目录
- 说明
- 常见的内存错误举例
- 常见的内存访问错误有以下几种:
- 内存问题定位步骤
- 野指针
- 内存释放后使用(UaF,Use after Free)
- 内存问题检查工具
- 常见的内存问题检查工具
- Valgrind
- gcc 命令行参数 -fsanitize=address -fno-omit-frame-pointer
- mprotect 或 gdb 内存断点(注意Linux地址空间随机化)
- 总结和经验
- 内存定位工具使用经验
- 多线程编程经验
说明
用gdb配合内核转储文件coredump瞬间定位段错误这是最基本的C/C++程序内存错误的定位方法。简单的coredump问题一般都是普通的内存访问错误,通过这个方法都很容易定位到相关的代码bug并修复。
但是在具体实践中,往往会有一些复杂的内存访问错误,尤其是多线程环境下的C/C++程序。因为其内存的分配、释放与访问经常会牵扯到多个线程,容易引入复杂而难以定位的内存错误,导致程序在执行过程中错误的访问内存而被操作系统结束掉。
本文介绍一些常见的内存错误和调试的步骤和方法,以及一些多线程程序避免内存问题的实践经验。
常见的内存错误举例
C/C++程序被称之为系统编程语言,往往编译成操作系统直接支持的可执行文件格式。C/C++语言本身没有垃圾回收机制,内存的动态分配与释放需要程序自行控制,对内存的访问也没有语言级别的校验和保护。出现内存访问错误后,进程多半会直接被操作系统结束掉。少部分情况因为访存地址合法,会对数据造成破坏(悬垂指针或者野指针),一般会在运行一段时间后才因为异常退出。这时候触发错误导致进程退出的代码位置往往不是”案发的第一现场“,给调试工作带来了更大的难度。
常见的内存访问错误有以下几种:
-
写内存越界(MO,Memory Overrun)
-
读写非法内存,本质上也属于内存越界(IMR / IMW, Invalid Memory Read / Invalid Memory Write)
-
栈溢出,也属于内存越界的一种(SO,Stack Overflow)
-
访问未初始化内存(AUM,Access Uninitialized Memory)
-
释放内存的参数为非法值(Wild Free)
-
内存释放两次(DF,Double Free)
-
函数访问指向被调用函数的栈内内存的指针(UaR,Use after Return)
-
内存释放后使用(UaF,Use after Free)
-
内存泄露(ML,Memory Leak)
上面这些都是一些抽象程度比较高的错误描述,具体到C/C++语言上面,会有更具体的错误,例如: -
读取未初始化过的变量
-
野指针/悬垂指针读写
-
错误的指针类型转换
-
从已分配内存块的尾部进行读/写(数组等类型读写越界)
-
不匹配地使用 malloc/new/new[] 和 free/delete/delete[]
内存问题定位步骤
问题重现
第一步是问题重现。只要是可以稳定重现的bug都是很好解决的。开启Linux coredump,如果能稳定重现几次问题的话,就可以转到第二步了。如果是难以重现的bug,就要想办法模拟现场来制造coredump了。譬如完整的回归测试,完整的压力测试往往都是有效的。
如果测试case并没有覆盖到可以重现出问题的场景,或者是诸如线下没问题,线上必coredump的情况,可以在线上进行模拟。模拟方法通常都是搭建测试环境,使用tcpcopy等工具在线上引流到测试机器进行压测,如果常规流量达不到重现标准,可以对流量进行放大。若线上搭建环境测试有困难,可以对线上流量抓包,然后在线下重放(tcpdump、tcpreplay和tcprewrite等工具)。
这一步之后,一般情况下都能增大重现的概率。如果还难以重现,往往都是一些代码本身的竞态条件(Race Condition)造成的,一般需要在引流测试的同时对CPU或者IO加压,以增大资源竞争的概率来增加问题复现的概率。甚至有些问题是出现网络抖动等情况下,需要模拟弱网络的环境(Linux 2.6内核以上有netem模块,可以模拟低带宽、传输延迟、丢包等情况,使用tc这个工具就可以设置netem的工作模式)。
至此,我们认为问题可以较容易复现且收集了足够多的coredump样本了。
gdb + coredump文件 + code review
有了足够多的样本后,就是gdb载入观察了,常用的命令有查看调用栈的bt,查看线程、局部变量、寄存器等信息的info等,使用bt打出调用栈后,f [n]切换到相应的调用层查看变量的值。配合代码review就能解决绝大多数普通的内存问题。如果说触发coredump的位置已经不是”案发的第一现场“,就需要用print和x等命令查看触发内存错误的指针值以及指针所在内存区域前后若干范围的值,往往会留下”杀手“代码的一些蛛丝马迹。此时的可能性一般有以下几种:
野指针
指针所在内存被其他代码非法修改(越界或者其他野指针误伤)
释放内存的参数为非法值(Wild Free),也可能是上一条原因导致
悬垂指针
内存释放后使用(UaF,Use after Free)
内存释放两次(DF,Double Free),第二次释放导致coredump
这类问题一般较难定位,尤其是野指针,某次内存的越界读写可能要在很久之后才会暴露出来。一般的调查手段难以奏效,需要上一些内存检查工具来辅助查找问题。
内存问题检查工具
C/C++代码的内存访问检查工具有很多,从非代码侵入式的工具到需要重新编译源程序的工具库都有。每个工具都有自己的一些检查的侧重点,不同的情况要选择不同的工具。如果难以判断问题来源,可以用的工具逐个尝试也是一种办法。后文中会逐一解读这些内存检查工具,并给出使用的方法和测试demo程序。
二分法 + code review
如果以上的方法都难以奏效的话,就只有最原始的方法了,在历史提交里通过二分法定位出问题提交,逐行进行代码review分析,推测所有的关联数据结构和多线程可能造成的静态条件。这是最后的方法了,把开发们全部关到小黑屋里,结合收集的coredump文件,画出数据结构关联图,专心解决问题。
常见的内存问题检查工具
glibc MALLOC_CHECK_
较新版本的glibc本身(其实准确讲glibc的内存分配的部分叫PtMalloc,本文用glibc指代PtMalloc)就有一些简单的内存检查或者保护的机制,环境变量里定义了MALLOC_CHECK_检查宏的情况下对一些诸如 double free 的问题都能直接识别定位出来。支持的值有:
0 - 不产生错误信息,也不中止这个程序
1 - 产生错误信息,但是不中止这个程序
2 - 不产生错误信息,但是中止这个程序
3 - 产生错误信息,并中止这个程序
在我的机器上默认并没有设置这个环境变量,但是默认的行为是配置3的行为。下面举几个例子,比如这样的代码:
#include <stdlib.h>
int main() {
char *buffer = malloc(20);
free(buffer);
free(buffer);
return 0;
}
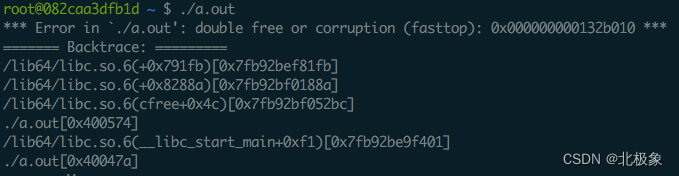
执行后直接崩溃并提示 double free or corruption 的错误:
另外释放无效的指针也会有相应的错误,例如下面的代码:
#include <stdlib.h>
int main() {
char *buffer = malloc(20);
free(buffer+2);
return 0;
}
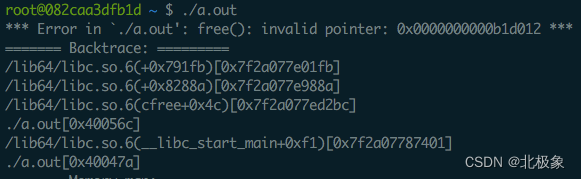
执行后崩溃并提示 free(): invalid pointer 的错误:
原理想来也很简单,实际上malloc(3)分配的内存会比用户实际申请的长度大一点,在返回给用户代码的指针位置的前面有一个固定大小的结构,放置着该块内存的长度、属性和管理的数据结构。试想调用free(3)的时候,并没有传入指针的长度,因为内存的长度记录在这个前置的管理结构里。那么只要在这个结构里放置一个校验的字段,标识出这块内存的状态是未分配,已分配还是已经释放。在调用free(3)的时候,回退指定的长度来检查这个字段,就能识别出double free或者invalid point等错误了。如果很巧合的是,释放的错误指针前面的数据正好满足这个校验,就会导致glibc错误的执行释放,导致glibc管理内存的结果破坏掉。理想的结果是就地崩溃,否则执行下去,崩溃的位置就不可预计了。
但是对于申请内存的越界访问,比如如下的代码就无能为力了。
#include <stdlib.h>
int main() {
char *buffer = malloc(20);
buffer[20] = 'a';
free(buffer);
return 0;
}
对于这种内存的访问错误,可以使用下面的工具。
Electric Fence(LD_PRELOAD=/usr/lib64/libefence.so)
Electric Fence 是一个内存调试库,原理是采用Linux的虚拟内存机制来保护动态分配的内存,在申请的内存的位置放置只读的哨兵页,在程序越界读写时直接coredump退出。具体信息可以参考维基百科的介绍:Electric Fence.
使用的方式很简单,直接在编译的命令行添加-lefence来链接该库即可(红帽系的Linux用yum安装ElectricFence库即可)。或者可以利用Linux动态链接库的PRELOAD机制来使用LD_PRELOAD宏来预先载入libefence.so进行内存保护。
执行刚才程序的结果如下:

运行后产生了core文件,gdb载入看看:

这样就检测出更多的内存访问错误了。
Electric Fence 的缺点也很明显,因为对内存做保护使用了mprotect(2)等API,这个API对内存设置只读等属性要求内存页必须是4K对齐的(本质上是Intel CPU的页属性设置的要求),所以内存使用率较低的程序可以用该库进行检查,但是内存使用率很高的程序在使用过程中会造成内存暴涨而不可用。另外实践中发现,使用该库后程序性能下降极其厉害,说百倍都不夸张,所以可用性不是很高。但是检查一些简单程序的内存访问还是很易用的。
Dmalloc
Dmalloc 类似Electric Fence,支持十多种操作系统,相比Electric Fence在性能上有较大提高。但是使用的话要求包含库的头文件后重新编译程序,略有点不便。其官方网站上有详细的功能说明和文档,本文就不照搬了。
Valgrind
Valgrind 是一套Linux下的仿真调试工具的集合。Valgrind 由内核以及基于内核的其他调试工具组成。内核类似于一个框架。它模拟了一个CPU环境,并提供服务给其他工具。而其他工具则类似于插件,利用内核提供的服务完成各种特定的内存调试任务。
Valgrind包括如下一些工具:
Memcheck:这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。
Callgrind:它主要用来检查程序中函数调用过程中出现的问题。
Cachegrind:它主要用来检查程序中缓存使用出现的问题。
Helgrind:它主要用来检查多线程程序中出现的竞争问题。
Massif:它主要用来检查程序中堆栈使用中出现的问题。
Extension:可以利用core提供的功能,自己编写特定的内存调试工具。
这里只举一个使用的例子。将上文的代码修改为:
#include <stdio.h>
#include <stdlib.h>
int main() {
char *buffer = malloc(20);
buffer[22] = 'a';
return 0;
}
Valgrind检查不需要重新编译程序,直接载入运行。结果如下:
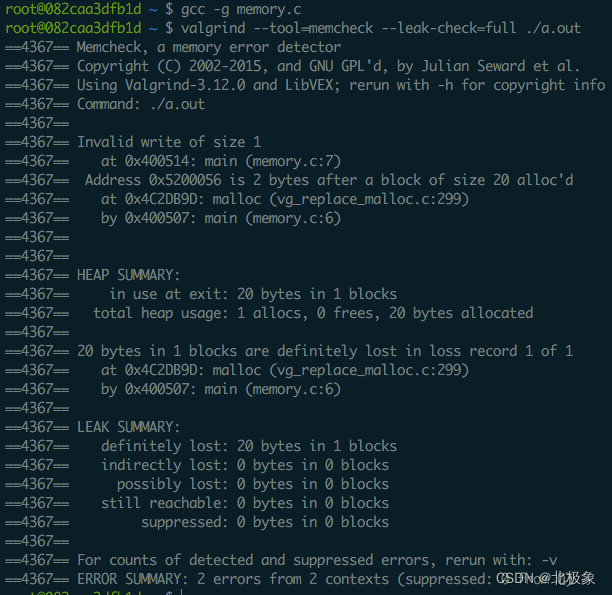
运行结果指出了代码第7行有1个越界的写,最后退出的时候有20 bytes的内存没有释放掉,这块内存是在代码第6行申请的(内存泄露)。Valgrind对程序运行的效率也有一些影响,但是实测比 Electric Fence 要强很多。
关于Valgrind的文章实在是太多了,本文重复一遍也没什么意义。所以Valgrind的使用参考官方文档或者网上的教程即可,本文不再赘述。
gcc 命令行参数 -fsanitize=address -fno-omit-frame-pointer
新版本的gcc(gcc49)提供了很好的内存访问检查机制,实践中发现对性能的影响居然比Valgrind小很多。在实践中 Electric Fence 和 Valgrind 严重影响了程序的性能,难以触发内存访问问题,而gcc的-fsanitize=address编译参数解决了大问题,唯一的缺点是gcc高版本才支持,而实践中,生成环境的代码都是老版本编译器编译的。
闲话不表,重新编译和运行程序,结果如下:
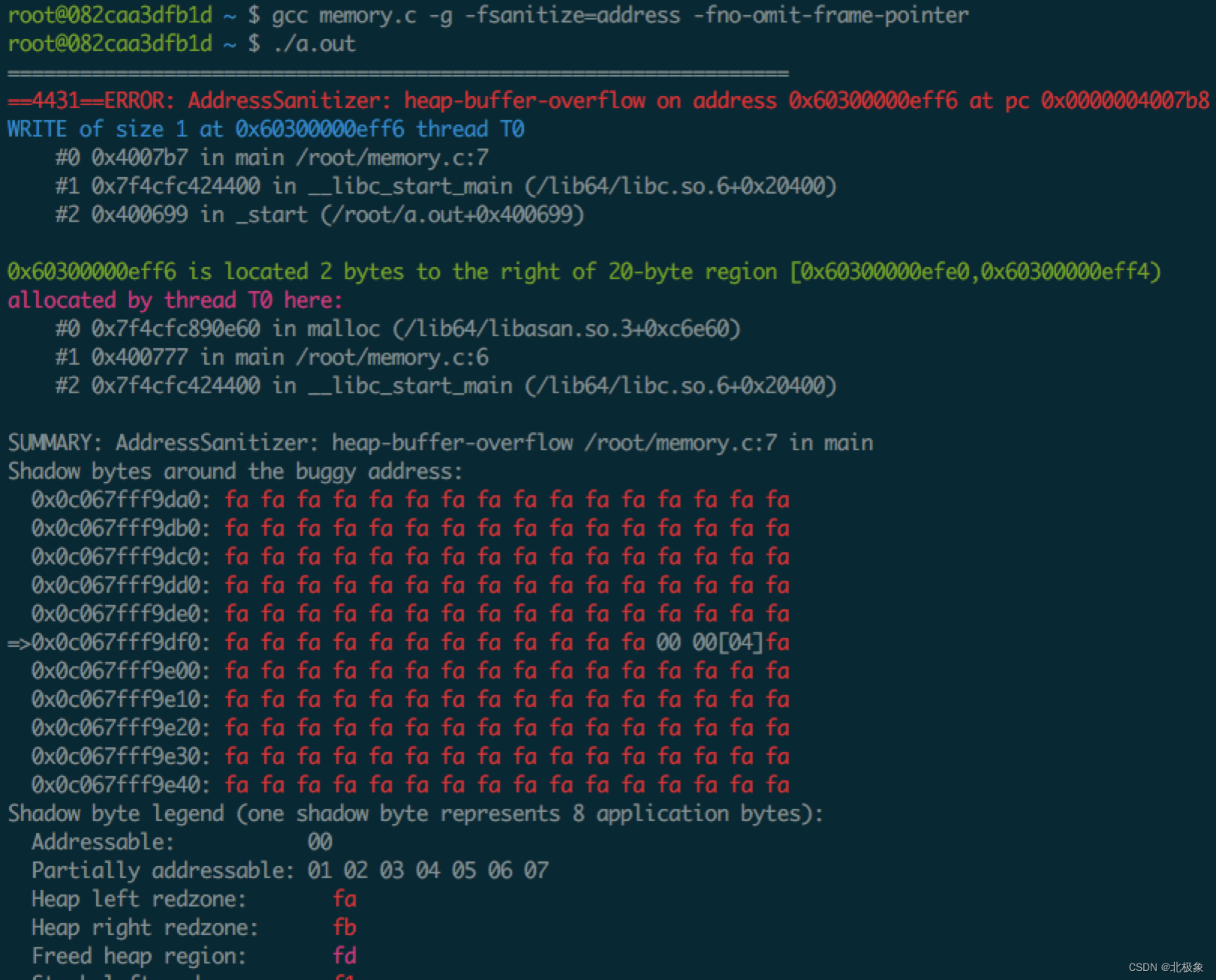
输出的结果也明确表示了越界的问题代码的位置在第7行,并且给出了越界位置的内存数据(红色部分)。另外第6行申请的内存泄露了。
实践中发现新版本gcc的这个功能很给力,性能衰减比Valgrind都小(但是还是很明显的慢),基本上编译后的服务组件是可以勉强跑压测的。添加gcc的检查参数,编译后完整的跑一遍单元测试和性能测试,就能发现内存访问的错误。
mprotect 或 gdb 内存断点(注意Linux地址空间随机化)
如果以上的工具都没办法解决的问题,多半都是在高并发情况下出现的一些竞态条件引起的。如果在编码阶段没有从理论上处理好多线程竞争的竞态条件,就给后期的调试埋下了很深的坑。多线程编程经验后面再说,这里先讨论如果真到了这一步怎么办。
既然内存检查工具无法重现问题,多半都是这些工具对测试程序造成的性能衰减引起的(先确认是否覆盖了所有的case和代码执行路径,是否执行过了会触发问题的代码路径)。那么这时候一般有两个方法,第一是寄希望于代码的静态扫描工具,这个谷歌下有很多,这里不讨论;另一个就是本节要说的:mprotect 或 gdb 内存断点。既然问题只有在高并发且性能不衰减的情况下触发,那么采用的手段就不能影响或者基本上不影响程序的性能。
如果程序每次core的位置都很固定或者位置相对固定的话,可以使用mprotect(2)系统调用:
#include <sys/mman.h>
int mprotect(void *addr, size_t len, int prot);
具体的参数和demo可以man 2 mprotect查看,这里不照搬man文档了。
mprotect(2)的限制也很明显,需要页对齐的地址(因为Intel对页属性设置的限制)。所以分配内存时就比较麻烦一点,需要合理的计算位置,将出现问题时会导致被破坏的地址囊括在保护范围,又不能影响其他代码正常执行。由于这个限制,会对mprotect(2)的使用场景有一些限制,但是对于固定会越界的代码位置来说,计算好数据位置,使得越界后第一个字节的内存起始的内存页就处于写保护中就可以了。随后像man文档的例子一样注册SIGSEGV信号的处理函数即可,这里可以用backtrace(3)和backtrace_symbols(3)等函数来打出调用栈,轻松找过越界的罪魁祸首。
最后是看似最原始最简单,但是依旧很给力的gdb内存断点。gdb调试支持对内存位置设置修改断点,不用自己很麻烦的设置内存保护和信号处理函数。而且gdb的内存断点不像直接用mprotect(2)有那么多限制(简单的翻了下代码,gdb用的是Intel CPU的调试寄存器实现,照着Intel文档写一个也没有多困难)。
下面演示下简单的使用方法,先看一段简单示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
void *thread_func(void *buff) {
sleep(1);
char *buffer = (char *)buff;
buffer[22] = 'a';
return NULL;
}
int main() {
char *buffer = malloc(20);
pthread_t th;
pthread_create(&th, NULL, thread_func, buffer);
pthread_join(th, NULL);
return 0;
}
另一个线程越界访问了buffer区域,下面用gdb的内存断点测试下,结果如下:
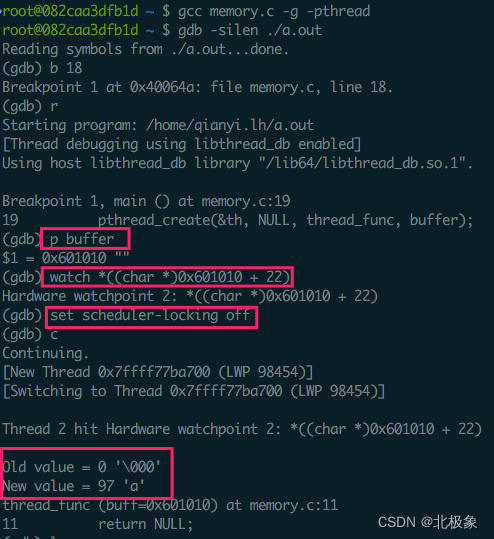
注意多线程调试的话要决定是都让gdb锁定调度,另外如果要监视子进程,运行程序前还要设置set follow-fork-mode child属性。如果是自己编码实现调试的话,关系到内存地址的一些操作,建议启动程序前禁用掉Linux的地址空间随机化机制(ASLR,Address space layout randomization),避免麻烦(gdb自己会设置,不需要关注)。ASLR是防御缓存区溢出的保护措施,关闭的方法很简单:
sudo sysctl -w kernel.randomize_va_space=0
总结和经验
内存定位工具使用经验
一般情况下遇到了内存泄露(ML,Memory Leak)的问题,简单看看最近新增代码的内存申请与释放部分,大多数能看出来。如果看不出来,直接用Valgrind运行检测, 很容易检查出来。另外遇到了不匹配地使用 malloc/new/new[] 和 free/delete/delete[]的问题,Valgrind也很容易检查出来。使用二方库和三方库的时候,很容易犯错误,如果遇到了库内申请的内存需要用户代码自己释放的情况(个人反感这种设计),一定要认真阅读文档,必要时查看源代码确认。
内存泄露(ML,Memory Leak)的问题至今还没有遇到Valgrind检查不出来的情况,道听途说过有人遇到过高并发下出现泄漏的情况,用Valgrind拖慢了程序,查不出来。这时候可以重载下全局的malloc / free函数,申请和释放内存的时候打印函数和返回地址(用异步日志库),运行一段时间后写代码处理日志,找到泄漏点即可。
若是coredump的问题,用gdb载入coredump文件和代码先行分析,一般能解决。如果解决不了直接上Valgrind跑跑看。如果Valgrind检查不出来,Electric Fence一般是不用试的。可以直接上DMalloc了,重新编译程序后测试。如果再不行,推荐gcc的-fsanitize=address -fno-omit-frame-pointer参数编译再运行测试。如果这些简单无脑的办法解决不了,就踏踏实实的分析代码,重现出足够多的coredump样本分析蛛丝马迹。然后用mprotect(2)保护相关的内存,设置SIGSEGV信号的处理函数。最后,有些越界之类的问题没那么复杂, gdb载入后设置内存断点,很容易就能找出罪魁祸首,很少需要自己用mprotect(2)之类的手段。所以玩好gdb就能解决很多问题了。
多线程编程经验
多线程编程是个很大的话题,这篇文章不准备细说,只给出一点参考建议。首先是教材,C/C++的多线程编程的经典教材很少,近些年也就一本《C++ Concurrency in Action(中文版:C++并发编程实战)》还算能看,但是说实话也不怎么样。倒是Java领域有很多并发编程的大作,比如《Java Concurrency In Practice(中文版:Java并发编程实践)》很不错。另外Java的concurrent库值得一读,我自己很多C++的并发的数据结构就是照抄concurrent翻译成C++的。C++程序员反过来向Java学习并发多少有点讽刺,C++11标准明确了内存模型之后,希望在并发领域能诞生些大作吧。
接着说说经验,并发的代码不是那么容易写的,如果不能准确的判断出竞态条件的话,不建议去写并发的代码。否则绝对是给自己找不自在。如果避免不了,一定要有完整的理论学习之后再上手,多分析多思考,多读优秀的并发实现(C++没有代表性的代码的话就去读Java的concurrent库,学着改成C++版的)。除此之外,C++代码尽可能的避免在线程间共享对象(单例除外),尽可能的使用成熟的并发模式和数据结构减少直接的对象共享,比如ConcurrentHashMap、NonBlockingQueue、BlockingQueue、CountDownLatch等。
C++在线程间共享对象有很多麻烦,尤其是析构函数面临的一系列竞态条件。详细的描述可以围观陈硕的大作《当析构函数遇到多线程》。shared_ptr这种引用计数型智能指针成为主流用法还需要时间(循环引用的问题需要时刻小心),但是可以预见的是会被更多的人接受。至于shared_ptr和weak_ptr的使用难度,最多几个小时认真学习和实践就能掌握。
最后,总结一句最精炼的C/C++多线程编程经验,那就是——别用C++写并发代码,工程中最好就别用C++这个语言。