Rethinking Mobile Block for Efficient Attention-based Models
结合 CNN 和 Transformer 的倒残差移动模块设计
ICCV-2023
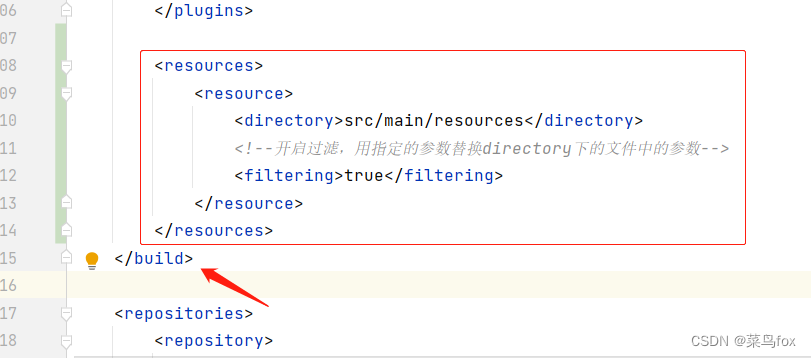
实例化了一个面向移动端应用的iRMB基础模块(Inverted Residual Mobile Block,倒残差移动模块),其同时具备CNN的静态短程建模能力和Transformer的动态长程特征交互能力,并进一步设计了仅由iRMB构成的EMO, Efficient MOdel轻量化主干模型。
结合CNN/Transformer结构的优点来构建类似IRB的轻量级基础模块。基于此,抽象了MMB(Meta Mobile Block)用来对IRB和Transformer中的MHSA/FFN进行归纳,其次实例化了高效的iRMB(Inverted Residual Mobile Block),最后仅使用该模块构建了高效的EMO(Efficient MOdel)轻量化主干模型。
元移动模块

如上图左侧所示,通过对 MobileNetv2 中的 IRB 以及 Transformer 中的核心 MHSA 和 FFN 模块进行抽象,作者提出了统一的 MMB 对上述几个结构进行归纳表示,即采用扩张率和高效算子 F来实例化不同的模块。

倒残差移动模块

不同模型的效果主要来源于高效算子 F的具体形式,考虑到轻量化和易用性,作者将 MMB 中的 F建模为Expanded Window MHSA(EW-MHSA)和Depth-Wise Convolution(DW-Conv)的级联,兼顾动态全局建模和静态局部信息融合的优势,同时能够有效地增加模型的感受野,提升对于下游任务的能力。

在整体框架上,EMO 仅由 iRMB 组成,没有其他复杂的操作符。iRMB 仅由标准卷积和 MHSA 组成,没有其他复杂的操作符。此外,得益于 DW-Conv, iRMB 可以通过 stride 来完成下采样操作。EMO 模型的详细架构配置如下图5所示。由于 MHSA 更适合为更深层次的语义特征建模,所以作者只在 Stage3 和 Stage4 使用 MHSA。为了进一步提高 EMO 的稳定性和效率,在 Stage1 和 Stage2 使用 BN + SiLU,在 Stage3 和 Stage4 使用 LN + ReLU。
Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing Images
CATnet(ContextAggregation模块)
远程感知图像中的实例分割任务旨在执行实例级别的像素级别标记,对于各种民用应用非常重要。尽管之前已经取得了成功,但是大多数现有的针对自然图像设计的实例分割方法在直接应用于俯视远程感知图像时遇到了严重的性能下降。经过仔细分析,我们发现这些挑战主要来自于缺乏具有区分度的目标特征,原因是受到严重的尺度变化、低对比度和聚集分布的影响。为了解决这些问题,提出了一种新的上下文聚合网络(CATNet)来改善特征提取过程。所提出的模型利用三个轻量级的即插即用模块,分别是密集特征金字塔网络(DenseFPN)、空间上下文金字塔(SCP)和分层感兴趣区提取器(HRoIE),在特征、空间和实例域中聚合全局视觉上下文。DenseFPN是一个多尺度特征传播模块,通过采用层内残差连接、层间稠密连接和特征重新加权策略,建立了更加灵活的信息流。利用注意机制,SCP通过将全局空间上下文聚合到本地区域中进一步增强特征。对于每个实例,HRoIE自适应地生成用于不同下游任务的RoI特征。


End
以上仅作个人学习记录使用