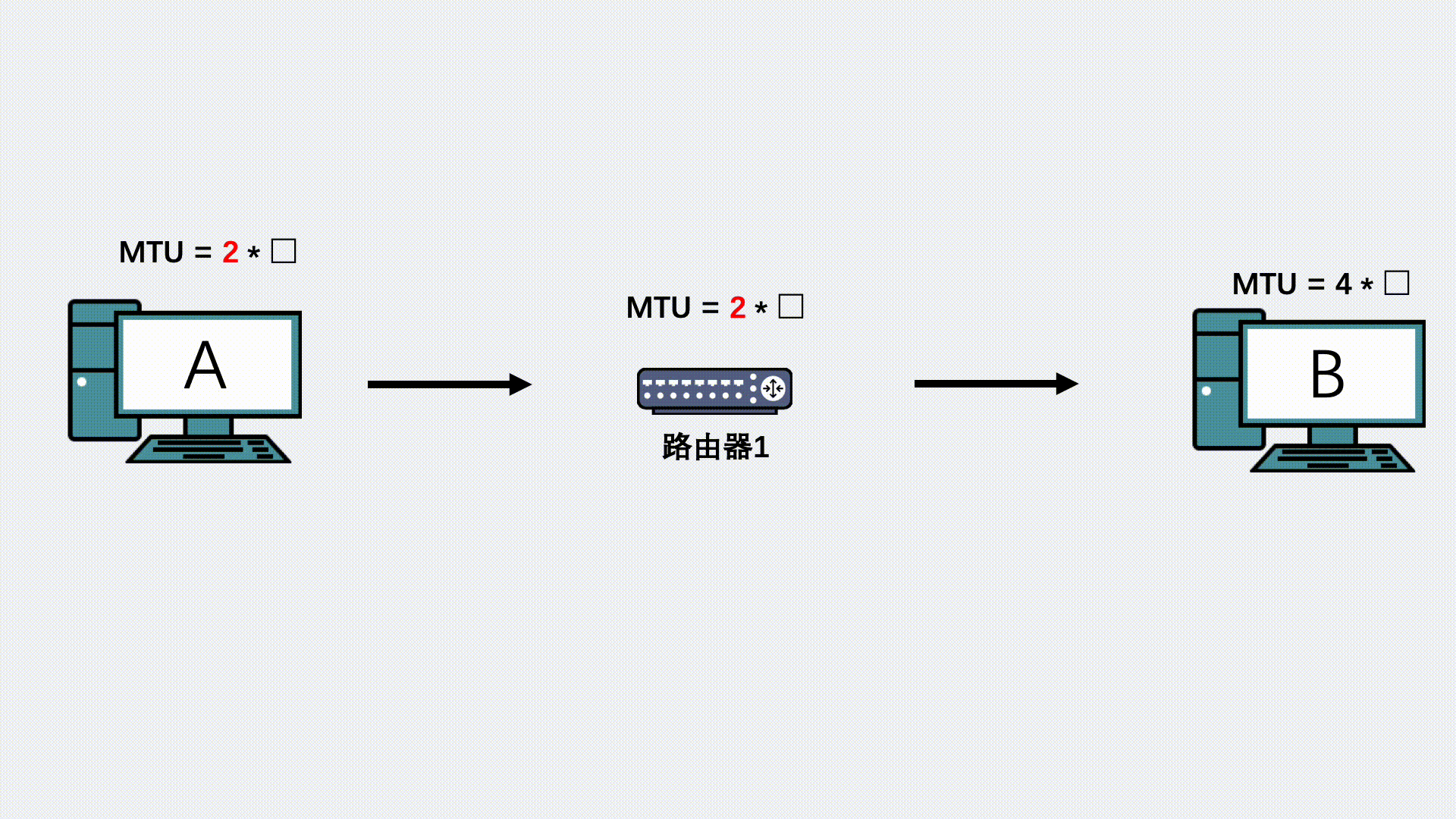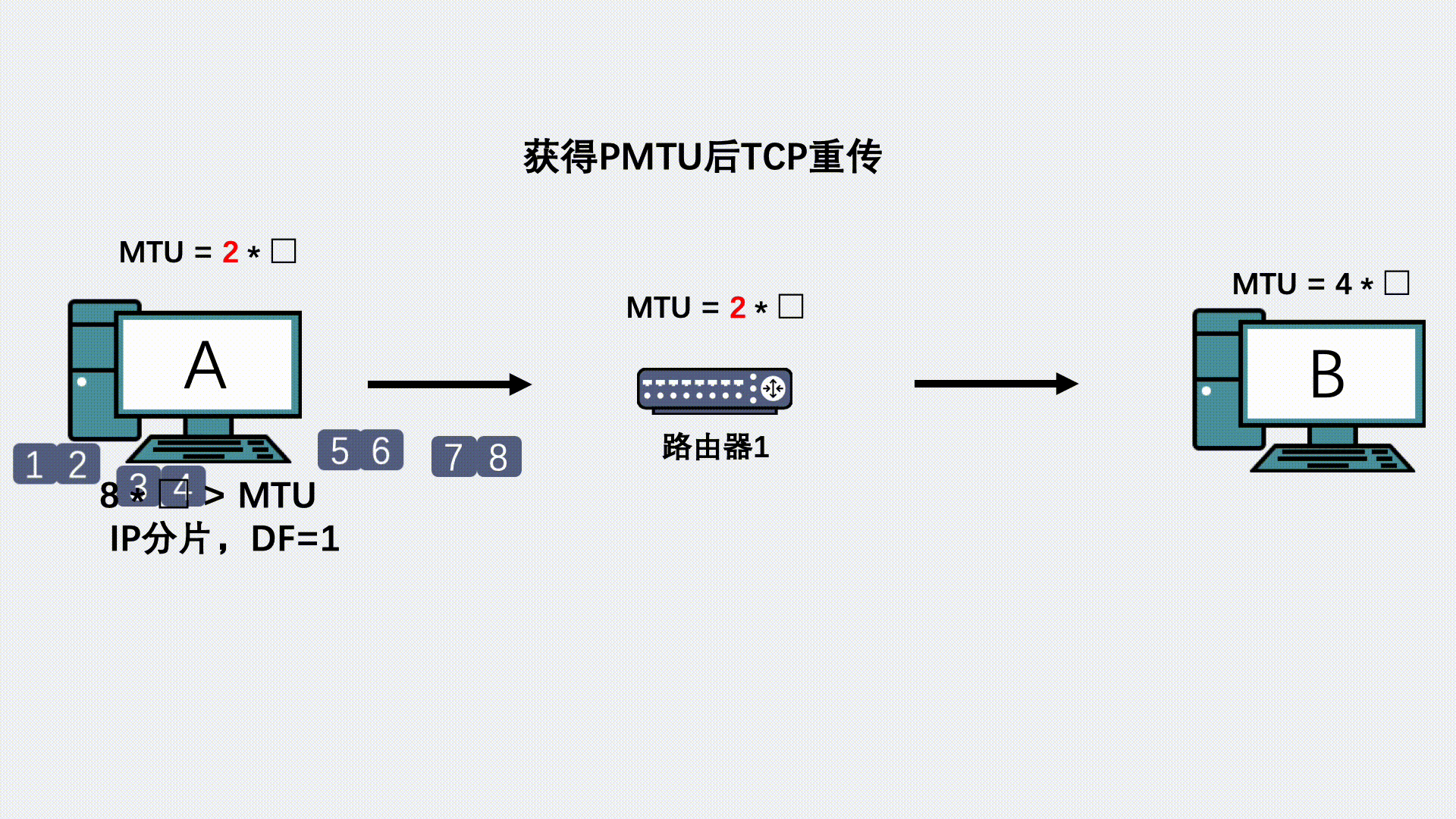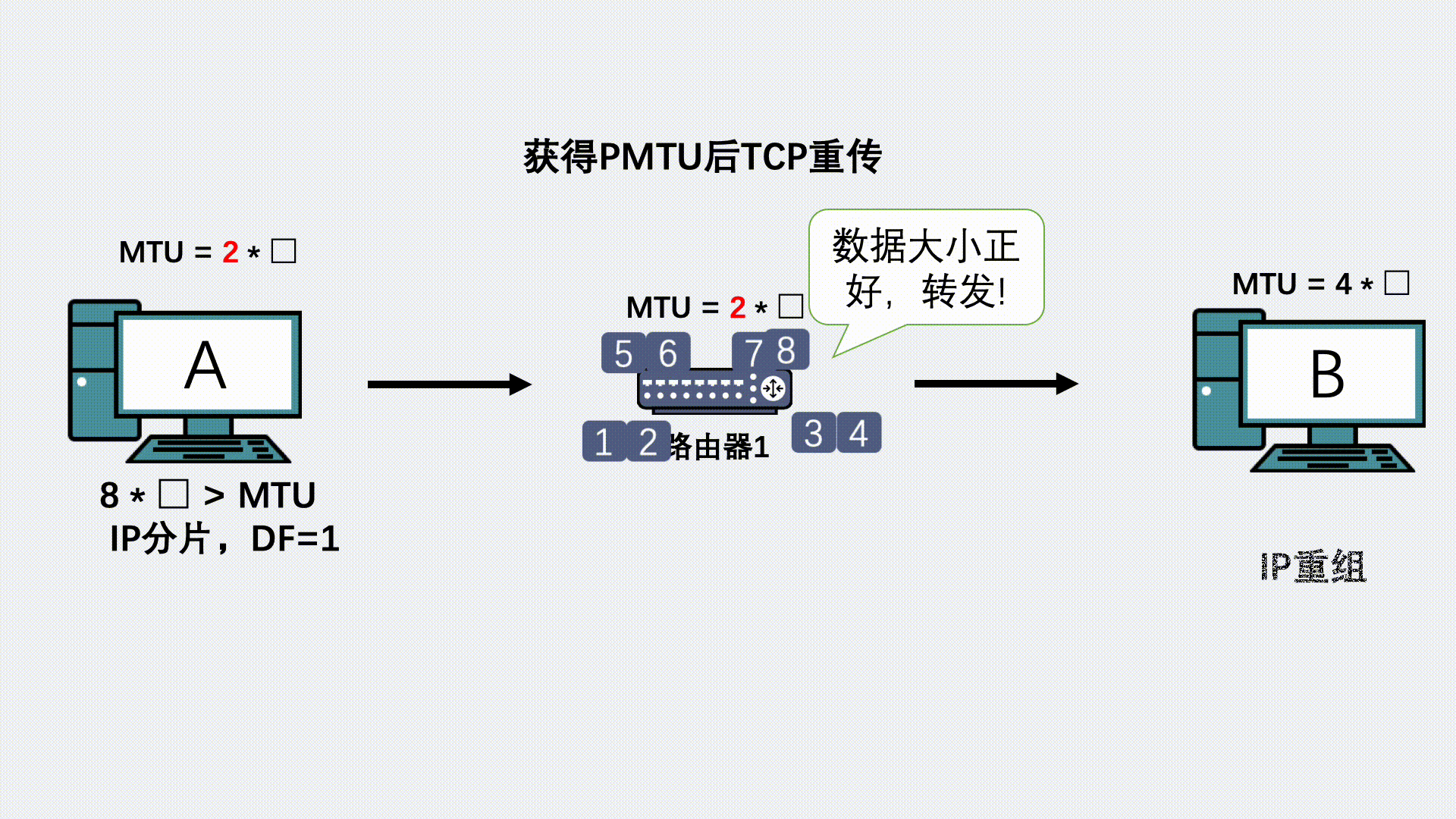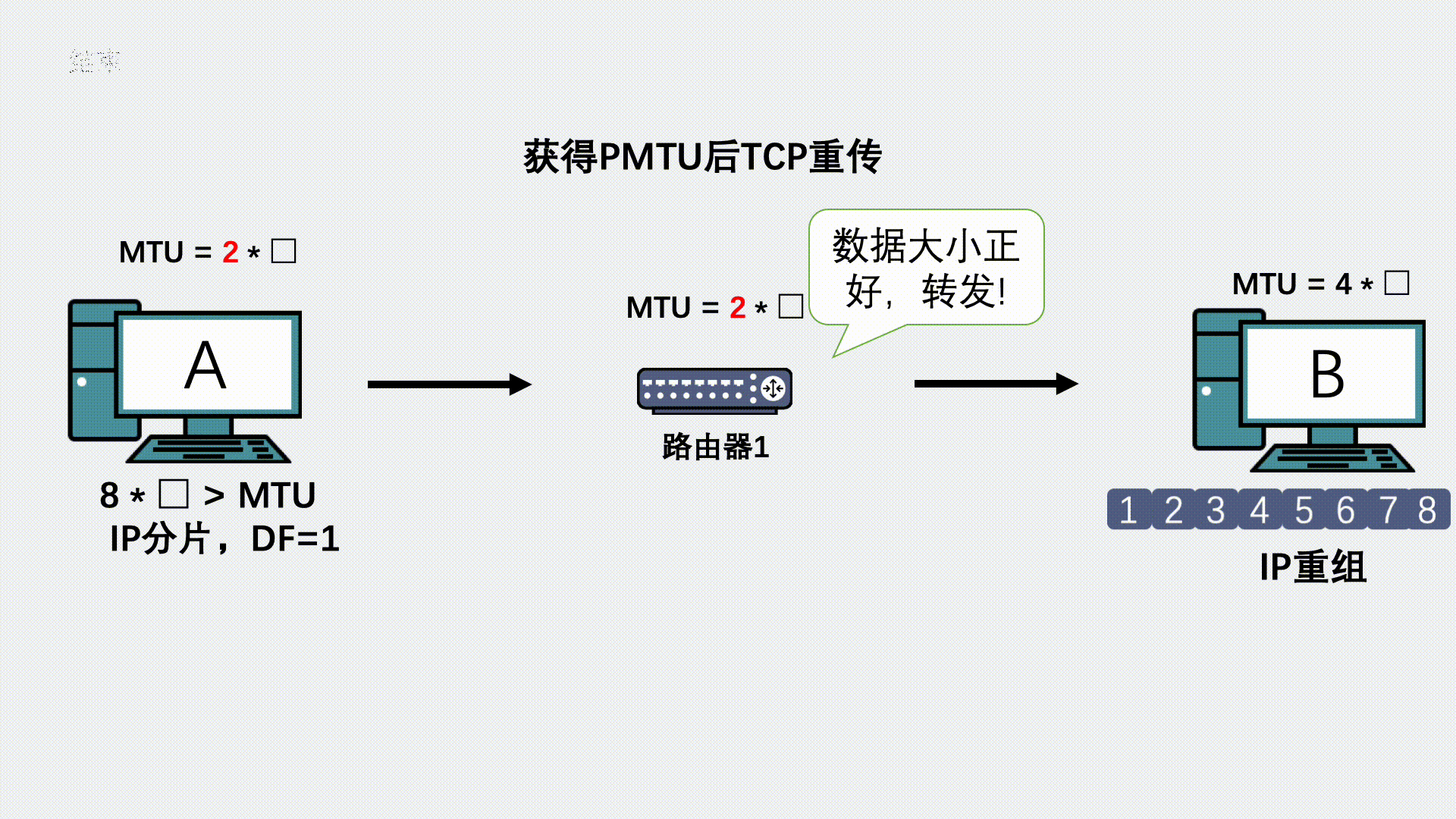
The Cherno——OpenGL
1. 欢迎来到OpenGL
OpenGL是一种跨平台的图形接口(API),就是一大堆我们能够调用的函数去做一些与图像相关的事情。特殊的是,OpenGL允许我们访问GPU(Graphics Processing Unit 图像处理单元,也就是显卡),可以更好地绘制图形。

实际上,为了利用在电脑或其他设备(比如手机)中强大的图形处理器,需要调用一些API访问固件。OpenGL正好是允许访问和操作GPU的许多接口中的一种。当然还有其他接口,Direct3D、Vulcan和Metal等。总的来说,在一定程度上,OpenGL允许我们控制显卡。
需要澄清一下一些人的误解,许多人称它为一个类库或一种引擎或其他的(比如框架),但这些都不是,OpenGL核心本身只是一种规范,算起来跟CPP规范差不多。实际上,它没有确定任何代码和类似的事情,本身就是规范,比如这个函数需要哪些参数,返回什么值。它只是一种你能利用这种API干什么的规范,没有任何具体的实现,这意味它绝不是一个类库,因为OpenGL本身没有代码,它只是一种规范,所以OpenGL本身不需要下载。那么谁去实现它呢,谁去为你调用的OpenGL函数写代码呢?答案是GPU制造商。如果你使用的是NVIDIA显卡,那么你的显卡驱动,也就是NAVIDIA驱动实际上包含了OpenGL的实现。
OpenGL的实现是每个显卡制造商,比如AMD、Intel等,都有自己的实现,每一家关于OpenGL的实现都会有些不同。这也就是有些游戏能在NAVIDIA驱动的NVIDIA显卡上运行,但在其他显卡设备上运行有些区别甚至出问题的原因。但不管怎么说,关键在于你的显卡制造商实现的OpenGL。这又可能导致下一个有关OpenGL常见的误解:它是开源的。它根本不是开源的,你看不到OpenGL的源码。因为首先它是由GPU制造商实现的,他们肯定不会公布他们的驱动源码。
总结就是OpenGL是在你的显卡驱动中实现的,并且它只是我们去控制显卡的规范。
传统OpenGL和现代OpenGL之间的区别:
OpenGL于90年代发布,那时的GPU是不可编程的,不能随心所欲,尤其在使用这些底层的API时。但现在人们可以很大程度去控制它,制造商给了程序员和开发者更多的控制权,这显然很好,因为我们可以为它做更多的优化。现代的OpenGL更像一个循环,一个低级的法则,它能给你比之前更多的控制权。传统的OpenGL更像是一套程序。
所以比如要画一个三角形,并且想要添加光源,基本上就是让光源等于true,就可以激活OpenGL的光源,然后就再告诉OpenGL光源加在哪里就可以了。所以传统的OpenGL真的很像一套预设,很容易使用代码比较少。但这样就会造成不能给你太多的控制权。但其实我们是想要更多的控制权的。
传统OpenGL和现代OpenGL之间最大的区别是可编程的着色器。 着色器是程序,它是运行在GPU上的代码。当我们使用cpp或Java等语言写代码时,这些代码是运行在CPU上的,但当我们开始处理图形的大部分时间里,我们想要更为精确的控制显卡运行,我们可能要将大部分代码从CPU转到GPU上,因为它在GPU上运行更快,这就是着色器存在的意义,允许我们在GPU上运行代码。
为什么说OpenGL是一种图形API又说它本身不是,而是一种规范?
说OpenGL是一种图形API,是因为它提供了一组函数和规范用于描述和操作图形硬件。然而它本身并不是API,而是一种规范,这个规范定义了函数和操作的方式,以及它们应该如何工作。
2. 设置OpenGL和在C++中创建一个窗口
GLFW是一个轻量级的类库,它能为我们做的事就是创建窗口、创建OpenGL的上下文以及给我们访问一些像输入之类的基础东西。
当我们需要下载GLFW的二进制文件时,可以选择32位或64位的,但我们应该如何选择呢?有些人可能会想我使用的是64位Windows系统,所以就选择64位的Windows二进制文件。然而这是一个错误的想法。实际上需要哪种架构,问题在于你项目需要构建的架构。如果我们设置我们的VS项目去构建win32或x86,那么我们就需要下载32位的二进制文件。如果我们的应用架构的是64位或x64,那么就需要选择64位二进制文件。所以实际上这个问题的关键在于架构,你的应用的平台架构,所以,你如何编译你的应用不是你正在使用的操作系统,当然64位的应用不会在一个32位操作系统上运行。但是如果在一个64位操作系统上,就可以运行32位和64位的应用。所以实际上下载哪个取决于你在哪个平台编译你的应用。
3. 在C++中使用现代OpenGL
当我们使用一些库函数时,实际上,我们需要去访问这些驱动,取出函数,并且调用它们。注意这里并不是字面上说的把函数取出来,实际上需要做的就是得到函数声明,然后设置链接,链接到对应的函数上。所以,我们需要访问驱动的动态链接库文件,然后只检索库里面那些函数的函数指针,这就是我们需要做的。
其实我们可以自己来实现这个事情,但它有一些问题,首先,它不可能是跨平台的,访问显卡驱动并从中取出这些函数,我们需要使用一些win32接口调用,当我们在Windows上的时候,载入库或载入函数指针等等。但这并不太好,因为它只能在Windows上用。第二个问题就是,如果超过一千个函数或之类的一些事情,那么我们需要手动去完成这些操作,并且为它们写代码,这将是一个糟糕的计划。
所以实际上我们做的就是,我们实际上需要使用到一些库,现在确实有一些现成的库可以帮助我们完成一些操作。
接下来将介绍另外一个库(GLEW)。基本上,它能做的就是为你提供OpenGL接口规范各种函数声明、符号声明和常量等诸如此类的东西。 这个库的实际实现,就是进入EDI,在你使用的显卡驱动签名中,查找对应的动态链接文件,然后载入所有这些函数指针,这就是它所能做的。不要认为这些库实现了一些函数或其他的东西,它们并没有,只是为了访问这些函数,而这些函数早就以二进制的形式存在你电脑上了,并且我们使用的这个库只是为我们做了一些事情,比如GLEW(OpenGL扩展管理)和GLAD库(OpenGL的一个比较特殊的扩展)。
说"glew 的实际实现就是进入 EDI,在使用的显卡驱动签名中,查找对应的动态链接文件,然后载入所有这些函数指针"有些过于准确,但大致描述了glew库的实现原理。
具体来说,GLEW库通过封装OpenGL的底层函数调用,提供了一组易于使用的接口,使得开发者可以方便地使用OpenGL的扩展功能。在实现过程中,GLEW库需要加载OpenGL函数库(如gl.dll或libgl.so),并且需要查询和注册OpenGL扩展函数。
在Windows平台上,GLEW库使用Windows API函数来访问和加载动态链接库,并且通过查找和使用特定的函数指针来加载OpenGL函数。在Linux平台上,GLEW库使用dlopen函数来加载OpenGL库文件,并通过查找和使用特定的函数指针来加载OpenGL函数。
因此,可以简单地说,glew库的实现是通过进入EDI(电子数据交换)标准协议,使用相应的显卡驱动签名,查找并加载对应的动态链接文件,然后载入所有这些函数指针,从而使得开发者可以方便地使用最新的OpenGL功能而不需要关心底层的细节。

使用GLEW的注意事项:
- 首先需要创建一个有效的渲染OpenGL上下文,然后调用glewInit()去初始化扩展的入口。所以不能直接从GLEW中直接调用OpenGL函数,直到你调用了glewInit()。
- 在调用glewInit()之前,需要先创建一个渲染OpenGL的上下文。
- 当需要用到glew.h头文件时,要在包含任何其他OpenGL相关的头文件之间就要先包含glew.h。也就是glew.h要放在前面。
glewInit()的返回值是一个整数,如果是GLEW_OK,则说明GLEW初始化成功。如果不是,则初始化失败。

不要认为这两个都是静态库,上面那个是动态库,下面的是静态库。从大小就可以看出来。但从技术上说,他们确实都是静态库。但如果需要链接dll。就要链接glew32.lib;这个glew32s.lib是链接静态库时需要用到的。
总结: 因为不同的平台OpenGL函数存放的地方会有所不同、文件结构也会有所不同,所以需要有一种方式可以自动找到OpenGL函数。GLEW就应运而生,GLEW库通过封装OpenGL的底层函数调用,提供了一组易于使用的接口,使得开发者可以方便地使用OpenGL的扩展功能。在实现过程中,GLEW库加载OpenGL函数库,并且查询和注册OpenGL扩展函数。
4. 顶点缓冲区和在现代OpenGL中画一个三角形
用现代OpenGL画三角形的话,相比传统的OpenGL会比较复杂,传统的只需要调用函数设置参数就行,但现代的需要能够创建一个顶点缓冲区(vertor buffer),还要创建一个着色器(shader)。
buffer就是一块用来存字节的内存,一个内存字节数组。顶点缓冲区跟C++中的字符数组的内存缓冲区不太一样,区别在于它是 OpenGL 中的内存缓冲区,这意味着它实际上在显卡上,在我们的VRAM(显存)中,也就是Video RAM。所以使用现代的OpenGL表示三角形的话,需要定义一些数据来表示三角形,然后把它们放到显卡(GPU)的 VRAM 中,还需要发出 DrawCall 指令(这是一个绘制指令),(意思就是告诉电脑,你的显存中有一堆数据,读取它,并把它绘制在屏幕上),实际上,我们还需要告诉显卡,如何读取和解释这些数据,以及如何把它放到我们屏幕上。当我们在CPU这边做了所有事情(我们用C++写的东西都是在CPU上运行的)。当我们写完这些东西,还要用某种方式告诉显卡,一旦从CPU发出了DrawCall指令,且一旦从显卡读到了这些数据,我希望你在屏幕上给我绘制出三角形。因为我们需要告诉显卡它要做什么,所以需要对显卡编程。并且还有着色器。
着色器是一个运行在显卡上的程序,是一堆我们可以编写的且可以在显卡上运行的代码。 它可以在显卡上以一种非常特殊又非常强大的方式运行。
注意: OpenGL具体的操作就是一个状态机,不需要把它看成对象或类似的东西。 我们所做的就是设置一系列的状态,然后当我们说一些事情,比如说给我绘制个三角形,那是与上下文相关的(先告诉它绘制三角形所需要的数据,然后它才去绘制,这种是分状态的)。换句话说,选择一个缓冲区和一个着色器,让电脑帮我绘制一个三角形。电脑会根据你选择的缓冲区和着色器,决定绘制什么样的三角形,绘制在哪里等等。这就是OpenGL的原理,它是一个状态机。
顶点缓冲区的好处: 顶点缓冲区包含这些顶点的数据,传到OpenGL的VRAM,然后发出一个DrawCall指令,电脑就可以根据缓冲区画出图形了。我们可以在gl渲染循环外面,先定义好缓冲区,在gl渲染循环中,就可以绘制已经存在的数据了。如果出于某些原因,我们需要改变数据帧或者其他东西,我们也可以通过更新缓冲区来做到这一点。
查OpenGL文档的链接: https://docs.gl/。
#include<GL/glew.h>
#include <GLFW/glfw3.h>
#include<iostream>
int main(void)
{
GLFWwindow* window;
/* Initialize the library */
if (!glfwInit())
return -1;
/* Create a windowed mode window and its OpenGL context */
window = glfwCreateWindow(640, 480, "Hello World", NULL, NULL);
if (!window)
{
glfwTerminate();
return -1;
}
/* Make the window's context current */
glfwMakeContextCurrent(window);
if (glewInit() != GLEW_OK)
std::cout << "Error!" << std::endl;
std::cout << glGetString(GL_VERSION) << std::endl;
float positions[6] = { //三个顶点画一个三角形
-0.5f, -0.5f,
0.0f, 0.5f,
0.5f, -0.5f
};
//在OpenGL中生成的所有东西都会被分配一个唯一的标识符,它只是一个整数。比如0、1、2。0通常是一个无效状态,但不都是。
//但基本上会得到一个数字,比如1、2、3等,这是实际对象的id,不管它是顶点缓冲区、顶点数组、着色器还是其他东西,都会得到一个整数来代表它。
//当想要使用这个对象时,就用这个数字
unsigned int buffer; //定义一个缓冲区,无符号int类型,用来存放缓冲区的地址
glGenBuffers(1, &buffer); //定义顶点缓冲区,然后指定要多少个缓冲区,因为我们只需要一个,所以输入 1,第二个参数需要一个无符号整型指针。因为这个函数的返回类型是 void,所以函数不返回生成的缓冲区id,我们要给它提供一个整数(指针)。函数会把id写入这个整数的内存,这就是为什么需要指针。
glBindBuffer(GL_ARRAY_BUFFER, buffer); //绑定缓冲区,第一个参数是目标,GL_ARRAY_BUFFER表示这是一个数组;第二个参数是我们要绑定的缓冲区
glBufferData(GL_ARRAY_BUFFER, 6 * sizeof(float),positions,GL_STATIC_DRAW); //第一个参数是target;第二个参数是指我们希望缓冲区多大或者数据有多大;
/* Loop until the user closes the window */
while (!glfwWindowShouldClose(window)) //glfwWindowShouldClose函数在我们每次循环的开始前检查一次GLFW是否被要求退出,如果是的话该函数返回true然后游戏循环便结束了,之后为我们就可以关闭应用程序了。
{
/* Render here */
glClear(GL_COLOR_BUFFER_BIT);
//传统的OpenGL绘制一个三角形,只需要下列函数,通过指定三个顶点来画三角形
/*
glBegin(GL_TRIANGLES);
glVertex2f(-0.5f, -0.5f); //按住alt+shift
glVertex2f( 0.0f, 0.5f);
glVertex2f( 0.5f, -0.5f);
glEnd();
*/
/* Swap front and back buffers */
glfwSwapBuffers(window); //交换颜色缓冲
/* Poll for and process events */
glfwPollEvents(); //glfwPollEvents函数检查有没有触发什么事件(比如键盘输入、鼠标移动等),然后调用对应的回调函数(可以通过回调方法手动设置)。我们一般在游戏循环的开始调用事件处理函数。
}
glfwTerminate(); //释放glfw分配的内存
return 0;
}
5. 在OpenGL中顶点的属性和布局
经过上一节的学习,我们还需要学习两个东西:顶点属性和着色器。顶点属性就是OpenGL管道的工作方式。
OpenGL管道的工作原理是我们为我们的显卡提供数据,我们在显卡上存储一些内存,它包含了我们想要绘制的所有数据,然后我们使用一个着色器,利用在显卡上执行的程序来读取数据并且完全显示在屏幕上。通常我们画几何图形的方式,就是使用一个叫顶点缓冲区的东西,这基本上是存储在显卡上的内存缓冲区。所以,当对着色器编程时,实际上是从读取顶点缓冲区开始的。当然,着色器需要知道缓冲区的布局,还需要知道是否有纹理坐标、法线之类。目前这个缓冲区包含的就是一堆的浮点数,它们指定了每个顶点的位置。
实际上,我们不得不告诉OpenGL,内存中有什么,又是如何布局的。如果我们不这样做,OpenGL看到的只是一堆字节。glVertexAttribPointer可以为我们做这件事,只有让OpenGL知道了我们的内存布局,它才知道怎么去正确地解析它。

index是需要修改的顶点属性的索引。着色器读取信息的方式就是通过索引,索引是一个快照。index几乎像一个数组,但里面的类型可能不同。一个索引表示实际引用的是哪个属性。顶点不仅由位置组成,有可能还有纹理坐标、法线、颜色等等。这些中的每一个就和位置一样,都是一个属性。所以index就是告诉我们这个属性的索引是什么。一般来说,如果我们有一个位置,例如在索引0处,我们需要把它作为索引0来引用。
size是每个通用顶点属性的组件数(顶点属性总的要用多少个分量来表示),它跟实际大小和字节没有关系,或者是说和它们实际占用了多少内存也没关系。它基本上是计数。
type是类型,比如我们实际的顶点位置,GL_FLOAT(浮点型)。则size表示的就是浮点数的数量。例如我们每个顶点是由两个浮点数组成,则size是2。因为我们提供了一个两个分量的向量来表示我们的位置,如果我们切换到3D坐标系,则size为3,因为是xyz。
normalized(标准化),如果我们处理的是浮点数。则不需要规范化,因为它们已经被规范化了。不需要规范化的话,这个参数可以为GL_FALSE。
stride(步幅)就是每个顶点之间的字节数。假如用上面的例子,一个顶点三个属性,位置、纹理坐标和法线,假如位置是一个三个分量(浮点数,4字节)的向量,纹理坐标是一个两个分量的矢量或两个浮点数,法线是三个分量。这样子一个顶点加起来就有32字节,这就是stride,它是每个顶点的字节大小。有了stride,系统就知道从索引0到索引1要增加32字节。
pointer(指针)是指向实际属性的指针。例如上面的例子中,因为顶点中位置这个属性在32字节的开始,所以位置的pointer为0;如果是纹理坐标,则它的pointer为12,因为从开始到纹理坐标有12字节的距离;法线的话为20。但事实上这些不用我们自己去计算,我们可以使用宏偏移量。
注意: 当要启用或禁用通用的顶点属性数组时,要调用glEnableVertexAttribArray()。这个函数只需要传入index就可以。通用顶点的索引绝对是启用或禁用的。

OpenGL是一个状态机,它不会去检查glVertexAttribPointer()是否被启用。也不会去检查它要是没启用会有什么关系。glEnableVertexAttribArray()在任何地方调用都可以,只要缓冲区已经绑定。
6. 在OpenGL中着色器的原理
当我们没有提供自己的着色器时,其实也可以画出图形。因为一些显卡驱动实际上会为你提供一个默认的着色器。但这会出现问题,就是有可能不同的显卡,会出现不一样的效果。
一个着色器基本上就是一个运行在你的显卡上的一个程序(代码)。而为什么我们一定要在代码能在显卡上运行呢?因为我们是在学图形编程,显卡在这方面发挥了重要作用。还有就是我们想要能够为显卡编程是因为我们希望能够告诉显卡该做什么,想要利用显卡的能力在屏幕上绘制图形。但这并不意味着我们所作的一切都得在显卡上做或必须以着色器的形式使用显卡,CPU在某些方面还是更快。有时我们更喜欢在CPU上去干一些事情,可能只是将结果数据发送给显卡,同时仍然在CPU上进行处理。
虽然话虽如此,但有些事情是不可否认的,图形编程只很多都与图形相关,显卡的速度要快得多。所以还是需要用到着色器。不仅仅在我们想要把东西从CPU上拿出来放到显卡上,从根本上,我们得给显卡编程,因为即使在画一个简单三角形的时候,还是需要能够告诉显卡如何画这个三角形,例如就像顶点在哪,是什么颜色,应该怎么画。我们需要去告诉显卡如何处理我们发送的数据。这就是着色器的本质。
两种比较常见的着色器:顶点着色器和片段着色器(也称为像素着色器),还有其他的曲面着色器、几何着色器、计算着色器等。
图形渲染管道的大概流程(假如我们是绘制一个三角形):
在CPU上写了一堆数据后向显卡发送了一些数据,绑定某些状态,之后我们会发出一个叫做DrawCall指令,就进入了着色器的阶段,处理DrawCall指令并在屏幕上绘制一些东西,就能看到一个三角形了。这个特定的过程基本上就是渲染管道。
我们如何在屏幕上从有数据到有结果的,当显卡开始绘制三角形是,着色器就派上用场了。
顶点着色器和片段着色器是顺着管道的两种不同的着色器类型。所以当我们真正发出DrawCall指令时,顶点着色器会被调用,然后就会调用片段着色器,然后我们就会在屏幕上看到结果。为了简单起见,这中间省略了很多东西,在顶点着色器调用之前有很多处理,在调用顶点和片段着色器之间也有很多处理以及在片段着色器和光栅化阶段之间也有很多处理。所以从发出DrawCall指令到顶点着色器,再到片段着色器,最终为了能在屏幕上看到像素。
那么顶点着色器干了什么,它会被我们试图渲染的每个顶点调用。例如,我们要画一个三角形的话,有三个顶点,这就意味着顶点着色器会被调用三次,每个顶点调用一次,并且顶点着色器的主要目的是告诉OpenGL,顶点在屏幕空间的什么位置,如果有必要,我们需要能够提供一些转换,以便OpenGL能把这些数字转换成屏幕坐标。
着色器只是一个程序,和实际的图形没有任何关系。顶点着色器会把我们在缓冲区中指定的顶点属性包含进去。所有的顶点着色器只是为了指定你想要的位置的方式,被用来解析数据从属性到下一阶段。延续上面简化的过程的话,下一个阶段是片段着色器(像素着色器
),片段着色器会为每个需要光栅化的像素运行一次。
例如,当我们画一个三角形的时候,我们指定的那三个顶点组成三角形,需要用实际的像素填充,这就是光栅化阶段做的事。并且片段着色器就是对三角形中需要填充的每个像素调用一次,并且片段着色器的主要目标是决定这个像素应该是什么颜色。
但有一个性能优化的问题,就是例如还是在这个三角形中,因为顶点只有三个,所以只会调用顶点着色器三次;而像素点的数量会取决于三角形的大小,如果三角形比较大,则像素点会比较多,而每个像素都会调用一次片段着色器。所以有时可以考虑一些事情在顶点着色器处理就好,不用去到片段着色器。片段着色器里的东西代价要高得多,因为片段着色器会为每个像素运行。不过话虽如此,有些东西显然需要像素计算,比如说光源,计算光源时每个像素都有一个颜色值,这个值是由很多东西决定的,例如光源、环境、纹理、提供给表面的材质等,这些一起来确定一个特定像素的正确颜色。
片段着色器的作用就是,精确到每个像素的颜色,根据一些输入,例如相机的位置在哪、所有的表面属性、环境属性等所有汇聚在一起,在片段着色器中确定单个像素的颜色。片段着色器是一个程序,运行来确定一个像素应该是什么颜色的。一旦片段着色器计算出结果,你的颜色基本上会出现在屏幕上。
总结:顶点着色器为每个顶点运行,决定了它们在屏幕上的位置。片段着色器为每个像素运行,决定了颜色输出。
OpenGL着色器中的一切都是基于状态机工作的,这意味着当你想画一个三角形时,需要把数据从CPU发给GPU,我们设置了所有的状态,启用着着色器,然后画出三角形。这就是OpenGL的工作方式。
#include<GL/glew.h>
#include <GLFW/glfw3.h>
#include<iostream>
int main(void)
{
GLFWwindow* window;
/* Initialize the library */
if (!glfwInit())
return -1;
/* Create a windowed mode window and its OpenGL context */
window = glfwCreateWindow(640, 480, "Hello World", NULL, NULL);
if (!window)
{
glfwTerminate();
return -1;
}
/* Make the window's context current */
//创建OpenGL的上下文
glfwMakeContextCurrent(window);
if (glewInit() != GLEW_OK)
std::cout << "Error!" << std::endl;
std::cout << glGetString(GL_VERSION) << std::endl;
float positions[6] = { //三个顶点画一个三角形
-0.5f, -0.5f,
0.0f, 0.5f,
0.5f, -0.5f
};
//在OpenGL中生成的所有东西都会被分配一个唯一的标识符,它只是一个整数。比如0、1、2。0通常是一个无效状态,但不都是。
//但基本上会得到一个数字,比如1、2、3等,这是实际对象的id,不管它是顶点缓冲区、顶点数组、着色器还是其他东西,都会得到一个整数来代表它。
//当想要使用这个对象时,就用这个数字
unsigned int buffer; //定义一个缓冲区,无符号int类型,用来存放缓冲区的地址
glGenBuffers(1, &buffer); //定义顶点缓冲区,然后指定要多少个缓冲区,因为我们只需要一个,所以输入 1,第二个参数需要一个无符号整型指针。因为这个函数的返回类型是 void,所以函数不返回生成的缓冲区id,我们要给它提供一个整数(指针)。函数会把id写入这个整数的内存,这就是为什么需要指针。
glBindBuffer(GL_ARRAY_BUFFER, buffer); //绑定缓冲区,第一个参数是目标,GL_ARRAY_BUFFER表示这是一个数组;第二个参数是我们要绑定的缓冲区
glBufferData(GL_ARRAY_BUFFER, 6 * sizeof(float), positions, GL_STATIC_DRAW); //第一个参数是target;第二个参数是指我们希望缓冲区多大或者数据有多大;
//以上从40行开始就是我们用来给OpenGL传数据的所有代码。然而,当我们给OpenGL数据时,我们并没有告诉它数据是什么。
//我们需要告诉OpenGL,我们的数据是怎么布局的,同时需要为缓冲区发出一个DrawCall指令。
//启用顶点属性数组
glEnableVertexAttribArray(0);
//告诉OpenGL,数据的内存布局
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, sizeof(float) * 2, 0);
/* Loop until the user closes the window */
while (!glfwWindowShouldClose(window)) //glfwWindowShouldClose函数在我们每次循环的开始前检查一次GLFW是否被要求退出,如果是的话该函数返回true然后游戏循环便结束了,之后为我们就可以关闭应用程序了。
{
/* Render here */
glClear(GL_COLOR_BUFFER_BIT);
//传统的OpenGL绘制一个三角形,只需要下列函数,通过指定三个顶点来画三角形
/*
glBegin(GL_TRIANGLES);
glVertex2f(-0.5f, -0.5f); //按住alt+shift
glVertex2f( 0.0f, 0.5f);
glVertex2f( 0.5f, -0.5f);
glEnd();
*/
//这个函数可以为缓冲区发出DrawCall指令,这是一个没有索引缓冲区时可以用的方法,因为我们没有索引缓冲区,所以用这个方法
//第一个参数指定绘制模式,指定什么图元;第二个参数用来指定使用的数组中的起始索引,从0开始,(-0.5f, -0.5f)这样算一个索引
//第三个参数是要渲染的索引的数量,因为是三角形,有三个顶点,所以是3个索引
glDrawArrays(GL_TRIANGLES, 0, 3);
//这是一个有索引缓冲区时使用的函数,第二个参数是指有多少个索引数据,第三个参数是indices,这个几乎不用,所以写NULL
//glDrawElements(GL_TRIANGLES,3,null)
/* Swap front and back buffers */
glfwSwapBuffers(window); //交换颜色缓冲
/* Poll for and process events */
glfwPollEvents(); //glfwPollEvents函数检查有没有触发什么事件(比如键盘输入、鼠标移动等),然后调用对应的回调函数(可以通过回调方法手动设置)。我们一般在游戏循环的开始调用事件处理函数。
}
glfwTerminate(); //释放glfw分配的内存
return 0;
}
7. 在OpenGL中写一个着色器
着色器可以来自不同地方的变体,可以从文件中读取它们,也可以从网上下载,作为二进制数据读入等多种方式,可以编译着色器。进入着色器编译阶段。
在这一节中,我们会为OpenGL提供一个字符串。归根结底,我们还是需要为OpenGL提供一个字符串,那就是你着色器的源码。
基本上,我们需要向OpenGL提供我们实际的着色器源码(文本),我们想让OpenGL编译这个程序,将顶点着色器和片段着色器链接到一个独立的着色器程序,然后返回一个唯一标识符给我们,这样我们就可以绑定这个着色器程序并使用它。
//创建着色器对象
static unsigned int CompileShader(unsigned int type, const std::string& source) {
//创建一个着色器对象
unsigned int id = glCreateShader(type);
const char* src = source.c_str();
//将着色器的源代码传递给指定的着色器对象
glShaderSource(id, 1, &src, nullptr);
//编译指定着色器对象中的源代码
glCompileShader(id);
//编译源代码不会返回任何数据。所以无法判断它是否出了问题
int result;
//获取着色器对象的特定参数值
glGetShaderiv(id, GL_COMPILE_STATUS, &result);
if (result == GL_FALSE) { //GL_FALSE等于0,表示失败
int length;
glGetShaderiv(id, GL_INFO_LOG_LENGTH, &length);
//要创建一个长度为length的数组,有两种方法
//在堆上动态分配(需要手动回收) char* messsage = new char[length];
//在栈上动态分配
char* message = (char*)alloca(length * sizeof(char));
glGetShaderInfoLog(id, length, &length, message);
std::cout << "编译"<<(type==GL_VERTEX_SHADER ? "vertex" : "fragment") << "着色器失败!" << std::endl;
std::cout << message << std::endl;
glDeleteShader(id);
return 0;
}
return id;
}
//不希望此函数链接到其他编译单元或c++文件,所以设置为静态函数
//将着色器的源码作为字符串传入。vertexShader接收顶点着色器的源码,fragmentShader接收片段着色器的源码
static unsigned int CreateShader(const std::string& vertexShader, const std::string& fragmentShader) {
//创建着色器程序对象并返回一个可用于引用的非0值的函数。
//着色器程序对象用于附加着色器对象,并提供机制将指定的着色器对象链接到创建的着色器程序。
unsigned int program = glCreateProgram(); //如果使用OpenGL规范,unsigned int应写成GLunit
//调用自己定义的函数创建顶点着色器对象
unsigned int vs = CompileShader(GL_VERTEX_SHADER, vertexShader);
//调用自己定义的函数创建片段着色器对象
unsigned int fs = CompileShader(GL_FRAGMENT_SHADER, fragmentShader);
//把这两个着色器附加到我们的程序上
glAttachShader(program, vs);
glAttachShader(program, fs);
//链接程序
glLinkProgram(program);
glValidateProgram(program);
//删除着色器,因为它们已经链接到一个program(程序)中,所以可以删除这些中间文件
glDeleteShader(vs);
glDeleteShader(fs);
return program;
}
使用如下:
//创建着色器
//在C++中,字符串之间的连接也可以不使用加号
std::string vertexShader =
"#version 330 core\n"
"\n"
"layout(location = 0) in vec4 position;" //layout(location) 限定符用于确保顶点数据与着色器中的变量正确对应,从而实现数据的正确传递和处理
"\n"
"void main()\n"
"{\n"
" gl_Position = position;\n"
"}\n";
std::string fragmentShader =
"#version 330 core\n"
"\n"
"layout(location = 0) out vec4 color;"
"\n"
"void main()\n"
"{\n"
" color = vec4(1.0,0.0,0.0,1.0);\n"
"}\n";
unsigned int shader = CreateShader(vertexShader, fragmentShader);
//绑定着色器
glUseProgram(shader);
8. 自己的总结
-
说OpenGL是一种图形API,是因为它提供了一组函数和规范用于描述和操作图形硬件。然而它本身并不是API,而是一种规范,这个规范定义了函数和操作的方式,以及它们应该如何工作。
-
使用GLEW的注意事项:
(1)首先需要创建一个有效的渲染OpenGL上下文,然后调用glewInit()去初始化扩展的入口。所以不能直接从GLEW中直接调用OpenGL函数,直到你调用了glewInit()。
(2)在调用glewInit()之前,需要先创建一个渲染OpenGL的上下文。
(3)当需要用到glew.h头文件时,要在包含任何其他OpenGL相关的头文件之间就要先包含glew.h。也就是glew.h要放在前面。
-
OpenGL管道的工作原理是我们为我们的显卡提供数据,我们在显卡上存储一些内存,它包含了我们想要绘制的所有数据,然后我们使用一个着色器,利用在显卡上执行的程序来读取数据并且完全显示在屏幕上。实际上,我们不得不告诉OpenGL,内存中有什么,又是如何布局的。如果我们不这样做,OpenGL看到的只是一堆字节。glVertexAttribPointer可以为我们做这件事,只有让OpenGL知道了我们的内存布局,它才知道怎么去正确地解析它。
-
着色器:
着色器是运行在GPU上的程序,可编程的有顶点着色器和片段着色器。顶点着色器是有多少个顶点就运行多少次,而片段着色器是有多少个像素就运行多少次。
顶点着色器(确定顶点的最终位置)中,一般以顶点位置、顶点法线、颜色、纹理坐标作为输入,具体的视具体情况而定。而一般以gl_Position作为输出,用于表示变换后的顶点位置。
片段着色器中(确定每个像素的颜色),一般以顶点属性(如位置、法线、纹理坐标等)和uniform变量作为输入。一般以像素颜色为输出。
-
关于有一个性能优化的问题:
就是例如还是在这个三角形中,因为顶点只有三个,所以只会调用顶点着色器三次;而像素点的数量会取决于三角形的大小,如果三角形比较大,则像素点会比较多,而每个像素都会调用一次片段着色器。所以有时可以考虑一些事情在顶点着色器处理就好,不用去到片段着色器。片段着色器里的东西代价要高得多,因为片段着色器会为每个像素运行。
-
完整的图形渲染管线流程:
(1)准备阶段:初始化glfw,设置窗口属性(glfwWindowHint())、创建窗口(glfwCreateWindow())、设置OpenGL渲染上下文、初始化glew和渲染之前告诉OpenGL渲染窗口的尺寸大小(glfwGetFramebuffersize()和glViewPort()),把顶点数据传递给顶点着色器;
(2)顶点着色器:把一个单独的顶点作为输入,确定每个顶点的位置。根据要求对每个顶点进行变换,例如平移、旋转、缩放等;
(3)图元装配:将顶点着色器输出的所有顶点作为输入,并将所有顶点装配成指定的图元形状。
(4)几何着色器:把图元形式的一系列顶点的集合作为输入,对图元进行下一步的变换和处理,例如生成新的顶点、改变图元形状等。
(5)光栅化:将图元映射为最终屏幕上相应的像素,生成供片段着色器使用的片段。
(6)片段着色器:计算每个像素的最终颜色,包括纹理、材质、光照等。
(7)Alpha测试和混合:这个阶段检测片段的对应的深度(和模板(Stencil))值,用它们来判断这个像素是其它物体的前面还是后面,决定是否应该丢弃。这个阶段也会检查alpha值(alpha值定义了一个物体的透明度)并对物体进行混合(Blend)。Alpha测试是指当不同物体重叠且在屏幕的不同深度时,会根据物体的深度和透明度对物体的不同显示或忽略。当两个物体一前一后时,前面物体又是透明的话,此时就会对它们进行混合。
-
纹理:
为了能够把纹理映射到图形上,我们需要指定图形的每个顶点各自对应纹理的哪个部分。这样每个顶点就会关联着一个纹理坐标,用来标明该从纹理图像的哪个部分采样(采集片段颜色)。之后在图像的其他片段上进行片段插值。纹理坐标在x和y轴上,范围为0到1之间(注意我们使用的是2D纹理图像)。使用纹理坐标获取纹理颜色叫做采样。它可以采用几种不同的插值方式,所以我们需要自己告诉OpenGL该怎样对纹理采样。
对于纹理,一定要指定这四个参数,过滤器(放大、缩小两个)和环绕方式(GL_TEXTURE_WRAP_S水平环绕、GL_TEXTURE_WRAP_T垂直环绕,有点像x和y轴),如果不指定,就会得到一个黑色的纹理,因为OpenGL有给它们默认值,默认情况下就是黑色。
-
在坐标变换中,通常会设定一个坐标范围,再在顶点着色器中将这些坐标变换为标准化设备坐标。然后将这些标准化设备坐标传入光栅器,将它们变换为屏幕上的二维坐标或像素。将坐标变换为标准化设备坐标,接着再转化为屏幕坐标的过程通常是分步进行的。过程通常是这样:
局部坐标(就是我们自己定义的坐标) —根据模型矩阵(由平移、旋转和缩放操作组成)—> 世界坐标 —根据观察矩阵(用于定义虚拟摄像机的位置和朝向,将场景从全局坐标系转换到摄像机的局部坐标系) —> 观察坐标 —根据投影矩阵(用于将三维场景中的物体坐标转换为二维屏幕坐标,实现透视效果和深度感)—> 裁剪坐标(经过裁剪和透视除法等操作,将坐标变换为标准化设备坐标的范围(-1.0,1.0)) —视口变换和垂直翻转—> 屏幕坐标。
以上状态是一个顶点在最终被转化为片段之前需要经历的。
-
摄像机:
当讨论摄像机/观察空间时,是在讨论一摄像机的视角作为场景远点所有顶点的坐标:观察矩阵把所有的世界坐标变换为相对于摄像机位置与方向的观察坐标。要定义一个摄像机,需要确定它在世界空间中的位置、观察的方向、一个指向它右侧的向量以及一个指向它上方的向量。摄像机位置简单来说就是世界空间中一个指向摄像机位置的向量。
-
颜色:
当在OpenGL中创建一个光源时,希望给光源一个颜色,利用颜色反射的定律,我们先将光源设置为白色。然后用光源的颜色与物体的颜色值相乘,所得到的就是这个物体所反射的颜色(也就是我们所感知到的颜色)。这里说的颜色都是一个向量。
-
光照:
在OpenGL中,当要使用光照时可以使用冯氏光照模型。该模型的主要结构由3个分量组成:环境、漫反射和镜面光照。环境光照分量会永远给物体一些颜色,不至于使物体完全黑暗;漫反射光照是为了模拟光源对物体方向性的影响,如物体的某部分越是正对着光源,它就越亮;镜面光照是为了模拟有光泽物体上面出现的亮点,它的颜色相比于物体颜色会更倾向于光的颜色。
-
材质:
当描述一个表面时,可以分别为三个光照分量(环境、漫反射和镜面)定义一个材质颜色。通过为每个分量指定一个颜色,我们就能够对表面的颜色输出有细粒度的控制。再添加一个反光度分量,结合上上述的三个颜色,就有了全部所需的材质属性了。ambient(环境)材质向量定义了在环境光照下这个表面反射的是什么颜色,通常与表面的颜色相同。diffuse(漫反射)材质向量定义了在漫反射光照下表面的颜色。漫反射颜色(和环境光照一样)也被设置为我们期望的物体颜色。specular(镜面)材质向量设置的是表面上镜面高光的颜色(或者甚至可能反映一个特定表面的颜色)。最后,shininess影响镜面高光的散射/半径。
材质是用于描述物体的外观和反射特性的属性集合。它定义了物体的颜色、光照响应以及其他与表面特性相关的属性。