概述
page migration设计之初是在numa system的各个node之间迁移physical pages,意味着进程页面的虚拟地址不会变化,物理地址发生改变,migration的目的将page迁移到临近的cpu上降低内存访问延迟。
页面迁移粗略步骤
A. In kernel use of migrate_pages()
-----------------------------------
1. Remove pages from the LRU.
Lists of pages to be migrated are generated by scanning over
pages and moving them into lists. This is done by
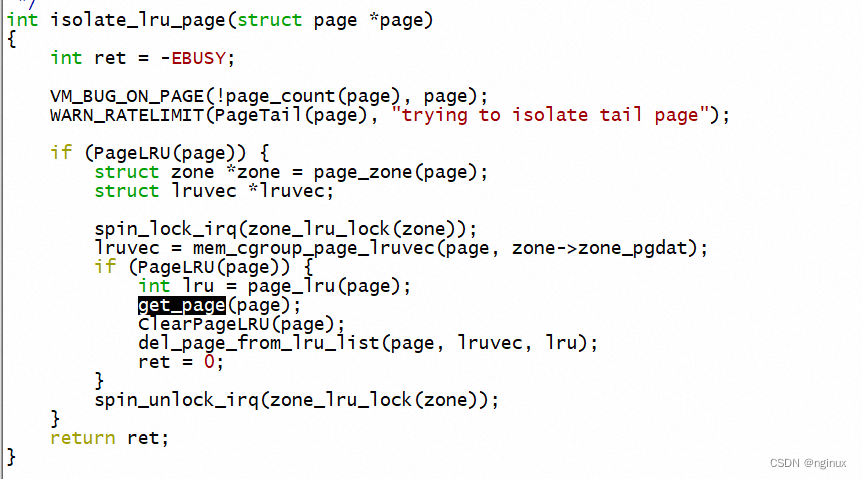
calling isolate_lru_page().
Calling isolate_lru_page increases the references to the page
so that it cannot vanish while the page migration occurs.
It also prevents the swapper or other scans to encounter
the page.
2. We need to have a function of type new_page_t that can be
passed to migrate_pages(). This function should figure out
how to allocate the correct new page given the old page.
3. The migrate_pages() function is called which attempts
to do the migration. It will call the function to allocate
the new page for each page that is considered for
moving.1. 将页面从LRU列表移除。
使用isolate_lru_page将一批pages从LRU中隔离出来,同时会增加page->_refcount引用计数,避免迁移过程中被回收或者swap-out换出。
2. 使用一个函数找到一个空闲的页面当作迁移目的地。
3. migrate_pages函数实现迁移逻辑。
Non-LRU page migration
具体参考内核:bda807d4445414e8e77da704f116bb0880fe0c76 这个提交
尽管migration最开始是numa系统降低内存访问延迟,随着内核发展,申请high-order时候触发的memory compaction也是migration重要使用者。当前migration设计的存在一个挺严重的问题:只能迁移LRU列表中的Page。但是万事都有例外,比如某些内核,某些内核申请的pages还是可以迁移的,比如zsmalloc, virtio-balloon pages。
为了解决上面的问题,driver需要一种方式告诉kernel说,是可以迁移Non-LRU page的。高速内存的方式就是定义三个函数:
1. bool (*isolate_page) (struct page *page, isolate_mode_t mode);
What VM expects on isolate_page function of driver is to return *true*
if driver isolates page successfully. On returing true, VM marks the page
as PG_isolated so concurrent isolation in several CPUs skip the page
for isolation. If a driver cannot isolate the page, it should return *false*.
Once page is successfully isolated, VM uses page.lru fields so driver
shouldn't expect to preserve values in that fields.
2. int (*migratepage) (struct address_space *mapping,
struct page *newpage, struct page *oldpage, enum migrate_mode);
After isolation, VM calls migratepage of driver with isolated page.
The function of migratepage is to move content of the old page to new page
and set up fields of struct page newpage. Keep in mind that you should
indicate to the VM the oldpage is no longer movable via __ClearPageMovable()
under page_lock if you migrated the oldpage successfully and returns
MIGRATEPAGE_SUCCESS. If driver cannot migrate the page at the moment, driver
can return -EAGAIN. On -EAGAIN, VM will retry page migration in a short time
because VM interprets -EAGAIN as "temporal migration failure". On returning
any error except -EAGAIN, VM will give up the page migration without retrying
in this time.
Driver shouldn't touch page.lru field VM using in the functions.
3. void (*putback_page)(struct page *);
If migration fails on isolated page, VM should return the isolated page
to the driver so VM calls driver's putback_page with migration failed page.
In this function, driver should put the isolated page back to the own data
structure.non-lru movable page flags
对于这种non-lru的pages有个重要的问题是:内核怎么知道non-lru pages是否movable?因为linux struct page的flags成员并没有一个PG_movable的标志,所以这种方式行不通,需要另辟蹊径,让driver主动告诉kernel,使用如下函数:

linux复用了page->mapping的最低两位,在内核里面page->mapping不仅可以用于标识non-lru page的movable特性,anon page也有在使用:
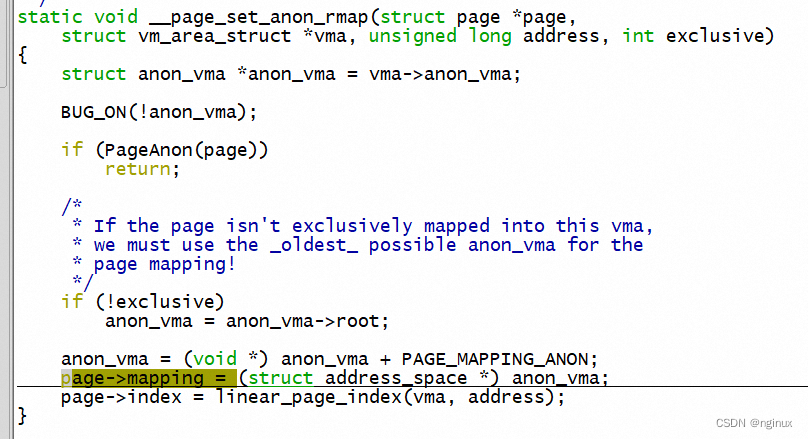
为什么anon page要在低两位增加PAGE_MAPPING_ANON呢?如上面代码anon page的mapping字段实际指向的是一个anon_vma结构,又因为mapping字段的类型是address_space,所以上面强转伪装成了address_space,这么一伪装就把kernel欺骗了,如果不适用额外的手段,kernel无法知道page->mapping到底是anon_vma,还是address_space了!!!,所以对于Anon page也复用mapping的低两位,用于区分这两种情况,内核注释如下:
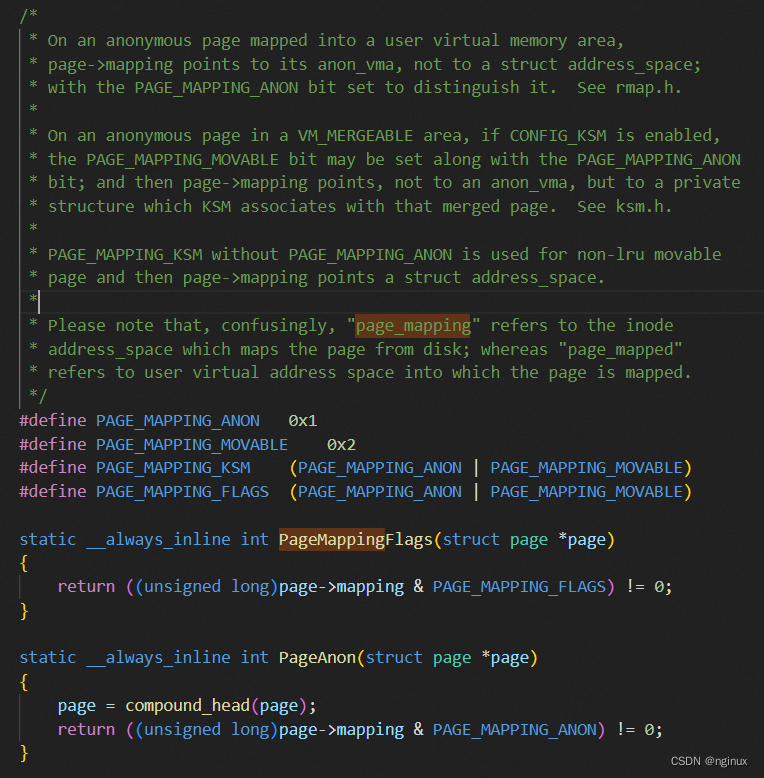
内核这么处理就可以通过page->mapping的判定是否是Anone page,正如上面的PageAnon函数实现。
内核如何判定non-lru page movable?
上面绕了一圈,总结起来就是driver需要通过page->mapping的低两位上设置PAGE_MAPPING_MOVABLE告诉kernel non-lru page是movable的,kernel同时增加了__PageMovable判定这种non-lru page是否可以movable:

注意:
1. LRU pages never can have PAGE_MAPPING_MOVABLE in page->mapping。
2. __PageMovable函数不能确保返回值的准确性,要100%准确判定non-lru page是否movable需要使用PageMovable函数:
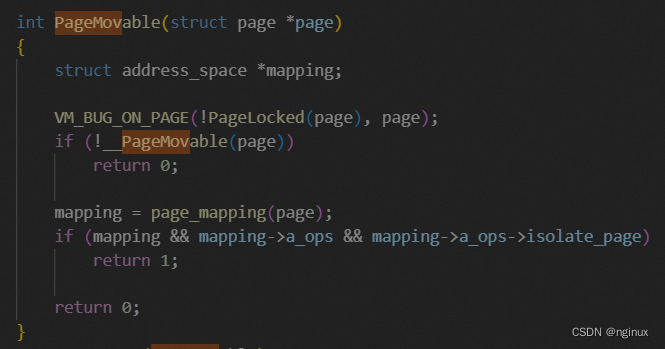
但是由于__PageMovable更速度轻量,且LRU中的page不可能设置PAGE_MAPPING_MOVABLE ,所以内核往往这样使用这两个函数:
1. __PageMovable判定page是否在LRU当中:
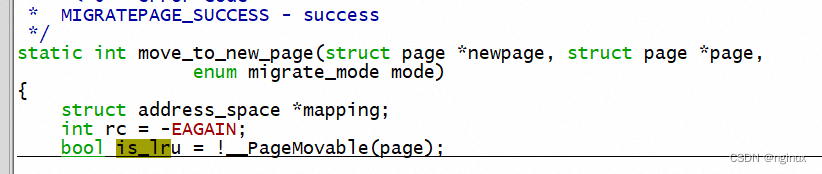
2. 先调用轻量级的__PageMovable判定movable,再通过PageMovable进一步确认,因为__PageMovable返回false肯定是不movable的,如果返回true,那需要进异步PageMovable判定,由于大概率__PageMovable就判定准确了,少部分降低到PageMovable二次确认,所以性能还是有好处的:
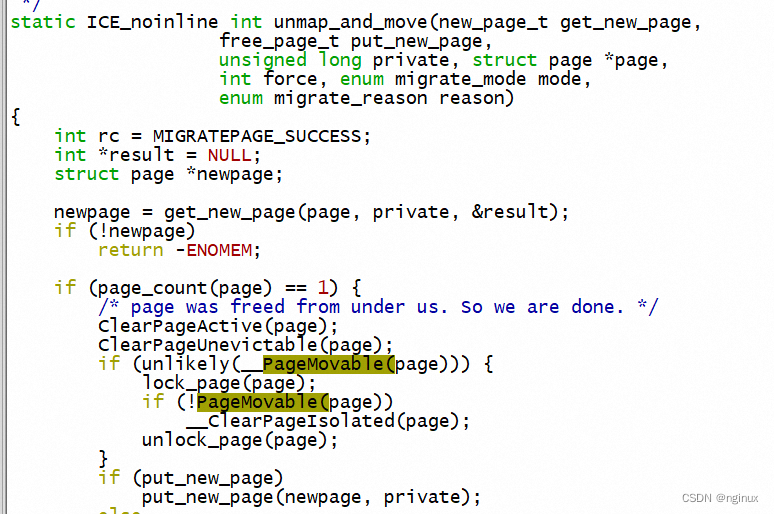
migrate_pages设计逻辑
内核文档介绍该函数实现逻辑如下:

上面步骤还是比较繁琐的,在本小节中我们先抓住重点梳理逻辑,先不陷入源码细节。迁移核心要做几个事情:
- 解除page A的映射,并映射到新page B。由于共享内存等原因,一个page可能被映射给多个进程的VMA里面,所以迁移的时候page可能涉及多个映射的解除。
- address_space的radix tree 从指向A到指向B.
- 新page B对应的flags和内容要和老page A一样。
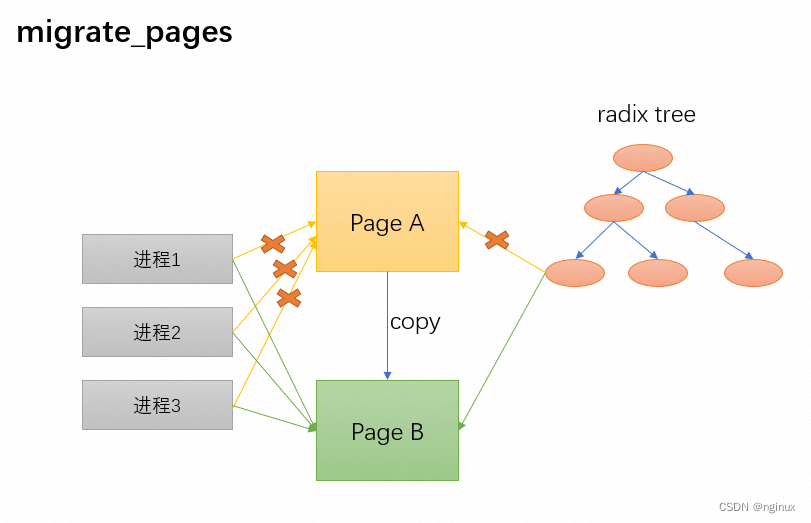
迁移的过程中除了进程1-3依然可能会继续访问Page A,内核内存管理系统其他的部分也可能访问PageA,应该避免内核的内存管理的其他部分干扰迁移。比如正在迁移PageA,内存子系统还在LRU里面扫描A,试图将PageA从inactive Lru移动到active LRU中,那么这就属于骚操作了,所以迁移过程会先通过isolate_lru_page将PageA从LRU中隔离出来,隔离出来之后就可以安心迁移PageA了,因为isolate会组织PageA被释放,也避免LRU的扫描动作,isolate_lru_page参考本文前面的分析。
PageA页面隔离之后,进程访问1-3访问PageA必须是无缝的,不能因为迁移页面就无法运行,当然迁移过程中进程被delay是可以接受的。迁移分3个阶段:
早期:进程的页表项依然指向PageA,此时进程可照常访问A。
中期:PageA已unmap,但是还没map到B,这个阶段属于空窗期,进程无法访问A,此时访问实际会触发缺页中断,然后缺页处理程序就是要等待map B,换个空窗期进程访问会延迟等到。
末期:pageB完成map,唤醒中期中被延迟等待的进程,并能访问到B。
上面中期等待是通过__migration_entry_wait完成:
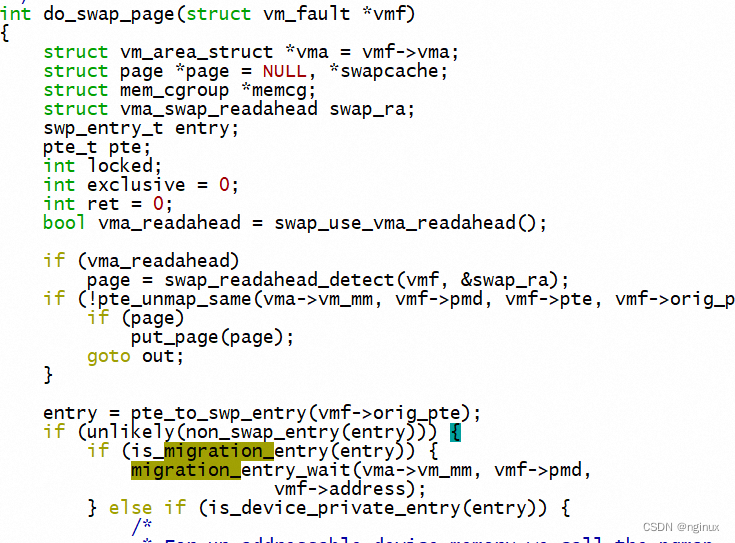
中期阶段的时候,进程访问Page A会触发page fault,其此时会进程is_migration_entry逻辑(设置成migration entry是在unmap A的时候做的),然后migration_entry_wait等待迁移完成。