「导语」
硬石科技,成立于2018年,总部位于武汉,是一家专注于应急管理行业和物联感知预警算法模型的技术核心的物联网产品和解决方案提供商。硬石科技作为一家高新技术企业,持有6项发明专利,拥有100余项各类平台认证和资质,荣获国家级及省市级荣誉共计13项,受到应急主管部门的高度认可。多年来,硬石科技致力于为应急管理业务提供优质服务,并取得了显著成就。
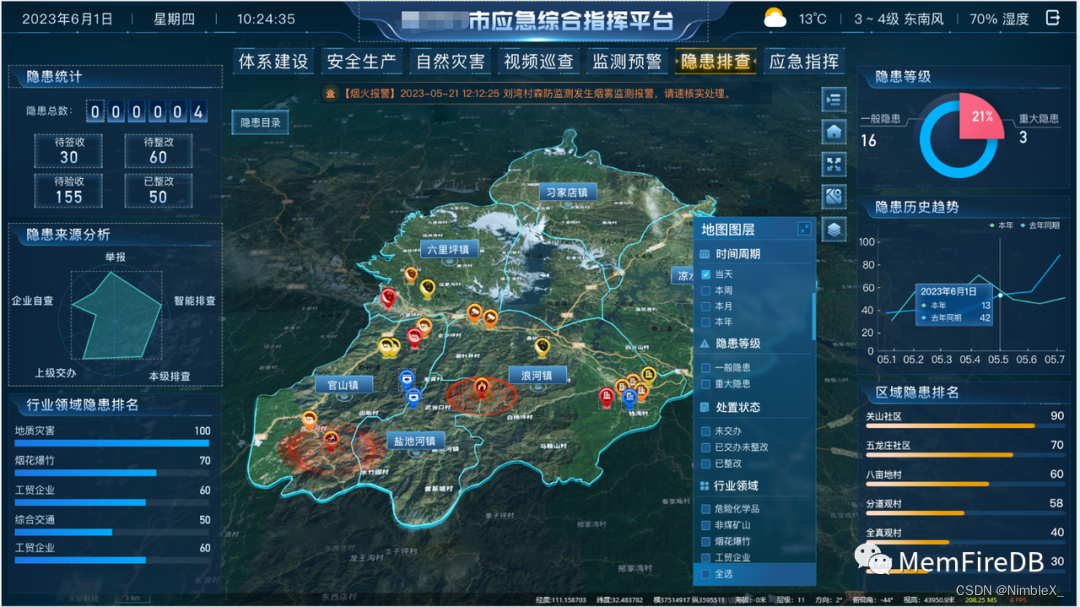
硬石科技专业致力于应急管理行业,提供以物联网技术和感知预警算法模型为核心的先进产品和解决方案。应急管理行业的业务非常繁多和复杂,很多时候都需要在短时间内交付出稳定高效的业务系统。譬如下图某市的应急综合指挥大屏,这款大屏集成了先进的物联网技术和感知预警算法模型,为应急管理部门提供了强大的工具和支持。通过实时监测和分析数据,应急隐患排查大屏能够帮助应急主管部门在事前、事中和事后快速响应和处理突发事件。
通过之前对MemFire Cloud基本了解,它的一些特性比如自动生成API接口、云存储等功能正是本次需求所需要的。综合考量下,我们决定使用MemFire Cloud来开发此次的应急大屏。
那么,这样一套大屏具体是如何使用MemFire Cloud开发的呢?在开发过程中又会遇到哪些挑战呢?
应急综合指挥大屏带来的三大挑战
1.大量不同维度的隐患数据需要进行统计分析,需要开发各种api接口
隐患数据来源于不同维度的数据采集,包括各个行业领域的数据(几十个领域)、乡镇层面的社区数据,以及不同级别和来源的隐患数据等。为了满足前端的多样化数据展示需求,需要开发大量的API接口来提供各个维度的数据。
2.多样性展示需求、数据关联性复杂,实现各种统计分析
由于隐患数据的多样性和与之相关联的多个数据表,表与表之间存在较强的数据关联性。因此,特定场景下需要进行复杂的统计分析才能获得所需的数据。
3.存储并检索海量的非结构化的隐患数据
隐患大屏需要存储海量的隐患数据的素材,包括图片、视频和附件。这种情况下,需要具备强大的存储和管理大数据的能力,以确保能够有效地存储和检索这些数据的素材。
面对挑战,MemFire Cloud如何破局
那么面对应急综合指挥大屏带来的三大挑战,MemFire Cloud如何一一攻克?
首先,针对大量不同维度的数据需要开发各种API接口的挑战。在项目过程中,根据业务需求我们需要根据时间周期、隐患等级、处置状态、行业领域和行政区划等多个不同的维度来统计和分析,整个过程中需要开发接近30个api接口。采用MemFire Cloud自动生成REST接口,大约一天的工作量就可以获得所有的接口。中途遇到两次需求变更的情况,我们也无需重新编写接口和前后端联调,只需要根据自动生成的API接口返回数据进行一些数据结构的调整即可。这样的优化方案极大地简化了开发流程,提高了开发效率,并确保了应对需求变更的灵活性。
接着,面对多样性展示需求、数据关联性复杂,实现各种统计分析的挑战。在我们开发过程中遇到一些困难,例如在数据表之间没有建立外键关联的情况下如何进行多表关联查询。比如像这样的需求场景:
现在需要查询当前区县下的所有乡镇的数据,乡镇的顺序必须根据表yj_countryside_info里countryside_type = '1'后的乡镇的顺序。但是乡镇的数据又在表sys_dept里,为何不直接使用yj_countryside_info表呢?这是因为yj_countryside_info表里是一个数据字典,里面有很多测试乡镇,它并不能代表当前区县的所有乡镇。在这种情况下,我们遇到的问题就是:
「当需要查询一个数据表的数据时,这个数据表的过滤是依赖于另外一张表的某些数据或某个字段时,但是这两张表又未建立关联关系,传统的sql脚本是可以通过左关联查询到的,但是在使用MemFire Cloud目前api是无法做到的。」
我们请教了MemFire Cloud相关的技术人员,他们耐心的解答并给出了三种解决方案。
a. 创建视图
「优点」:视图可以根据特定的业务需求和查询条件,对数据进行过滤、排序、聚合等操作,从而简化了对数据的操作。使用视图可以将复杂的查询逻辑封装到一个视图中,使得用户可以通过简单的查询语句获取所需的数据。
「缺点」:它们可能会影响性能,因为它们需要消耗额外的资源;它们可能不能够提供最新的数据。
b.使用数据库函数
原理就是写一个可以统计数据并且返回统计数据的sql脚本的方法跑在数据库,然后通过MemFire Cloud的rpc数据库方法在前端调用该函数。
例如:
get_sub_dept就是我们定义的数据库函数
CREATE OR REPLACE FUNCTION get_sub_dept(my_dept_id varchar)
RETURNS TABLE (sub_dept_id VARCHAR)
AS $$
BEGIN
RETURN QUERY select dept_id from sys_dept d where my_dept_id = any (string_to_array(d.ancestors, ','));
END;
$$ LANGUAGE plpgsql;
在前端调用此方法
const { data, error } = await supabase.rpc('get_sub_dept', { my_dept_id: '1111' })
「缺点」:对前端人员对数据库知识和设计有一定的要求,存在数据库里面的代码,不好维护。
c.子查询
熟悉业务和熟悉数据表的设计的同时和条件允许下,看是否可以通过子查询方式过滤数据。
例如sql脚本:
SELECT
sd.dept_id,
sd.dept_name
FROM
sys_dept sd
WHERE
sd.del_flag = '0'
AND sd.dept_id IN ( SELECT yci.dept_id FROM yj_countryside_info yci WHERE yci.countryside_type = '1' )
ORDER BY
sd.order_num
转换为api查询:
const xz_list = await supabase
.from('yj_countryside_info')
.select('dept_id').eq('countryside_type', '1')
if (xz_list && xz_list.data.length > 0) {
const xz_array = xz_list.data.map(item => item.dept_id);
const { data, error } = await supabase
.from('sys_dept')
.select('dept_id,dept_name').eq('del_flag', '0').order("order_num", { ascending: true }).in('dept_id', xz_array)
}
经过综合考虑,我们选择了方案C来解决这个问题。我们发现方案C相对于方案A和方案B,在后期的维护成本方面有很大的降低。
最后,面对存储海量隐患相关的图片、视频和附件的挑战。我们借助MemFire Cloud云存储具备强大的存储和管理大数据的能力,创建了存储桶来统一存储海量素材,并使用REST接口及SDK快速实现了文件上传、下载和访问等功能的开发,满足了项目的需求。
总结
通过借助MemFire Cloud的强大能力,项目开发周期由原来的一个月缩短到现在的两周,投入人力由原来的两个减少为一个。这使得开发变得更加高效和简化,抗住了三大数据的挑战,完全不用担心底层数据的问题,保证了数据大屏快速稳定的上线,缩减了时间与人力成本。
使用MemFire Cloud,我们可以专注于前端开发工作,而无需担心后端的搭建和维护,也不需要开发接口,前端只需要关注页面的样式和功能交互。这种快速开发和节约成本的方法,能够更好地实现应急大屏的开发需求。
当然,在使用MemFire Cloud的时候也遇到了一些在使用文档上的不便,比如花费了很长时间才找到自己想要的文档内容。也希望平台能够对此关注起来哈!总体来说,我们对使用MemFire Cloud的开发海量数据大屏的体验还是感到非常惊喜的!也希望MemFire Cloud能够越来越强大!