《Linux内核源码分析》课程笔记
- 漏洞安全与虚拟内存
- CPU缓存技术
- malloc系统调用
- 中断
- 锁与IPC机制
- MMU
- 内存页回收
- 内核设备驱动程序
- 内核启动流程
这个课好烂,就是打广告用的。出现的老师的英语听着难受。
漏洞安全与虚拟内存
-
CPU架构:1、X86架构,采用CISC指令集(复杂指令集计算机),程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。2、ARM架构,是一个32位的精简指令集(RISC)架构。3、RISC-V架构,是基于精简指令集计算(RISC)原理建立的开放指令集架构。4、MIPS架构,是一种采取精简指令集(RISC)的处理器架构,可支持高级语言的优化执行。
-
熔断漏洞利用乱序执行的特点,使得的用户态程序也可以读出内核空间的数据,包含个人私有数据和密码;而幽灵漏洞利用分支预测执行的特点来进行攻击。
-
侧信道攻击:是密码学当中一种常见的暴力攻击技术,针对加密电子设备在运行过程中的时间消耗、功率消耗或电磁辐射之类侧信道信息泄露而对加密设备进行攻击的方法。例如,高速缓存侧信道攻击(熔断)的流程如下:
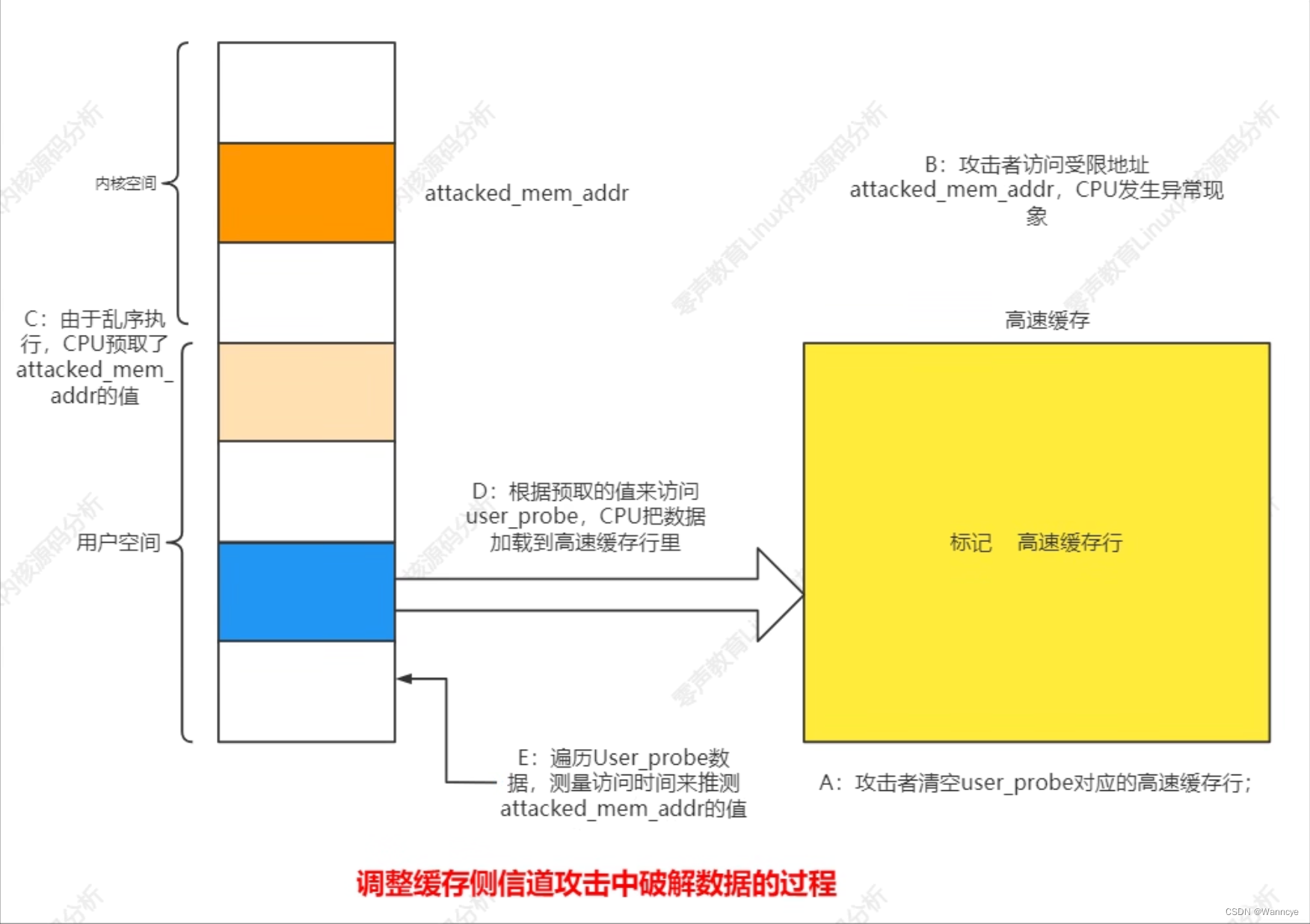
分析:CPU执行指令时乱序执行的,执行过程中允许产生异常。发生异常时,在异常之后的代码可能已经执行。这种情况下,可能把一些还没用到的数据加载到了高速缓存中。 -
malloc是用户态常用的分配内存接口的函数,mmap是用户态常用的监理文件映射或匿名映射的函数。
-
内存描述符:mm_struct,PCB的task_struct有一个指针指向这个mm_struct,示意图如下:
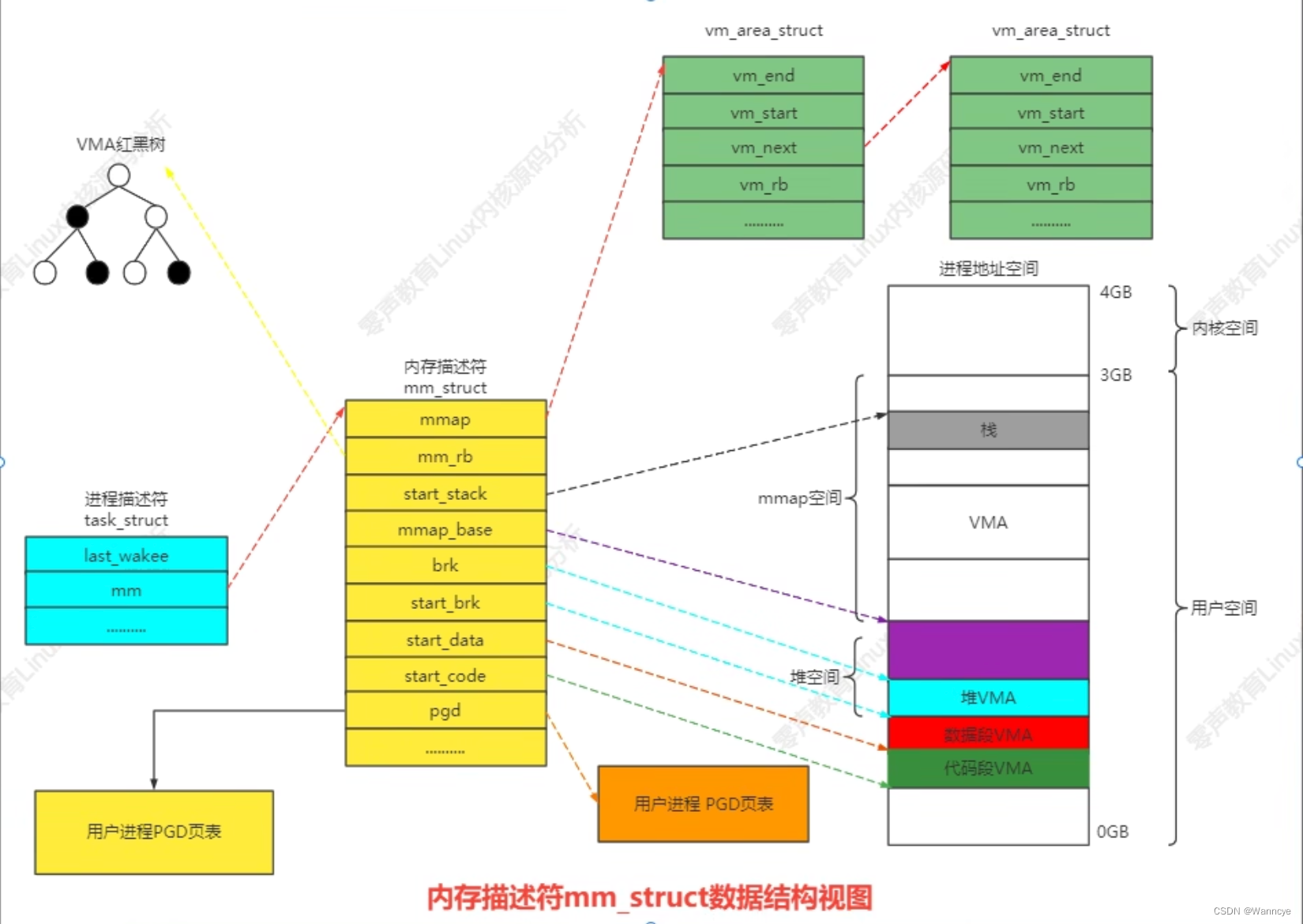
每个VMA都要连接到mm_struct中的链表以及红黑树当中。
mmap/munmap接口函数是在应用程序中分配内存、读写大文件、链接动态库文件、多进程间共享内存的方法。
CPU缓存技术
- 缓存集成度低,和内存相比相同容量下、体积会大,访问速度接近于处理器。SMP系统中,处理器每个核都有独立的一级缓存,共享二级缓存。
- 缓存行的标签通常是从物理地址生成,索引可以从物理地址或者虚拟地址生成,根据索引生成的方式可以将缓存分成两类:
a. 把从物理地址生成索引的缓存称为物理索引物理标签缓存(PIPT)
b. 把从虚拟地址生成索引的缓存称为虚拟索引物理标签缓存(VIPT) - 缓存策略
a. 写分配:假设处理器写数据的时候,没有命中缓存行的时候就分配一个缓存行,然后读取数据并填充缓存行
b. 读分配:处理器读数据的时候,没有命中缓存行就分配一个缓存行
缓存更新:
a. 写回:处理器在写数据的时候只更新缓存,并将缓存行标记为脏,只有在缓存被替换的时候再更新内存
b. 写透:处理器在写数据的时候,同时更新缓存和内存,但是并不会把缓存行标记为脏 - 内核在很么情况下需要维护缓存?
a. 内核修改或删除页表的时候
b. 内核使用内核虚拟地址修改进程的物理页
malloc系统调用
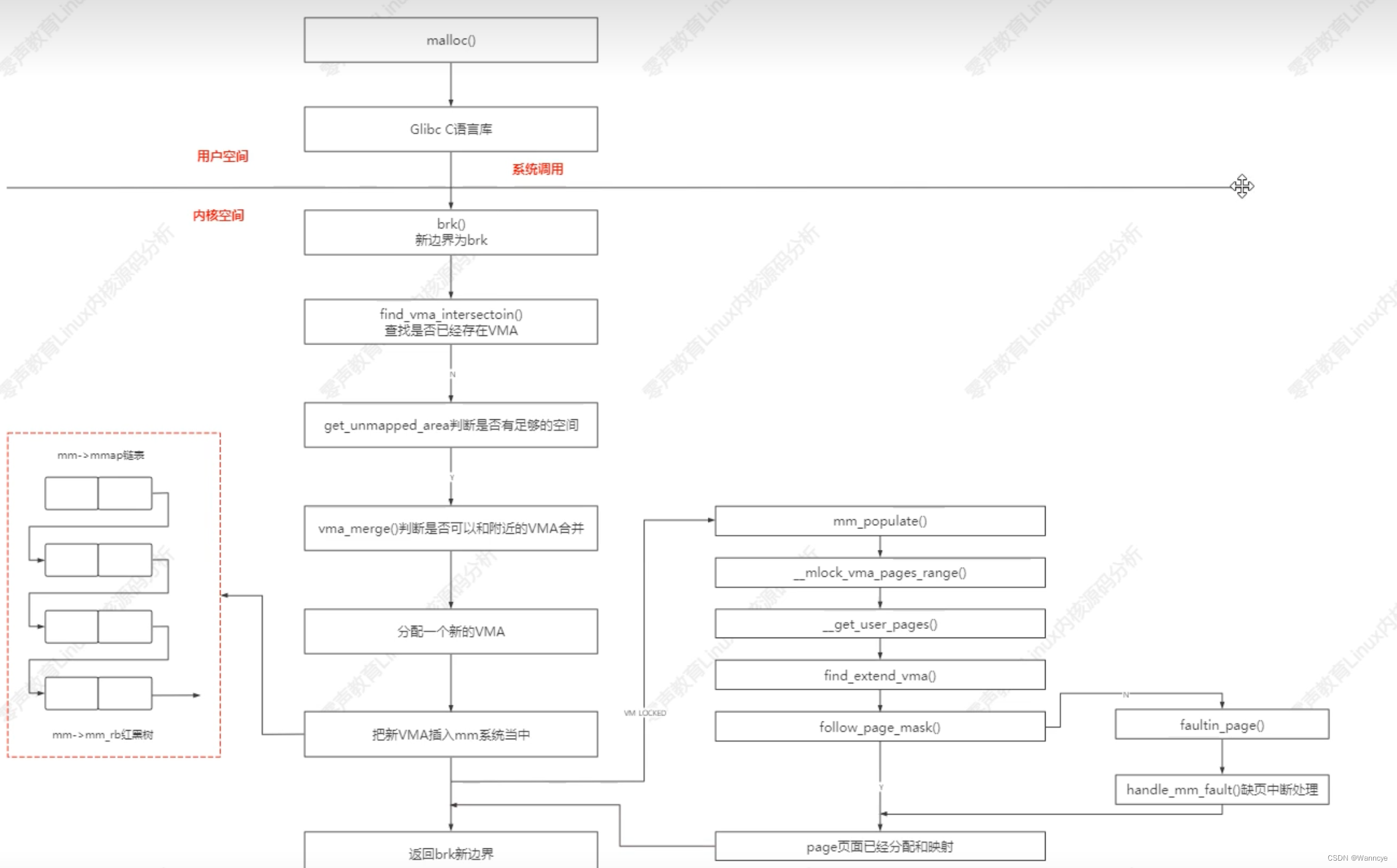
- malloc是专门用于内存分配的函数。malloc函数—>Linux内核系统调用brk(向系统申请内存)。malloc() 源码里默认定义了一个阈值:
如果用户分配的内存小于 128 KB,则通过 brk() 申请内存;
如果用户分配的内存大于 128 KB,则通过 mmap() 申请内存;
处理器MMU硬件处理最小单位是页,所以内核分配内存也是以页为单位的。
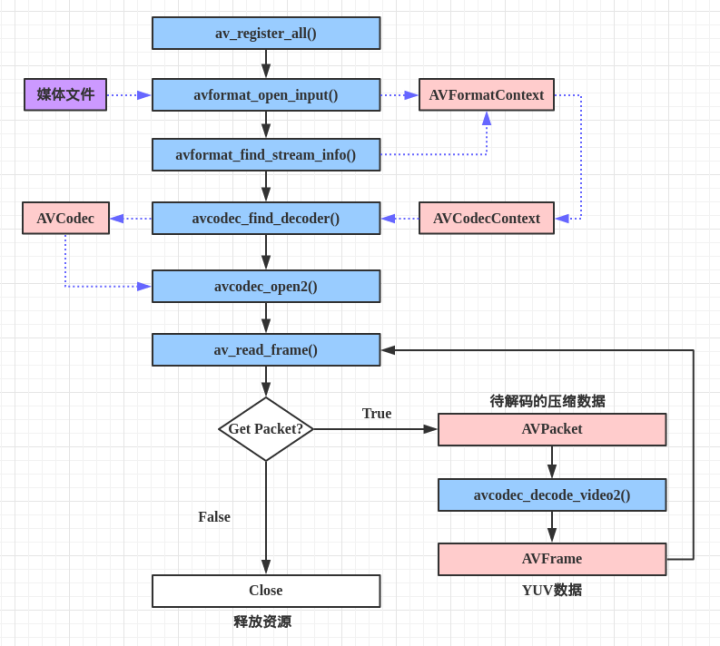
流程如下:
中断
- 中断控制器:将所有终端源发起的中断,通过对中断控制器的编程,可以控制每个中断源的优先级,也可以打开和关闭中断源。
- Programmable Interrupt Controller:PIC,可编程中断控制器
- 中断产生:在硬件电路中,两种方式:电平触发、边缘触发
- IRQ:中断请求。每个中断源都会对应一个IRQ编号
- 中断注册:Linux中断子系统向驱动程序提供注册中断的API
锁与IPC机制
- 内核锁机制:
a. 原子操作
b. 自旋锁:可基于CAS实现
struct semaphore {
spinlock_t lock; // 用于修改count的锁,其实可以直接用atomic_t
unsigned int count;
struct list_head wait_list; // 等待信号量的进程
};
c. 信号量
d. 读写锁
e. CAS锁:解决多线程条件下使用锁造成性能损耗问题的算法,保证了原子性,这个原子操作是由CPU来完成的
CAS的原理:CAS算法有三个操作数,通过内存中的值(V)、预期原始值(A)、修改后的新值。
(1)如果内存中的值和预期原始值相等, 就将修改后的新值保存到内存中。
(2)如果内存中的值和预期原始值不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作,直到重试成功。
- RCU:Read Copy Update。允许读写并发执行。
- 大内核锁(BKL):锁定整个内核,确保没有CPU在核心态并行运行。
MMU
-
两级分页机制将32位的虚拟空间分成三段,低十二位表示页内偏移,高20分成两段分别表示两级页表的偏移。
PGD(Page Global Directory): 最高10位,全局页目录表索引
PTE(Page Table Entry):中间10位,页表入口索引
当在进行地址转换时,结合在CR3寄存器中存放的页目录(page directory, PGD)的这一页的物理地址,再加上从虚拟地址中抽出高10位叫做页目录表项(内核也称这为pgd)的部分作为偏移, 即定位到可以描述该地址的pgd;从该pgd中可以获取可以描述该地址的页表的物理地址,再加上从虚拟地址中抽取中间10位作为偏移, 即定位到可以描述该地址的pte;在这个pte中即可获取该地址对应的页的物理地址, 加上从虚拟地址中抽取的最后12位,即形成该页的页内偏移, 即可最终完成从虚拟地址到物理地址的转换。从上述过程中,可以看出,对虚拟地址的分级解析过程,实际上就是不断深入页表层次,逐渐定位到最终地址的过程,所以这一过程被叫做page talbe walk。 -
ARM64位可以指定地址线的位数,但是最高支持48位。
内存页回收
- 物理页根据是否有存储设备支持可以分为:支持交换的页;存储设备支持的文件页。
- 针对不同的页,采用不同的回收策略:
针对支持交换的页,先把页的数据写到交换区,然后释放物理页
针对存储设备支持的页,如果是干净的页,直接释放,如果是脏页,先写回设备,再释放物理页 - LRU算法中有5个lru链表:
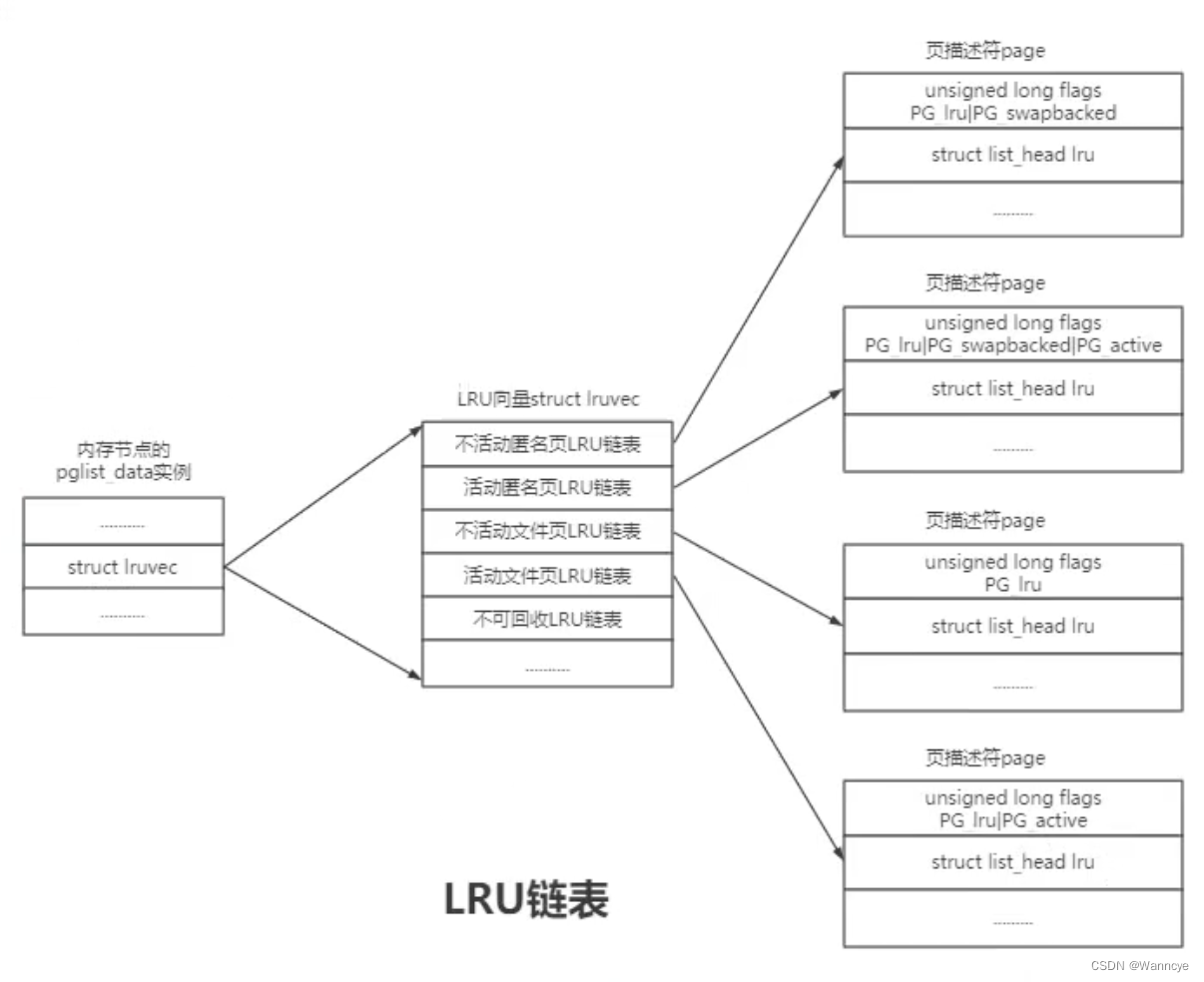
- 回收页表映射的匿名或文件页时,需要从页表中删除映射,内核需要知道物理页被映射到那些进程的虚拟地址空间,需要实现物理页到虚拟页的反向映射。
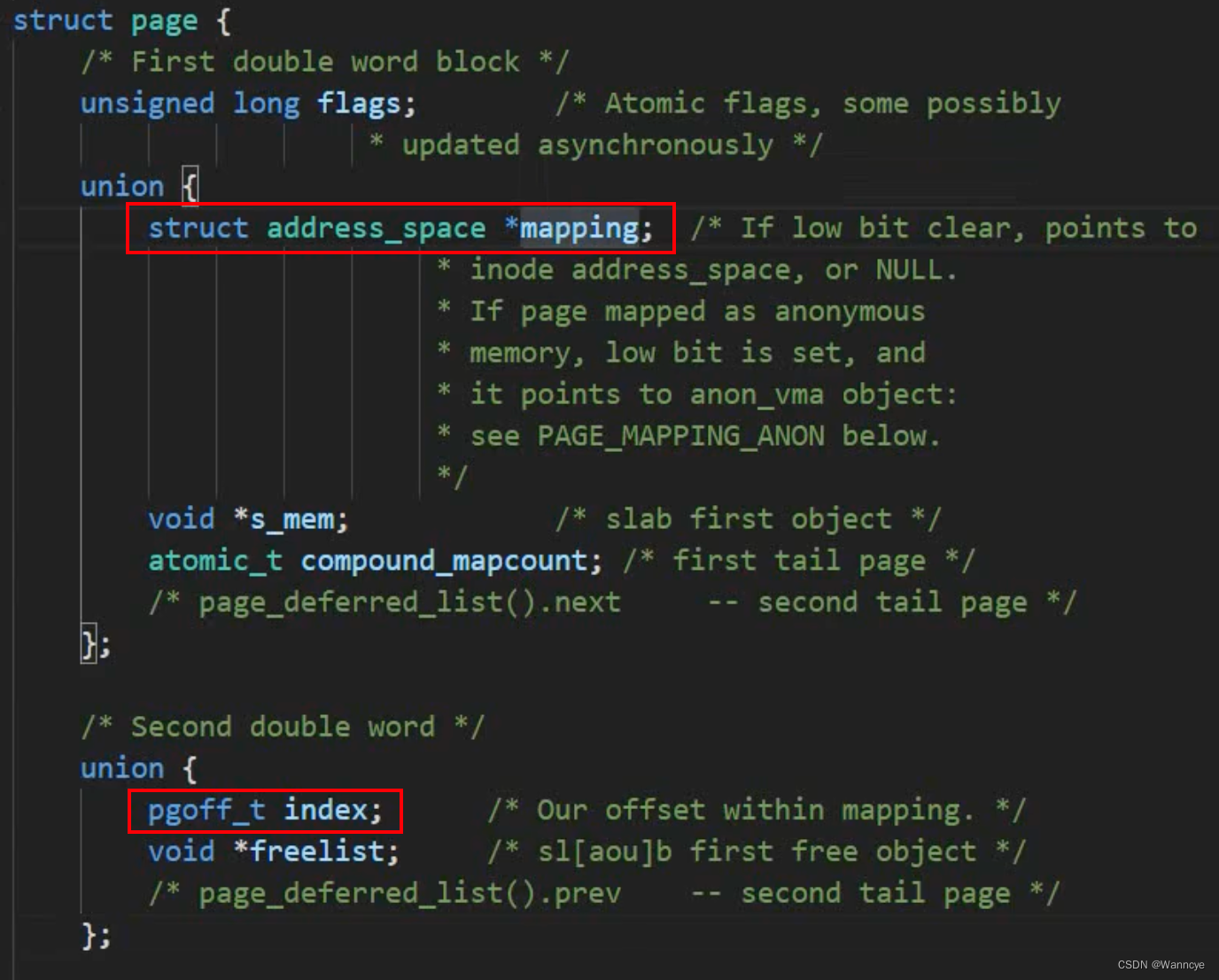
index:表示在映射里的偏移。对于匿名映射,index是物理页对应的虚拟页再虚拟内存区域的页偏移;对于文件映射映射,index是物理页存储的数据在文件页中的页偏移。
mapping中有标识匿名页和文件页的位。
内核设备驱动程序
- Linux中的输入输出设备被分为:块设备、字符设备、网络设备
- 驱动程序所做的工作:(1)将抽象要求转换为具体要求; (2)检查 I/O 请求的合法性; (3)读出和检查设备的状 态; (4)传送必要的参数; (5)设置工作方式; (6)启动 I/O 设备。
- 设备驱动程序:CPU不是系统中唯一智能的设备,每个物理设备都拥有自己的控制器。在Linux中管理硬件控制器的代码并不在每个应用程序中,而是由内核统一管理,这些处理和管理硬件控制器的软件就是设备驱动程序。
- 内核具有共性:(1)驱动程序属于内核代码;(2)为内核提供统一接口;(3)驱动程序的执行属于内核机制并使用内核服务;(4)动态可加载;(5)可配置
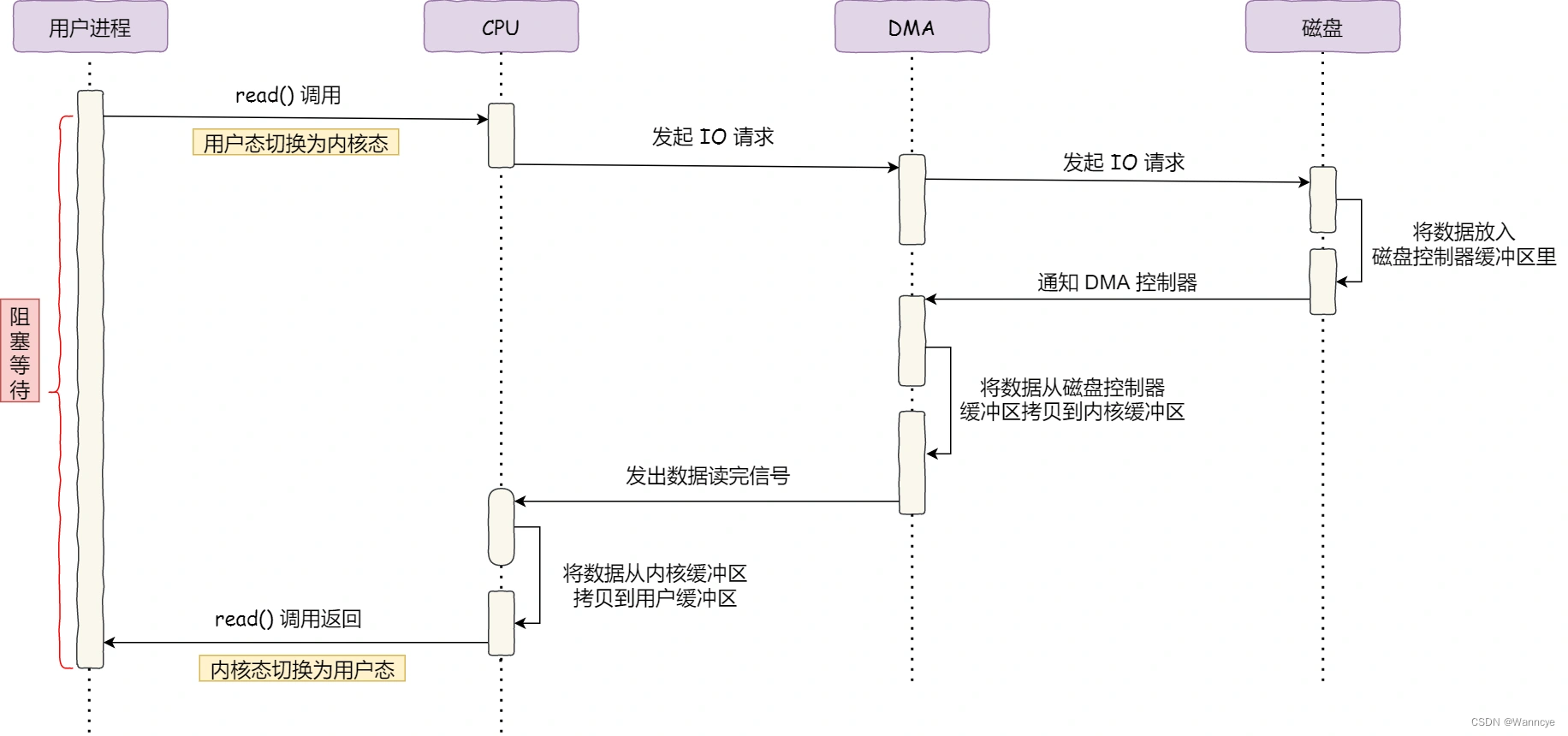
- DMA;在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。
内核启动流程
- 实模式:程序中用到的地址都是真实的物理地址。在32位CPU下,系统复位或加电时都是以实模式启动,然后再切换为保护模式。在实模式下,所有的段都是可以读、写和可执行的。保护模式:相当于引入虚拟地址之类的概念对内存进行保护,相比实模式更安全。
- 启动过程:按下电源;主板会向电源组发出信号;接到信号后,主板启动CPU(CPU重置所有寄存器,初始化数据);BIOS执行程序存储在ROM中,起始位置为0xFFFF0,当CS:IP指向此位置时,BIOS开始工作。BIOS主要包括内存映射。BIOS程序会选择一个启动设备,并将控制权交给启动扇区的代码,主要工作即使用中断向量和中断服务程序完成BootLoader的加载,最终将boot.img加载到0x7c00的位置启动。