目录
1.执行顺序
2.SELECT查询时的两个顺序
3.关联过程
1.执行顺序
-
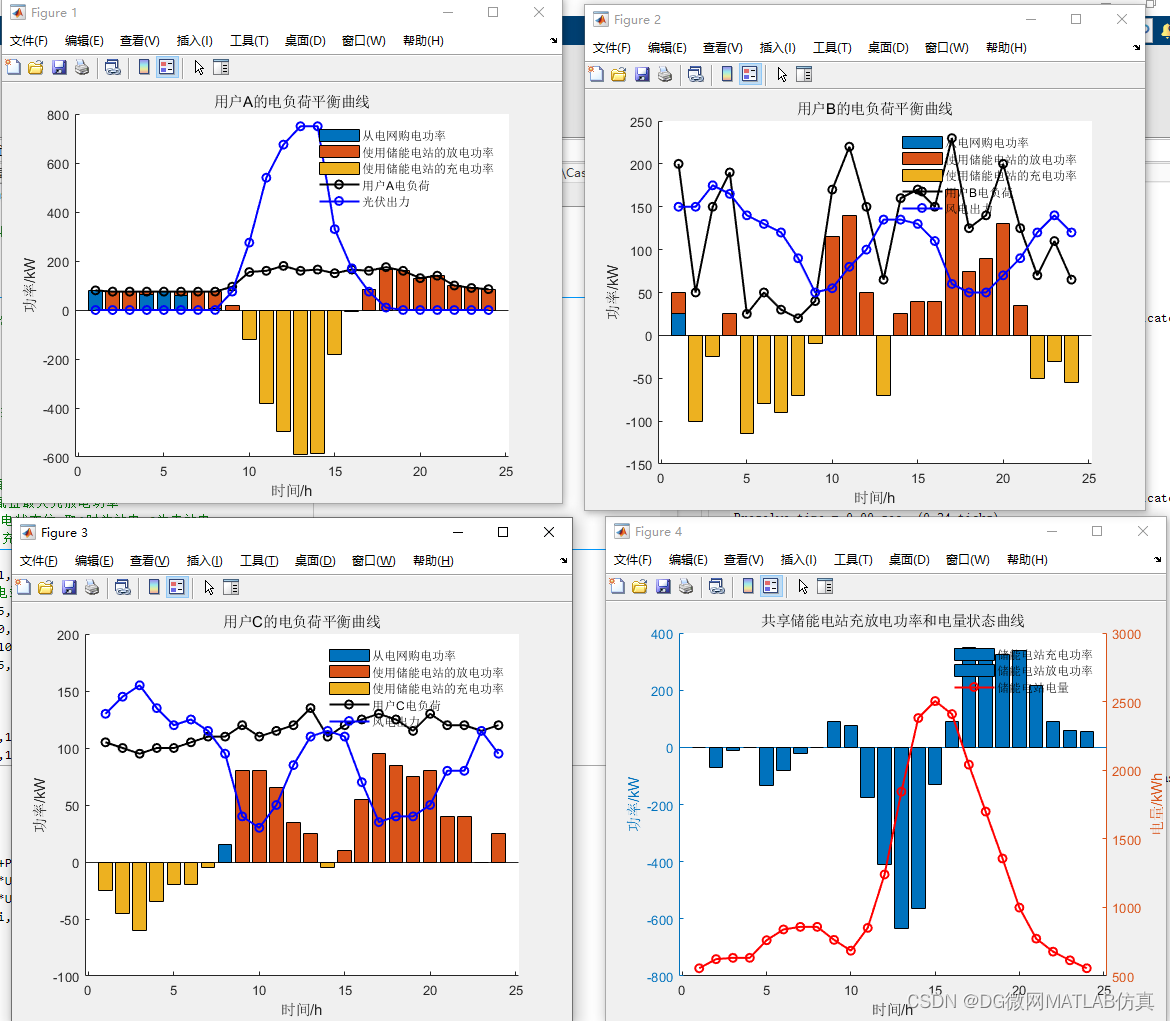
我们先执行from,join来确定表之间的连接关系,得到初步的数据
-
where对数据进行普通的初步的筛选
-
group by 分组
-
各组分别执行having中的普通筛选或者聚合函数筛选。
-
然后把再根据我们要的数据进行select,可以是普通字段查询也可以是获取聚合函数的查询结果,如果是集合函数,select的查询结果会新增一条字段
-
将查询结果去重distinct
-
最后合并各组的查询结果,按照order by的条件进行排序
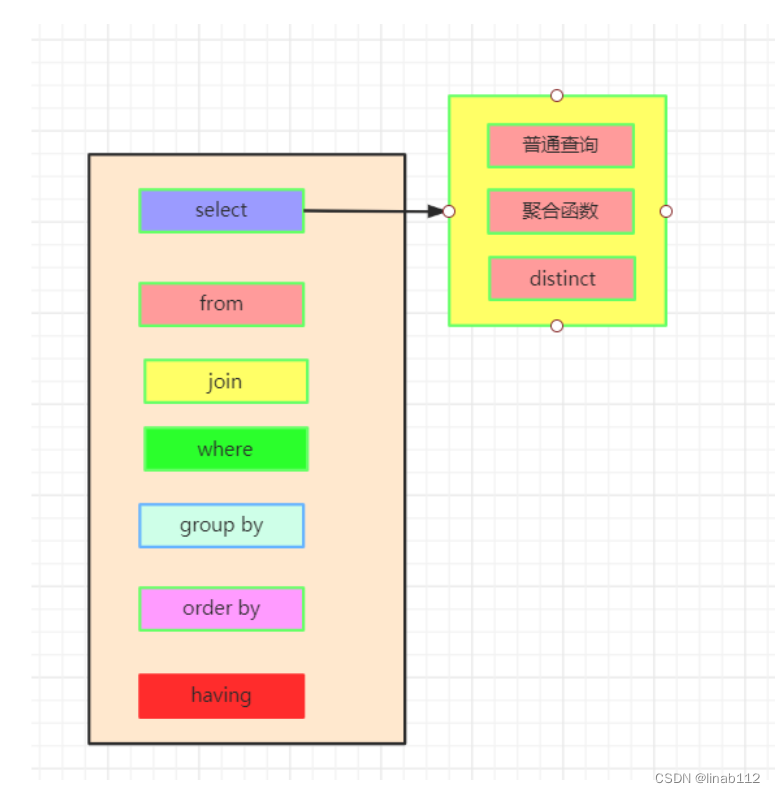
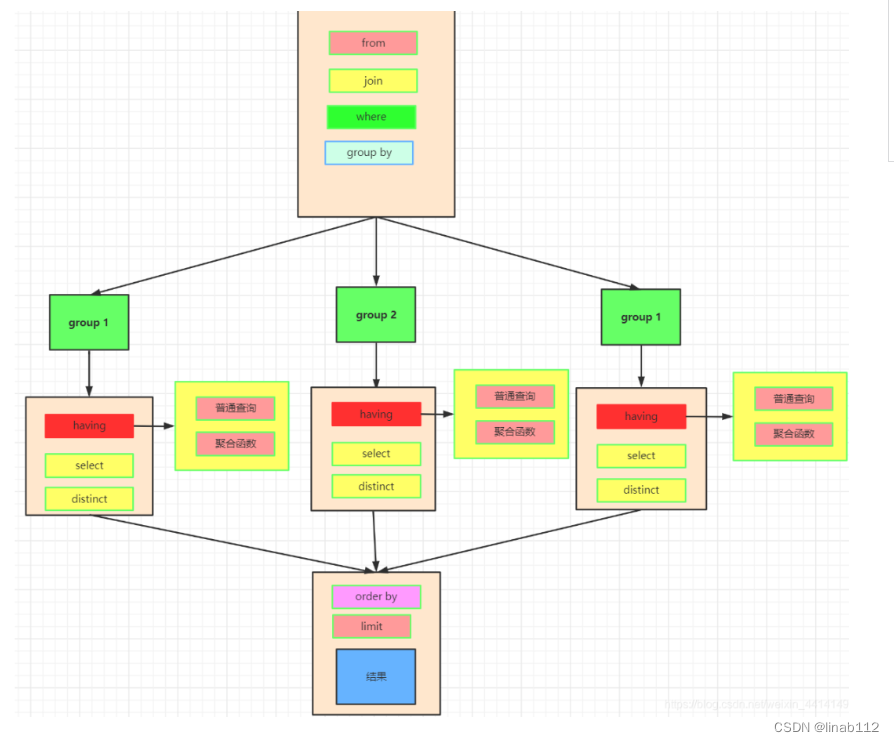
2.SELECT查询时的两个顺序
1.关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...2.SELECT语句的执行顺序(在MySQL和Oracle中,SELECT执行顺序基本相同)
FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT3.例子
SELECT DISTINCT player_id, player_name, count(*) as num #顺序5
FROM player JOIN team ON player.team_id = team.team_id #顺序1
WHERE height > 1.80 #顺序2
GROUP BY player.team_id #顺序3
HAVING num > 2 #顺序4
ORDER BY num DESC #顺序6
LIMIT 2 #顺序7在SELECT语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在SQL的执行过程中,对于我们来说是不可见的。
3.关联过程
1.from&join&where
用于确定我们要查询的表的范围,涉及哪些表。
选择一张表,然后用join连接
from table1 join table2 on table1.id=table2.id选择多张表,用where做关联条件
from table1,table2 where table1.id=table2.id我们会得到满足关联条件的两张表的数据,不加关联条件会出现笛卡尔积。
2.group by
按照我们的分组条件,将数据进行分组,但是不会筛选数据。
3.having&where
having中可以是普通条件的筛选,也能是聚合函数。而where只能是普通函数,一般情况下,有having可以不写where,把where的筛选放在having里,SQL语句看上去更丝滑。
使用where再group by
先把不满足where条件的数据删除,再去分组
使用group by再having
先分组再删除不满足having条件的数据,这两种方法有区别吗,几乎没有!
4.select
分组结束之后,我们再执行select语句,因为聚合函数是依赖于分组的,聚合函数会单独新增一个查询出来的字段,这里我们两个id重复了,我们就保留一个id,重复字段名需要指向来自哪张表,否则会出现唯一性问题。最后按照用户名去重。
select employee.id,distinct name,salary, avg(salary)将各组having之后的数据再合并数据。
5.order by
最后我们执行order by 将数据按照一定顺序排序,比如这里按照id排序。如果此时有limit那么查询到相应的我们需要的记录数时,就不继续往下查了。
6.limit
记住limit是最后查询的,为什么呢?假如我们要查询年级最小的三个数据,如果在排序之前就截取到3个数据。实际上查询出来的不是最小的三个数据而是前三个数据了,记住这一点。




![[附源码]Python计算机毕业设计Django宁财二手物品交易网站](https://img-blog.csdnimg.cn/eb9c2bc43de745f2b206e058c0c4a480.png)