文章目录
- mq由哪几部分组成
- rocketmq
- kafka
- 为什么需要这几部分
- nameserver/zookeeper
- 可靠性
- broker
- 可靠性
- 生产者
- 消费者
mq由哪几部分组成
rocketmq
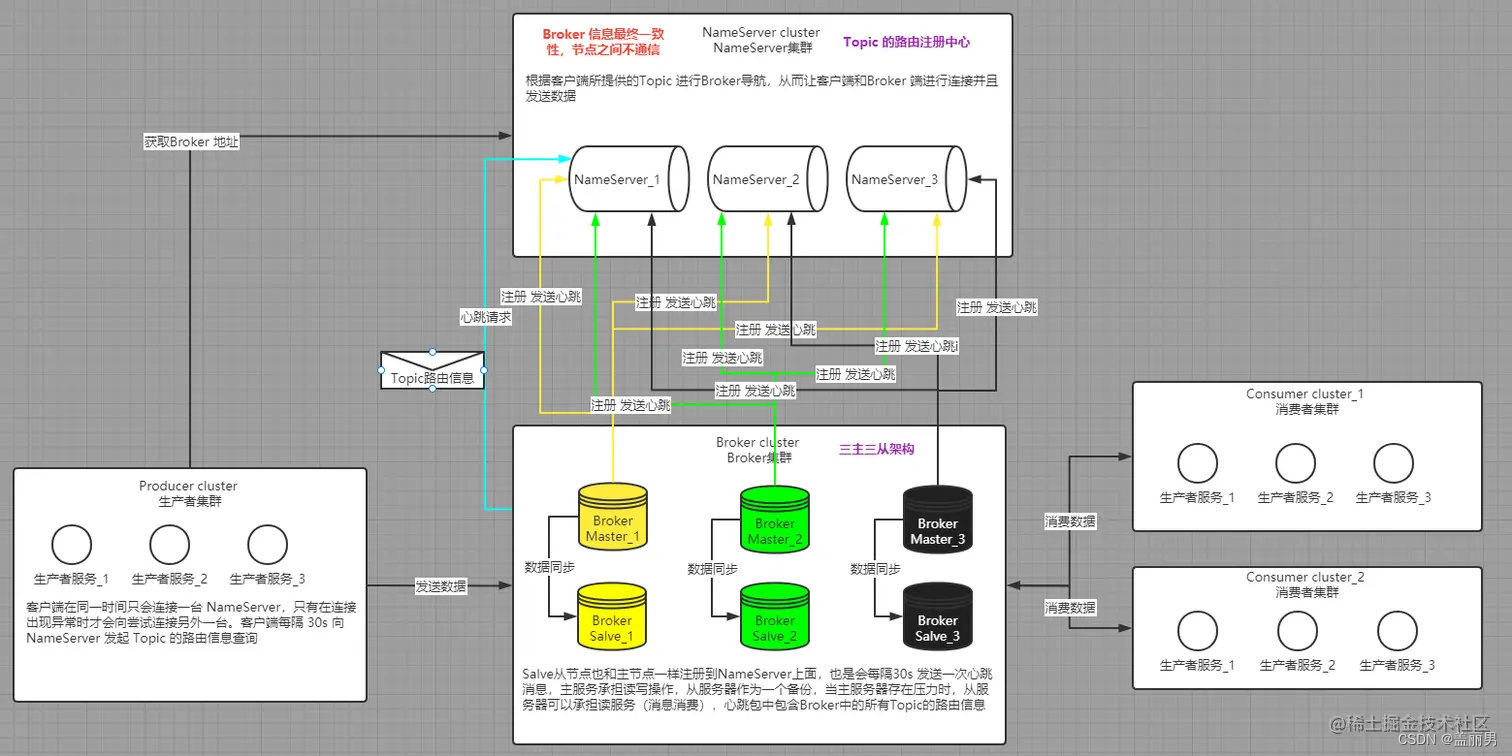
kafka
这里先不讨论Kafka Raft模式
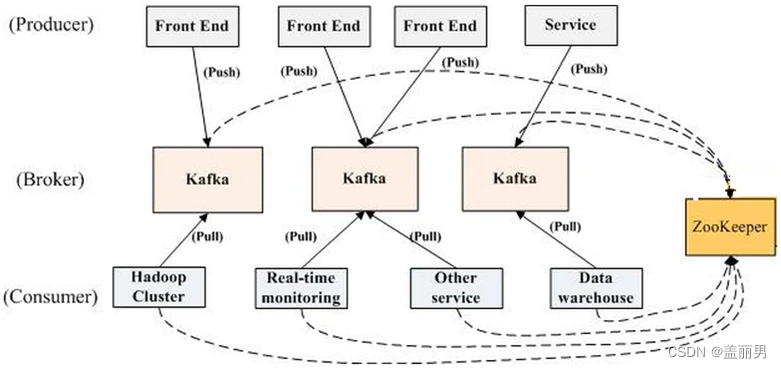
比较一下,kafka的结构和rocketmq的机构基本上一样,都需要一个注册中心,一个broker,然后就是我们的生产者和消费者。
为什么需要这几部分
nameserver/zookeeper
可以理解为注册中心,生产者,消费者,broker都需要注册到nameserver。
RocketMQ 中的 NameServer 和 Kafka 中的 ZooKeeper 在一些方面有相似的作用,但也存在一些区别。它们都是分布式消息传递系统中的关键组件,用于协调和管理集群中的各种信息和状态。以下是它们的共同点和区别:
共同点:
-
集群配置管理: 在两个系统中,都需要管理集群的配置信息,如节点的网络地址、分区分配等。
-
节点健康监测: NameServer 和 ZooKeeper 都能监测集群中各个节点的健康状态,帮助及时发现故障。
-
负载均衡: 两者都可以支持负载均衡,确保请求分发到可用的节点上。
-
元数据管理: 它们都用于存储和管理集群中的元数据,包括主题、分区、消费者组等信息。
-
故障检测和恢复: 在故障情况下,都能够帮助检测并协助进行恢复,确保数据的可用性。
区别:
-
角色不同: NameServer 主要用于 RocketMQ 集群的消息管理和路由,而 ZooKeeper 在 Kafka 中的作用更广泛,涵盖了集群的配置、状态、协调等多个方面。
-
分区分配: 在 Kafka 中,ZooKeeper 参与分区和副本分配的过程,而在 RocketMQ 中,NameServer 只处理消息队列的路由信息。
-
Leader 选举: 在 Kafka 中,ZooKeeper 负责监测 Leader 的状态并进行选举,而在 RocketMQ 中,Leader 选举是由 Broker 自身处理的。
-
消费者协调: 在 Kafka 中,ZooKeeper 协调消费者组的成员关系和消费进度,而在 RocketMQ 中,消费者协调是由 Broker 和 NameServer 共同完成的。
-
依赖程度: 在 Kafka 2.8.0 版本以后,Kafka 开始逐步剥离对 ZooKeeper 的依赖,而在 RocketMQ 中,NameServer 仍然是核心组件之一。
可靠性
rocketmq的nameserver可以集群配置来实现高可用,还可以配置相应的报警和备份机制。
zookeeper一般我们部署的时候都会部署多个节点来保证可用性。
broker
总体上,不管是rocketmq还是kafka的broker,都包含了消息存储,传递和处理的功能。可以理解为数据处理的中心,生产者和消费者都要和broker打交道。
可靠性
RocketMQ 和 Kafka 都是流行的分布式消息传递系统,它们在消息存储、可靠性和吞吐量方面有些不同的实现策略。
RocketMQ 的消息存储和可靠性:
在 RocketMQ 中,消息存储使用了类似数据库的存储引擎,被称为 CommitLog(提交日志)。消息首先被写入 CommitLog 中,然后通过内存映射的方式进行索引,这有助于实现高速读写。然后,消息将异步复制到其他 Broker 节点的 CommitLog 中,以实现冗余和可靠性。
-
可靠性保障: RocketMQ 通过异步复制和冗余存储来实现消息的可靠性。当消息写入本地 CommitLog 后,会异步地进行复制到其他 Broker 节点。只有当多个 Broker 节点都确认收到消息后,消息才被视为已提交。这种方式保障了消息的不丢失和高可靠性。
-
吞吐量: RocketMQ 通过消息分区和水平扩展来提高吞吐量。每个主题被划分为多个分区,每个分区都有多个副本。这样,多个消费者可以同时消费不同分区中的消息,从而提高了系统的吞吐量。
Kafka 的消息存储和可靠性:
在 Kafka 中,消息存储采用了一种日志结构的文件系统,被称为日志分段(Log Segment)。消息以追加写入的方式写入日志分段中,每个分段有固定大小。Kafka 还使用了消息索引来加速消息的查找。
-
可靠性保障: Kafka 通过副本机制来实现消息的冗余存储。每个分区通常有多个副本,其中一个是 Leader,负责读写操作,其他副本是 Followers,用于备份。当 Leader 宕机时,Kafka 可以从 Followers 中选举出新的 Leader。这种机制确保了消息在 Leader 宕机时仍然可用。
-
吞吐量: Kafka 通过分区和副本的组合来提高吞吐量。多个消费者可以并行地从不同分区读取消息,而多个副本可以在不同的 Broker 上并行处理写入操作,提高了整体吞吐量。
综上所述,RocketMQ 和 Kafka 在消息存储和可靠性方面都使用了类似的冗余副本机制,确保消息不丢失。它们的吞吐量提升主要通过分区、副本和并行处理来实现。虽然实现细节有所不同,但它们的目标都是在高吞吐量和消息可靠性之间取得平衡。
生产者
RocketMQ 和 Kafka 都提供了多种方式来保证消息生产者发送的消息的可靠性。以下是它们在消息可靠性方面的主要策略:
RocketMQ 生产者消息可靠性策略:
-
同步发送模式: RocketMQ 的生产者可以选择同步发送模式,这意味着生产者在消息发送后会等待消息被所有副本成功保存后才返回成功。这可以确保消息不会在发送时丢失。
-
异步发送模式: 生产者还支持异步发送模式,生产者在发送消息后不会等待确认,而是通过回调函数来处理消息发送的结果。异步发送适用于不需要严格的实时性的场景。
-
可靠性级别(Level): RocketMQ 支持不同的消息可靠性级别,分为可靠性发送和可靠性同步发送。可靠性发送仅确保消息被发送到 Broker,而可靠性同步发送会等待消息被所有副本保存后才返回。
-
重试和超时机制: 如果发送消息时遇到错误,RocketMQ 生产者会根据设置的重试次数和超时时间进行自动重试。这有助于确保消息在短时间内能够成功发送。
Kafka 生产者消息可靠性策略:
-
acks 配置: Kafka 生产者可以通过配置
acks参数来控制消息发送的可靠性级别。可以选择的值包括 0、1 和 all。acks=0表示生产者不等待确认,acks=1表示在 Leader 副本确认接收后返回,acks=all表示在所有副本都确认接收后返回。 -
重试机制: 如果消息发送失败,Kafka 生产者会自动进行重试,重试次数和间隔时间可以通过配置进行调整。
-
消息缓冲: Kafka 生产者会将发送的消息缓存在本地内存中,待缓冲区满或达到一定的时间间隔后,才进行一次批量发送。这样可以提高发送效率,并减少网络传输开销。
-
幂等性与事务性: 较新版本的 Kafka 支持生产者的幂等性和事务性。幂等性保证了重复消息不会引起副作用,而事务性确保了多个消息的原子性发送。
总的来说,无论是 RocketMQ 还是 Kafka,它们都提供了多种策略来确保生产者发送的消息的可靠性,包括等待确认、重试、缓冲和事务等机制,以满足不同应用场景的需求。选择适当的策略取决于业务需求和性能要求。
消费者
RocketMQ 和 Kafka 在消费者端都提供了一些机制来确保消息的可靠性传递。以下是它们在消息消费可靠性方面的主要策略:
RocketMQ 消费者消息可靠性策略:
-
消息确认机制: RocketMQ 消费者通过消息确认机制来确保消息的可靠性。消费者在成功处理消息后,会向 Broker 发送确认消息,告知该消息已被消费。如果消费者没有发送确认消息,Broker 将认为消息未被成功消费,会进行重试。
-
消息消费失败重试: 如果消费者在处理消息时发生错误,RocketMQ 支持设置消费重试次数。当消息消费失败时,消费者会自动进行重试,直到达到最大重试次数。
-
顺序消费: RocketMQ 支持顺序消费,即确保相同队列中的消息按照顺序被消费。这在需要保持消息顺序的业务场景中很有用。
-
定时消息和延迟消息: RocketMQ 支持定时消息和延迟消息,这允许消费者在特定时间或一段时间后消费消息,确保消息在正确的时机被处理。
Kafka 消费者消息可靠性策略:
-
偏移量管理: Kafka 消费者会跟踪每个分区的消费偏移量,确保消费者从正确的位置开始消费消息。消费者会定期提交偏移量,以便在重启后能够继续消费未处理的消息。
-
消费者组: Kafka 支持将多个消费者组成一个消费者组,每个分区只能被同一个消费者组中的一个消费者消费。这有助于确保每个消息只被一个消费者消费。
-
自动提交和手动提交: Kafka 消费者可以选择自动提交偏移量或手动提交偏移量。手动提交可以更精确地控制偏移量的提交,避免因自动提交导致的重复消费或丢失。
-
消息处理的幂等性: 消费者在处理消息时可以实现幂等性,确保多次处理同一消息不会产生副作用。
-
消费者分区再均衡: 当消费者组成员发生变化时,Kafka 会进行消费者分区再均衡,以确保分区被正确地分配给消费者。这有助于实现高可用性和负载均衡。
总之,无论是 RocketMQ 还是 Kafka,消费者端都提供了消息确认、消费失败重试、偏移量管理、幂等性处理等多种机制来保证消息的可靠性传递。选择适当的策略和配置取决于业务需求和性能要求。