范式
概念:设计数据库时,需要遵循的一些规范。要遵循后边的范式要求,必须遵循前边的所有范式要求
第一范式:
数据库表的每一列都是不可分割的基本数据项
这样子就不满足第一范式
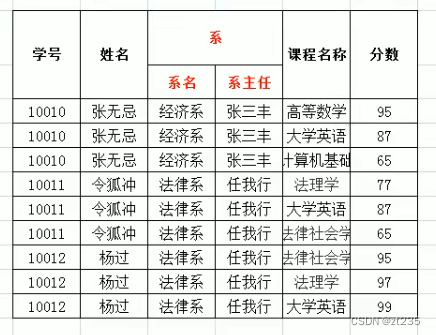
这样子就满足第一范式
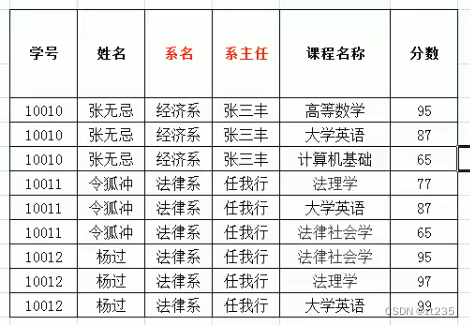
存在问题:
数据重复十分严重:姓名 系主任 系名
数据添加存在问题:添加新开设的系名和系主任时,数据不合法
数据删除存在问题:张无忌同学毕业了,删除数据时,会将系的数据一起删除掉
第二范式:
在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
函数依赖
1.函数依赖︰A-->B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A
例如:学号-->姓名。(学号,课程名称)-->分数
2.完全函数依赖∶A-->B,如果A是一个属性组,则B属性值得确定需要依赖于A属性组中所有的属性值。
例如∶(学号,课程名称)-->分数
3,部分函数依赖∶A-->B,如果A是一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。
例如:(学号,课程名称)-- >姓名
4.传递函数依赖:A-->B,B -- >c .如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性属性组)的值可以确定唯一C属性的值,则称c传递函数依赖于A
例如:学号-->系名,系名-->系主任
5,码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如:该表中码为:(学号,课程名称)
*主属性:码属性组中的所有属性
*非主属性:除过码属性组的属性
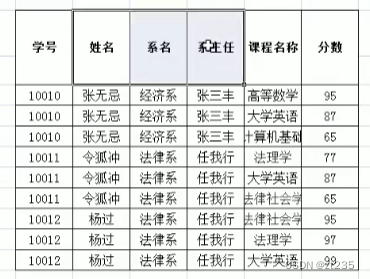
满足第二范式,需要消除部份依赖,就要把姓名 系名 系主任 拿出来
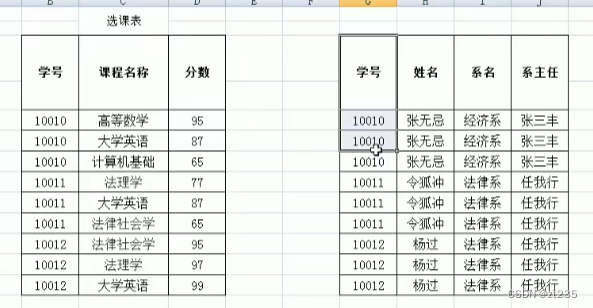
清除重复数据就可以满足第二范式
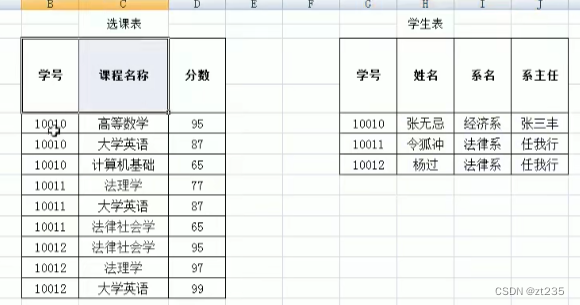
第二范式解决了数据重复十分严重的问题
第三范式:
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
在学生表有学号-->系名-->系主任 的传递依赖,那么就把系主任拿出来,消除传递依赖

解决了数据的删除问题和添加问题
事务
概念:如果一个包含多个步骤的业务操作,被事务管理,那么这次操作要么同时成功,要么同时失败
事务的四大特征:
1.原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败
2.持久性:当事务提交或回滚后,数据库会持久化的保存数据
3.隔离性:多个事务之间相互独立
4.一致性:事务操作前后,数据总量不变
eg:比如转账
张三给李四转账500
事务开启(start transaction)---剩下的语句一起成功
张三余额大于500
假如这一步出错了
回滚事务(rollback)---回到开启事务的时候
张三-500
李四+500
到这里成功了
提交事务(commit)---数据库改变
事务开启需要选中我们要进行的语句
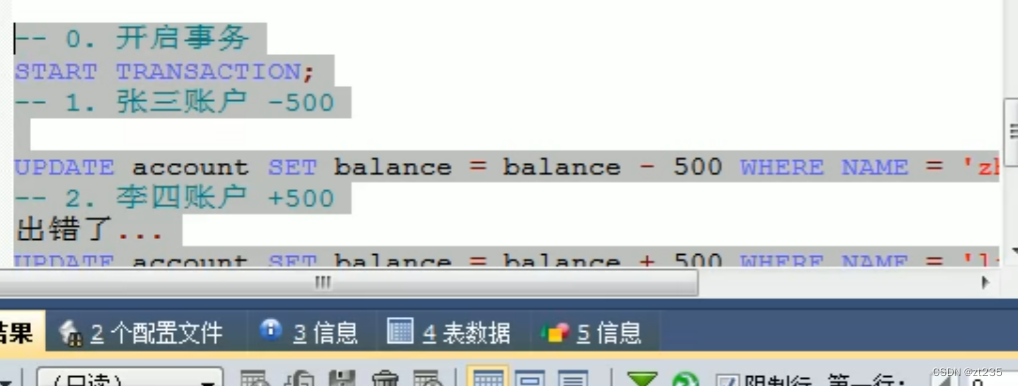
事务回滚只需要一条就ok
事务提交也是一条就ok
MySQL默认自动提交事务
自动提交:
- mysql就是自动提交的
- 一条dml语句会自动提交一次事务
手动提交:
- oracle数据库默认是手动提交事务
- 需要先开启事务再提交
修改默认提交方式:
查看:select @@autocommit;---- 1表示自动提交 0表示手动提交
修改:set @@autocommit = 0;
多表查询
内连接查询
1.确定从那些表中查询数据
2.条件是什么
3.查询那些字段
隐式内连接:(由where条件限定出来)
Select
表名.列名…(你想显示出来的列)
表名.*(就是表的所有)
From
Emp…(列名)(你想那几个表emp t1 就是给emp起别名)
Where
条件
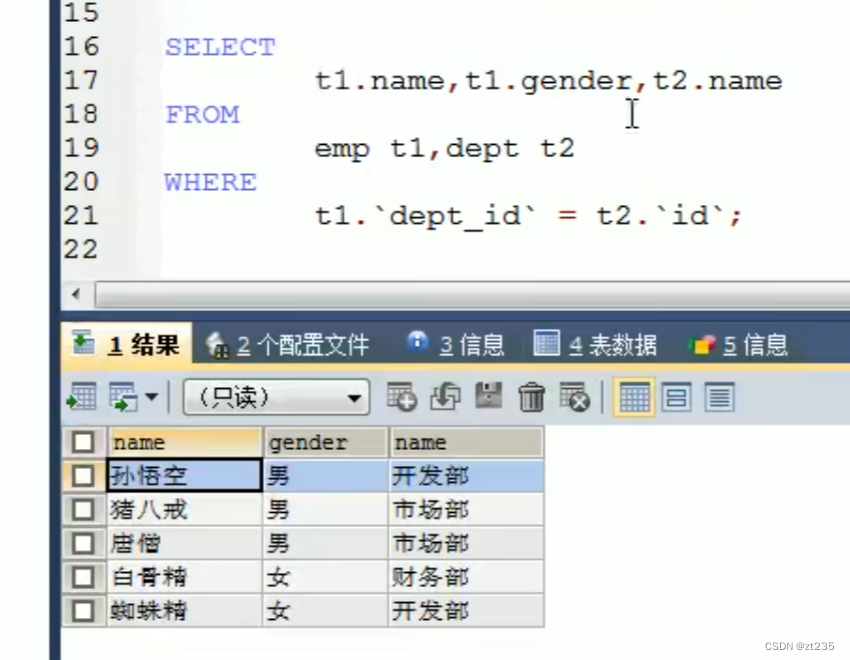
显式内连接:
语法:select 字段列表(列名 *就表示全出来) from 表名1 inner join 表名2 on 条件(加入的条件)
eg:(inner为可写可不写的操作)
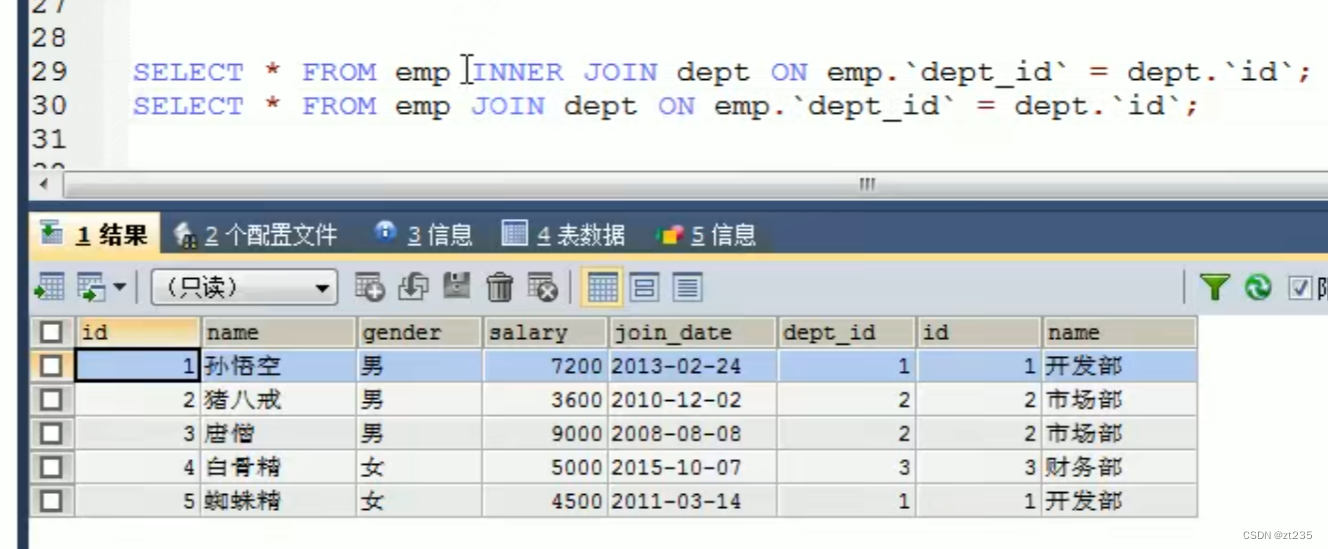
外连接查询
左外连接:
*语法: select 字段列表 from 表1 left [outer] join 表2 on 条件
就是查左表的所有信息和右表与其交集的部分
左表就是左边那个表1 右表就是表2
eg:左表

右表
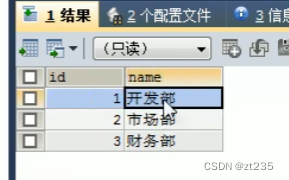
然后左外连接:

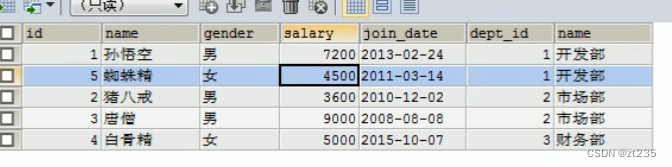
右外连接:
*语法: select 字段列表 from 表1 right [outer] join 表2 on 条件
就是查右表的所有信息和左表与其交集的部分
左表就是左边那个表1 右表就是表2
右外连接:
子查询
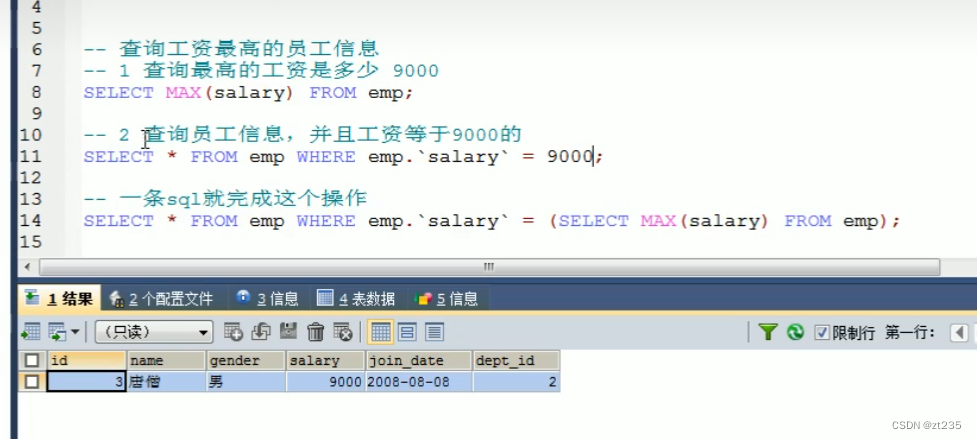
就是一条查询语句里面嵌套另一条查询语句
嵌套的那一条语句为子查询
查询中嵌套查询 称嵌套查询为子查询
子查询的不同情况(就是把语句给利用运算符给合一起去)
1.子查询的结果是单行单列的:
*子查询可以作为条件,使用运算符去判断
eg:
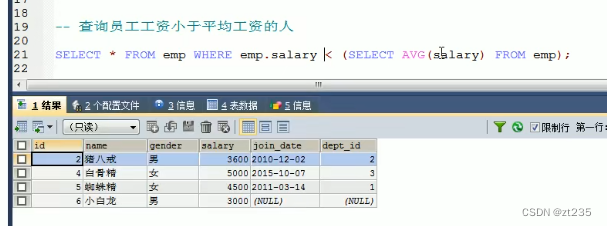
2.子查询的结果是多行单列的:
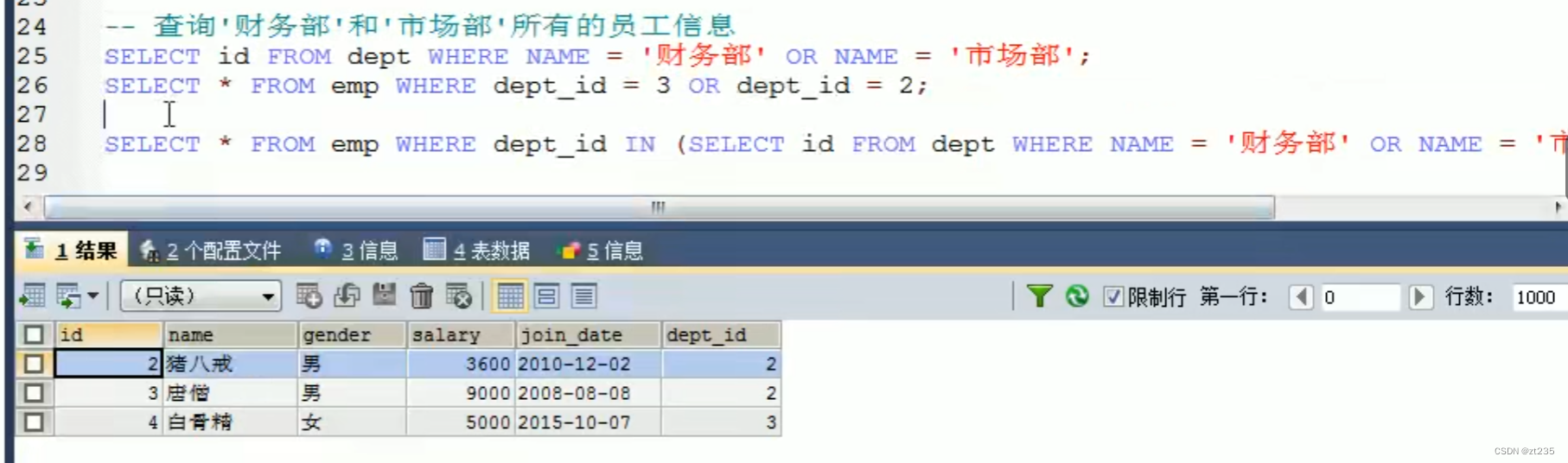
3.子查询的结果是多行多列的:
子查询可以作为一张虚拟表来进行查询
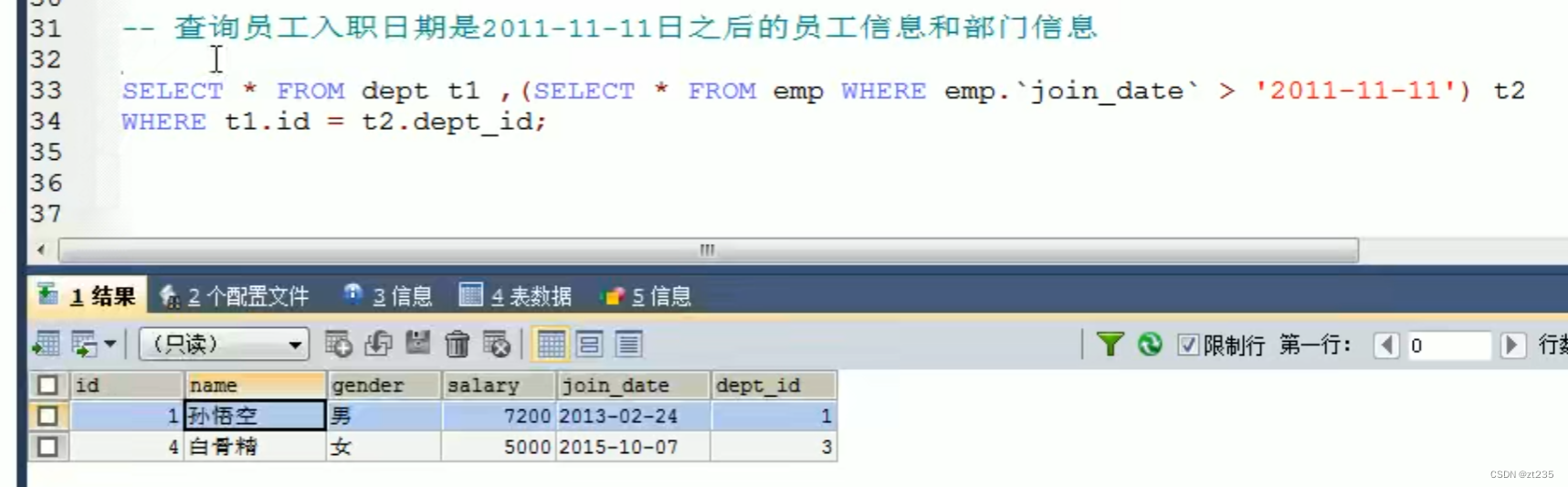
题目