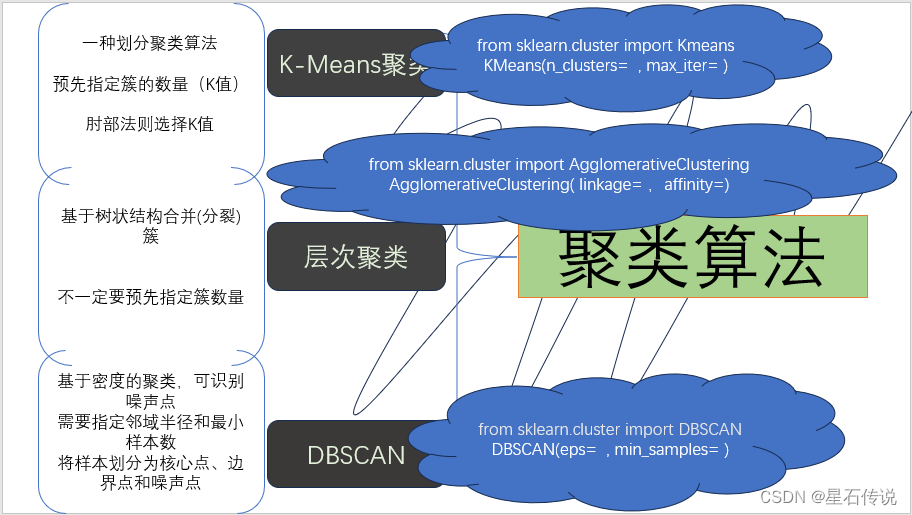
机器学习——聚类算法一
文章目录
- 前言
- 一、基于numpy实现聚类
- 二、K-Means聚类
- 2.1. 原理
- 2.2. 代码实现
- 2.3. 局限性
- 三、层次聚类
- 3.1. 原理
- 3.2. 代码实现
- 四、DBSCAN算法
- 4.1. 原理
- 4.2. 代码实现
- 五、区别与相同点
- 1. 区别:
- 2. 相同点:
- 总结
前言
在机器学习中,有多种聚类算法可以用于将数据集中的样本按照相似性进行分组。本文将介绍一些常见的聚类算法:
- K-Means聚类
- 层次聚类
- DBSCAN算法
一、基于numpy实现聚类
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from numpy.linalg import norm
import random
np.random.seed(42)
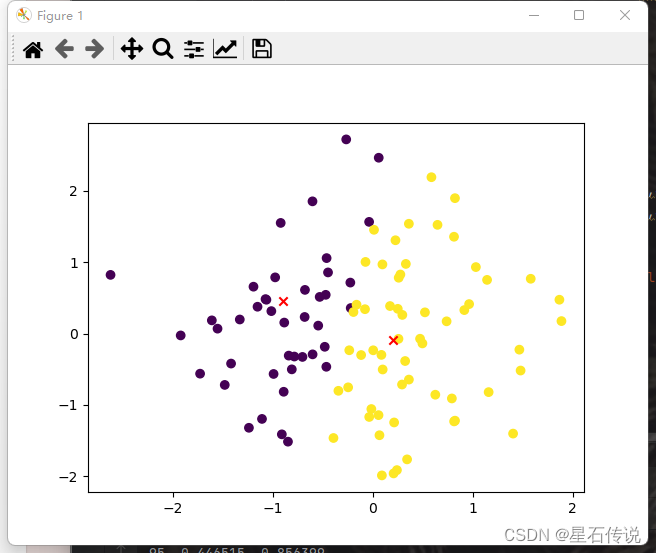
data = np.random.randn(100,2) #生成一个包含100个样本点的随机数据集,每个样本有2个特征
df = pd.DataFrame(data= data,columns=["x1","x2"])
x1_min, x1_max, x2_min, x2_max = df.x1.min(), df.x1.max() ,df.x2.min(), df.x2.max()
# 初始化两个质心
centroid_1 = np.array([random.uniform(x1_min, x1_max), random.uniform(x2_min, x2_max)])
centroid_2 = np.array([random.uniform(x1_min, x1_max), random.uniform(x2_min, x2_max)])
data = df.values
#设置迭代次数为10
for i in range(10):
clusters = []
for point in data:
centroid_1_dist = norm(centroid_1- point) #计算两点之间的距离
centroid_2_dist = norm(centroid_2- point)
cluster = 1
if centroid_1_dist > centroid_2_dist:
cluster = 2
clusters.append(cluster)
df["cluster"] = clusters
#更换质心(即迭代聚类点)
centroid_1 = [round(df[df.cluster == 1].x1.mean(),3), round(df[df.cluster == 1].x2.mean(),3)]
centroid_2 = [round(df[df.cluster == 2].x1.mean(),3), round(df[df.cluster == 2].x2.mean(),3)]
plt.scatter(x1, x2, c=df["cluster"])
plt.scatter(centroid_1,centroid_2, marker='x', color='red')
plt.show()
二、K-Means聚类
2.1. 原理
K-means 是一种迭代算法,它将数据集按照距离划分为 K 个簇(其中K是用户预先指定的簇的数量),每个簇代表一个聚类(聚类后同一类数据尽可能聚集到一起,不同类数据分离)。实现步骤如下:
- 随机初始化K个质心,每个质心代表一个簇
- 将每个样本点分配到距离其最近的质心所代表的簇。(如此就形成了K个簇)
- 更新每个簇的质心,(即计算每个簇中样本点的平均值)
- 重复步骤2和步骤3,直到质心的位置不再改变或达到预定的迭代次数。
2.2. 代码实现
- 导入数据集,以鸢尾花(iris)数据集为例:
from sklearn.datasets import load_iris
import pandas as pd
# 加载数据集
iris = load_iris()
#查看数据集信息
print(iris.keys())
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
#获取特征数据
data = iris["data"]
# 获取标签数据
target = iris["target"]
print(pd.Series(target).unique())
[0 1 2]
#查看分类名
print(iris["target_names"])
['setosa' 'versicolor' 'virginica']
#整合到数据框
import pandas as pd
df = pd.DataFrame(data= iris["data"],columns= iris["feature_names"])
print(df.head())
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
- 确定初始化质点K的取值
肘部法则选择聚类数目:
该方法适用于K值相对较小的情况,随着聚类数目的增加,聚类误差(也称为SSE,Sum of Squared Errors)会逐渐减小。然而,当聚类数目达到一定阈值后,聚类误差的减小速度会变缓,形成一个类似手肘的曲线。这个手肘点对应的聚类数目就是肘部法则选择的合适聚类数目。
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
sse = []
# 设置聚类数目的范围
k_range = range(1, 10)
# 计算每个聚类数目对应的 SSE
for k in k_range:
kmeans = KMeans(n_clusters=k,random_state = 42)
kmeans.fit(df)
sse.append(kmeans.inertia_)
# 绘制聚类数目与 SSE 之间的曲线图
plt.style.use("ggplot")
plt.plot(k_range, sse,"r-o")
plt.xlabel('Number of K')
plt.ylabel('SSE')
plt.title('Elbow Method')
plt.show()
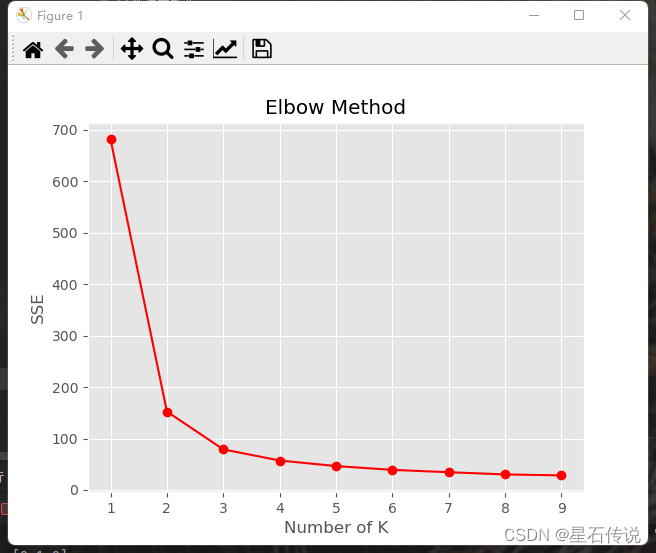
从图中可看出,当K=3时,该曲线变得比较平缓,则该点为肘部点。即最佳的聚类数目为K=3
- 从sklean中调用k-Means算法模型
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3,max_iter= 400,random_state=42)
kmeans.fit(df)
print(kmeans.cluster_centers_)
y_kmeans = kmeans.labels_
df["y_kmeans"] = y_kmeans
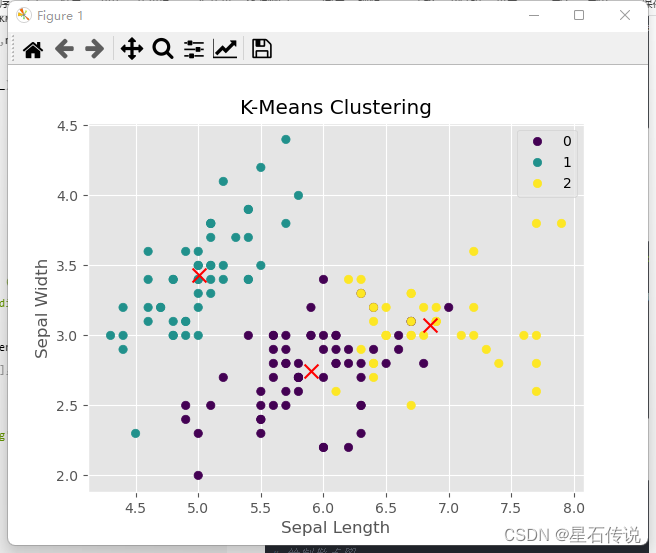
- 可视化聚类结果
绘制平面图:
plt.scatter(df["sepal length (cm)"], df["sepal width (cm)"], c=df["y_kmeans"], cmap='viridis')
# 绘制聚类中心
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', marker='x', s=100)
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('K-Means Clustering')
handles, labels = sc.legend_elements()
plt.legend(handles, labels)
plt.show()
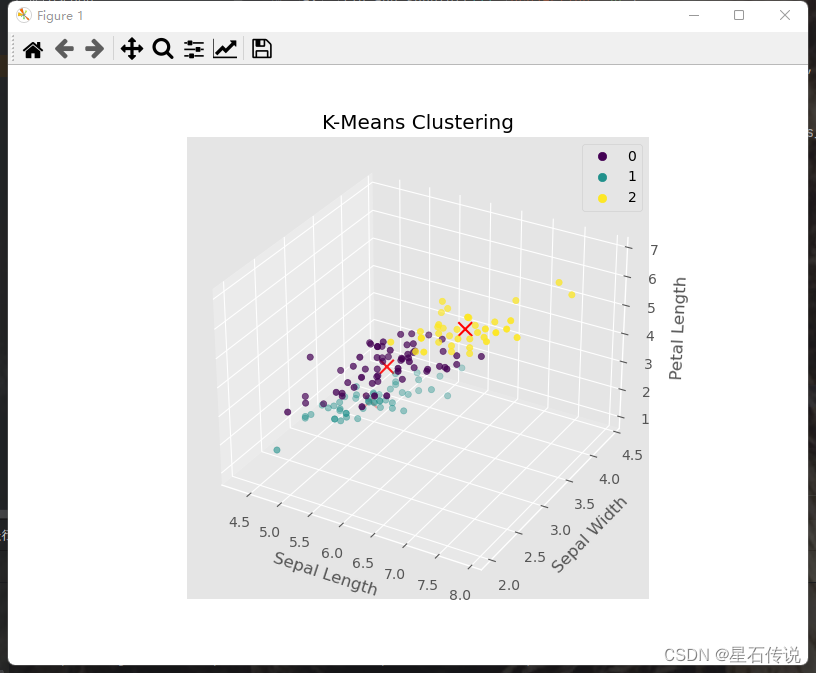
绘制三维图:
# 创建3D图形对象
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# 绘制散点图
sc = ax.scatter(df["sepal length (cm)"], df["sepal width (cm)"], df["petal length (cm)"], c=df["y_kmeans"], cmap='viridis')
# 绘制聚类中心
ax.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], kmeans.cluster_centers_[:, 2], c='red', marker='x', s=100)
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Sepal Width')
ax.set_zlabel('Petal Length')
ax.set_title('K-Means Clustering')
# 添加图例
handles, labels = sc.legend_elements()
ax.legend(handles, labels)
plt.show()
2.3. 局限性
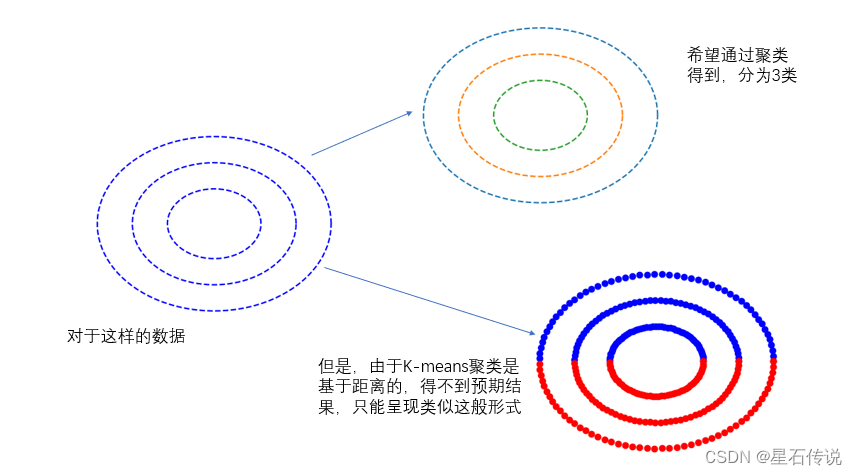
k-Means算法通过距离来度量样本之间的相似性,因此对于非凸形状的聚类,算法可能无法正确地将样本划分到正确的聚类中。
k-Means算法对噪声和离群点敏感。这些异常值可能会影响到聚类结果,使得聚类变得不准确
需要事先指定聚类的数量k,而且对结果敏感。如果选择的聚类数量不合适,会导致聚类结果不准确或不理想。
比如这种情况:
三、层次聚类
3.1. 原理
层次聚类(Agglomerative clustering)算法是一种基于树状结构的聚类方法,分为凝聚型和分裂型层次聚类。
分裂型层次聚类从整个数据集作为一个簇开始,然后逐步将簇分裂为更小的簇,直到达到预定的簇的数量或达到某个停止准则。
凝聚型层次聚类将数据集中的样本逐步合并为越来越大的簇。
即从N个簇开始(每个样本为一个簇),在每个步骤中合并两个最相似的簇,直到达到某个停止准则。
如图所示,从上(下)往下(上):
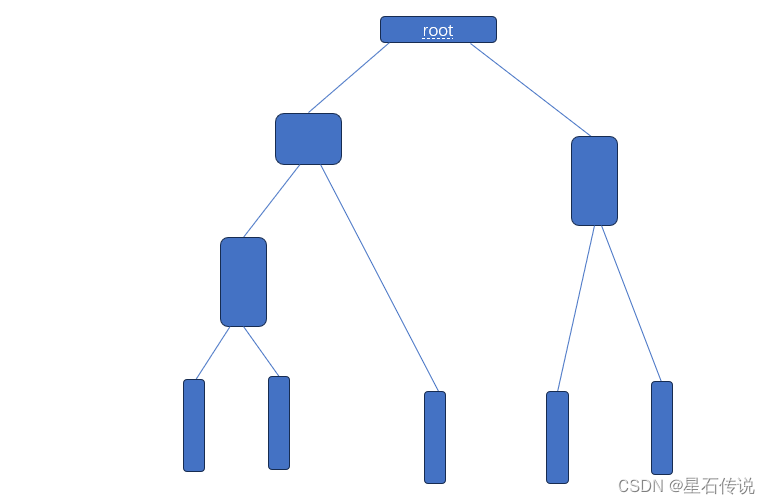
优点是可以直观地展示数据点之间的相似性关系,并且不一定要预先指定聚类簇的数量。
层次聚类的缺点是计算复杂度较高,且对数据的噪声和异常值比较敏感。
3.2. 代码实现
参数 linkage: 用于指定链接算法。
“ward” : 单链接,即两个簇的样本对之间距离的min
“complete”: 全链接,即两个簇的样本对之间距离的max
“average”: 均链接,即两个簇的样本对之间距离的mean
参数 affinity : 用于计算距离。
“euclidean”:使用欧几里德距离来计算数据点之间的距离(这是默认的距离度量方法)。
“manhattan”:使用曼哈顿距离来计算数据点之间的距离,它是两个点在所有维度上绝对值之和的总和。
“cosine”:使用余弦相似度来计算数据点之间的距离。
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering()
print(cluster.fit_predict(df))
cluster = AgglomerativeClustering(n_clusters= 3 ,linkage= "complete",affinity="manhattan")
cluster.fit(df)
df["cluster"] = cluster.labels_
print(cluster.labels_)
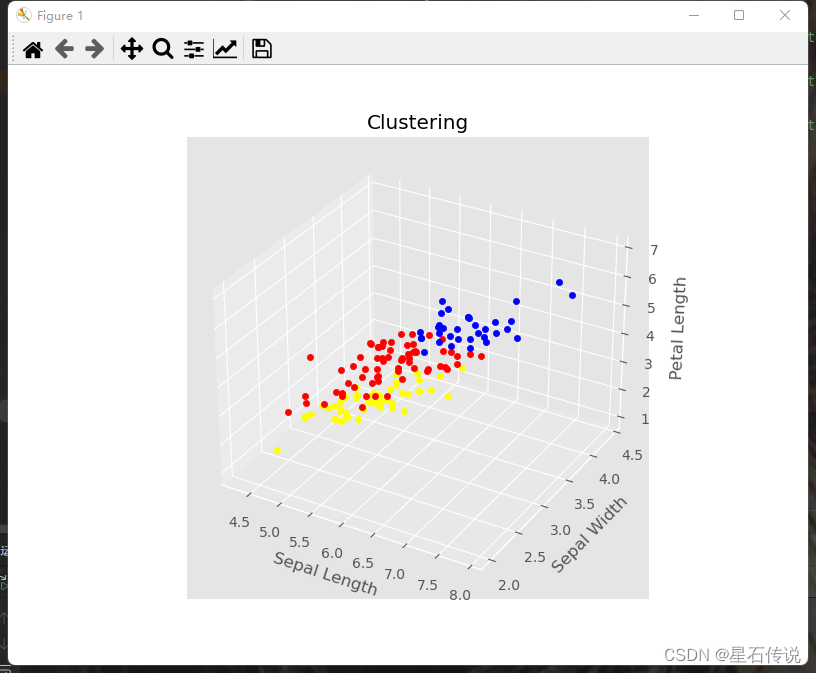
# 创建3D图形对象
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
plt.style.use("ggplot")
for i in range(len(df["cluster"])):
if df["cluster"][i] == 0:
ax.scatter(df["sepal length (cm)"][i], df["sepal width (cm)"][i], df["petal length (cm)"][i],c = "red")
elif df["cluster"][i] ==1:
ax.scatter(df["sepal length (cm)"][i], df["sepal width (cm)"][i], df["petal length (cm)"][i],c = "blue")
else:
ax.scatter(df["sepal length (cm)"][i], df["sepal width (cm)"][i], df["petal length (cm)"][i],c = "yellow")
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Sepal Width')
ax.set_zlabel('Petal Length')
ax.set_title('Clustering')
plt.show()
四、DBSCAN算法
4.1. 原理
DBSCAN是一种基于密度的聚类算法,它能够发现任意形状的聚类簇,并且能够识别出噪声点,它将样本划分为核心点、边界点和噪声点。算法的步骤如下:
-
随机选择一个未访问的样本点。根据设置的距离半径(eps),称在这一范围的区域为该样本实例的邻域
-
如果该样本点的邻域内样本数大于设定的阈值(min_samples),则将其标记为核心点,并将其邻域内的样本点加入到同一个簇中。
-
如果该样本点的邻域内样本数小于设定的阈值,则将其标记为边界点。
-
重复以上步骤,直到所有样本点都被访问。
-
最后,任何不是核心点,且邻域中没有实例样本的样本点都将被标记为噪声点
4.2. 代码实现
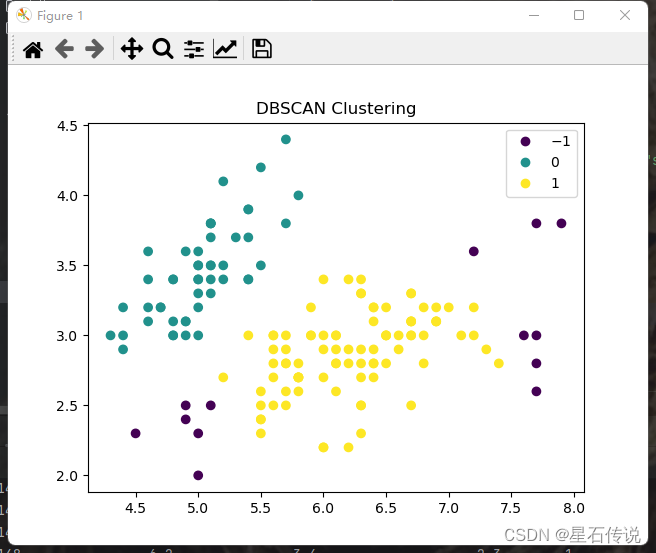
from sklearn.cluster import DBSCAN
cluster = DBSCAN(eps= 0.6 , min_samples= 10)
cluster.fit(df)
df["cluster"] = cluster.labels_
print(df)
#-1代表噪声点
print(df["cluster"].value_counts())
1 88
0 49
-1 13
Name: cluster, dtype: int64
sc = plt.scatter(df["sepal length (cm)"],df["sepal width (cm)"],c = df["cluster"])
plt.title('DBSCAN Clustering')
handles, labels = sc.legend_elements()
plt.legend(handles, labels)
plt.show()
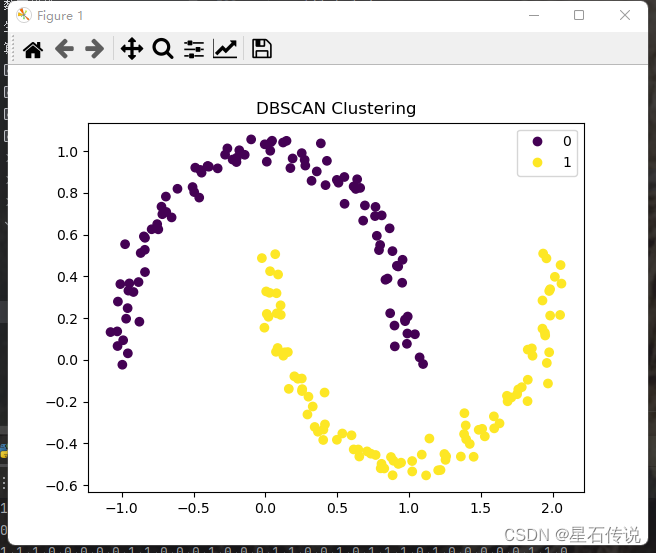
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
# 生成随机数据
X, y = make_moons(n_samples=200, noise=0.05)
print(X)
dbscan = DBSCAN(eps=0.3, min_samples=5)
dbscan.fit(X)
# 获取聚类标签
labels = dbscan.labels_
#因为设置的noise很小,故没有噪声点
print(pd.Series(labels).value_counts())
0 100
1 100
dtype: int64
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.title('DBSCAN Clustering')
handles, labels = sc.legend_elements()
plt.legend(handles, labels)
plt.show()
五、区别与相同点
1. 区别:
-
K-means是一种划分聚类算法,它将数据集划分为固定数量的簇(一定要预先指定簇的数量),而层次聚类(不一定要指定簇的数量)和DBSCAN算法(需要指定邻域半径和最小样本数),它们可以自动确定簇的数量。
-
K-means和层次聚类算法都假设簇具有相同的形状和大小,而DBSCAN算法可以发现任意形状和大小的簇。
-
K-means和层次聚类算法都对异常值敏感,而DBSCAN算法对异常值不敏感。(可去掉噪声点)
2. 相同点:
K-means、层次聚类和DBSCAN算法都是无监督学习算法中的聚类算法,它们不依赖于标签信息。
这些算法都使用距离或相似性度量来度量样本之间的相似性或距离。
总结
本文从最开始的自己实现聚类到后面的三个机器学习中聚类算法:( K-Means 、层次聚类、DBSCAN聚类)的学习,再到后面对这三个算法的比较与总结。加深了对聚类原理的了解。
我住长江头,君住长江尾;日日思君不见君
–2023-8-31 筑基篇