YOLO-V1
经典的one-stage方法
YouOnlyLookOnce,名字就已经说明了一切!把检测问题转化成回归问题,一个CNN就搞定了!可以对视频进行实时检测,应用领域非常广!
 核心思想:
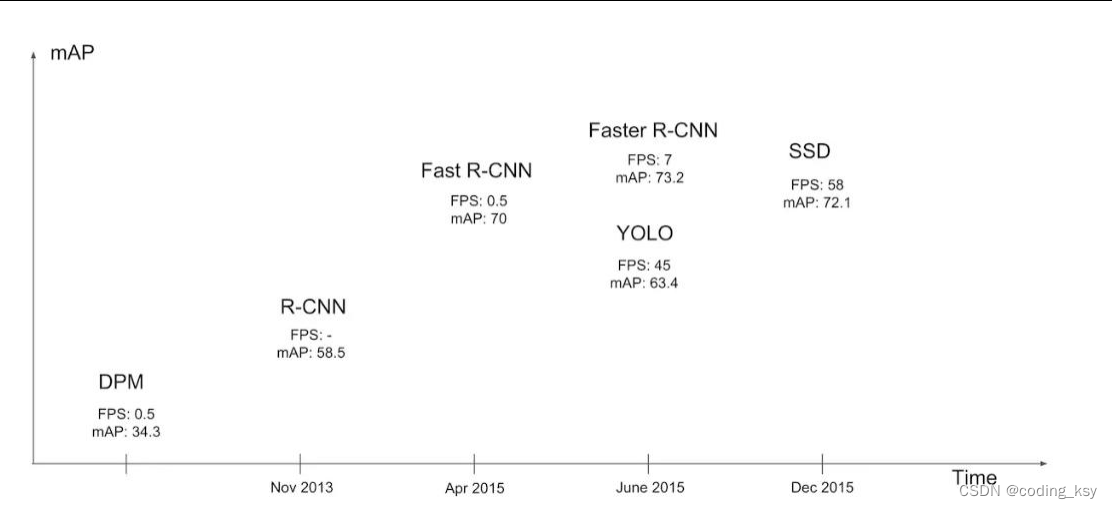
核心思想:
Yolov1的核心思想是将对象检测问题转化为一个回归问题,通过单个神经网络直接在输入图像上预测边界框和类别。这个网络被划分为多个网格,每个网格负责检测特定区域内的对象。每个网格预测多个边界框和每个边界框的置信度,以及每个边界框所属的类别。整个网络采用全连接层将所有预测值聚合在一起,并利用非极大值抑制过滤出最终的检测结果。这种方法减少了检测过程中的计算量,提高了检测速度,同时保持了较高的准确率。
 网络架构
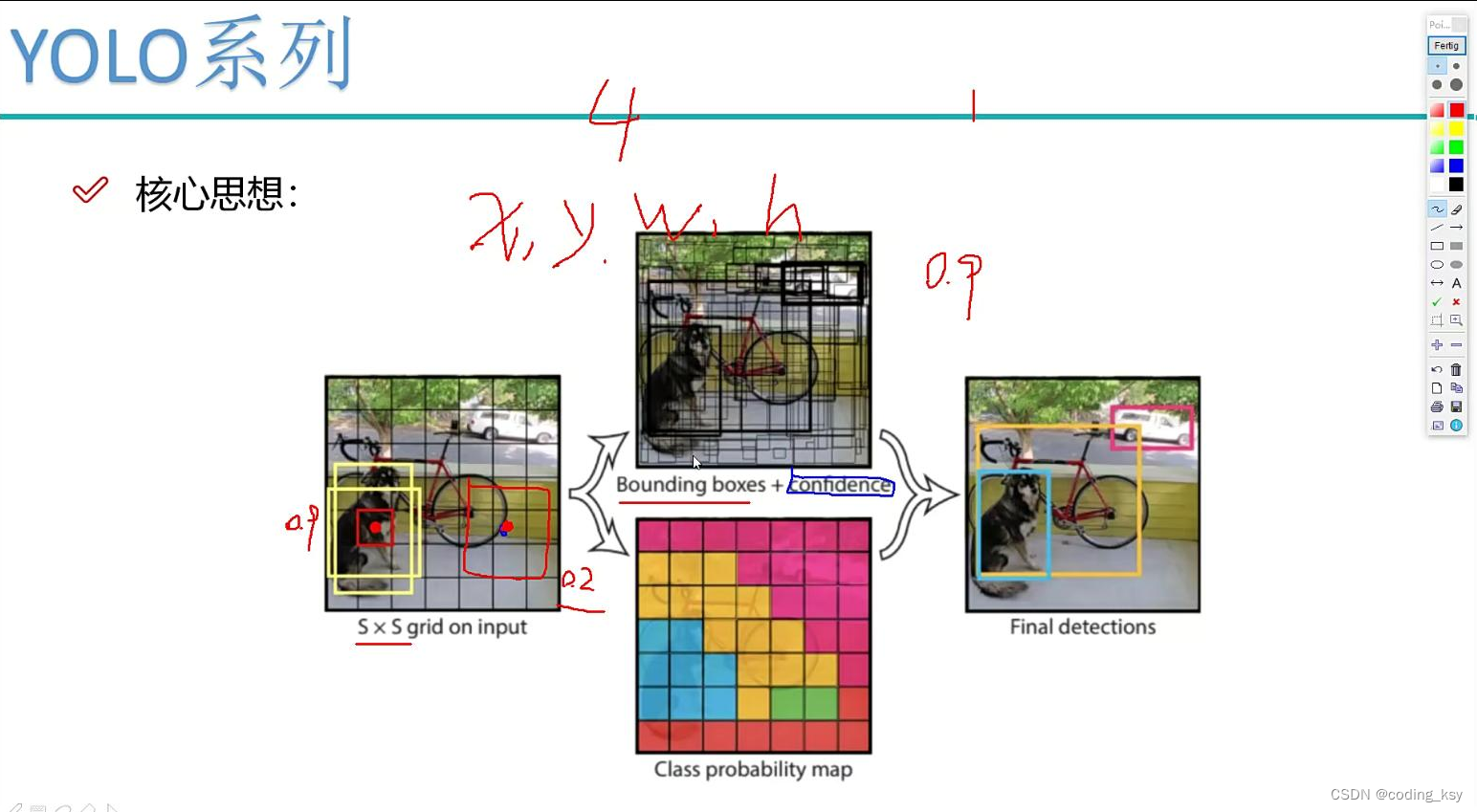
网络架构
YOLOv1(You Only Look Once Version 1)是一种基于卷积神经网络的目标检测算法,由Joseph Redmon于2015年提出。相较于之前的目标检测算法,YOLOv1在速度上有很大的优势,可以实现实时目标检测。
YOLOv1的网络架构可以分为两个阶段:特征提取和目标检测。特征提取使用了一个24层的卷积神经网络,将输入图像经过多次卷积层和池化层处理后,得到一张特征图。目标检测则在这张特征图上完成,将图像分成7x7个网格,并对每个网格预测目标的类别和位置。
YOLOv1的网络架构如下图所示:
yolov1-network-arch
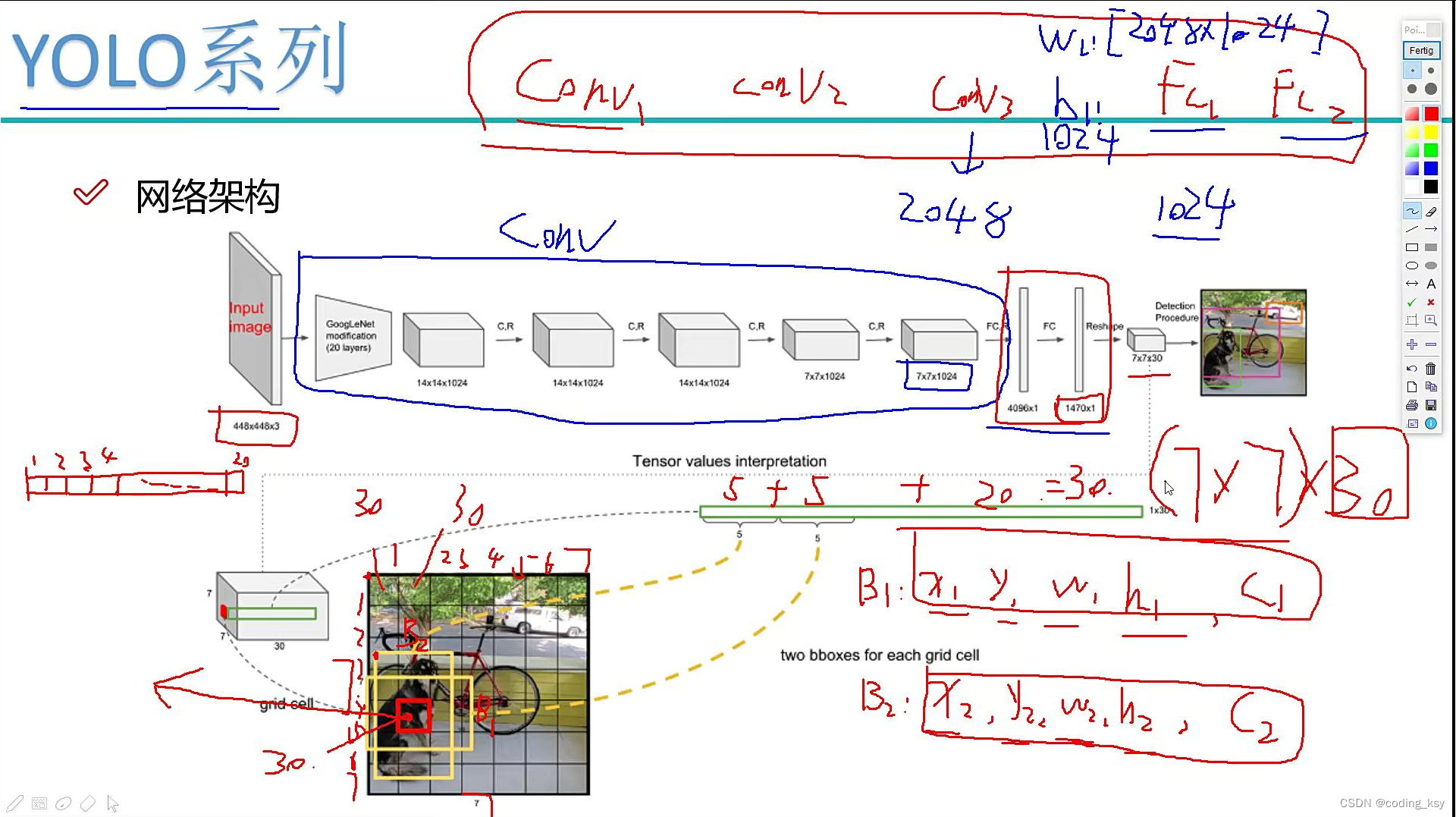
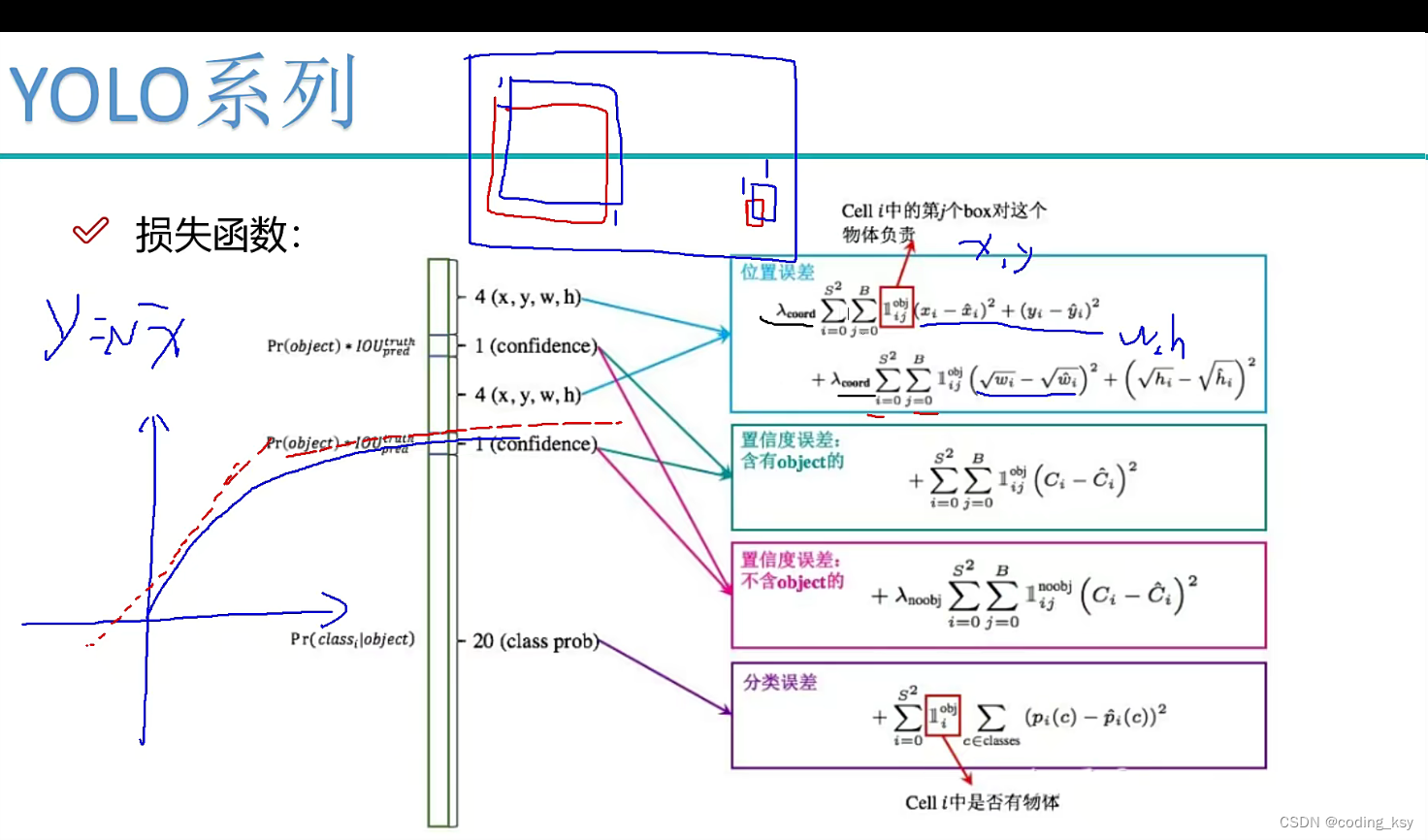
输入图像首先会经过一个卷积层,该卷积层使用Sobel边缘检测滤波器,可以提取图像中的边缘信息。接着经过多个卷积层和池化层处理,最后得到一张7x7x1024的特征图。这张特征图被分为7x7个网格,每个网格预测两个边界框(bounding box),每个边界框包含5个预测值:x、y、w、h和置信度(confidence)。x和y表示边界框中心在网格中的位置,w和h表示边界框的宽度和高度,置信度表示该边界框包含目标的概率。
YOLOv1的训练过程使用了交叉熵损失函数,并且将不同类别的损失进行了加权,使得小目标和大目标的权重相等,避免了某些类别在预测时过度占据了损失函数。此外,YOLOv1的训练过程采用了多尺度输入图像,以更好地处理不同大小的目标。
虽然YOLOv1在速度上有很大的优势,但是在检测精度方面并不是最优的。随后的YOLOv2、YOLOv3和YOLOv4等版本不断推出,对YOLOv1的网络架构进行了改进和优化,提高了检测精度和速度。
每个数字的含义
损失函数
NMS(非极大值抑制)
 NMS (Non-maximum suppression,非极大值抑制)是一种在计算机视觉中常用的技术,主要用于目标检测、边缘检测等领域中的局部最大值的筛选。
NMS (Non-maximum suppression,非极大值抑制)是一种在计算机视觉中常用的技术,主要用于目标检测、边缘检测等领域中的局部最大值的筛选。
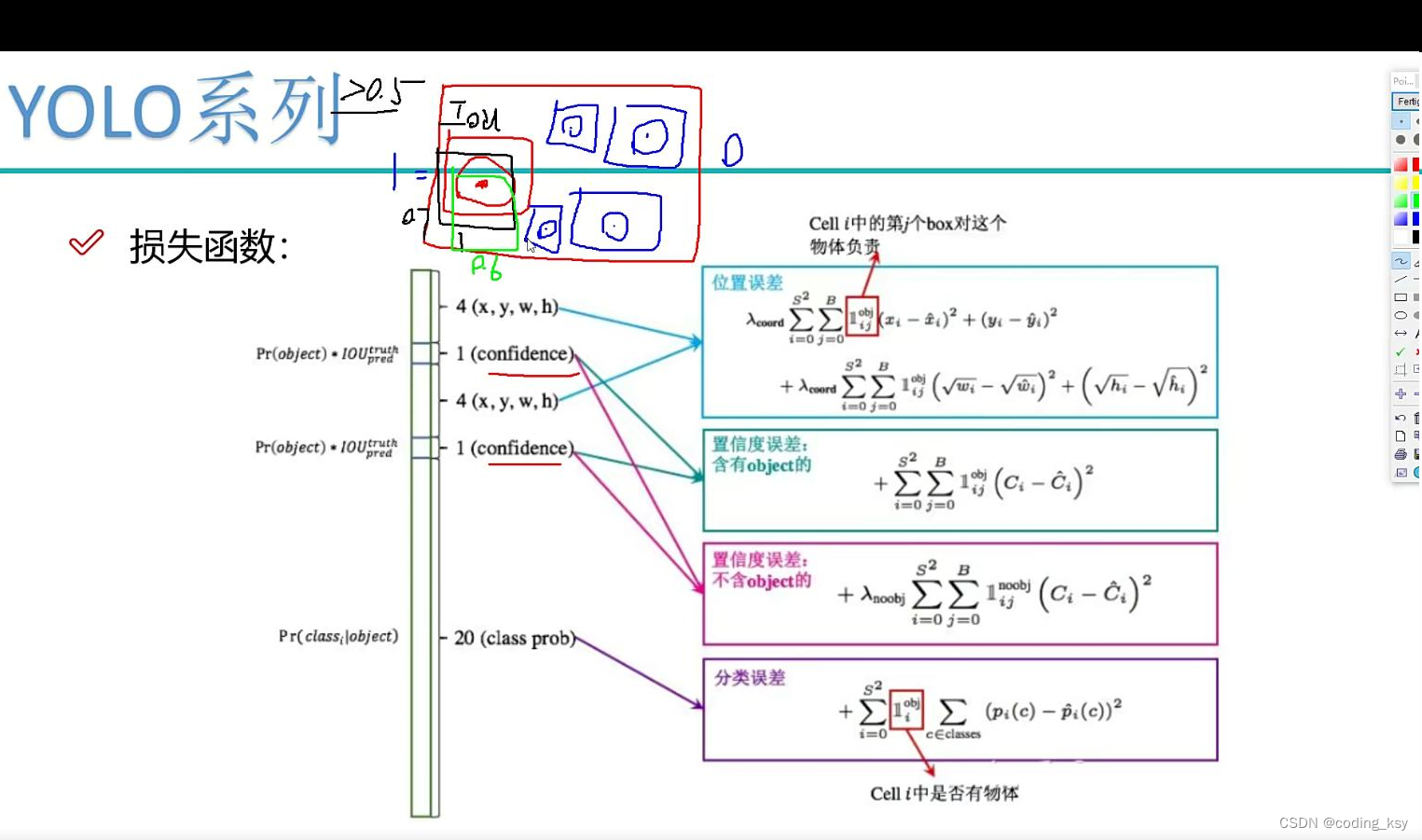
在目标检测中,经常会使用滑动窗口或者锚框来搜索可能包含目标的区域。这个过程中,往往会产生很多重叠的检测结果,不同的检测结果可能都认为自己是目标。这时候,需要使用NMS来筛选掉其中的冗余检测结果,只保留最准确的那一个。
NMS的基本思想很简单,对于一组检测结果,首先会按照其得分(比如分类概率)从高到低排序,然后从得分最高的检测结果开始,遍历其余所有检测结果。对于任意两个重叠度(IoU)大于一定阈值的检测结果,只保留得分较高的那个,将得分较低的检测结果删除。重复这个过程,直到所有检测结果被遍历完。
NMS算法的核心就是对检测框进行排序和遍历并删除冗余的检测框,然后返回排好序的检测框列表。NMS算法是目标检测的重要组成部分,也是多个目标检测算法共有的一个优化手段。
YOLO-V1的优缺点
优点:快速,简单!
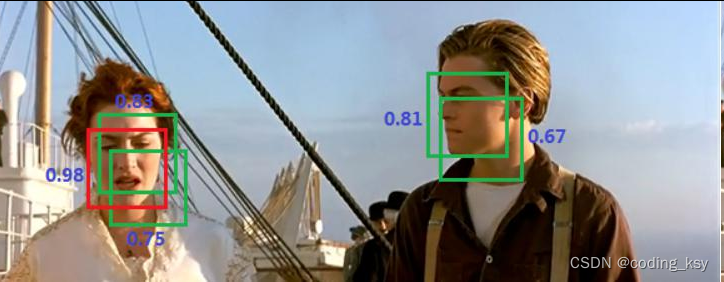
问题1:每个Cell只预测一个类别,如果重叠无法解决问题2:小物体检测效果一般,长宽比可选的但单一