博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
文章目录
- CUDA编程模型——共享内存
- 一、多种CUDA存储单元介绍
- 1.1 共享内容介绍
- 1.2 配方式
- 1.3 bank竞争
- 1.4 如何避免冲突
- 1.5 共享内存优化
CUDA编程模型——共享内存
一、多种CUDA存储单元介绍
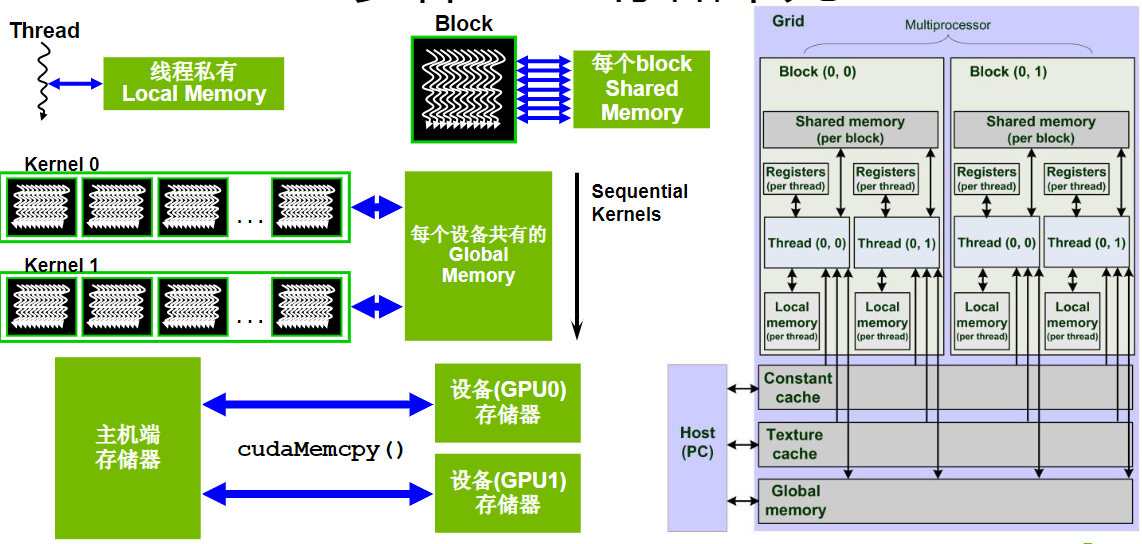
内存访问速度(由快到慢):
- Register file
- Shared Memory
- Constant Memory
- Texture Memory
- Local Memory and Global Memory:位于Device memory中,空间最大,latency最大,是GPU最基础的内存;
1.1 共享内容介绍
实际驻留在GPU芯片上的内存只有两种类型:寄存器和共享内存。所以,Shared Memory是目前最快的可以让多个线程通信的地方。那么,就有可能会出现同时有很多线程访问Shared Memory上的数据。为了克服这个同时访问的瓶颈,Shared Memory被分成32个逻辑块,称为bank。
- Shared Memory可以被设置成16KB,32KB ,48KB…剩下的给L1缓存;
- 带宽可以使32bit 或者 64 bit;
- 可以被多线程同时访问,因此存储器被划分为 banks;
- 连续的 32-bit 访存被分配到连续的 banks;
- 每个 bank 每个周期可以响应一个地址;
- 如果有多个bank的话可以同时响应更多地址申请;
1.2 配方式
静态分配:
- __shared__ int s[64];
动态分配: - dynamicKernel<<<1, n, n*sizeof(int)>>>(d_d, n);
extern __shared__ int s[];
1.3 bank竞争
- 同常量内存一样,当一个 warp 中的所有线程访问同一地址的共享内存时,会触发一个广播(broadcast)机制到
warp 中所有线程,这是最高效的; - 如果同一个 half-warp/warp 中的线程访问同一个 bank中的不同地址时将发生 bank conflict;
- 每个 bank 除了能广播(broadca st)还可以多播(mutilcast)(计算能力 >= 2.0),也就是说,如果一个 warp 中的多个线程访问同一个 bank 的同一个地址时(其他线程也没有访问同一个bank 的不同地址)不会发生 bank
conflict; - 即使同一个 warp 中的线程随机的访问不同的 bank,只要没有访问同一个 bank 的不同地址就不会发生 bank conflict;
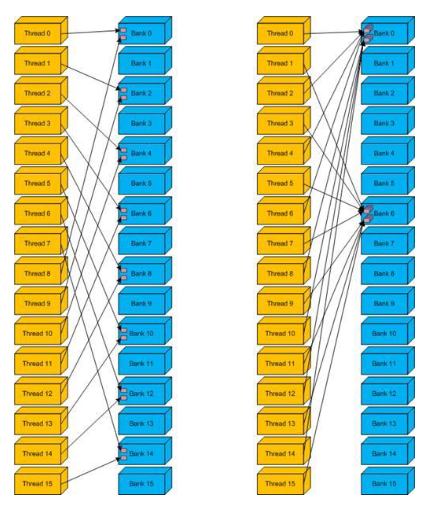
如果没有bank冲突的话,Shared memory 跟 registers 一样快:
- 快速情况:
- warp 内所有线程访问 不同 banks, 没有冲突
- warp 内所有线程读取同一地址,没有冲突(广播)
- 慢速情况:
- Bank Conflict: warp 内多个线程访问同一个bank
- 访存必须串行化
1.4 如何避免冲突
先看一个有bank冲突的例子:

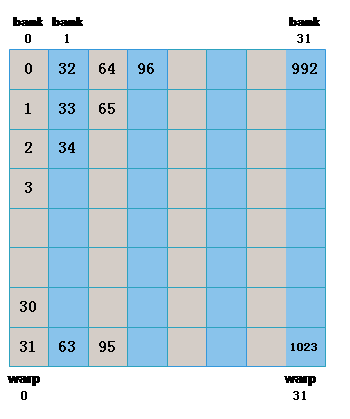
一个warp中的线程会访问,同一列中的数据,产生了bank冲突。
解决方法:
-
memory padding方法
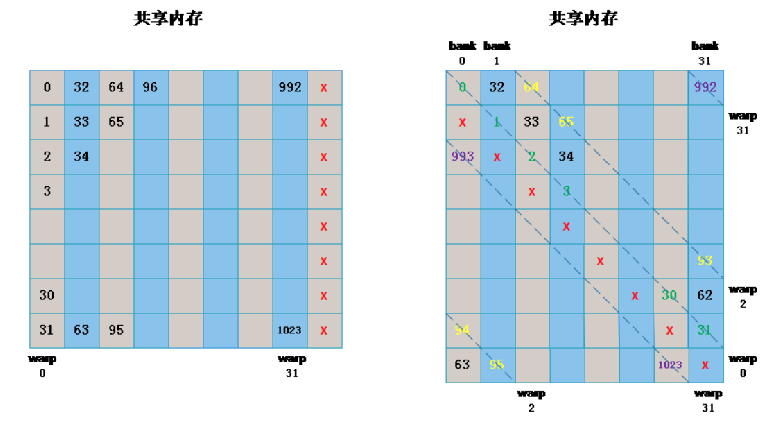
使用了上面的内存padding方法之后,访问顺序编程了右图所示的“斜线”的顺序,代码如下:

1.5 共享内存优化