分析&回答
- Flink 1.1.0:第一次引入 SQL 模块,并且提供 TableAPI,当然,这时候的功能还非常有限。
- Flink 1.3.0:在 Streaming SQL 上支持了 Retractions,显著提高了 Streaming SQL 的易用性,使得 Flink SQL 支持了复杂的 Unbounded 聚合连接。
- Flink 1.5.0:SQL Client 的引入,标志着 Flink SQL 开始提供纯 SQL 文本。
- Flink 1.9.0:抽象了 Table 的 Planner 接口,引入了单独的 Blink Table 模块。Blink Table 模块是阿里巴巴内部的 SQL 层版本,不仅在结构上有重大变更,在功能特性上也更加强大和完善。
- Flink 1.10.0:作为第一个 Blink 基本完成 merge 的版本,修复了大量遗留的问题,并给 DDL 带来了 Watermark 的语法,也给 Batch SQL 带来了完整的 TPC-DS 支持和高效的性能。
CDC 支持
SQL 1.11 Flink SQL 在原有的基础上扩展了新场景的支持:
- Flink SQL 引入了对 CDC(Change Data Capture,变动数据捕获)的支持,它使 Flink 可以方便地通过像 Debezium 这类工具来翻译和消费数据库的变动日志。
- Flink SQL 扩展了类 Filesystem connector 对实时化用户场景和格式的支持,从而可以支持将流式数据从 Kafka 写入 Hive 等场景。
CDC 支持
CDC 格式是数据库中一种常用的模式,业务上典型的应用是通过工具(比如 Debezium 或 Canal)将 CDC 数据通过特定的格式从数据库中导出到 Kafka 中。在以前,业务上需要定义特殊的逻辑来解析 CDC 数据,并把它转换成一般的 Insert-only 数据,后续的处理逻辑需要考虑到这种特殊性,这种 work-around 的方式无疑给业务上带来了不必要的复杂性。如果 Flink SQL 引擎能原生支持 CDC 数据的输入,将 CDC 对接到 Flink SQL 的 Changelog Stream 概念上,将会大大降低用户业务的复杂度。

流计算的本质是就是不断更新、不断改变结果的计算。考虑一个简单的聚合 SQL,流计算中,每次计算产生的聚合值其实都是一个局部值,所以会产生 Changelog Stream。在以前想要把聚合的数据输出到 Kafka 中,如上图所示,几乎是不可能的,因为 Kafka 只能接收 Insert-only 的数据。Flink 之前主要是因为 Source&Sink 接口的限制,导致不能支持 CDC 数据的输入。
Flink SQL 1.11 经过了大量的接口重构,在新的 Source&Sink 接口上,支持了 CDC 数据的输入和输出,并且支持了 Debezium 与 Canal 格式(FLIP-105)。这一改动使动态 Table Source 不再只支持 append-only 的操作,而且可以导入外部的修改日志(插入事件)将它们翻译为对应的修改操作(插入、修改和删除)并将这些操作与操作的类型发送到后续的流中。
如上图所示,理论上,CDC 同步到 Kafka 的数据就是 Append 的一个流,只是在格式中含有 Changelog 的标识:
- 一种方式是把 Changlog 标识看做一个普通字段,这也是目前普遍的使用方式。
- 在 Flink 1.11 后,可以将它声明成 Changelog 的格式,Flink 内部机制支持 Interpret Changelog,可以原生识别出这个特殊的流,将其转换为 Flink 的 Changlog Stream,并按照 SQL 的语义处理;同理,Flink SQL 也具有输出 Change Stream 的能力 (Flink 1.11 暂无内置实现),这就意味着,你可以将任意类型的 SQL 写入到 Kafka 中,只要有 Changelog 支持的 Format。
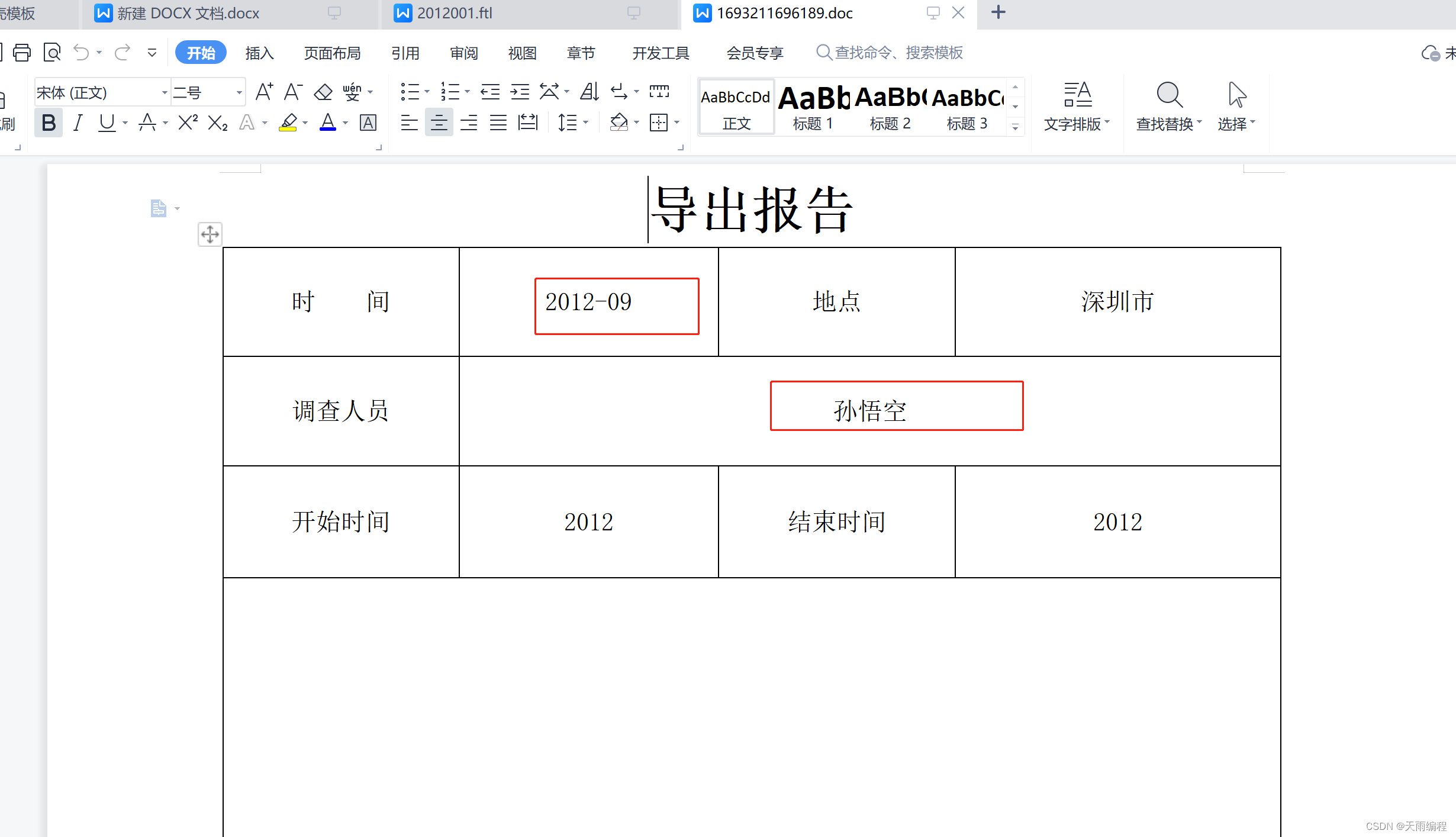
- Flink 1.11 彻底的抛弃了推断 PK这个机制,不再从 Query 来推断 PK 了,而是完全依赖 Create table 语法。比如 Create 一个 jdbc_table,需要在定义中显式地写好 Primary Key(后面 NOT ENFORCED 的意思是不强校验,因为 Connector 也许没有具备 PK 的强校验的能力)。当指定了 PK,就相当于就告诉框架这个Jdbc Sink 会按照对应的 Key 来进行更新。如此,就跟 Query 完全没有关系了,这样的设计可以定义得非常清晰,如何更新完全按照设置的定义来。
Hive 流批一体
首先看传统的 Hive 数仓。一个典型的 Hive 数仓如下图所示。一般来说,ETL 使用调度工具来调度作业,比如作业每天调度一次或者每小时调度一次。这里的调度,其实也是一个叠加的延迟。调度产生 Table1,再产生 Table2,再调度产生 Table3,计算延时需要叠加起来。

问题是慢,延迟大,并且 Ad-hoc 分析延迟也比较大,因为前面的数据入库,或者前面的调度的 ETL 会有很大的延迟。Ad-hoc 分析再快返回,看到的也是历史数据。
所以现在流行构建实时数仓,从 Kafka 读计算写入 Kafka,最后再输出到 BI DB,BI DB 提供实时的数据服务,可以实时查询。Kafka 的 ETL 为实时作业,它的延时甚至可能达到毫秒级。实时数仓依赖 Queue,它的所有数据存储都是基于 Queue 或者实时数据库,这样实时性很好,延时低。但是:
- 第一,基于 Queue,一般来说就是行存加 Queue,存储效率其实不高。
- 第二,基于预计算,最终会落到 BI DB,已经是聚合好的数据了,没有历史数据。而且 Kafka 存的一般来说都是 15 天以内的数据,没有历史数据,意味着无法进行 Ad-hoc 分析。所有的分析全是预定义好的,必须要起对应的实时作业,且写到 DB 中,这样才可用。对比来说,Hive 数仓的好处在于它可以进行 Ad-hoc 分析,想要什么结果,就可以随时得到什么结果。
能否结合离线数仓和实时数仓两者的优势,然后构建一个 Lambda 的架构?
核心问题在于成本过高。无论是维护成本、计算成本还是存储成本等都很高。并且两边的数据还要保持一致性,离线数仓写完 Hive 数仓、SQL,然后实时数仓也要写完相应 SQL,将造成大量的重复开发。还可能存在团队上分为离线团队和实时团队,两个团队之间的沟通、迁移、对数据等将带来大量人力成本。如今,实时分析会越来越多,不断的发生迁移,导致重复开发的成本也越来越高。少部分重要的作业尚可接受,如果是大量的作业,维护成本其实是非常大的。
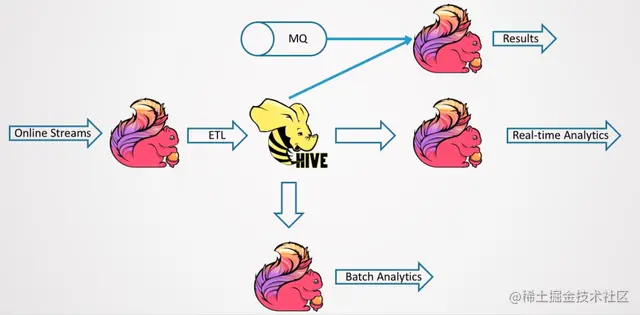
如何既享受 Ad-hoc 的好处,又能实现实时化的优势?一种思路是将 Hive 的离线数仓进行实时化,就算不能毫秒级的实时,准实时也好。所以,Flink 1.11 在 Hive 流批一体上做了一些探索和尝试,如下图所示。它能实时地按 Streaming 的方式来导出数据,写到 BI DB 中,并且这套系统也可以用分析计算框架来进行 Ad-hoc 的分析。这个图当中,最重要的就是 Flink Streaming 的导入。
反思&扩展
其实用与没用不需要绝对回答,根据你自己实际的使用来就好了。
Flink SQL很多时候在测试的时候很好用,在单纯实时计算的时候也非常不错,如果你要做实时数仓,其实并不一定是最好的选择,能高效低成本的打通离线数据和实时数据才是王道。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!