cuda学习笔记4——cuda 核函数
- 一、CUDA规范
- 二、核函数内部线程的使用
- 2.1 如何启动核函数
- demo 1:起16个线程来计算,四个线程块,每个块内四个线程例子
- demo2
核函数是指在GPU端运行的代码,核函数内部主要干了什么?简而言之,就是规定GPU的各个线程访问哪个数据并执行什么计算。
一、CUDA规范
1、编写核函数必须遵循CUDA规范,CUDA规范如下:
- 必须写在*.cu文件中
- 必须以__global__限定符声明定义;
- 返回类型必须是void;
- 不支持可变数量的参数;
- 核函数内部只能访问设备内存
- 核函数内部不能使用静态变量
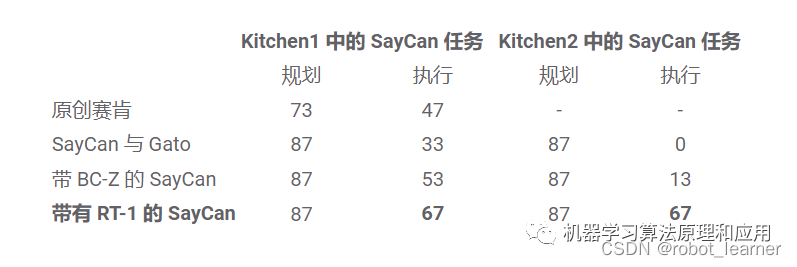
2、函数声明中,global、device、__host__三者区别
-
__global__修饰的函数是核函数,在设备端执行,可以从主机端调用,也可以在sm3以上的设备端调用(比如动态并行);
-
__device__修饰的函数是设备函数,在设备端执行,只能从设备端调用;
-
__host__修饰的函数是主机函数,在主机端执行,只能从主机端调用;
-
__device__和__host__可以一起使用,来表示该函数可以同时在主机端和设备端执行;
-
nvcc编译选项中添加-dc(相当于–relocatable-device-code=true --compile)时,__global__函数可以调用其它文件中的__device__函数,否则只能调用同文件中的__device__函数。
__global__描述的函数就是“被CPU调用,在GPU上运行的代码”,同时它也打通了__host__和__device__修饰的函数。
二、核函数内部线程的使用
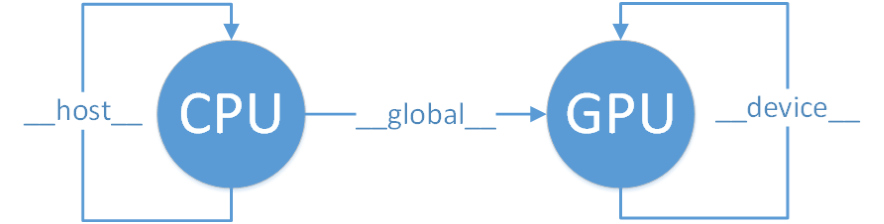
CUDA从逻辑上将GPU线程分成了三个层次——线程格(grid)、线程块(block)和线程(thread)。
每个核函数对应一个线程格,一个线程格中有一个或多个线程块,一个线程块中有一个或多个线程。在一维的情况下,三者关系如图所示。

CUDA核函数中为什么将线程分为三个层次,其实是与GPU的硬件组成相关联的。在GPU硬件中本身就存在三个层次——核心、流多处理器、设备,这是一种类似于计算机集群的层次结构,而我们编写的核函数正是运行在这种层次结构上,所以核函数必须支持这三个层次,否则任务无法顺利分解,也就无法从高层次向低层次传递。
我们可以将Grid想象为一栋楼,将Block想象为楼里面的房间,而Thread就是房间里面的工作人员。这样,启动一个核函数就像将一项任务交给一栋楼来完成,楼将任务分解给各个房间,房间再将任务分解给各个工作人员。
使用线程时需要弄清楚两个值——线程全局id和核函数的线程总数。
在核函数内部有四个非常有用的内置变量——threadIdx、blockIdx、blockDim和gridDim。我们可以通过blockIdx索引到线程块,通过threadIdx索引到某个块内的线程,通过blockDim得到一个块内线程总数,通过gridDim得到一个格内块总数。
所以,在一维的情况下,计算线程全局id公式为:
线程全局id = blockIdex.x * blockDim.x + threadIdx.x
在一维的情况下,核函数内的线程总数为:
核函数的线程总数 = gridDim.x * blockDim.x
在二维的情况下,两个值的计算公式为:
线程全局id = (blockIdex.x + blockIdx.y * gridDim.x) * (blockDim.x * blockDim.y) + threadIdx.x + threadIdx.y * blockDim.x
核函数的线程总数 = gridDim.x * gridDim.y * blockDim.x * blockDim.y
以一维的方式实现两个数组逐元素相加为例,展示核函数编写方法:
__global__ void kernelAdd(float *a, float *b, float *c, unsigned int n)
{
unsigned int tx = threadIdx.x;
unsigned int bx = blockIdx.x;
unsigned int index = bx*blockDim.x + tx;
unsigned int stride = gridDim.x*blockDim.x;
while(index<n)
{
c[index] = a[index] + b[index];
index += stride;
}
}
在kernel函数中,grid size 和block size都被存储在内置预定义变量gridDim.x 和 blockDim.x中。相应地,线程唯一id被以下两个内置预定义变量所制定:
blockIdx.x: 指定了线程在几个网格(grid)的第几个块(block),值在0到gridDim.x - 1之间。
threadIdx.x:指定了线程在第几个块(block)中的第几个线程,值在0到blockDim.x - 1之间。
2.1 如何启动核函数
启动CUDA核函数与启动C/C++函数很相似,只是额外添加了<<<>>>尖括号配置信息,尖括号内的配置信息并不是传递给核函数的,而是传递给CUDA运行时系统,告诉运行时系统如何启动核函数。
尖括号中包括四种信息,<<<块个数,线程个数,动态分配共享内存,流>>>,其中动态分配共享内存和流不是必填项。确定块个数和线程个数的一般步骤为:
先根据GPU设备的硬件资源确定一个块内的线程个数
再根据数据大小和每个线程处理数据个数确定块个数
参考代码如下:
//每个块内有256个线程
unsigned int threads = 256;
//每个线程处理4个数据,注意这4个数不是相邻的
unsigned int unroll = 4;
//根据数据量计算出块的个数
//为了保证线程数足够,在数据量的基础上加了threads-1,相当于向上取整
unsigned int blocks = (dataNum + threads -1)/threads/unroll;
cudaKernel<<<blocks, threads>>>(***);
demo 1:起16个线程来计算,四个线程块,每个块内四个线程例子
test3.cu
#include "cuda.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("Hello World from block %d and thread %d!\n", bid, tid);
}
int main(void)
{
hello_from_gpu<<<4, 4>>>();
cudaDeviceSynchronize();
return 0;
}
编译
nvcc test3.cu -o test3
运行
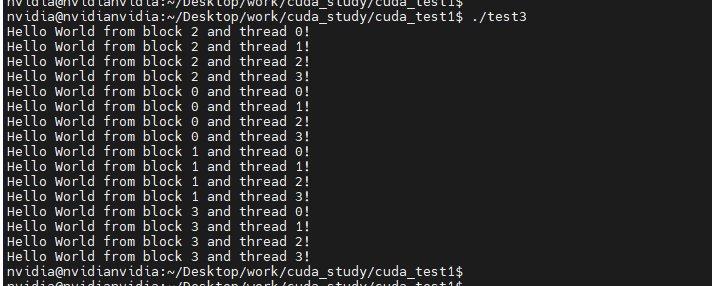
因为每个网格(grid)互相独立,所以上述输出并不确定。
demo2
#include "cuda.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void run_on_gpu() {
printf("GPU thread info X:%d Y:%d Z:%d\t block info X:%d Y:%d Z:%d\n",
threadIdx.x, threadIdx.y, threadIdx.z, blockIdx.x, blockIdx.y, blockIdx.z);
}
int main() {
dim3 threadsPerBlock(2, 3, 4);
int blocksPerGrid = 1;
run_on_gpu<<<blocksPerGrid, threadsPerBlock>>>();
cudaDeviceReset();
return 0;
}
参考:
https://blog.csdn.net/jr_Peng/article/details/125188778
https://blog.csdn.net/weixin_38346042/article/details/127155195
https://blog.csdn.net/breaksoftware/article/details/79302590
https://blog.csdn.net/xiangxianghehe/article/details/91870957