原文链接:tecdat.cn/?p=41693
在当今数字化浪潮席卷全球的时代,城市交通领域的海量数据如同蕴藏着无限价值的宝藏等待挖掘。作为数据科学家,我们肩负着从复杂数据中提取关键信息、构建有效模型以助力决策的使命(点击文末“阅读原文”获取完整代码、数据、文档)。
我们团队承接并完成了一项极具挑战性的咨询项目 —— 针对出租车出行数据的深度分析与预测研究。该项目旨在通过对出租车运营数据的全方位剖析,为城市交通资源优化配置与科学规划提供坚实的数据支撑。
项目伊始,我们面对的是出租车出行的原始数据,这些数据包含行程标识、叫车方式、时间信息、GPS 坐标等多维度特征,然而数据缺失与异常问题也随之而来。为此,我们运用 Python 为核心工具,开展数据预处理工作,筛选有效数据子集。紧接着,借助数据可视化手段,从时间、叫车类型等维度深入探索数据规律,发现出行活动在工作日与周末、不同叫车方式间的显著差异。针对数据中的异常值,我们创新性地引入基于贝叶斯概率的异常检测模型,成功识别出约 10% 存在无效 GPS 坐标的路线。最后,我们构建了包括随机森林回归器(RFR)、梯度提升回归器(GBR)、线性回归(LR)、k 近邻回归(KNR)、决策树回归(DTR)等多种机器学习模型,对出租车行程进行预测,对比各模型性能,为后续优化与实际应用奠定基础。
专题项目文件已分享在交流社群,阅读原文进群和 500 + 行业人士共同交流和成长。我们期待探索数据背后的无限可能,为城市交通的智能化发展贡献力量。
文章流程图
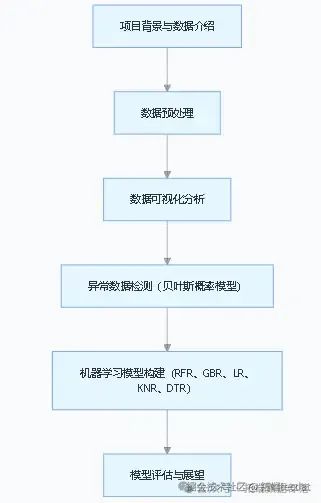
出租车出行数据分析与预测研究
在城市交通日益复杂的当下,出租车作为重要的出行方式,其运营数据蕴含着巨大价值。通过对出租车出行数据的深入分析与精准预测,不仅能够优化出租车资源配置,还能为城市交通规划提供有力支撑。本次研究围绕出租车出行数据展开,旨在探索数据背后的规律,并构建有效的预测模型。
数据探索与预处理
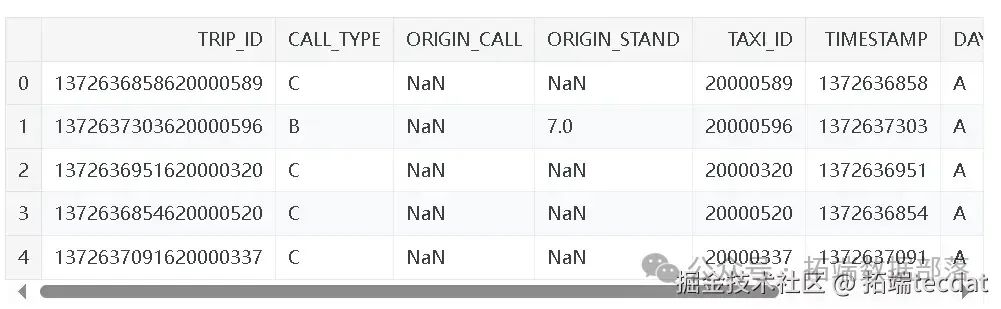
研究首先面临的是出租车出行数据。每一条数据样本对应一次完整的行程,包含9个特征。TRIP_ID 是每次行程的唯一标识;CALL_TYPE 标识叫车方式,分为从调度中心派单(A)、在特定站点向司机叫车(B)和其他方式(C) ;ORIGIN_CALL 在 CALL_TYPE 为 A 时标识行程客户的电话号码,否则为 NULL ;ORIGIN_STAND 在 CALL_TYPE 为 B 时标识出租车起始站点,否则为 NULL ;TAXI_ID 标识执行行程的出租车司机;TIMESTAMP 以Unix时间戳记录行程开始时间;DAYTYPE 标识行程开始日期类型,分为节假日或特殊日(B)、特殊日前一天(C)和普通日(A) ;MISSING_DATA 表示GPS数据流是否完整;POLYLINE 记录行程的GPS坐标序列。行程总时长通过 (POLYLINE中的点数 - 1) x 15 秒计算,部分行程存在数据缺失,这为研究带来挑战。
为了更好地分析数据,我们使用Python进行数据处理。
接着读取数据并进行初步处理:
ini
代码解读
复制代码
source = pd.read_csv("tr.cv", sep=",", low_memory=False)
no_poly_source = source.loc[:, source.columns!= 'POLYLINE']
miss_false_no_poly_source = no_poly_source[no_poly_source.MISSING_DATA == False]通过这几步,我们筛选出了GPS数据完整且不含 POLYLINE 列的数据子集,为后续分析做准备。
数据可视化分析
数据可视化能够帮助我们直观地发现数据中的规律和特征。我们对数据从多个维度进行了可视化探索。
在时间维度上,通过提取数据中的年、月、日、时等信息,绘制了各类图表。例如,绘制年份分布饼图,观察每年出行数据的占比:
还绘制了出行数量随日期的变化折线图,清晰呈现出不同日期出行量的波动趋势:
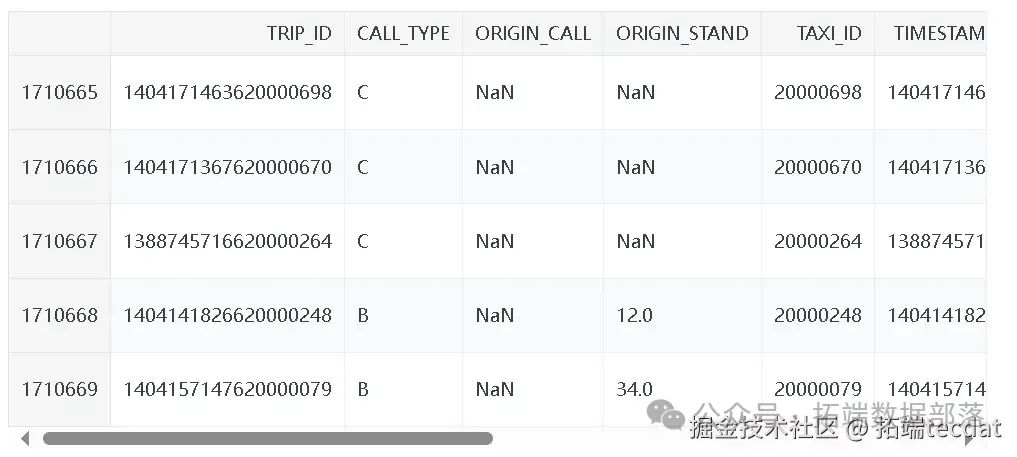
此外,还分析了每月、每月中的每一天、每周的每一天的出行数量分布情况,绘制了相应的柱状图。
每月出行数量柱状图:
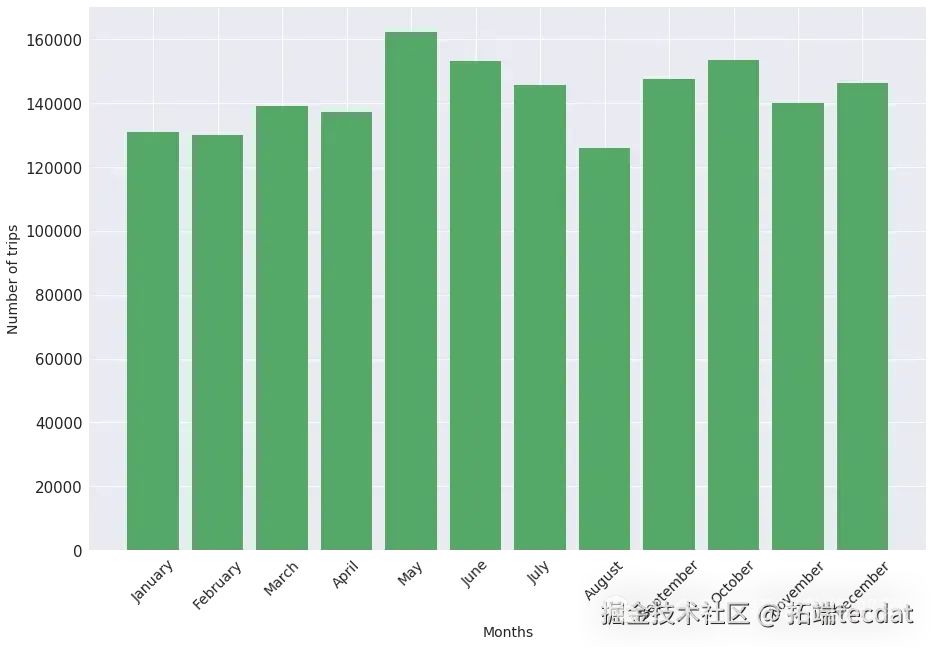
每月中每天出行数量柱状图:
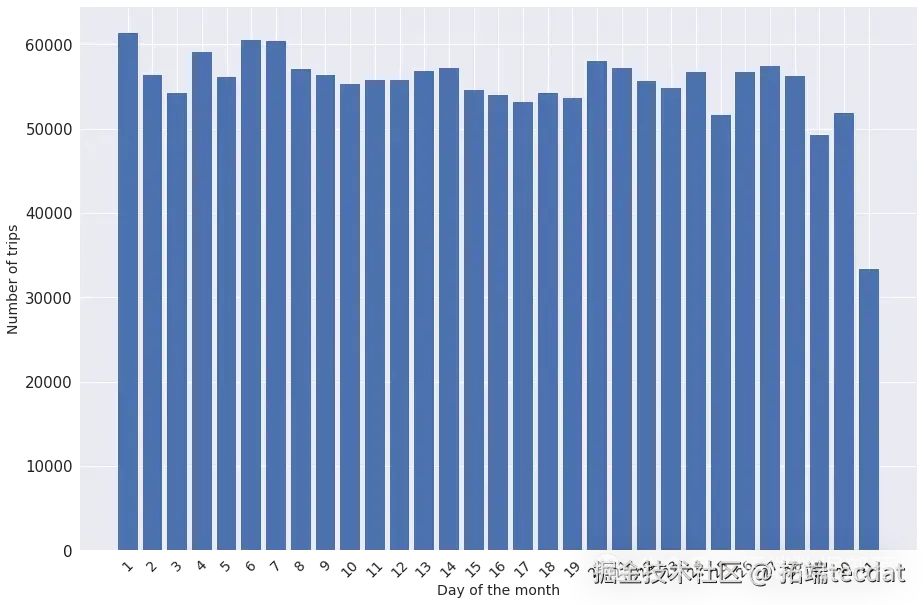
每周中每天出行数量柱状图:
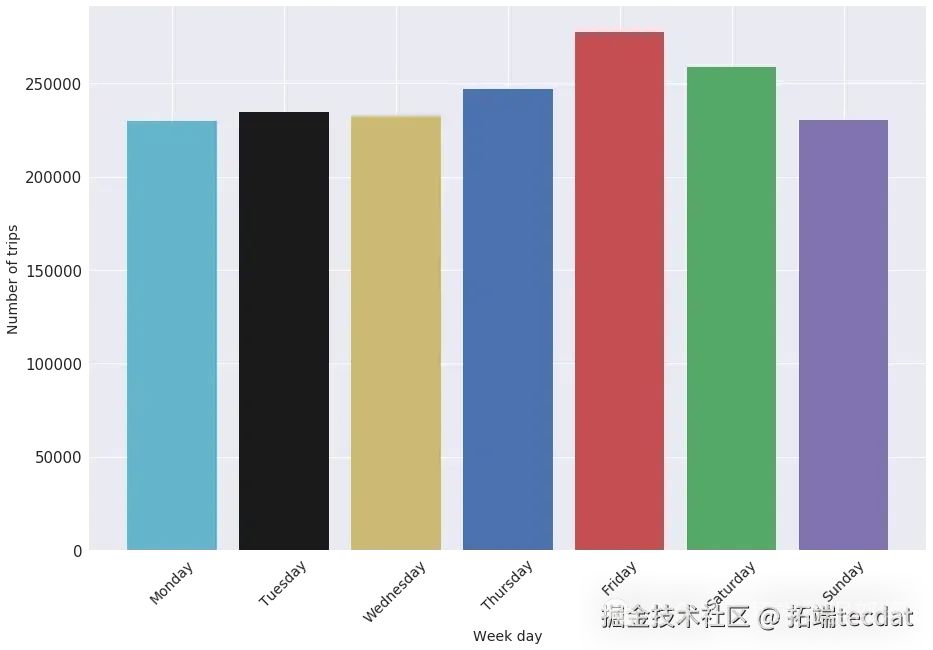
在叫车类型维度,绘制了叫车类型占比的饼图和矩形树图,直观展示不同叫车方式的比例:
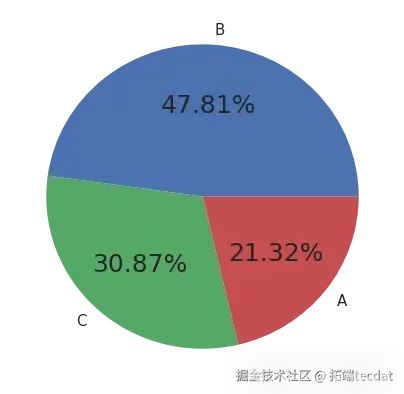
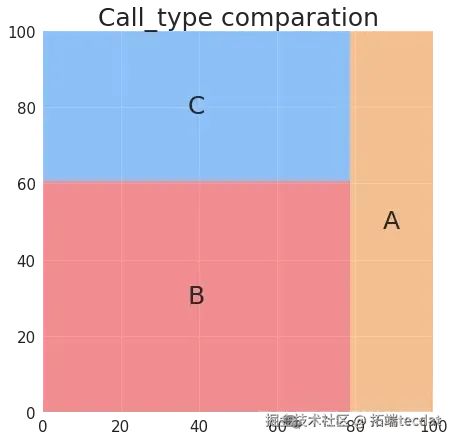
同时,分析了每周不同日期各类叫车方式的出行数量差异,绘制柱状图进行对比:
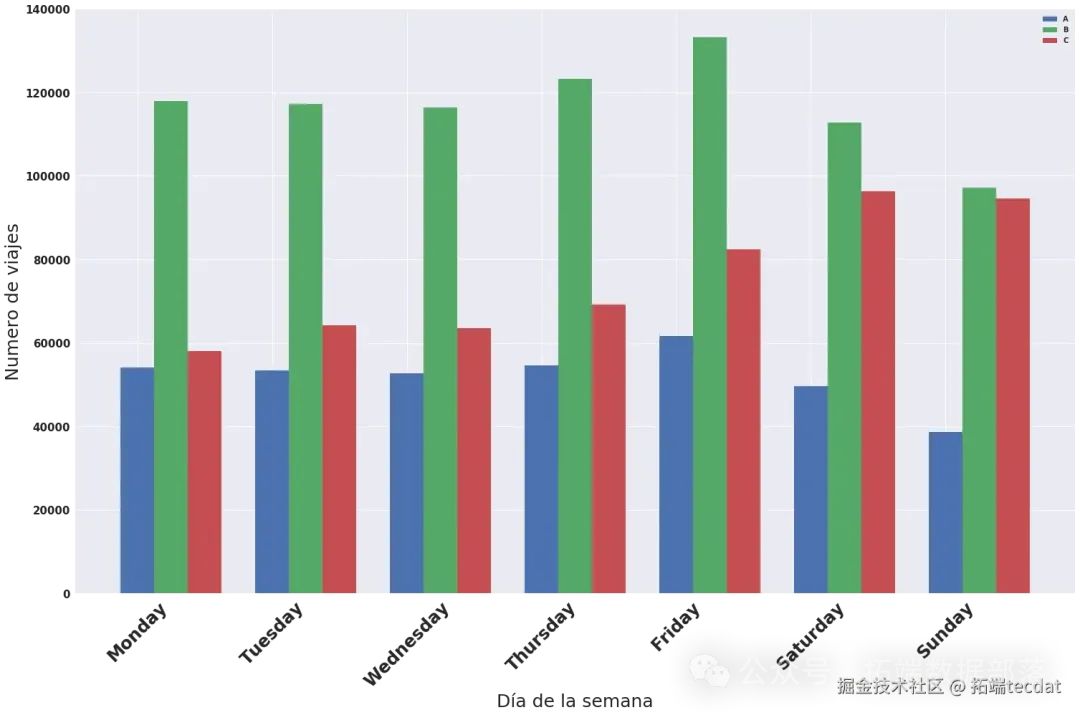
通过这些可视化图表,我们发现出行数量在不同时间和叫车方式上存在明显差异。例如,周末和工作日的出行高峰时间不同,某些叫车方式在特定时间段更为常见。
热图
点击标题查阅往期内容

杭州出租车行驶轨迹数据空间时间可视化分析

左右滑动查看更多
01
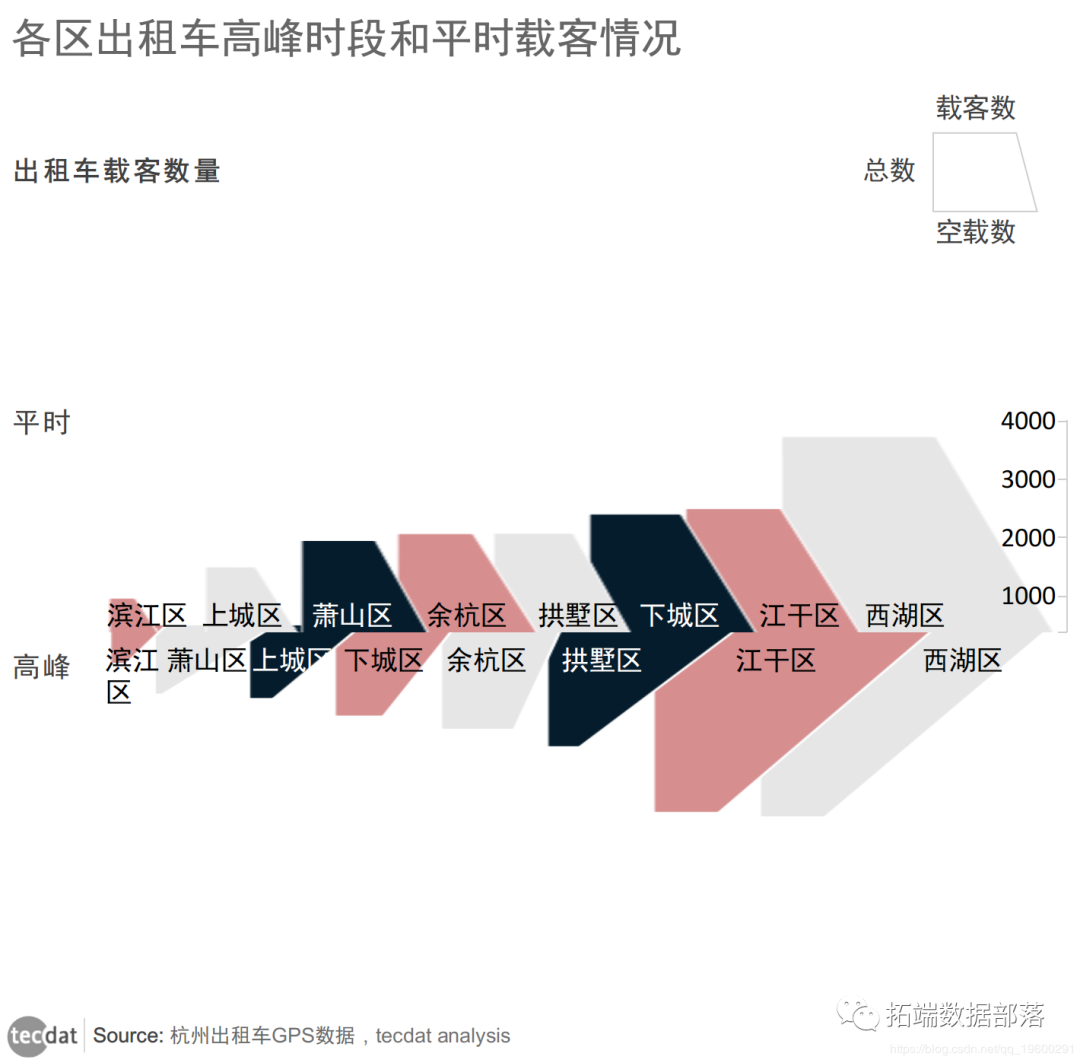
02
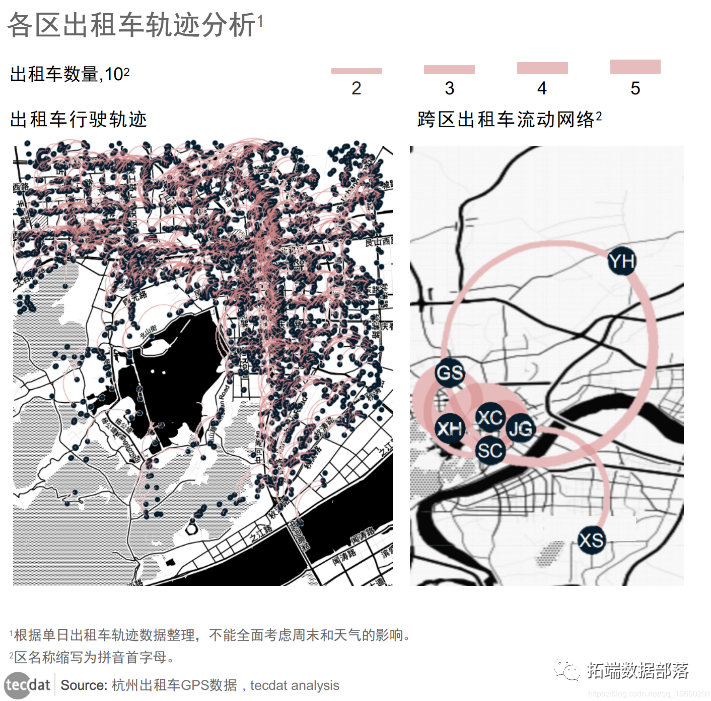
03
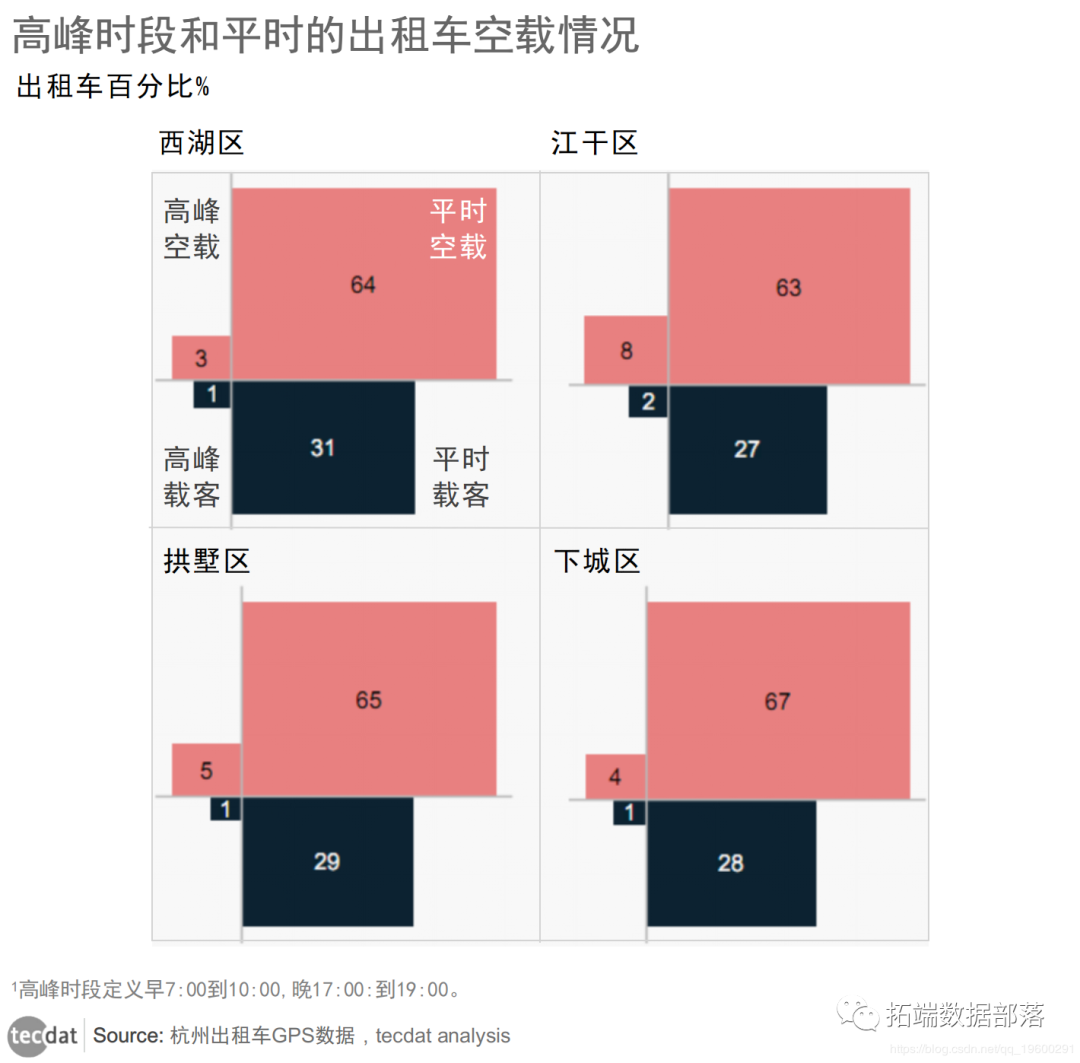
04

出租车出行数据分析与异常检测
AI提示词:请编写代码,使用pandas读取压缩格式的CSV文件,文件路径为’…/sv.zip’,分隔符为逗号,设置低内存模式为False。
ini
代码解读
复制代码
taxi = pd.read_csv(
'..
)出行时间分析
接下来,我们从出行时间的角度对数据进行分析。通过绘制热力图,我们可以直观地看到不同时间段的出行情况。
AI提示词:请使用Python和seaborn库,绘制一个热力图,展示出租车在不同小时和工作日的出行次数分布。需要对数据进行透视表处理,将结果列名设置为中文星期几,使用’coolwarm’颜色映射。
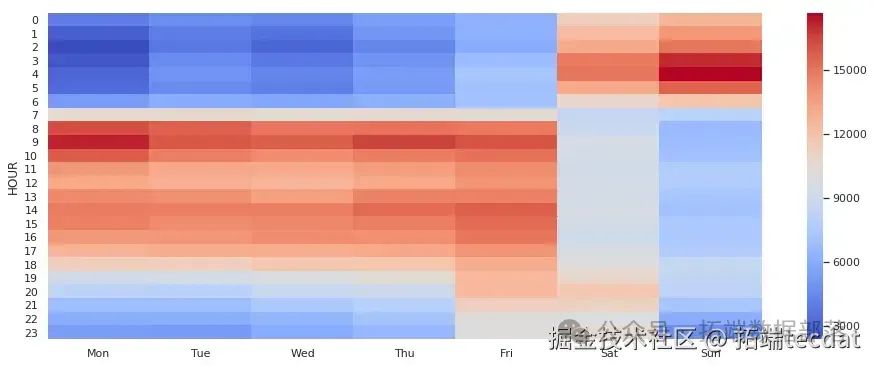
从这个热力图中,我们可以明显看出工作日和周末的出行情况有很大差异。工作日的出行活动主要集中在8点到18点之间,周一的首个小时出现出行高峰。而周五和周六的晚上出行活动也非常活跃,尤其是周六。这表明出行活动主要有两个来源:工作和休闲。工作出行集中在工作日的工作时间,而休闲出行则在周五晚上和周六晚上较为频繁。
我们还可以进一步按照叫车类型对数据进行分组,分析不同叫车类型在不同时间段的出行情况。
AI提示词:请编写一个函数,用于绘制不同叫车类型下,出租车在不同小时和工作日的出行次数热力图。需要对数据进行透视表处理,将结果列名设置为中文星期几,使用’coolwarm’颜色映射。然后使用seaborn的FacetGrid函数按照叫车类型进行分组绘制。
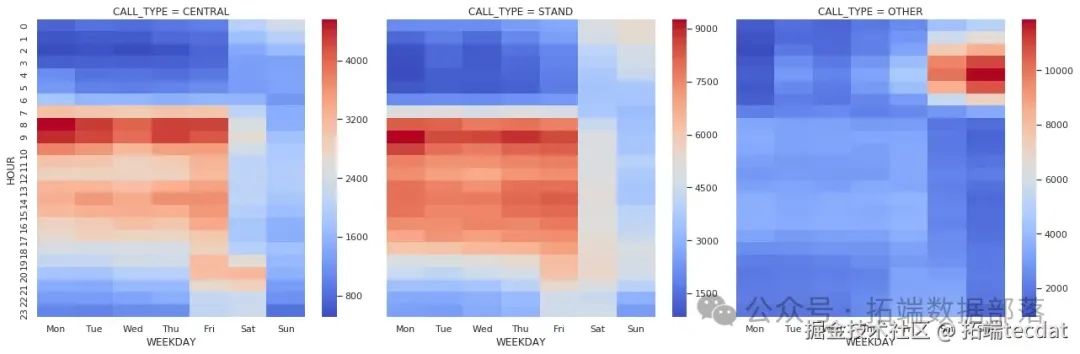
从这个分析中我们发现,不同叫车类型的出行时间分布有明显差异。“其他”叫车类型主要集中在周五和周六晚上,可能是因为出租车司机在这些时间段前往休闲区域接客。而从调度中心派单的出行,在早上首个小时和其他时间段有较大反差,周五和周六晚上有一个小高峰。在站点叫车的出行情况则相对平稳,有特定的活动水平和时间。这说明叫车类型与出行活动有很大的相关性。
我们继续探究一年中不同周、不同工作日的出行次数分布情况。
AI提示词:编写代码处理数据,去除重叠日期数据,提取周数信息,通过透视表计算不同周、不同工作日的出行次数,设置中文星期几为索引,反转星期顺序后绘制热力图。
ini
代码解读
复制代码
# 去除最后一天(6月30日,2014年),因其存在数据重叠问题
taxi = taxi[(taxi.YEAR != 2014) | (taxi.MONTH != 6) | (taxi.DAY != 30)]
taxi["WEEK_NUMBER"] = taxi.TIMESTAMP.apply(lambda x: datetime.fromtimestamp(x).isocalendar()[1])
data = taxi.pivot_table(
从这张图中,我们能发现一些特殊日期出行次数的变化,像1月1日、12月25日等节假日,以及某些特定时间段,出行次数明显不同,背后可能有着各种社会活动或特殊事件的影响 。
行程距离与时长分析
行程的距离和时长也是重要的分析维度。
AI提示词:编写代码,先筛选去除距离和时长的极端值数据,分别通过透视表计算不同小时和工作日的平均行程距离与平均行程时长,然后绘制两张热力图展示结果。
ini
代码解读
复制代码
sns.set(rc={"figure.figsize": (16, 6)})
# 去除行程距离的极端值
taxi = taxi[(taxi.TRIP_DISTANCE < taxi.TRIP_DISTANCE.quantile(0.99))]
distance = taxi.pivot_table(
index="HOUR", columns="WEEKDAY", values=["TRIP_DISTANCE"], aggfunc=np.mean
)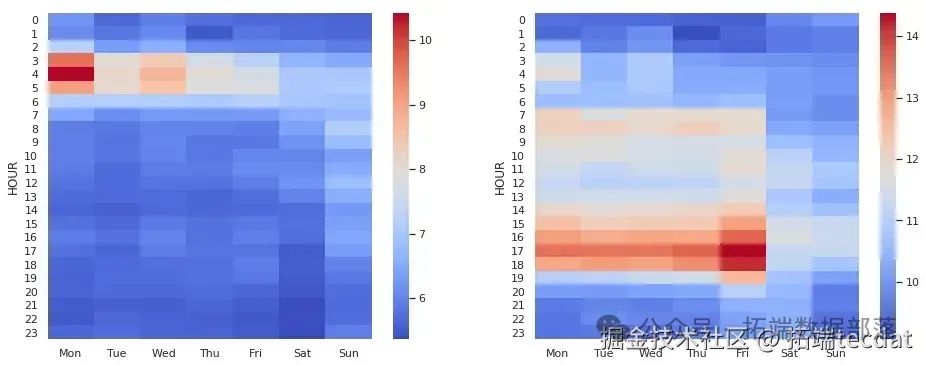
虽然距离和时长高度相关,但它们的均值表现却有所不同。在距离方面,工作日深夜有大量较长距离的行程,周一尤为明显,推测可能是前往机场赶早班机的行程。在时长方面,夜间和周末行程时间低于平均水平,而傍晚尤其是周五,行程时间较长,很可能是交通拥堵导致。
进一步按照叫车类型分组,分析不同叫车类型下行程距离和时长在不同时间段的分布。
AI提示词:编写绘制热力图的通用函数,对数据进行处理和类型转换,使用FacetGrid按叫车类型分组,分别绘制不同叫车类型下行程距离和时长在不同小时和工作日的热力图。
ini
代码解读
复制代码
def draw_heatmap(*args, **kwargs):
data = kwargs.pop("data")
d = data.pivot_table(
index=args[0], columns=args[1], values=args[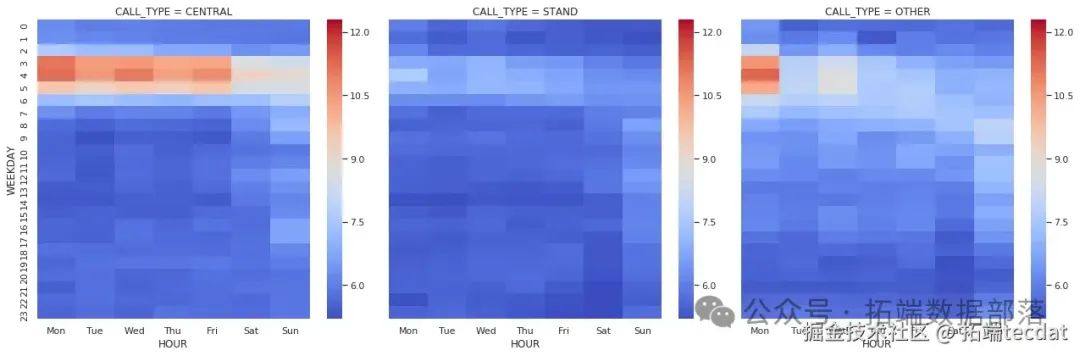
ini
代码解读
复制代码
# 绘制行程时长热力图
g = sns.FacetGrid(data, co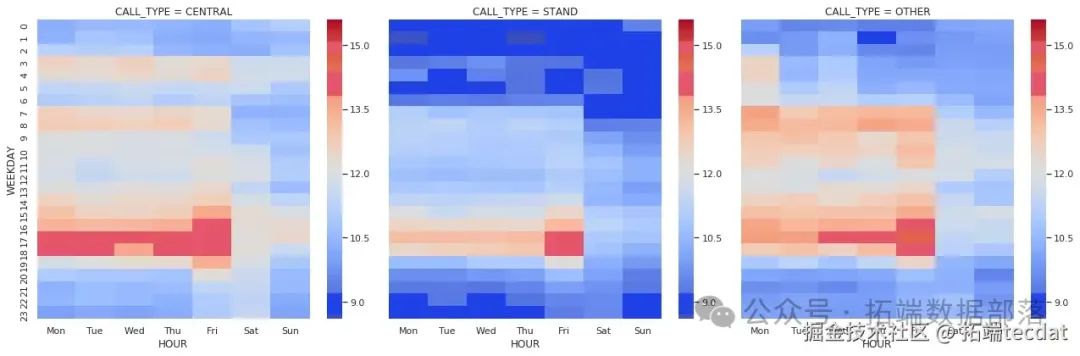
同时,我们也分析了一年中不同周、不同工作日的平均行程距离和时长情况。
AI提示词:编写代码处理数据,去除重叠日期数据,提取周数信息,分别通过透视表计算不同周、不同工作日的平均行程距离和平均行程时长,设置中文星期几为索引,反转星期顺序后绘制热力图。
ini
代码解读
复制代码
# 去除最后一天(6月30日,2014年),因其存在数据重叠问题
taxi = taxi[(taxi.YEAR != 2014) | (taxi.MONTH != 6) | (taxi.DAY != 30)]
taxi["WEEK_NUMBER"] = taxi.TIMESTAMP.apply(lambda x: datetime.fromtimestamp(x).isocalendar()[1])
# 计算平均行程距离
data = taxi.pivot_table(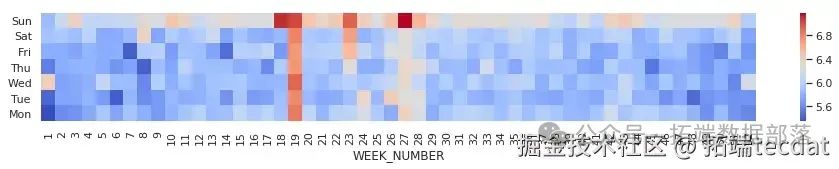
ini
代码解读
复制代码
# 计算平均行程时长
data = taxi.pivot_table(
index="WEEKDAY", columns="WEEK_NUMBER", values="TRIP_TIME", aggfunc=np.mean
)
异常数据检测
在查看出租车行驶路线时,我们发现部分路线存在巨大的不连续性,这可能是异常值或数据采集问题导致的。为了检测这些异常数据,我们先从速度和距离的角度进行分析。
AI提示词:请编写代码,使用sklearn库中的DistanceMetric计算经纬度之间的距离,定义函数计算两点之间的速度,并绘制速度的经验分布函数图。
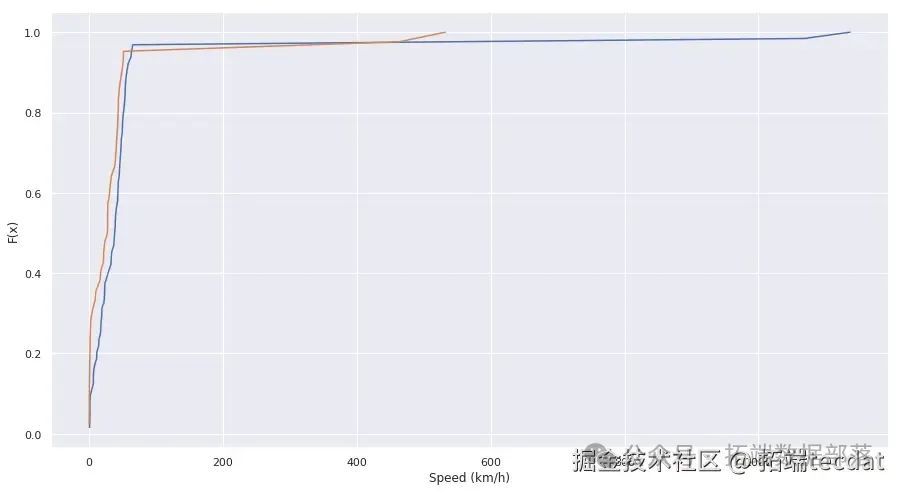
从速度的经验分布函数图中可以看出,异常点的速度与行程中的其他速度明显不同。接下来,我们绘制点间速度随距离变化的热力图,进一步分析异常数据的特征。
AI提示词:请编写代码,定义一个函数用于绘制点间速度随距离变化的热力图,然后绘制两条轨迹的热力图。
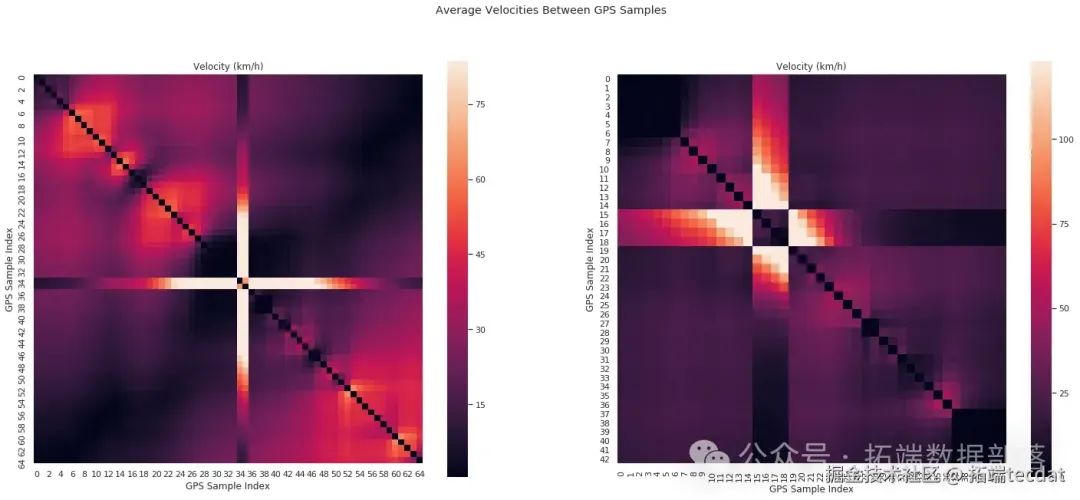
通过这些可视化分析,我们可以直观地看到异常点的存在。为了更系统地检测异常点,我们进一步分析GPS坐标点间距离的分布,发现其符合一定规律。我们利用这个规律,构建了基于贝叶斯概率的异常点检测模型。
AI提示词:请编写代码,定义一个函数计算GPS坐标点的似然值,一个函数对似然值进行归一化处理,一个函数绘制似然值曲线,然后绘制四条轨迹的似然值曲线。
python
代码解读
复制代码
deflikelihood(coords, ab):
n = len(coords)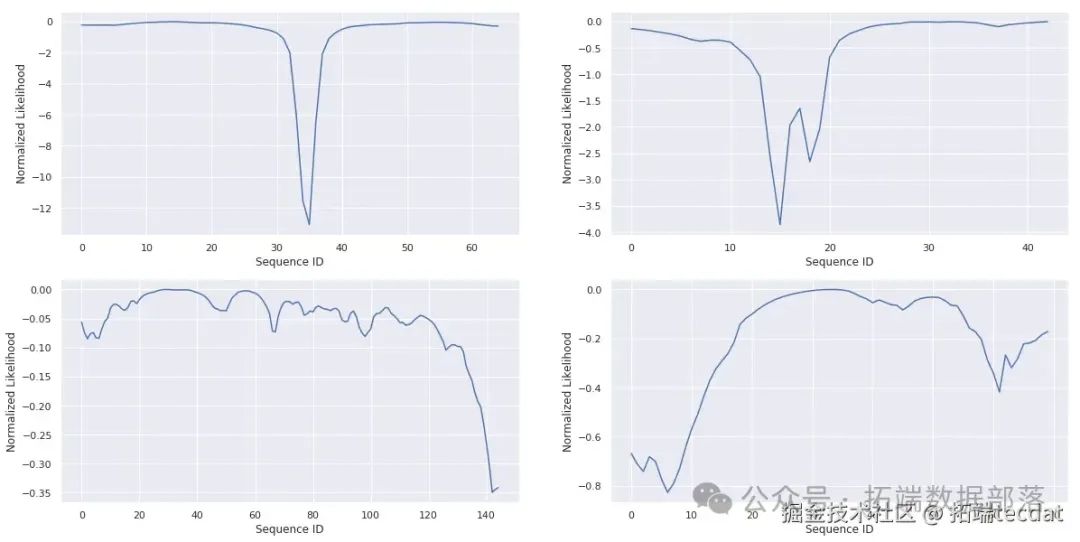
通过计算每个点在路线中的对数似然比,我们设定一个阈值,以此判断该点是否为异常点。
AI提示词:编写代码确定检测参数,包括取轨迹长度的90%分位数作为长度标准,设定似然比阈值;然后应用异常检测方法标记可能存在异常点的轨迹,绘制热力图展示结果;最后统计存在无效GPS坐标的路线数量。
通过上述操作,我们成功检测出约10%的存在无效GPS坐标的路线。
css
代码解读
复制代码
bad_routes = df.traj.apply(lambda t: (norm_lr(likelihood(t,coeffs)) < thresh).any()).values
print("存在无效点的路线: {} / 总路线数".format(bad_routes.sum()))为了验证检测结果的可靠性,我们随机抽取一些被标记为存在异常的路线进行可视化检查。
AI提示词:编写函数对指定路线进行可视化检查,在轨迹图上标记出检测到的异常点;然后调用函数对多条路线进行检查。
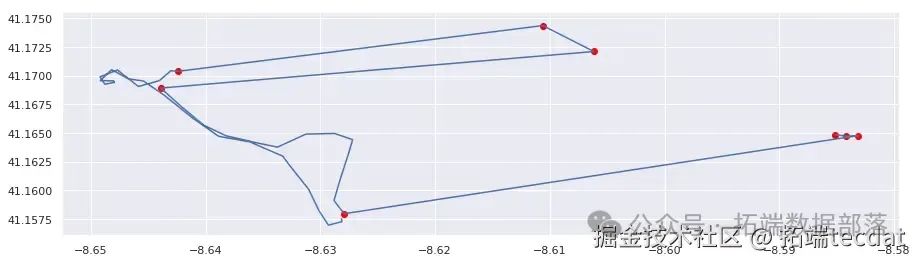
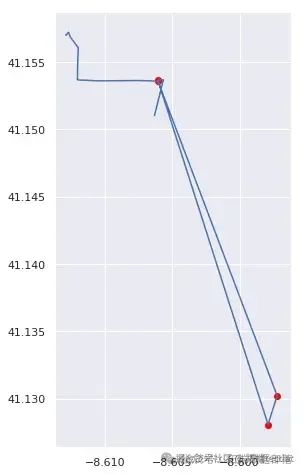
最后,我们绘制未检测出异常点的路线图,与之前的结果进行对比。
ini
代码解读
复制代码
df[~bad_routes].lines.plot(figsize=[15,15])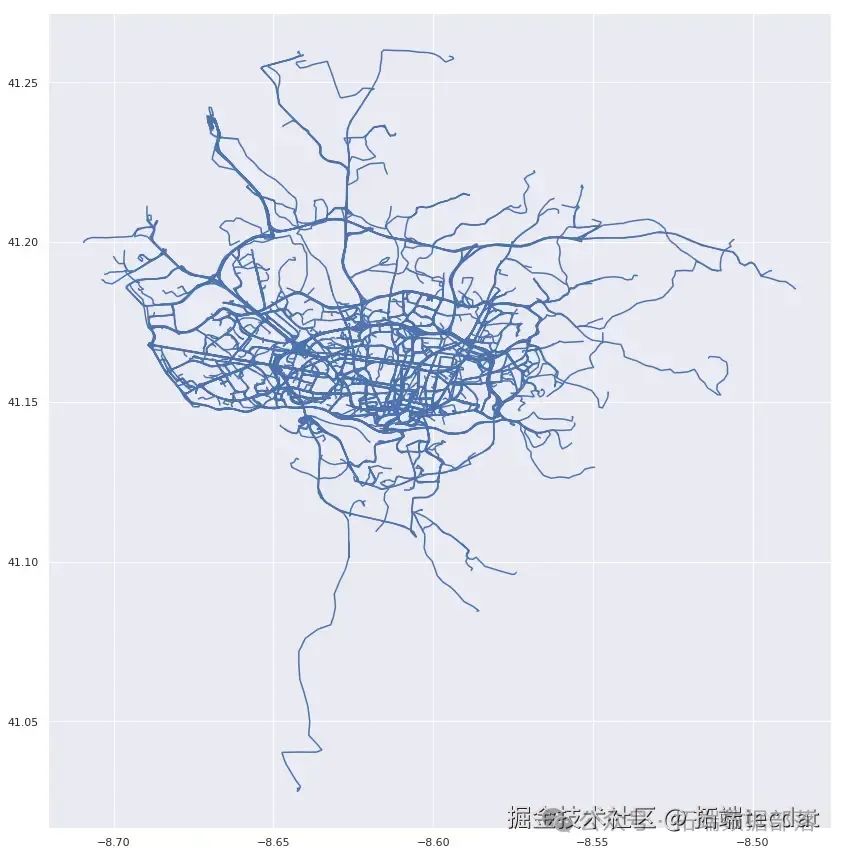
通过对出租车出行数据抽丝剥茧般的分析,我们像侦探破案一样,发现了出行活动在时间和叫车类型上的规律。从热力图中,我们能清晰看到工作日和周末出行高峰的差异,也了解到不同叫车类型在不同时间段的活跃程度。同时,我们还找到了一种有效的异常数据检测方法,利用贝叶斯概率模型,成功揪出了约10%存在无效GPS坐标的路线。
然而,这只是探索城市交通数据宝藏的开始。我们虽然发现了异常数据,但还不清楚它们产生的具体原因。是高楼大厦影响了信号接收?还是数据采集设备出了问题?此外,检测出异常数据后,如何用更准确的数据替换这些无效数据段,也是一个亟待解决的问题。
在对出租车出行数据进行了详细的探索性分析和异常数据检测后,我们进一步深入研究,尝试构建多种机器学习模型来对出租车的行程进行预测,以便更精准地把握出租车出行的规律,为城市交通规划和运营提供更有力的支持。
机器学习模型的构建
为了构建合适的机器学习模型,我们首先对数据进行了必要的预处理和特征工程,将数据划分为训练集和测试集,分别用于模型的训练和评估。以下是我们构建的几种常见的机器学习模型及其实现过程。
随机森林回归器
AI提示词:请使用Python编写代码,构建一个多输出的随机森林回归模型,设置随机森林的估计器数量为100,随机种子为1。然后使用训练数据对模型进行训练,并分别对训练集和测试集进行预测,最后计算并输出训练集和测试集上的均方误差以及R²分数。
python
代码解读
复制代码
from sklearn.ensemble import RandomForestRegressor
from sklearn.multioutput import MultiOutputRegressor
from sklearn.metrics import mean_squared_error, r2_score
# 构建多输出随机森林回归器
forest = MultiOutputRegressor(RandomForestRegressor(n_estimators=100, random_state=1))
# 模型训练
forest = forest.fit(X_train, y_train)
# 对训练集和测试集进行预测
随机森林回归器通过集成多个决策树来进行预测,能够有效地处理复杂的非线性关系。从结果中我们可以看到,它在训练集和测试集上都取得了一定的性能表现。
梯度提升回归器
AI提示词:编写Python代码,构建一个多输出的梯度提升回归模型,设置随机种子为0。使用训练数据进行模型训练,然后对训练集和测试集进行预测,最后计算并输出在训练集和测试集上的均方误差以及R²分数。

梯度提升回归器通过迭代地拟合弱学习器来逐步提升模型的性能,对于一些具有复杂模式的数据往往能有较好的表现。从其性能指标来看,它在训练集和测试集上的表现也各有特点。
多输出线性回归
AI提示词:请用Python实现一个多输出的线性回归模型,设置线程数为1。使用划分好的训练数据对模型进行训练,接着分别对训练集和测试集进行预测,最后计算并输出训练集和测试集上的均方误差以及R²分数。

线性回归是一种简单而经典的回归模型,假设自变量和因变量之间存在线性关系。通过计算性能指标,我们可以评估它在出租车行程预测任务中的适用性。
多输出k近邻回归
AI提示词:编写Python代码构建多输出的k近邻回归模型。使用训练数据对模型进行训练,然后分别对训练集和测试集进行预测,最后计算并输出在训练集和测试集上的均方误差以及R²分数。

k近邻回归算法基于样本之间的距离来进行预测,简单直观。通过在训练集和测试集上的评估,我们可以了解它在出租车行程数据上的表现。
多输出决策树回归
AI提示词:请使用Python构建一个多输出的决策树回归模型,设置最大深度为50,随机种子为1。使用训练数据训练模型,然后分别对训练集和测试集进行预测,最后计算并输出训练集和测试集上的均方误差以及R²分数。

决策树回归通过对数据进行递归划分来构建模型,能够处理非线性关系。通过性能指标的计算,我们可以判断它在出租车行程预测中的效果。
模型评估与展望
通过对以上多种机器学习模型的构建和训练,以及在训练集和测试集上的性能评估,我们得到了各个模型的均方误差和R²分数等指标。这些指标反映了不同模型在出租车行程预测任务中的表现差异。
从结果来看,不同的模型各有优劣。例如,随机森林回归器和梯度提升回归器在处理复杂数据关系时可能具有更好的性能,但计算成本相对较高;而线性回归模型简单直观,但对于非线性数据的拟合能力可能有限。
在未来的研究中,我们可以进一步优化这些模型,比如调整模型的超参数、尝试更多的特征工程方法,或者结合多个模型的预测结果,以提高预测的准确性和可靠性。同时,我们还可以将这些模型应用到实际的城市交通场景中,为出租车调度、交通流量优化等提供更有效的支持,真正实现数据驱动的城市交通管理和决策。

本文中分析的完整数据、代码、文档分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取完整代码、数据、文档。
本文选自《Python+AI提示词出租车出行轨迹:梯度提升GBR、KNN、LR回归、随机森林融合预测及贝叶斯概率异常检测研究》。
点击标题查阅往期内容
基于出租车GPS轨迹数据的研究:出租车行程的数据分析
用数据告诉你出租车资源配置是否合理
把握出租车行驶的数据脉搏 :出租车轨迹数据给你答案!
基于出租车GPS轨迹数据的研究:出租车行程的数据分析
用数据告诉你出租车资源配置是否合理
共享单车大数据报告
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
消费者共享汽车使用情况调查
新能源车主数据图鉴
python研究汽车传感器数据统计可视化分析
R语言ggmap空间可视化机动车交通事故地图
R语言ggmap空间可视化机动车碰撞–街道地图热力图



![]()