摘要及声明
1:本文主要利用实际数据进行检验,从定量角度分析基金发行情况与股票市场之间的关系;
2:本文主要为理念的讲解,模型也是笔者自建,文中假设与观点是基于笔者对模型及数据的一孔之见,如果读者有更好的验证思路和算法设计欢迎随时联系;
3:本文主要数据通过万得数据库获取,模型实现基于R 4.3;
目录
1. 基金与市场间的联系
2. 历史统计
3. 相关性分析
4. 基金发行情况对后市的预测效力
5. 结论
6. 代码实现
6.1 数据统计
6.2 数据分析
1. 基金与市场间的联系
基金的发行往往有“好发不好做,好做不好发”的特征,简单来说就是基金发行火爆的时候,市场往往处于过热的高点,此时进入市场很容易高位站岗;而当新基金发行低迷的时候,往往市场处于底部位置,此时的性价比高,进入市场则胜率更大。为了验证这些说法,笔者通过Wind基金数据库获取所有净值类基金(包含已到期的基金)的发行时的规模、成立日期和投资类型。经过相关统计后笔者认为,基金发行有顺市场周期的特点,但依靠基金发行情况判断市场转折点是很难的。为了方便批量处理数据和可视化展示,笔者选择R语言进行分析,具体的代码讲解在文章第六部分。
2. 历史统计
由于获取了所有类型的基金(共18900支),下面先进行简单统计。图一可以看出,混合型基金以及债券型基金是历史上发行最多的两种产品,分别发行了7.33万亿和6.01万亿;接下来是纯股票型基金,历史一共发行了2.23万亿。结合图二可以知道,混合型基金中,偏股混合型基金是发行最多的,历史上一共发行了4.10万亿;债券型基金中,中长期纯债型基金是最多的,共发行3.54万亿。总的来看:1)我国公募基金在资产配置方面以股票和债券为主;2)相较于发达国家成熟市场,我国被动型的指数基金的发行是比较少的;3)另类型基金及FOF的发行量也相对比较少。
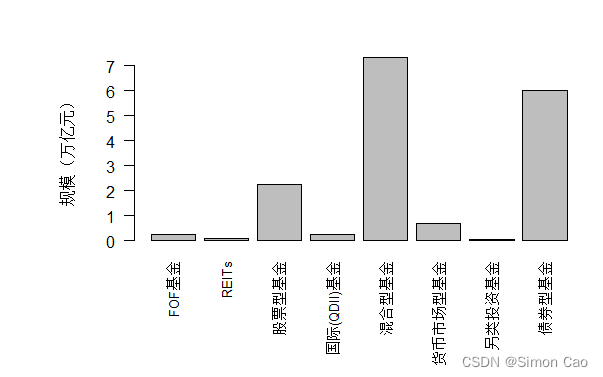
图一:万德一级投资类型基金历年发行总规模
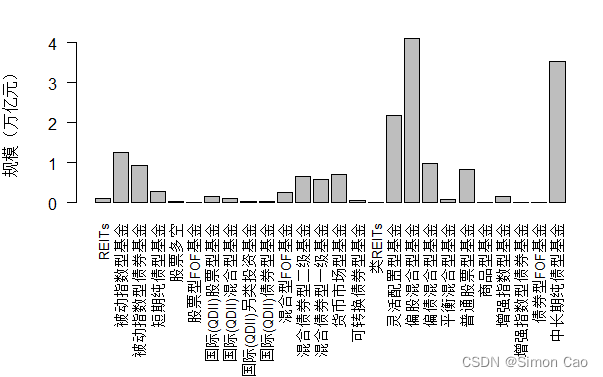
图二:万德二级投资类型基金历年发行总规模
本期文章是讨论基金市场与股票市场的关系,因此后面笔者着重分析股票型和偏股混合型基金的数据;一些灵活配置型基金由于底层资产难以界定,就排除在外不进行统计;还有其它类型的基金也不进行统计。
对股票型和偏股混合型基金发行时的规模(下文简称“新发基金规模”)进行月度数据加总并叠加沪深300净值走势可得图三:
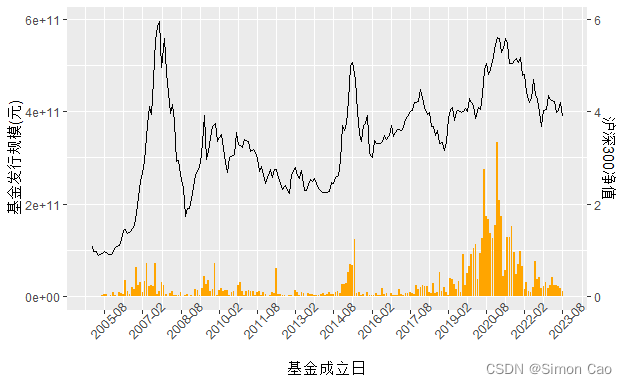
图三:月度新发基金规模及沪深300净值走势
从图三可以看出每当指数进入牛市时期,基金发行相对的都会出现高峰期。但是这个图没有考虑到市场的相对规模,例如2007年和2015都是基金相对高峰期,只是当时市场规模,上市公司数量以及通胀等因素限制,导致2020年的数据远远高于十几年前。因此,笔者选择用2002年9月的货币M2作为基期数(),进行基金规模的名义值(
,
为期数)调整计算得到实际值(
):
最后将指数净值走势再次叠加可得图四(注:由于2023年8月M2数据尚未公布,笔者沿用2023年7月M2作为8月数据进行计算):
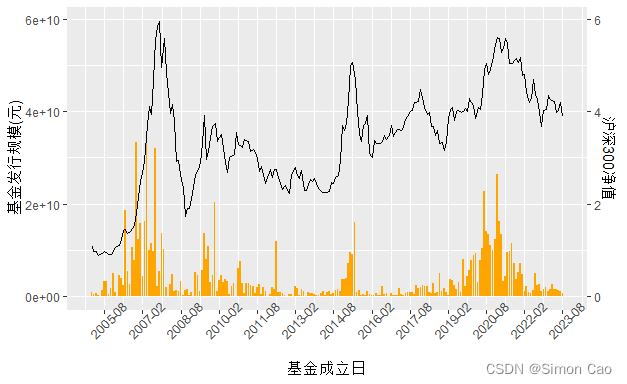
图四:月度新发基金规模(实际值)及沪深300净值走势
从图四不难发现,每当基金发行到达顶峰,后面市场基本都会走熊,例如2007年、2015年和2021年;而每当基金发行到达低谷,后面市场基本都会走牛,例如2008年底、2014年和2016年初。这也就是主流观点认为基金发行是反向指标的原因,但这只是大致从图上观察到的规律,具体是否存在数理关系还需要进一步量化论证。
3. 相关性分析
就图四来看,基金顶峰往往也是市场顶峰,基金低谷往往也是市场低谷期。两者的相关性究竟是怎样的,还需要进一步进行分析。由于指数的净值和基金发行规模都是绝对数,下面笔者利用Z分对数据进行标准化处理。从图五上看,基金规模数据是类似于log normal分布,因此后面计算时先对基金数据取log,转换为近似的正态分布,如图六:
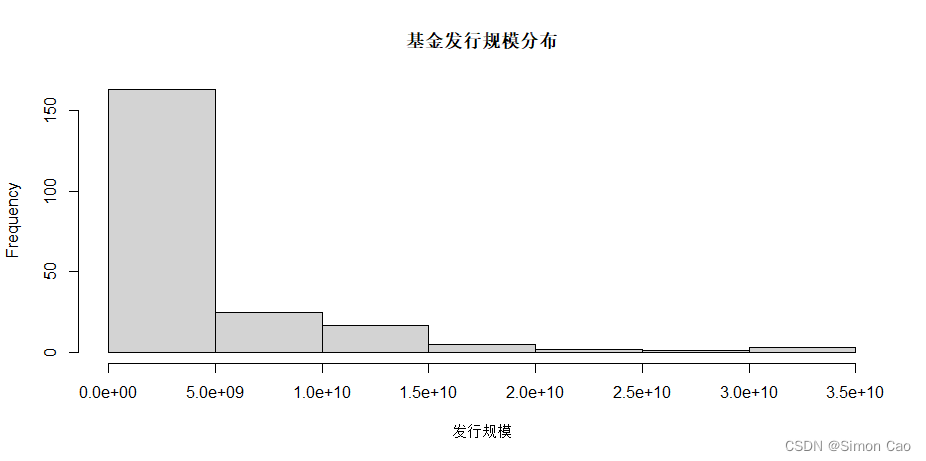
图五:基金发行规模数据分布
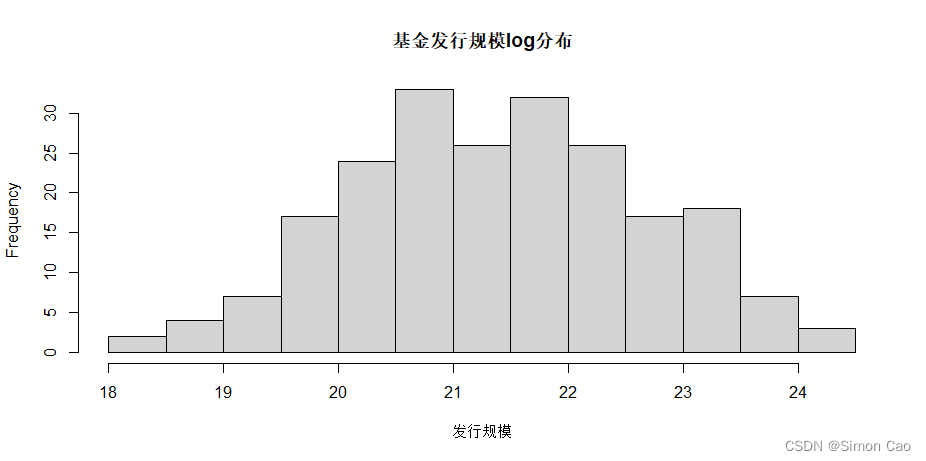
图六:基金发行规模数据对数分布
为避免前视偏差,不能一股脑将所有数据都拿来标准化。笔者采用24个月为移动窗口进行计算,已知时间序列,可以通过公式[1]计算出该时间序列
的Z分, 其中
和
分别为
的均值和标准差:
将净值与基金发行规模对数值标准化后可得图七,从图中相对0轴的分布就可以直观看出移动窗口期(2年)内数据所处于的相对高/低位:
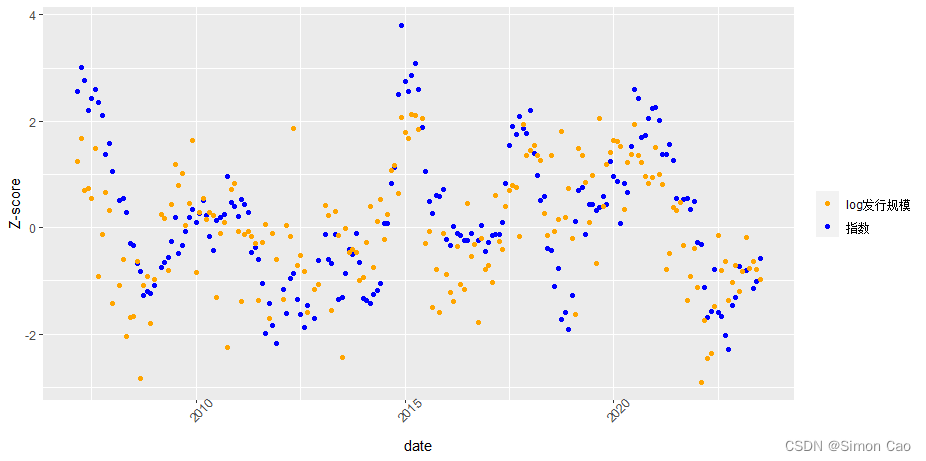
图七:沪深300指数净值与对数基金发行规模(实际值)的Z分时间序列分布
经过计算,两者相关系数为56.63%,对于金融数据来说这已经是很高的相关性了。这说明市场较好/较差时,基金发行情况也较好/较差,基金发行情况存在顺股票市场周期的特点。但其实相关性高只能证明市场好的时候基金发行情况也好,市场差的时候基金发行情况也差,并没有体现对后市的影响。
不过从图七其实可以大致看出,基金发行时而领先于指数(例如08年),时而同步于指数(例如14年行情启动时),时而滞后于指数(15年高点见顶)。
4. 基金发行情况对后市的预测效力
笔者采用n阶滞后回归的方式验证基金发行情况对后市的影响。设为基金的Z分,
为指数的Z分,依照公式[2]利用最小二乘法进行拟合(其中,
为滞后阶数):
拟合从0阶到36阶的回归结果,将模型参数、系数
和
的P值输出到图表上,得到图八:
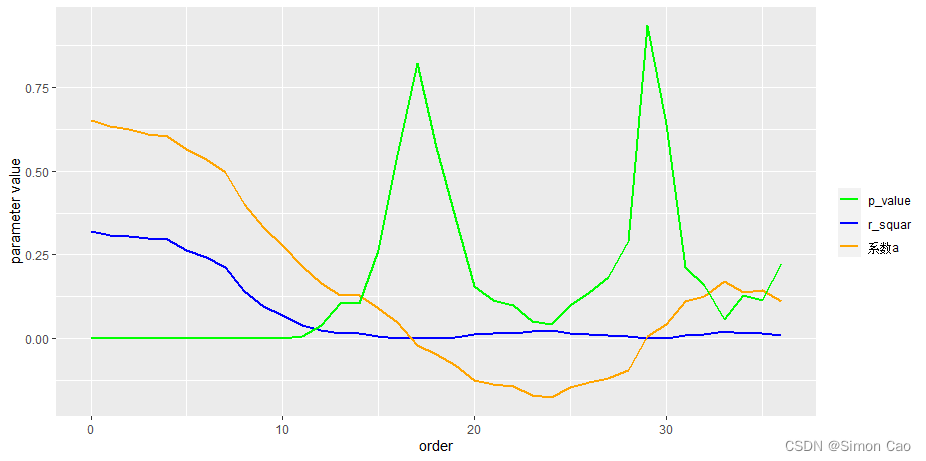
图八:模型[2]关键参数
从R方结果来看,0阶滞后项对
解释力度最强,随着滞后阶数上升解释力度逐渐趋近于0;系数a在0-23阶滞后项逐渐降低,之后则是逐渐上升的趋势,且18-28阶的数值为负;虽然P值有较大波动,但结合P值不难看出,基本只有0-10阶的系数是显著的。总结来看,即使观察到目前基金发行情况不佳,股票市场冷淡,那么即使是在未来3年内也很难说股票市场是否一定会出现反转。
当然,只验证基金对股票市场预测作用是不够的,下面分析股票市场是否对基金发行有影响,将[2]式中的滞后项反过来再次进行拟合:
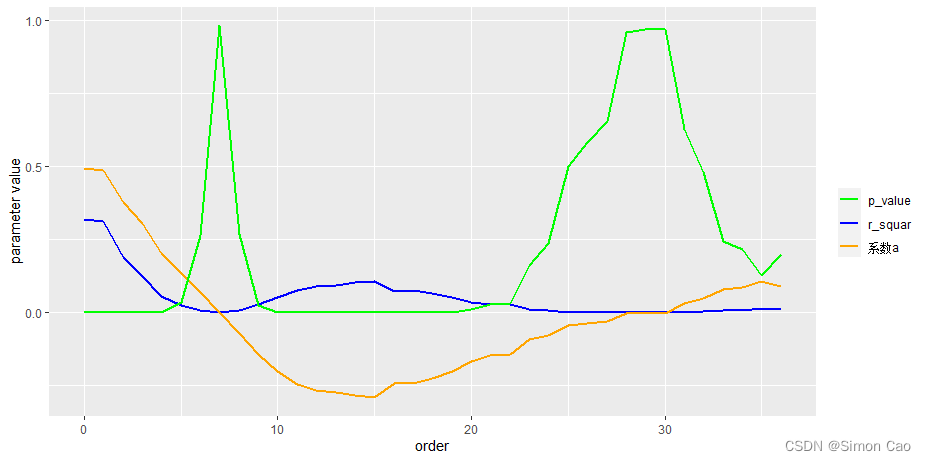
图九:模型[3]关键参数
图九参数有个很有意思的现象,滞后10-19期时,系数a为负值且拥有较高的显著度;滞后15期左右时,系数a最大且模型解释力度有一定提升。这说明市场位于高位时,未来15个月左右会有可能观察到基金发行较差;反之,市场位于低位时,未来15个月左右有可能会观察到基金发行较好。不过鉴于这个结论的解释力度较低(不到10%),笔者认为基金与指数间仅仅只是一种微弱的联系,并没有很强的指导意义。即使利用指数自身进行自回归,其表现也远强于利用基金数据进行预测的结果,如模型[4]:
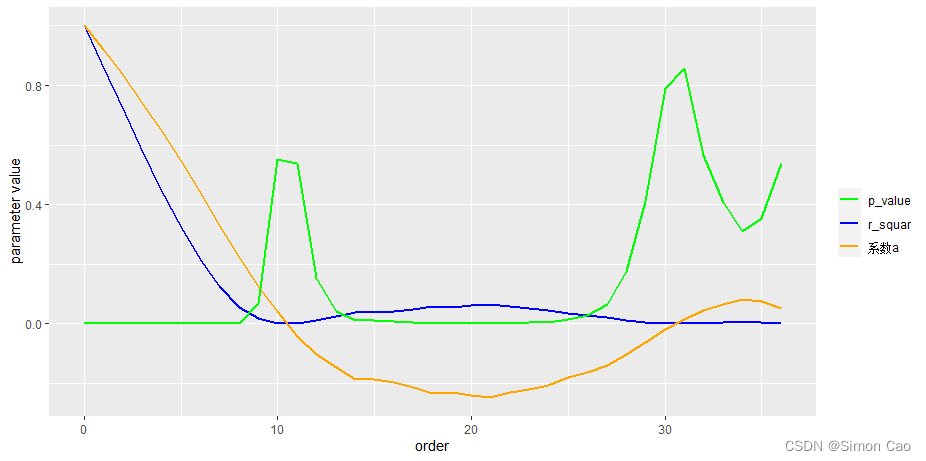
 图十:模型[4]关键参数
图十:模型[4]关键参数
5. 结论
基于回归分析结果,笔者认为基金发行状况对指数高低点的预测并无太大作用。基金发行情况存在顺股票市场周期的特点,基金低的时候并不意味着未来市场一定会涨。基金处于低位市场也同样处于低位,后期市场会不会涨完全取决于什么时候均值回归,而并非由基金处于低位驱动。本文有一定局限性,例如,没有考虑新发基金作为增量资金对市场的影响;只以沪深300作为代表性市场指数,没有考虑其它指数和结构化行情;最后,预测效力的验证只考虑了固定周期,而市场的周期时长往往是动态可变的,并不是固定的某个值。
6. 代码实现
实际上Wind是有基金发行情况统计功能的,但上面数据功能很简单,只能支持数据简单的导出和可视化。想要进行深入的分析最好的办法就是获取到历史上所有基金的发行数据自己做统计。代码所需要的数据笔者已经上传到资源中,有需要的可以通过笔者博客资源或这个链接下载:博客文章数据资源-CSDN文库
6.1 数据统计
首先导入需要的模块,设置工作路径:
library(readxl)
library(ggplot2)
library(dplyr)
setwd("C:/data") 将下载好的数据读取进R studio,运行后会展示出读取的表格和变量统计情况,目前一共拿到18900支基金数据:
df <- read_excel("发行情况.xlsx") # 公募基金发行规模数据
View(df)
summary(df)
证券代码 证券简称 发行规模 发行份额
Length:18900 Length:18900 Min. :0.000e+00 Min. :0.000e+00
Class :character Class :character 1st Qu.:9.552e+07 1st Qu.:8.949e+07
Mode :character Mode :character Median :2.660e+08 Median :2.608e+08
Mean :1.063e+09 Mean :1.033e+09
3rd Qu.:9.676e+08 3rd Qu.:9.253e+08
Max. :9.095e+10 Max. :9.095e+10
NA's :2963 NA's :2901
基金成立日 一级投资类型 二级投资类型
Min. :2001-09-21 00:00:00 Length:18900 Length:18900
1st Qu.:2017-07-04 06:00:00 Class :character Class :character
Median :2020-09-01 00:00:00 Mode :character Mode :character
Mean :2019-07-03 19:54:01
3rd Qu.:2022-01-25 00:00:00
Max. :2023-08-28 00:00:00
NA's :2 先进行变量分析,查看各种投资类型的基金数量到底是怎么样的:
# 一级投资类型
statis <- aggregate(发行规模~一级投资类型, data = df, FUN = sum) # 数据透视,聚合函数为求和
par(mar=c(7,7,3,1)) # 设置图表显示边距
barplot(height = statis$发行规模/1000000000000, names.arg = statis$一级投资类型, las=2,cex.names = 0.8,
ylab="规模(万亿元)") # 原始数据是元,转换一下单位
# 二级投资类型
statis <- aggregate(发行规模~二级投资类型, data = df, FUN = sum)
par(mar=c(9,4,2,1))
barplot(height = statis$发行规模/1000000000000, names.arg = statis$二级投资类型, las=2,cex.names = 0.8,
ylab="规模(万亿元)")运行后可得前文的图一和二。
接下来选中股票型和偏股混合型基金。因为基金发行是按日期进行统计的,因此需要对日期数据进行处理,方便利用聚合函数进行数据透视:
df <- df[(df$"一级投资类型" == "股票型基金")|(df$"二级投资类型" == "偏股混合型基金"), ]
df$基金成立日 <- format(df$基金成立日, "%Y%m") # 只保留年和月
# 将日期数据转换为Date类型,将日设置为每个月的1号,年和月保持不变
df$基金成立日 <- as.Date(paste0(df$基金成立日, "01"), format = "%Y%m%d")处理完成之后就可以在月频上对基金发行数据进行统计了,为了使数据更有可比性,笔者对名义规模进行货币量的调整,得到实际规模。进一步叠加指数走势,可视化即可得前文的图四:
statis <- aggregate(发行规模~基金成立日, data = df, FUN = sum) # 数据月度加总聚合
# 名义值调整
m2_table <- read_excel("M2数据.xlsx")
m2_table$日期 <- as.Date(m2_table$日期, format = "%Y%m%d")# 转换日期格式
m2_table <- as.data.frame(m2_table) # 转换表格格式
colnames(m2_table) <- c("基金成立日", "m2") # 设置列名,方便后面按合并数据表
m2_table$m2 <- m2_table[m2_table$基金成立日=="2002-09-01", "m2"] / m2_table$m2 # M2基期数/当期M2
fund_volum <- merge(statis, m2_table) # 合并表格
fund_volum$发行规模 <- fund_volum$发行规模 * fund_volum$m2 # 乘以货币增速调整因子,计算实际规模
# 叠加指数
index <- read_excel("000300_月线数据.xls")
index <- as.data.frame(index)
index$date <- format(index$date, "%Y%m")
index$date <- as.Date(paste0(index$date, "01"), format="%Y%m%d")
index <- index[, c("date", "涨跌幅")]
row.names(index) <- index$date
index$nav <- cumprod(index$涨跌幅/100+1) # 计算净值
colnames(index) <- c("基金成立日", "指数涨跌幅", "nav")
fund_volum <- merge(fund_volum, index)
# 可视化
ggplot() +
geom_bar(data = fund_volum, aes(x = 基金成立日, y = 发行规模),stat = "identity", fill = "orange") +
geom_line(data = fund_volum, aes(x = 基金成立日, y = nav*10^10))+
scale_y_continuous(name = "基金规模(元)",sec.axis = sec_axis(trans=~./10^10, name="指数涨跌幅"))+ # 设置副轴标尺
scale_x_date(date_labels = "%Y-%m", date_breaks = "18 month") +
theme(axis.text.x = element_text(angle = 45, vjust = 1))6.2 数据分析
下面是数据分析部分,因为后面需要计算Z分,先查看发行规模及净值分布,运行得到图五及图六。净值数据不做任何处理:
hist(fund_volum$发行规模, xlab = "发行规模", main = "基金发行规模分布") # 图五
hist(fund_volum$nav, xlab = "nav", main = "指数净值分布")
fund_volum$发行规模 <- log(fund_volum$发行规模)
hist(fund_volum$发行规模, xlab = "发行规模", main = "基金发行规模log分布") # 图六下面利用移动窗口计算Z值并存入数据表:
# 移动窗口计算
fund_z_lst <- c()
nav_z_lst <- c()
for (i in 36:nrow(fund_volum)){
fund_v <- fund_volum$发行规模[i]
fund_mu <- mean(fund_volum$发行规模[(i-36):i])
fund_std <- sd(fund_volum$发行规模[(i-36):i])
fund_z <- (fund_v - fund_mu) / fund_std
fund_z_lst <- c(fund_z_lst, fund_z)
nav_v <- fund_volum$nav[i]
nav_mu <- mean(fund_volum$nav[(i-36):i])
nav_std <- sd(fund_volum$nav[(i-36):i])
nav_z <- (nav_v - nav_mu) / nav_std
nav_z_lst <- c(nav_z_lst, nav_z)
}
# 数据汇总
z_data <- data.frame(date = fund_volum$基金成立日[36:nrow(fund_volum)], nav_z = nav_z_lst, fund_z = fund_z_lst)
# 可视化
ggplot(data = z_data, aes(x = date)) +
geom_line(aes(y = nav_z, color = "指数"), linewidth = 1) +
geom_line(aes(y = fund_z, color="log发行规模"), linewidth = 1) +
scale_color_manual(values = c("指数" = "blue", "log发行规模" = "orange")) +
labs(x = "date", y = "Z-score", color = "") +
theme(axis.text.x = element_text(angle = 45, vjust = 1))
rho <- cov(z_data$nav_z, z_data$fund_z)/(sd(z_data$nav_z)*sd(z_data$fund_z))
print(c("相关性", rho)) # 查看二者相关系数利用回归模型拟合,将模型参数存进表格并可视化。因为要计算多阶滞后项,写个循环保存每次生成的参数。下面注释掉的两行代码分别对应公式[3]和[4],只要去掉注释,运行相关公式即可生成图八、图九和图十:
r_squar <- c() # R方
p_value <- c() # 系数P值
coe <- c() # 斜率系数
for (i in 0:36){
z_data$fund_z_lag <- lag(z_data$fund_z, i) # 创建滞后项
z_data$nav_z_lag <- lag(z_data$nav_z, i) # 创建滞后项
model <- lm(formula=nav_z~fund_z_lag, data=z_data) # 公式[2] 基金为自变量,指数净值作为因变量
# model <- lm(formula=fund_z~nav_z_lag, data=z_data) # 公式[3] 指数净值为自变量,基金作为因变量
# model <- lm(formula=nav_z~nav_z_lag, data=z_data) # 公式[4] 指数自回归
model_result <- summary(model) # 保存模型参数
r_squar <- c(r_squar, model_result$r.squared)
coe <- c(coe, model_result$coefficients[2,1])
p_value <- c(p_value, model_result$coefficients[2,4])
}
para <- data.frame(lag = c(0:36), r_squar = r_squar, p_value = p_value, coe = coe) # 生成参数表
# 可视化
ggplot(aes(x = lag), data= para)+
geom_line(aes(y = r_squar, color="r_squar"), size=1)+
geom_line(aes(y = coe, color="系数a"), size=1)+
geom_line(aes(y = p_value, color="p_value"), size=1)+
scale_color_manual(values = c("r_squar" = "blue", "系数a" = "orange", "p_value" = "green")) +
labs(x = "order", y = "parameter value", color="")7. 往期精选
| 往期精选 | ||
| 系列 | 文章传送门 | 实现方式 |
| 金融杂谈 | 券商金股哪家强——信息比率 | Python |
| 从指数构建原理看待A股的三千点魔咒 | Python | |
| 决策树学习基金持仓并识别公司风格类型 | R | |
| 垃圾公司对回报率计算的影响几何 | Python | |
| 市场预测美联储加息的有效性几何 | Python | |
| 基于均值方差最优化资产配置的模型特性 | Python | |
| 金融危机模拟 | Python | |