建好的指定的contact point.
-
Continue matching subsequent sibling nodes: 是否继续匹配嵌套策略。
-
Override grouping:是一种告警策略设置,可用于覆盖默认的告警分组工作方式。默认情况下,Grafana根据告警规则的标签对告警进行分组。但是,对于某些特殊情况,用户可能希望以不同的方式进行告警分组,这时就可以使用Override grouping来实现。
使用Override grouping,用户可以通过自定义指标和筛选条件来定义告警的分组方式。这样可以根据特定的业务需求,将相关的告警归为一组,便于在仪表盘中统一管理和查看。
Override grouping的设置涉及以下几个重要的概念:
- 可聚合的字段:定义用于分组的字段,可以是任意的标签或指标。
- 聚合器:确定了要使用哪种方法来聚合分组,如平均值、最大值、最小值等。
- 时间范围:告警分组的时间范围,可以是一个固定的时间段或相对于当前时间的一段时间。
用户可以根据具体情况选择合适的聚合字段、聚合器和时间范围来定义告警的分组方式。通过Override grouping,用户可以更加灵活地管理和控制告警的分组行为,从而更好地满足业务需求。
-
Override general timings(覆盖一般定时):用来覆盖通用的重复和间隔定时。
具体来说,Grafana的告警策略中,可以设置一个重复间隔时间(Repeat interval),用于确定告警规则检查条件的重复间隔。默认情况下,这个间隔会使用Grafana的全局设置。
然而,有时候我们希望针对特定的告警规则使用不同的重复间隔时间,这就可以使用Override general timings(覆盖一般定时)来实现。通过勾选此选项,并设置相应的重复间隔时间,可以覆盖全局设置,使特定的告警规则使用不同的重复间隔时间。
这样做的好处是,可以根据特定的告警规则的需求,灵活地定义重复间隔时间,以更加精确和准确地监控和警告系统的状态变化。这对于保证系统的稳定性、性能和安全性非常有帮助。
-
Group wait: 为传入警报创建的新组发送初始通知之前的等待时间。
-
Group interval: 发送第一个通知后为该组发送一批新警报的等待时间。
-
Repeat interval: 成功发送警报后重新发送警报的等待时间。
-
4. 创建告警规则(rule)
rule有三种类型:
-
Cortex or Loki managed alerting rule:创建由Cortex或者Loki管理的rule;需要对Prometheus或者其他数据源有读写权限。
Cortex和Loki都是与Grafana密切相关的工具。
Cortex是一个可扩展、多租户、分布式的时间序列数据库。它能够接收和存储大规模的指标数据,并提供高速查询、聚合和处理数据的能力。Cortex的设计目标是能够处理海量的时间序列数据,并且具有可水平扩展性和高可用性。Cortex允许用户通过内置的查询语言PromQL来查询和分析指标数据,并支持数据的可视化和报表功能。Cortex还提供了横向扩展的能力,可以轻松地增加存储容量和查询吞吐量。因此,Cortex适用于大规模监控系统中需要存储和查询大量指标数据的场景。
Loki是一个用于日志聚合和存储的系统。它可以接收多个来源的日志数据,并将它们存储为可搜索和可查询的格式。与传统的日志存储系统相比,Loki采用了一种高效的存储和索引方法,可以充分利用现代存储技术和硬件,以提供更高的性能和可扩展性。Loki支持使用标准的日志查询语言PromQL来查询和分析日志数据,并且与Cortex集成,可以实现和指标数据的混合查询和分析。此外,Loki还提供了强大的数据可视化和报表功能,可以方便地展示和监控系统的日志信息。
综上所述,Cortex和Loki是Grafana监控和可视化平台的两个重要组成部分。Cortex用于存储和查询大规模的指标数据,而Loki则用于存储和查询系统的日志数据。它们都具有高性能、可扩展性和易于使用的特点,能够满足大规模监控系统中对指标和日志数据的存储、查询和分析需求。
-
Cortex or Loki managed recording rule:创建recording类型的rule。
-
Grafana managed alerting rule:创建grafana管理的告警规则,我们主要介绍这个类型的规则。
4.2 Grafana managed alerting rule
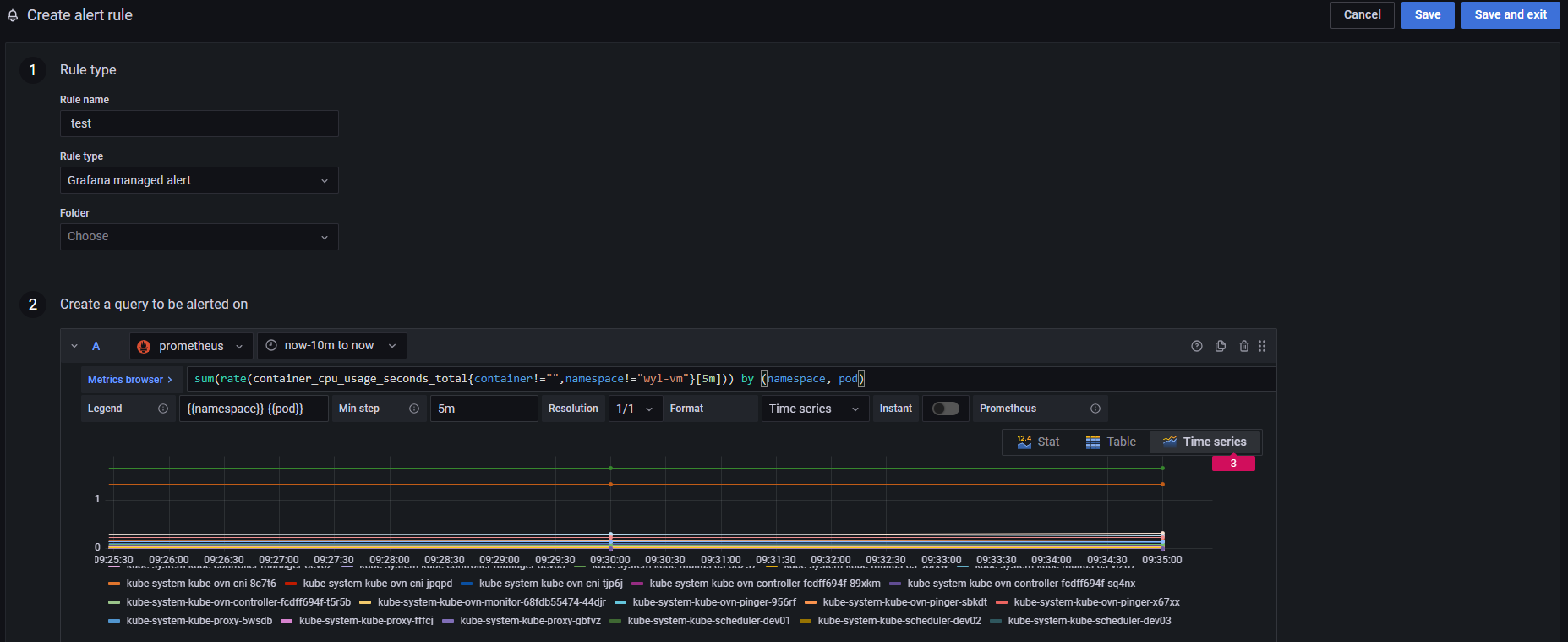
-
rule name: 告警规则名。
-
rule type: 告警规则类型。
-
Folder: 选择所属的Folder。
-
创建告警规则语句:
-
选择数据源为Prometheus
-
查询展示的最近10分钟的数据。
-
Metrics browser: 设定数据查询的语句使用PromQL语法。
-
Legend: 根据查询出的数据变量设置显示指标名。
-
Min step: 最小步长表示图形里每两个点的最小数据间隔是多少,例如:这里我设置了 200,那表示图形上每隔 200 个单位才会有一个点。
-
Resolution: 这表示其数据精度是怎样的,是 1 比 1 的精度,还是原有的 1/2,还是 1/3 等等。如果是 1/2 的话,那么就是原本 1 个单位显示一个点,现在 2 个单位合并起来显示成一个点了,那么其精度就变低了。
-
Format: 表示你的数据格式是什么,这里有:Time series、Table、Heap Map 三个选项。Time series 表示是时间序列数据,即随着时间的流动有源源不断的数据。Table 表示是一个表格数据。Heap Map 表示是热力图数据。
-
instant: 勾选时查询只在指定的单个时间点上执行,这对于需要聚合或对单个时间点数据感兴趣的场景非常有用。面板的时间选择器将被禁用,因为查询仅在一个固定时间点上执行。不勾选时:查询将返回一个时间范围内的数据,这对于需要在一段时间内进行数据分析或比较的情况非常有用。面板的时间选择器将启用,可以选择查询的时间范围。

创建Expression(表达式):
-
classic condition:
-
avg(): 用于计算一段时间内的平均值。适用于告警需要基于平均值的场景。例如,如果需要在CPU平均负载超过阈值时触发告警,可以使用avg()函数。 -
last(): 用于获取时间段内最后一个数据点的值。适用于告警需要基于最后一个数据点的场景。例如,如果需要在最后一个数据点超过阈值时触发告警,可以使用last()函数。 -
max(): 用于计算一段时间内的最大值。适用于告警需要基于最大值的场景。例如,如果需要在CPU负载的最大值超过阈值时触发告警,可以使用max()函数。 -
min(): 用于计算一段时间内的最小值。适用于告警需要基于最小值的场景。例如,如果需要在CPU负载的最小值低于阈值时触发告警,可以使用min()函数。 -
sum(): 用于计算一段时间内的总和。适用于告警需要基于总和的场景。例如,如果需要在一段时间内的请求数总和超过阈值时触发告警,可以使用sum()函数。 -
count(): 用于计算一段时间内的数据点数量。适用于告警需要基于数据点数量的场景。例如,如果需要在一段时间内的请求数量超过阈值时触发告警,可以使用count()函数。
-
Define alert conditions: 定义告警状态:
-
condition: 选择基于哪个query或者表达式进行告警。
-
Evaluate: 设置多久评估一次告警条件,
-
For: 满足条件持续多久触发告警,改变告警状态到firing.
-
Configure no data and error handling: 设定无数错和错误处理:
No Data Option Description No Data Create a new alert DatasourceNoDatawith the name and UID of the alert rule, and UID of the datasource that returned no data as labels.Alerting Set alert rule state to Alerting.Ok Set alert rule state to Normal.Error or timeout option Description Alerting Set alert rule state to AlertingOK Set alert rule state to NormalError Create a new alert DatasourceErrorwith the name and UID of the alert rule, and UID of the datasource that returned no data as labels.
Add details for your alert: 添加其他额外的alert信息。
-