目录
一:数据集准备
二:加载文件
三:查看DataFrame的头部和尾部数据 ,shape
四:统计摘要
五:获取数据
六:缺失值处理
一:数据集准备
可以新建txt,复制下面内容,并修改后缀为csv,放置于pycharm编辑器
搞笑镜头,拥抱镜头,打斗镜头,label
45,2,9,1
21,17,5,1
54,9,11,1
39,0,,1
5,2,57,2
3,2,65,2
6,4,21,2
7,46,4,3
9,39,8,3
9,38,17,3
2,3,55,2


二:加载文件
DataFrame数据结构 ,结果输出
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
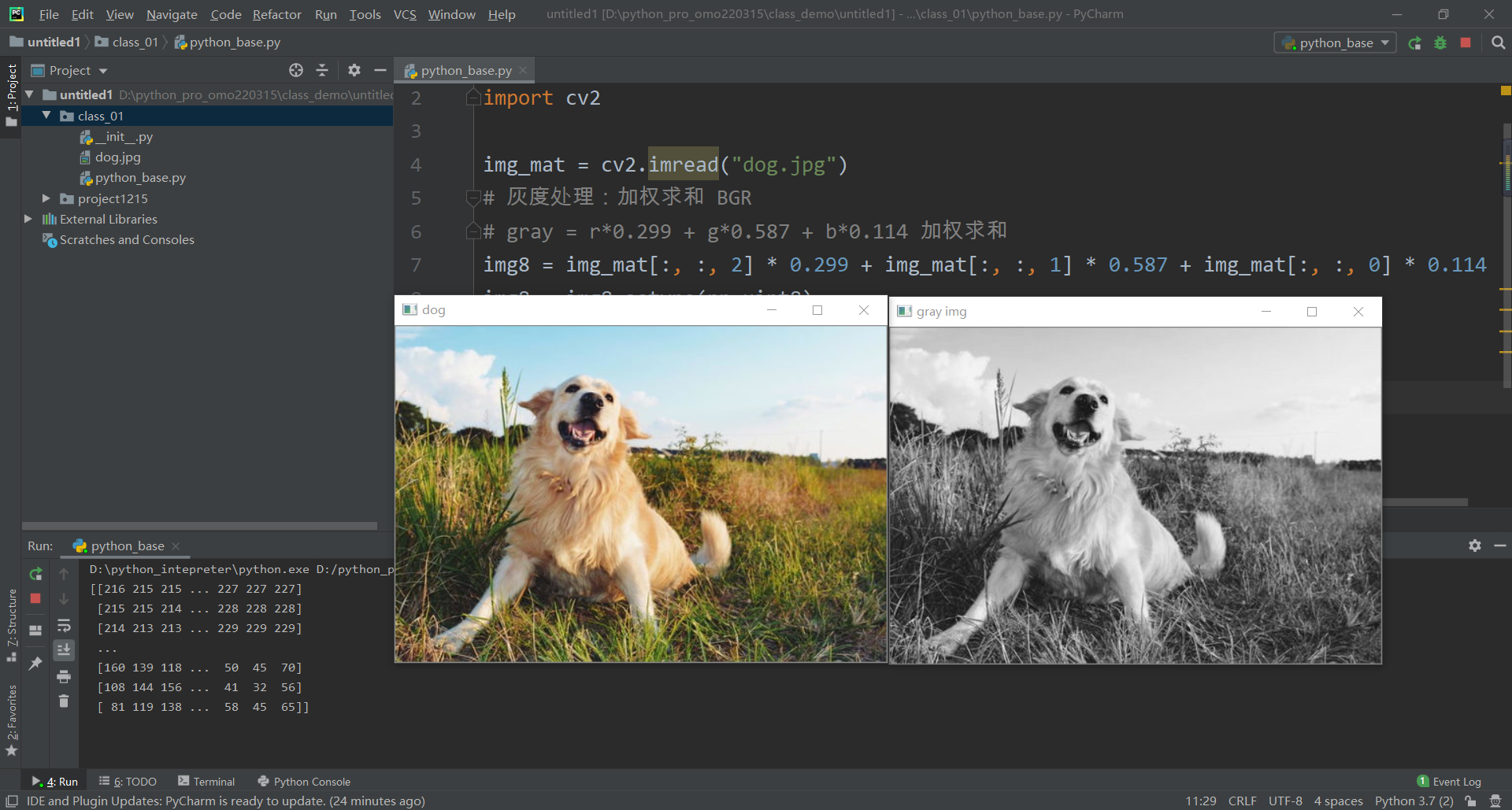
print(df, type(df))
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1
3 39 0 NaN 1
4 5 2 57.0 2
5 3 2 65.0 2
6 6 4 21.0 2
7 7 46 4.0 3
8 9 39 8.0 3
9 9 38 17.0 3
10 2 3 55.0 2 <class 'pandas.core.frame.DataFrame'>三:查看DataFrame的头部和尾部数据 ,shape
查看头部 head
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.head())
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1
3 39 0 NaN 1
4 5 2 57.0 2查看尾部 tail
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.tail())
a b c label
6 6 4 21.0 2
7 7 46 4.0 3
8 9 39 8.0 3
9 9 38 17.0 3
10 2 3 55.0 2shape,查看规格
如下输出结果为 11行 4列
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.shape)
(11, 4)四:统计摘要
求平均、最大、最小
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
print(df.describe())

a b c label
count 11.000000 11.000000 10.000000 11.000000
mean 18.181818 14.727273 25.200000 1.909091
std 18.845786 17.613012 24.003703 0.831209
min 2.000000 0.000000 4.000000 1.000000
25% 5.500000 2.000000 8.250000 1.000000
50% 9.000000 4.000000 14.000000 2.000000
75% 30.000000 27.500000 46.500000 2.500000
max 54.000000 46.000000 65.000000 3.000000五:获取数据
如下示例,获取第一列 列索引
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# print(df.describe())
print(df['a']) # 获取列 列索引--第一列
0 45
1 21
2 54
3 39
4 5
5 3
6 6
7 7
8 9
9 9
10 2
Name: a, dtype: int64如下示例,获取前三行 行切片
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# print(df.describe())
# print(df['a']) # 获取列 列索引--第一列
print(df[0:3]) # 获取行 行切片--前三行
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1获取某行
iloc[2]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# print(df.describe())
# print(df['a']) # 获取列 列索引--第一列
# print(df[0:3]) # 获取行 行切片--前三行
print(df.iloc[2]) # 获取行
a 54.0
b 9.0
c 11.0
label 1.0
Name: 2, dtype: float64获取前3行 前2列
iloc[:3,:2]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# print(df.describe())
# print(df['a']) # 获取列 列索引--第一列
# print(df[0:3]) # 获取行 行切片--前三行
# print(df.iloc[2]) # 获取行
print(df.iloc[:3, :2]) # 获取前3行前2列
通过列表索引项,获取数据
iloc[[2, 5, 6], [0, 3]]
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# print(df.describe())
print(df.iloc[[2, 5, 6], [0, 3]]) # 通过列表索引项
a label
2 54 1
5 3 2
6 6 2六:缺失值处理
具体要求
1.找到缺失值
2.进行填充
3.超过1/3数据没有填写,这一列数据不具有研究性意义,直接剔除
1.找到缺失值
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 找到缺失值
print(df.isnull().sum())
如下结果,c处存在有缺失值,已被找到
a 0
b 0
c 1
label 0
dtype: int642.进行填充
均值填充/中位数/众数
inplace = True 可以替换掉原来的数据
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 找到缺失值
# print(df.isnull().sum())
# 均值填充
df['c'].fillna(df.c.mean(), inplace=True)
print(df)
如下结果:缺失值已被均值填充
a b c label
0 45 2 9.0 1
1 21 17 5.0 1
2 54 9 11.0 1
3 39 0 25.2 1
4 5 2 57.0 2
5 3 2 65.0 2
6 6 4 21.0 2
7 7 46 4.0 3
8 9 39 8.0 3
9 9 38 17.0 3
10 2 3 55.0 23.超过1/3数据没有填写,这一列数据不具有研究性意义,直接剔除
行列选择 loc
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 找到缺失值
# print(df.isnull().sum())
# 均值填充
# df['c'].fillna(df.c.mean(), inplace=True)
# print(df)
# 不具有代表性数据,剔除
# 行列选择
print(df.loc[:, ['a', 'b']])
a b
0 45 2
1 21 17
2 54 9
3 39 0
4 5 2
5 3 2
6 6 4
7 7 46
8 9 39
9 9 38
10 2 3值选择 at
import numpy as np
import pandas as pd
# 列名
columns = ['a', 'b', 'c', 'label']
# 1 加载文件
df = pd.read_csv("classify.csv", sep=',', names=columns, header=0)
# 找到缺失值
# print(df.isnull().sum())
# 均值填充
# df['c'].fillna(df.c.mean(), inplace=True)
# print(df)
# 不具有代表性数据,剔除
# # 行列选择
# print(df.loc[:, ['a', 'b']])
# 值选择
print(df.at[1, 'b'])
输出值:17




![[C/C++/初学者]万年历(输入年份和月份,输出对应的日历表——数组)](https://img-blog.csdnimg.cn/4879cbf16c334d00a6bd9c72a8d5a000.png)





![[附源码]Nodejs计算机毕业设计基于的企业人事管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/c806708a8a8947c7a8c85932fce9c224.png)