文章目录
- 1. 并行处理
- 简要说明
- CompletableFuture是银弹吗?
- 测试案例
- 测试结论
- 半异步,半同步
- 总结
- 2. 最小化事务范围
- 简要说明
- 编程式事务模板
- 3. 缓存
- 简要说明
- 4. 合理使用线程池
- 简要说明
- 使用场景
- 线程池的创建
- 参数的配置建议
- 线程池的监控
- 线程池的资源隔离
- 5. 服务预热
- 线程池
- Web服务
- 连接池
- 缓存
- 静态代码块
- 其他扩展
- 6. 缓存对齐
- CPU的多级缓存
- 效果演示
- 缓存行对齐
- 7. 减少对象的产生
- 避免使用包装类型
- 使用不可变对象
- 静态方法
- 视图
- 对象池
- 8. 并发处理
- 锁的粒度控制
- volatile
- CAS
- 对象锁、类锁
- 自旋锁
- 分段锁
- 读写锁
- 写时复制
- 9. 异步
- 10. for循环优化
- 减少循环
- 批量获取
- 缓存结果
- 并行处理
- 11. 减少网络传输的体积
- 精简字段
- 数据传输格式
- 压缩
- 12. 减少服务之间的依赖
- 链路治理
- 数据冗余
- 结果缓存
- 消息队列
1. 并行处理
简要说明
举个例子:在价格查询链路中,我们需要获取多种独立的价格配置项信息,如基础价、折扣价、商户活动价、平台活动价等等。为了加快处理速度,可以使用多线程并行处理的方式,利用并发计算的优势。而CompletableFuture是一种流行的实现多线程的方式,它可以轻松地管理线程的创建、执行和回调,提高程序的可扩展性和并发性。
然而,多线程的使用也存在一些弊端,例如硬件资源的限制和线程间的通信开销等。因此,我们需要在使用多线程的同时,考虑到I/O密集型和CPU密集型的差异,以避免过度开启线程导致性能下降。同时,对于线程池的运行情况,我们也需要有一定的了解和控制,以确保程序的高效稳定运行。
CompletableFuture是银弹吗?
我们常说“手拿锤子看什么都像钉子”,使用CompletableFuture的确能够帮助我们解决许多独立处理逻辑的问题,但是如果使用过多的线程,反而会导致线程调度时间不能得到保障,线程会被浪费在等待CPU时间片上,特别是对于那些本来执行速度就很快的任务,使用CompletableFuture之后反而会拖慢整体执行时长。
因此,在使用CompletableFuture时,我们需要根据具体的场景和任务,仔细考虑是否需要并行处理。如果需要并行处理,我们需要根据任务的性质和执行速度,选择合适的线程池大小和并行线程数量,以避免线程调度时间的浪费和执行效率的下降。
测试案例
执行a,b,c,d4个方法,比较同步执行与异步执行的耗时情况。
全同步执行
private void test() {
long s = System.currentTimeMillis();
a(10);
b(10);
c(10);
d(10);
long e = System.currentTimeMillis();
System.out.println(e - s);
}
public void a(int time) {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void b(int time) {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void c(int time) {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void d(int time) {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
全异步执行
private void test2() {
long s = System.currentTimeMillis();
List<CompletableFuture<?>> completableFutureList = new ArrayList<>();
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
a(10);
});
completableFutureList.add(future1);
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
b(10);
});
completableFutureList.add(future2);
CompletableFuture<Void> future3 = CompletableFuture.runAsync(() -> {
c(10);
});
completableFutureList.add(future3);
CompletableFuture<Void> future4 = CompletableFuture.runAsync(() -> {
d(10);
});
completableFutureList.add(future4);
CompletableFuture<?>[] futures = completableFutureList.toArray(new CompletableFuture[0]);
CompletableFuture<Void> futureAll = CompletableFuture.allOf(futures);
futureAll.join();
long e = System.currentTimeMillis();
System.out.println(e - s);
}
结果统计
| P99 | P90 | P50 | |
|---|---|---|---|
| 4个方法全异步 | |||
| 并发50、每个方法5ms,全异步 | 25ms | 25ms | 20ms |
| 并发50、每个方法10ms,全异步 | 70ms | 60ms | 50ms |
| 并发50、每个方法50ms,全异步 | 250ms | 190ms | 120ms |
| 4个方法全同步 | |||
| 并发50、每个方法5ms,全同步 | 20ms | 20ms | 20ms |
| 并发50、每个方法10ms,全同步 | 60ms | 60ms | 60ms |
| 并发50、每个方法50ms,全同步 | 250ms | 250ms | 250ms |
| 2个方法全异步 | |||
| 并发50、每个方法5ms,全异步 | 15ms | 15ms | 12ms |
| 并发50、每个方法10ms,全异步 | 40ms | 40ms | 20ms |
| 并发50、每个方法50ms,全异步 | 130ms | 130ms | 70ms |
| 2个方法全同步 | |||
| 并发50、每个方法5ms,全同步 | 10ms | 10ms | 10ms |
| 并发50、每个方法10ms,全同步 | 40ms | 40ms | 40ms |
| 并发50、每个方法50ms,全同步 | 125ms | 125ms | 125ms |
测试结论
在分配了相对合理的线程池的情况下,通过以上分析,可以得出下列两个结论:
- 方法耗时越少,同步比异步越好。
- 方法数量越少,同步比异步越好。
半异步,半同步
有时候,如果方法较多,为了减少高并发时P99较高,我们可以让耗时多的方法异步执行,耗时少的方法同步执行。
通过以下数据可以看出,耗时是差不多的,但可以节省不少线程资源。
| P99 | P90 | P50 | |
|---|---|---|---|
| 耗时多异步,耗时少同步 | |||
| 并发50、a,b方法50ms;c,d方法5ms;a,b异步;c,d同步 | 70ms | 70ms | 70ms |
| 并发50、a,b方法50ms;c,d方法10ms;a,b异步;c,d同步 | 100ms | 100ms | 100ms |
| 全异步 | |||
| 并发50、a,b方法50ms;c,d方法5ms;a,b异步;c,d同步 | 70ms | 70ms | 70ms |
| 并发50、a,b方法50ms;c,d方法10ms;a,b异步;c,d同步 | 90ms | 90ms | 80ms |
总结
CompletableFuture提供了一种优雅而强大的方式来处理并发请求和任务。然而,正如在处理高并发时使用过多的线程会导致资源浪费和效率下降一样,使用过多的 CompletableFuture 也会导致同样的问题。这种现象被称为 “线程调度问题”,它会导致性能下降和吞吐量下降(P99值较高)。因此,我们需要在使用 CompletableFuture 时考虑实际场景和负载情况,并根据需要使用恰当的技术来优化性能。
2. 最小化事务范围
简要说明
首先,我们需要明确的是,事务的存在势必会对性能产生影响,特别是在高并发的情况下,因为锁的竞争,会带来极大的性能损耗。因此,在处理数据交互的过程中,我们始终坚持尽可能地减少事务的范围,从而提升接口的响应速度。
一般来说,我们可以利用@Transactional注解轻松实现事务的控制。但是,由于@Transactional注解的最小粒度仅限于方法级别,因此,为了更好地控制事务的范围,我们需要通过编程式事务来实现。
在编程式事务中,我们可以更灵活地控制事务的开启和结束,以及对数据库操作的处理。通过适当的设置事务参数和操作规则,我们可以实现事务的最小化,从而提升系统的性能和可靠性。
编程式事务模板
public interface TransactionControlService {
/**
* 事务处理
*
* @param objectLogicFunction 业务逻辑
* @param <T> result type
* @return 处理结果
* @throws Exception 业务异常信息
*/
<T> T execute(ObjectLogicFunction<T> objectLogicFunction) throws Exception;
/**
* 事务处理
*
* @param voidLogicFunction 业务逻辑
* @throws Exception 业务异常信息
*/
void execute(VoidLogicFunction voidLogicFunction) throws Exception;
}
@Service
public class TransactionControlServiceImpl implements TransactionControlService {
@Autowired
private PlatformTransactionManager platformTransactionManager;
@Autowired
private TransactionDefinition transactionDefinition;
/**
* 事务处理
*
* @param businessLogic 业务逻辑
* @param <T> result type
* @return 处理结果
* @throws Exception 业务异常信息
*/
@Override
public <T> T execute(ObjectLogicFunction<T> businessLogic) throws Exception {
TransactionStatus transactionStatus = platformTransactionManager.getTransaction(transactionDefinition);
try {
T resp = businessLogic.logic();
platformTransactionManager.commit(transactionStatus);
return resp;
} catch (Exception e) {
platformTransactionManager.rollback(transactionStatus);
throw new Exception(e);
}
}
/**
* 事务处理
*
* @param businessLogic 业务逻辑
*/
@Override
public void execute(VoidLogicFunction businessLogic) throws Exception {
TransactionStatus transactionStatus = platformTransactionManager.getTransaction(transactionDefinition);
try {
businessLogic.logic();
platformTransactionManager.commit(transactionStatus);
} catch (Exception e) {
platformTransactionManager.rollback(transactionStatus);
throw new Exception(e);
}
}
}
transactionControlService.execute(() -> {
// 把需要事务控制的业务逻辑写在这里即可
});
3. 缓存
简要说明
缓存,这一在性能提升方面堪称万金油的技术手段,它的重要性在各种计算机应用领域中无可比拟。
缓存作为一种高效的数据读取和写入的优化方式,被广泛应用于各种领域,包括电商、金融、游戏、直播等。
虽然在网络上关于缓存的文章不胜枚举,但要想充分发挥缓存的作用,需要针对具体的业务场景进行深入分析和探讨。因此,在本节中,我们将不过多赘述缓存的具体使用方法,而是重点列举一些使用缓存时的注意事项.
使用缓存时的注意事项
- 缓存过期时间:设置合适的过期时间可以保证缓存的有效性,但过期时间过长可能会浪费内存空间,过期时间过短可能会导致频繁刷新缓存,影响性能。
- 缓存一致性:如果缓存的数据与数据库中的数据不一致,可能会导致业务逻辑出现问题。因此,在使用缓存时需要考虑缓存一致性的问题。
- 缓存容量限制:缓存容量有限,如果缓存的数据量过大,可能会导致内存溢出或者缓存频繁清理。因此,在使用缓存时需要注意缓存容量的限制。
- 缓存需要考虑负载均衡:在高并发场景下,需要考虑缓存的负载均衡问题,避免某些缓存服务器因为热点数据等问题负载过重导致系统崩溃或者响应变慢。
- 缓存需要考虑并发读写:当多个用户同时访问缓存时,需要考虑并发读写的问题,避免缓存冲突和数据一致性问题。
- 缓存穿透问题:当大量的查询请求都无法命中缓存时,导致每次查询都会落到数据库上,从而造成数据库压力过大。
- 缓存击穿问题:当缓存数据失效后,导致大量的请求直接打到数据库中,从而造成数据库压力过大。
- 查询时间复杂度:需额外注意缓存查询的时间复杂度问题,如果是O(n),甚至更差的时间复杂度,则会因为缓存的数据量增加而跟着增加。
考虑到这些问题通常优化的手段
- 数据压缩:选择合理的数据类型,举个例子:如果用Integer[] 和int[]来比较,Integer占用的空间大约是int的4倍。其他情况下,使用一些常见数据编码压缩技术也是常见的节省内存的方式,比如:BitMap、字典编码等。
- 预加载:当行为可预测时,那么提前加载便可解决构建缓存时的压力。
- 热点数据:热点数据如果不能打散,那么通常就会构建多级缓存,比如将应用服务设为一级缓存,Redis设为二级缓存,一级缓存,缓存全量热点数据,从而实现压力分摊。
- 缓存穿透、击穿:针对命中不了缓存的查询也可以缓存一个额外的标识;而针对缓存失效,要么就在失效前,主动刷新一次,要么就分散失效时间,避免大量缓存同时失效。
- 时间复杂度:在设计缓存时,优先考虑选择常数级的时间复杂度的方法。
4. 合理使用线程池
简要说明
在本文开始提到的使用CompletableFuture并行处理时,实际上就已经使用到线程池了,池化技术的好处,我想应该不用再过多阐述了,但关于线程池的使用还是有很多注意点的。
使用场景
异步任务
简单来说就是某些不需要同步返回业务处理结果的场景,比如:短信、邮件等通知类业务,评论、点赞等互动性业务。
并行计算
就像MapReduce一样,充分利用多线程的并行计算能力,将大任务拆分为多个子任务,最后再将所有子任务计算后的结果进行汇总,ForkJoinPool就是JDK中典型的并行计算框架。
同步任务
前面讲到的CompletableFuture使用,就是典型的同步改异步的方式,如果任务之间没有依赖,那么就可以利用线程,同时进行处理,这样理论上就只需要等待耗时最长的步骤结束即可(实际情况可参考CompletableFuture分析)。
线程池的创建
不要直接使用Executors创建线程池,应通过ThreadPoolExecutor的方式,主动明确线程池的参数,避免产生意外。
每个参数都要显示设置,例如像下面这样:
private static final ExecutorService executor = new ThreadPoolExecutor(
2,
4,
1L,
TimeUnit.MINUTES,
new LinkedBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("common-pool-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
参数的配置建议
CorePoolSize(核心线程数)
一般在配置核心线程数的时候,是需要结合线程池将要处理任务的特性来决定的,而任务的性质一般可以划分为:CPU密集型、I/O密集型。
比较通用的配置方式如下
CPU密集型:一般建议线程的核心数与CPU核心数保持一致。
I/O密集型:一般可以设置2倍的CPU核心数的线程数,因为此类任务CPU比较空闲,可以多分配点线程充分利用CPU资源来提高效率。
通过Runtime.getRuntime().availableProcessors()可以获取核心线程数。
另外还有一个公式可以借鉴
线程核心数 = cpu核心数 / (1-阻塞系数)
阻塞系数 = 阻塞时间/(阻塞时间+使用CPU的时间)
实际上大多数线上业务所消耗的时间主要就是I/O等待,因此一般线程数都可以设置的多一点,比如tomcat中默认的线程数就是200,所以最佳的核心线程数是需要根据特定场景,然后通过实际上线上允许结果分析后,再不断的进行调整。
MaximumPoolSize
maximumPoolSize的设置也是看实际应用场景,如果设置的和corePoolSize一样,那就完全依靠阻塞队列和拒绝策略来控制任务的处理情况,如果设置的比corePoolSize稍微大一点,那就可以更好的应对一些有突发流量产生的场景。
KeepAliveTime
由maximumPoolSize创建出来的线程,在经过keepAliveTime时间后进行销毁,依据突发流量持续的时间来决定。
WorkQueue
那么阻塞队列应该设置多大呢?我们知道当线程池中所有的线程都在工作时,如果再有任务进来,就会被放到阻塞队列中等待,如果阻塞队列设置的太小,可能很快队列就满了,导致任务被丢弃或者异常(由拒绝策略决定),如果队列设置的太大,又可能会带来内存资源的紧张,甚至OOM,以及任务延迟时间过长。
所以阻塞队列的大小,又是要结合实际场景来设置的。
一般会根据处理任务的速度与任务产生的速度进行计算得到一个大概的数值。
假设现在有1个线程,每秒钟可以处理10个任务,正常情况下每秒钟产生的任务数小于10,那么此时队列长度为10就足以。
但是如果高峰时期,每秒产生的任务数会达到20,会持续10秒,且任务又不希望丢弃,那么此时队列的长度就需要设置到100。
监控workQueue中等待任务的数量是非常重要的,只有了解实际的情况,才能做出正确的决定。
在有些场景中,可能并不希望因为任务被丢进阻塞队列而等待太长的时间,而是希望直接开启设置的MaximumPoolSize线程池数来执行任务,这种情况下一般可以直接使用SynchronousQueue队列来实现
ThreadFactory
通过threadFactory我们可以自定义线程组的名字,设置合理的名称将有利于你线上进行问题排查。
Handler
最后拒绝策略,这也是要结合实际的业务场景来决定采用什么样的拒绝方式,例如像过程类的数据,可以直接采用DiscardOldestPolicy策略。
线程池的监控
线上使用线程池时,一定要做好监控,以便根据实际运行情况进行调整,常见的监控方式可以通过线程池提供的API,然后暴露给Metrics来完成实时数据统计。
监控示例
线程池自身提供的统计数据
public class ThreadPoolMonitor {
private final static Logger log = LoggerFactory.getLogger(ThreadPoolMonitor.class);
private static final ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 4, 0,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("my_thread_pool_%d").build());
public static void main(String[] args) {
log.info("Pool Size: " + threadPool.getPoolSize());
log.info("Active Thread Count: " + threadPool.getActiveCount());
log.info("Task Queue Size: " + threadPool.getQueue().size());
log.info("Completed Task Count: " + threadPool.getCompletedTaskCount());
}
}
通过micrometer API完成统计,这样就可以接入Prometheus了
package com.springboot.micrometer.monitor;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import io.micrometer.core.instrument.Metrics;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
import java.util.stream.IntStream;
@Component
public class ThreadPoolMonitor {
private static final ThreadPoolExecutor threadPool = new ThreadPoolExecutor(4, 8, 0,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("my_thread_pool_%d").build(), new ThreadPoolExecutor.DiscardOldestPolicy());
/**
* 活跃线程数
*/
private AtomicLong activeThreadCount = new AtomicLong(0);
/**
* 队列任务数
*/
private AtomicLong taskQueueSize = new AtomicLong(0);
/**
* 完成任务数
*/
private AtomicLong completedTaskCount = new AtomicLong(0);
/**
* 线程池中当前线程的数量
*/
private AtomicLong poolSize = new AtomicLong(0);
@PostConstruct
private void init() {
/**
* 通过micrometer API完成统计
*
* gauge最典型的使用场景就是统计:list、Map、线程池、连接池等集合类型的数据
*/
Metrics.gauge("my_thread_pool_active_thread_count", activeThreadCount);
Metrics.gauge("my_thread_pool_task_queue_size", taskQueueSize);
Metrics.gauge("my_thread_pool_completed_task_count", completedTaskCount);
Metrics.gauge("my_thread_pool_size", poolSize);
// 模拟线程池的使用
new Thread(this::runTask).start();
}
private void runTask() {
// 每5秒监控一次线程池的使用情况
monitorThreadPoolState();
// 模拟任务执行
IntStream.rangeClosed(0, 500).forEach(i -> {
// 每500毫秒,执行一个任务
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 每个处理一个任务耗时5秒
threadPool.submit(() -> {
try {
TimeUnit.MILLISECONDS.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});
}
private void monitorThreadPoolState() {
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
activeThreadCount.set(threadPool.getActiveCount());
taskQueueSize.set(threadPool.getQueue().size());
poolSize.set(threadPool.getPoolSize());
completedTaskCount.set(threadPool.getCompletedTaskCount());
}, 0, 5, TimeUnit.SECONDS);
}
}
线程池的资源隔离
在生产环境中,一定要注意好资源隔离的问题,尽量不要将不同类型,不同重要等级的任务放入一个线程池中,以免因为线程资源争抢而互相影响。
5. 服务预热
服务预热也是很常见的一种优化手段,例如数据库连接、线程池中的核心线程,缓存等信息可以利用服务启动阶段预先加载,从而避免请求到来后临时构建的耗时。
下面提供一些预加载的方式
线程池
线程池本身提供了相关的API:prestartAllCoreThreads()通过该方法可以提前将核心线程创建好,非常方便。
Web服务
常见的如Tomcat,其本身也用到了线程池,只是其自身已经考虑到了预加载的问题,不需要我们额外处理了。

连接池
连接池常用的一般就是数据库连接池以及Redis连接池,大多数这些连接的客户端也都做了连接提前加载的工作,遇到没有预加载的参考其他客户端方式搞一下即可。
缓存
一般本地缓存可以在每次服务启动时预先加载好,以免出现缓存击穿的情况。
静态代码块
在服务启动时,静态代码块中的相关功能会优先被加载,可以有效避免在运行时再加载的情况。
其他扩展
预热实际上可聊的内容很多,一般有用到池化技术的方式,都是需要预热的,为了能够提升响应性能,将不在内存中的数据提前查好放入内存中,或者将需要计算的数据提前计算好,这都是很容易想到的解决方式,此外还有一些服务端在设计之初就会针对性地对一些热点数据进行特殊处理,比如JVM中的JIT、内存分配比;OS中的page cache;MySQL中的innodb_buffer_pool等,这些一般可以通过流量预热的方式来使其达到最佳状态。
6. 缓存对齐
CPU的多级缓存
CPU缓存通常分为大小不等的三级缓存
来自百度百科对三级缓存分类的介绍:
-
一级缓存都内置在CPU内部并与CPU同速运行,可以有效的提高CPU的运行效率。一级缓存越大,CPU的运行效率越高,但受到CPU内部结构的限制,一级缓存的容量都很小。
-
二级缓存,它是为了协调一级缓存和内存之间的速度。cpu调用缓存首先是一级缓存,当处理器的速度逐渐提升,会导致一级缓存就供不应求,这样就得提升到二级缓存了。二级缓存它比一级缓存的速度相对来说会慢,但是它比一级缓存的空间容量要大。主要就是做一级缓存和内存之间数据临时交换的地方用。
-
三级缓存是为读取二级缓存后未命中的数据设计的—种缓存,在拥有三级缓存的CPU中,只有约5%的数据需要从内存中调用,这进一步提高了CPU的效率。其运作原理在于使用较快速的储存装置保留一份从慢速储存装置中所读取数据并进行拷贝,当有需要再从较慢的储存体中读写数据时,缓存(cache)能够使得读写的动作先在快速的装置上完成,如此会使系统的响应较为快速。
效果演示
逐行写入
public class CacheLine {
public static void main(String[] args) {
int[][] arr = new int[10000][10000];
long s = System.currentTimeMillis();
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[i].length; j++) {
arr[i][j] = 0;
}
}
long e = System.currentTimeMillis();
System.out.println(e-s);
}
}
逐列写入
public class CacheLine {
public static void main(String[] args) {
int[][] arr = new int[10000][10000];
long s = System.currentTimeMillis();
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr[i].length; j++) {
arr[j][i] = 0;
}
}
long e = System.currentTimeMillis();
System.out.println(e-s);
}
}
虽然两种方式得到的结果是一样的,但性能对比却相差巨大,这就是缓存行带来的影响。
原因分析
CPU的缓存是由多个缓存行组成的,以缓存行为基本单位,一个缓存行的大小一般为64字节,二维数组在内存中保存时,实际上是以按行遍历的方式进行保存,比如:arr[0][0],arr[0][1],arr[1][0],arr[1][1],arr[2][0],arr[2][1]...
所以当按行访问时,是按照内存存储的顺序进行访问,那么CPU缓存后面的元素就可以利用到,而如果是按列访问,那么CPU的缓存是没有用的。
缓存行对齐
public class CacheLinePadding {
private static class Padding {
// 一个long是8个字节,一共7个long
// public volatile long p1, p2, p3, p4, p5, p6, p7;
}
private static class T extends Padding {
// x变量8个字节,加上Padding中的变量,刚好64个字节,独占一个缓存行。
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (long i = 0; i < 10000000; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < 10000000; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 100000);
}
}
同样的含有public volatile long p1, p2, p3, p4, p5, p6, p7;这一行代码与不含性能也相差巨大,这同样也是因为缓存行的原因,当运行在两个不同CPU上的两个线程要写入。
7. 减少对象的产生
避免使用包装类型
因为包装类型的创建和销毁都会产生临时对象,因此相比基本数据类型来说,会带来额外的消耗。
public class Main {
public static void main(String[] args) {
long s = System.currentTimeMillis();
testInteger();
long e = System.currentTimeMillis();
System.out.println(e - s);
testInt();
long e2 = System.currentTimeMillis();
System.out.println(e2 - e);
}
private static void testInt() {
int sum = 1;
for (int i = 1; i < 50000000; i++) {
sum++;
}
System.out.println(sum);
}
private static void testInteger() {
Integer sum = 1;
for (int i = 1; i < 50000000; i++) {
sum++;
}
System.out.println(sum);
}
}
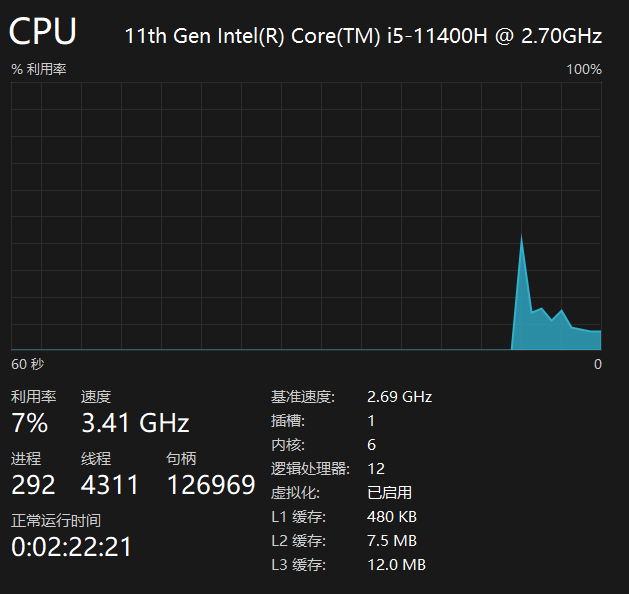
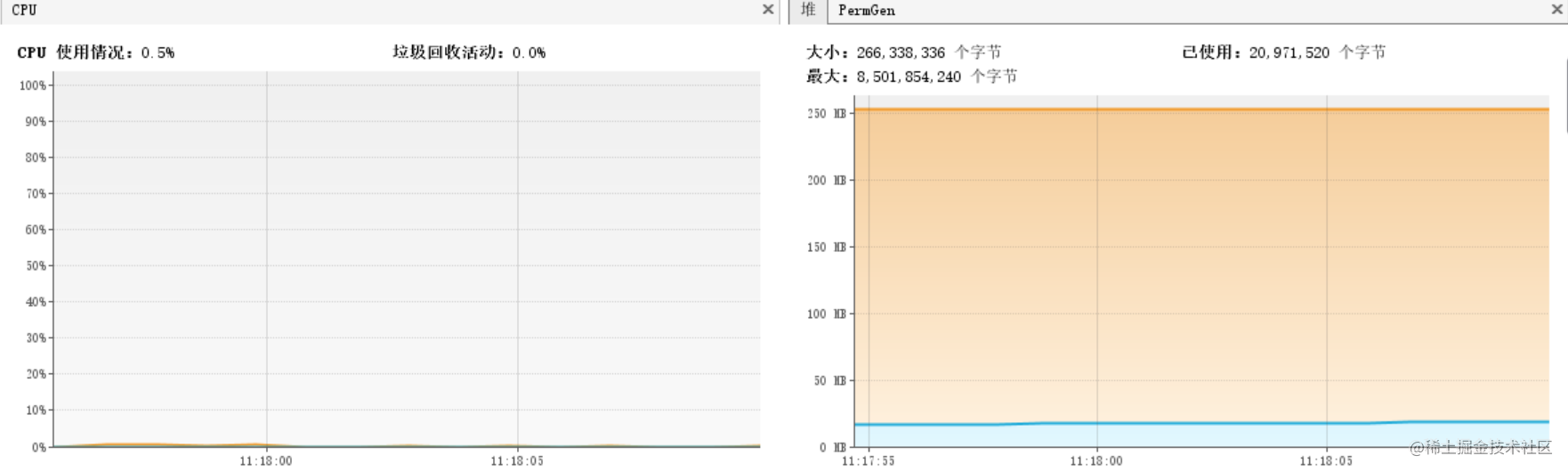
两个方法不仅执行时间相差百倍,在CPU和内存的消耗上Integer也明显弱于int。
Integer内存和CPU都能看到明显的波动

int几乎没波动
使用不可变对象
最为典型的案例就是String,我想应该不会有人去通过new的方式再去构建一个String字符串了吧!
String str = new String("abc");
String str = "abc";
同时,在实现字符串连接时通常使用StringBuilder或StringBuffer,这样可以避免使用连接符,导致每次都创建新的字符串对象。
静态方法
静态对象
Boolean.valueOf("true");
public static Boolean valueOf(String s) {
return parseBoolean(s) ? TRUE : FALSE;
}
public static final Boolean TRUE = new Boolean(true);
public static final Boolean FALSE = new Boolean(false);
静态工厂(单例模式)
public class StaticSingleton {
private static class StaticHolder {
public static final StaticSingleton INSTANCE = new StaticSingleton();
}
public static StaticSingleton getInstance() {
return StaticHolder.INSTANCE;
}
}
枚举
public enum EnumSingleton { INSTANCE; }
视图
视图是返回引用的一种方式。
map的keySet方法,实际上每次返回的都是同一个对象的引用。
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
对象池
对象池可以有效减少频繁的对象创建和销毁的过程,一般情况下如果每次创建对象的过程较为复杂,且对象占用空间又比较大,那么就建议使用对象池的方式来优化。
使用示例
org.apache.commons提供了对象池的工具类,可以直接拿来使用
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.11.1</version>
</dependency>
池化的对象
@Data
public class Cache {
private byte[] size;
}
池化对象工厂
public class CachePoolObjectFactory extends BasePooledObjectFactory<Cache> {
@Override
public Cache create() {
Cache cache = new Cache();
cache.setSize(new byte[1024 * 1024 * 16]);
return cache;
}
@Override
public PooledObject<Cache> wrap(Cache cache) {
return new DefaultPooledObject<>(cache);
}
}
对象池工具
import org.apache.commons.pool2.impl.GenericObjectPool;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import java.time.Duration;
public enum CachePoolUtil {
INSTANCE;
private GenericObjectPool<Cache> objectPool;
CachePoolUtil() {
GenericObjectPoolConfig<Cache> poolConfig = new GenericObjectPoolConfig<>();
// 对象池中最大对象数
poolConfig.setMaxTotal(50);
// 对象池中最小空闲对象数
poolConfig.setMinIdle(20);
// 对象池中最大空闲对象数
poolConfig.setMaxIdle(20);
// 获取对象最大等待时间 默认 -1 一直等待
poolConfig.setMaxWait(Duration.ofSeconds(3));
// 创建对象工厂
CachePoolObjectFactory objectFactory = new CachePoolObjectFactory();
// 创建对象池
objectPool = new GenericObjectPool<>(objectFactory, poolConfig);
}
/**
* 从对象池中取出一个对象
*/
public Cache borrowObject() throws Exception {
return objectPool.borrowObject();
}
public void returnObject(Cache cache) {
// 将对象归还给对象池
objectPool.returnObject(cache);
}
/**
* 获取活跃的对象数
*/
public int getNumActive() {
return objectPool.getNumActive();
}
/**
* 获取空闲的对象数
*/
public int getNumIdle() {
return objectPool.getNumIdle();
}
}
public class Main {
public static void main(String[] args) {
CachePoolUtil cachePoolUtil = CachePoolUtil.INSTANCE;
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@SneakyThrows
@Override
public void run() {
while (true) {
Thread.sleep(100);
// 使用对象池
Cache cache = cachePoolUtil.borrowObject();
m(cache);
cachePoolUtil.returnObject(cache);
// 不使用对象池
//Cache cache = new Cache();
//cache.setSize(new byte[1024 * 1024 * 2]);
//m(cache);
}
}
}).start();
}
}
// 无特殊作用
public static void m(Cache cache) {
if (cache.getSize().length < 10) {
System.out.println(cache);
}
}
}
使用对象池

不适用对象池

8. 并发处理
锁的粒度控制
并发场景下就要考虑线程安全的问题,常见的解决方式:volatile、CAS、自旋锁、对象锁、类锁、分段锁、读写锁,理论上来说,锁的粒度越小,并行效果就越高。
volatile
volatile是Java中的一个关键字,用于修饰变量。它的作用是保证被volatile修饰的变量在多线程环境下的可见性和禁止指令重排序。
volatile虽然不能保证原子性,但如果对共享变量是纯赋值或读取的操作,那么因为volatile保证了可见性,因此也是可以实现线程安全的。
CAS
compare and swap(比较并交换),CAS主要有三个参数,
V:内存值
A:当前时
B:待更新的值
当且仅当V等于A时,就将A更新为B,否则什么都不做。V和A的比较是一个原子性操作保证线程安全。
Random通过cas的方式保证了线程安全,但在高并发下很有可能会失败,造成频繁的重试。
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
ThreadLocalRandom进行了优化,其主要方式就是分段,通过让每个线程拥有独立的存储空间,这样即保证了线程安全,同时效率也不会太差。
public static ThreadLocalRandom current() {
if (U.getInt(Thread.currentThread(), PROBE) == 0)
localInit();
return instance;
}
static final void localInit() {
int p = probeGenerator.addAndGet(PROBE_INCREMENT);
int probe = (p == 0) ? 1 : p; // skip 0
long seed = mix64(seeder.getAndAdd(SEEDER_INCREMENT));
Thread t = Thread.currentThread();
U.putLong(t, SEED, seed);
U.putInt(t, PROBE, probe);
}
public int nextInt() {
return mix32(nextSeed());
}
final long nextSeed() {
Thread t; long r; // read and update per-thread seed
U.putLong(t = Thread.currentThread(), SEED,
r = U.getLong(t, SEED) + GAMMA);
return r;
}
对象锁、类锁
主要就是通过synchronized实现,是最基础的锁机制。
自旋锁
在自旋锁中,当一个操作需要访问一个共享资源时,它会检查这个资源是否被其他操作占用。如果是,它会一直等待,直到资源被释放。在等待期间,这个操作会进入一个自旋状态,也就是不会被系统挂起,但是也不会继续执行其他任务。当资源被释放后,这个操作会立即返回并继续执行下一步操作。
自旋锁是一种简单而有效的同步机制,自旋锁的优点是减少线程上下文切换的开销,但是它也有一些缺点。由于它需要一直进行自旋操作,所以会消耗一定的CPU资源。因此,在使用自旋锁时需要仔细考虑并发问题和性能问题。
分段锁
在分段锁的模型中,共享数据被分割成若干个段,每个段都被一个锁所保护,同时只有一个线程可以在同一时刻对同一段进行加锁和解锁操作。这种锁机制可以降低锁的竞争,提高并发访问的效率。
ConcurrentHashMap的设计就是采用分段锁的思想,其会按照map中的table capacity(默认16)来划分,也就是说每个线程会锁1/16的数据段,这样一来就大大提升了并发访问的效率。
读写锁
读写锁主要根据大多数业务场景都是读多写少的情况,在读数据时,无论多少线程同时访问都不会有安全问题,所以在读数据的时候可以不加锁,不过一旦有写请求时就需要加锁了。
读、读:不冲突
读、写:冲突
写、写:冲突
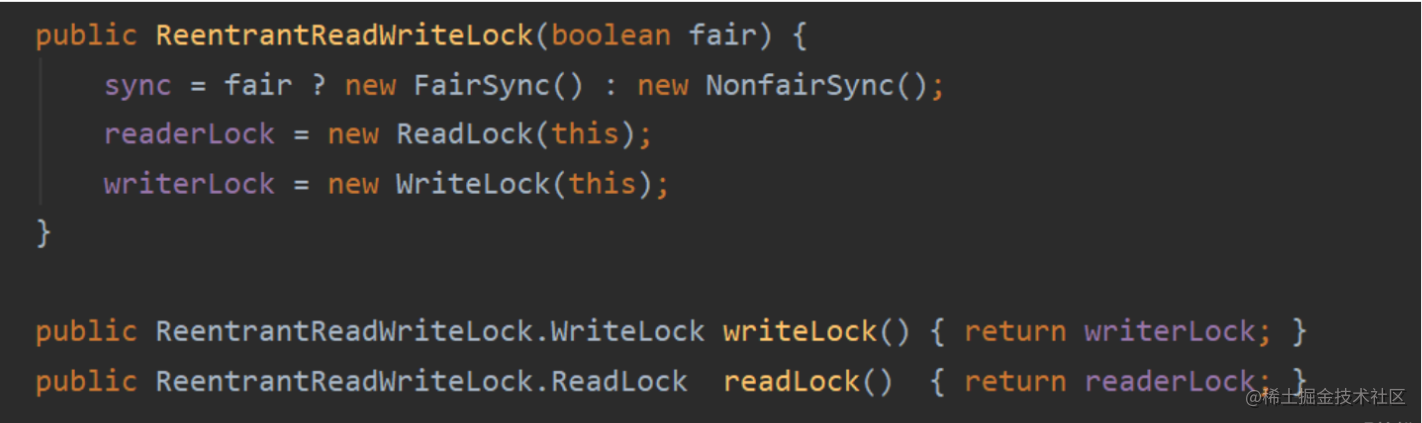
典型的如:ReentrantReadWriteLock
写时复制
写时复制最大的优势在于,在写数据的过程时,不影响读,可以理解为读的是数据的副本,而只有当数据真正写完后才会替换副本,当副本特别大、写数据过程比较漫长时,写时复制就特别有用了。
CopyOnWriteArrayList、CopyOnWriteArraySet就是集合操作时,为保证线程安全,使用写时复制的实现
public E get(int index) {
return elementAt(getArray(), index);
}
final Object[] getArray() {
return array;
}
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1);
es[len] = e;
setArray(es);
return true;
}
}
final void setArray(Object[] a) {
array = a;
}
写时复制也存在两个问题,可以看到在add方法时使用了synchronized,也就是说当存在大量的写入操作时,效率实际上是非常低的,另一个问题就是需要copy一份一模一样的数据,可能会造成内存的异常波动,因此写时复制实际上适用于读多写少的场景。
对比说明
import java.util.Collections;
import java.util.Iterator;
import java.util.Set;
import java.util.UUID;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CopyOnWriteArraySet;
import java.util.concurrent.CountDownLatch;
public class ThreadSafeSet {
public static void main(String[] args) throws InterruptedException {
//Set<String> set = ConcurrentHashMap.newKeySet();
//CopyOnWriteArraySet<String> set = new CopyOnWriteArraySet();
readMoreWriteLess(set);
System.out.println("==========华丽的分隔符==========");
//set = ConcurrentHashMap.newKeySet();
//set = new CopyOnWriteArraySet();
writeMoreReadLess(set);
}
private static void writeMoreReadLess(Set<String> set) throws InterruptedException {
//测20组
for (int k = 1; k <= 20; k++) {
CountDownLatch countDownLatch = new CountDownLatch(10);
long s = System.currentTimeMillis();
//创建9个线程,每个线程向set中写1000条数据
for (int i = 0; i < 9; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
set.add(UUID.randomUUID().toString());
}
countDownLatch.countDown();
}).start();
}
//创建1个线程,每个线程从set中读取所有数据,每个线程一共读取10次。
for (int i = 0; i < 1; i++) {
new Thread(() -> {
for (int j = 0; j < 10; j++) {
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
iterator.next();
}
}
countDownLatch.countDown();
}).start();
}
//阻塞,直到10个线程都执行结束
countDownLatch.await();
long e = System.currentTimeMillis();
System.out.println("写多读少:第" + k + "次执行耗时:" + (e - s) + "毫秒" + ",容器中元素个数为:" + set.size());
}
}
private static void readMoreWriteLess(Set<String> set) throws InterruptedException {
//测20组
for (int k = 1; k <= 20; k++) {
CountDownLatch countDownLatch = new CountDownLatch(10);
long s = System.currentTimeMillis();
//创建1个线程,每个线程向set中写10条数据
for (int i = 0; i < 1; i++) {
new Thread(() -> {
for (int j = 0; j < 10; j++) {
set.add(UUID.randomUUID().toString());
}
countDownLatch.countDown();
}).start();
}
//创建9个线程,每个线程从set中读取所有数据,每个线程一共读取100万次。
for (int i = 0; i < 9; i++) {
new Thread(() -> {
for (int j = 0; j < 1000000; j++) {
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
iterator.next();
}
}
countDownLatch.countDown();
}).start();
}
countDownLatch.await();
long e = System.currentTimeMillis();
System.out.println("读多写少:第" + k + "次执行耗时:" + (e - s) + "毫秒" + ",容器中元素个数为:" + set.size());
}
}
}
经过测试可以发现在读多写少时CopyOnWriteArraySet会明显优于ConcurrentHashMap.newKeySet(),但在写多读少时又会明显弱于ConcurrentHashMap.newKeySet()。
当然使用CopyOnWriteArraySet还需要注意一点,写入的数据可能不会被及时的读取到,因为遍历的是读取之前获取的快照。
这段代码可以测试CopyOnWriteArraySet写入数据不能被及时读取到的问题。
public class COWSetTest {
public static void main(String[] args) throws InterruptedException {
CopyOnWriteArraySet<Integer> set = new CopyOnWriteArraySet();
new Thread(() -> {
try {
set.add(1);
System.out.println("第一个线程启动,添加了一个元素,睡100毫秒");
Thread.sleep(100);
set.add(2);
set.add(3);
System.out.println("第一个线程添加了3个元素,执行结束");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
//保证让第一个线程先执行
Thread.sleep(1);
new Thread(() -> {
try {
System.out.println("第二个线程启动了!睡200毫秒");
//Thread.sleep(200);//如果在这边睡眠,可以获取到3个元素
Iterator<Integer> iterator = set.iterator();//生成快照
Thread.sleep(200);//如果在这边睡眠,只能获取到1个元素
while (iterator.hasNext()) {
System.out.println("第二个线程开始遍历,获取到元素:" + iterator.next());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
9. 异步
异步是提升系统响应能力的重要手段之一,异步思想的应用也非常的广泛,常见的有:线程、MQ、事件通知、响应式编程等方式,有些概念在前面的章节中也涉及到了,异步最核心的思想就是,先快速接收,后查询结果,比如:如果接口处理时间较长,那么可以优先响应中间状态(处理中),然后提供回调和查询接口,这样就可以大大提升接口的吞吐量!
10. for循环优化
减少循环
通常可以通过一些高效的算法或者数据结构来减少循环次数,尤其当出现嵌套循环时要格外小心。
常见的方式比如:有序的查找可以用二分,排序可以用快排,检索可以构建Hash索引等等。
批量获取
优化前:每次查询一次数据库
for(String userId : userIds){
User user = userMapper.queryById(userId);
if(user.getName().equals("xxx")){
// ...
}
}
优化后:先批量查询出来,再处理
Map<String, User> userMap = userMapper.queryByIds(userIds);
for(String userId : userIds){
User user = userMap.get(userId);
if(user.getName().equals("xxx")){
// ...
}
}
缓存结果
优化前:每次都要根据每个用户的roleId去数据库查询一次。
Map<String, User> userMap = userMapper.queryByIds(userIds);
for(String userId : userIds){
User user = userMap.get(userId);
Role role = roleMapper.queryById(user.getRoleId());
}
优化后:每次根据roleId查询过以后就暂记下来,后面再遇到相同roleId时即可直接获取,这比较适用于一次循环中roleId重复次数较多的场景。
Map<String, User> userMap = userMapper.queryByIds(userIds);
Map<String, Role> roleMap = new HashMap<>();
for(String userId : userIds){
User user = userMap.get(userId);
Role role = roleMap.get(user.getRoleId());
if(role == null){
role = roleMapper.queryById(user.getRoleId());
roleMap.put(user.getRoleId(), role);
}
}
并行处理
典型的如parallelStream
Integer sum = numbers.parallelStream().reduce(0, Integer::sum);
11. 减少网络传输的体积
精简字段
1.数据库查询时要避免频繁查询大文本字段,常见的如下面几种:select url, describe, remark from t
2.接口传输时同样要注意尽量减少内容传输的大小。
3.精简字段除了通过减少不必要的字段传输之外,也可以通过改变数据结构,数据类型来实现。
数据传输格式
常用的如JSON,语法简单,相比XML来说传输体积更小,解析更快,但如果需要频繁传输大量数据时,使用protobuf则更会更加高效,因为其采用结构化的数据描述语言,并使用二进制编码,因为体积更小,速度更快。
压缩
常见的数据压缩方式如:GZIP、zlib,而zip常用于文件压缩。
借助Hutool工具包,可以看下压缩的效果
gzip压缩
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 1000; i++) {
sb.append(i);
}
System.out.println("压缩前:" + sb.toString().getBytes().length);
byte[] compressedBytes = ZipUtil.gzip(sb.toString(), CharsetUtil.UTF_8);
System.out.println("压缩后:" + compressedBytes.length);
String str = ZipUtil.unGzip(compressedBytes, CharsetUtil.UTF_8);
System.out.println("压缩还原:" + str.getBytes().length);
压缩前:2890
压缩后:1474
压缩还原:2890
zlib压缩
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 1000; i++) {
sb.append(i);
}
System.out.println("压缩前:" + sb.toString().getBytes().length);
byte[] compressedBytes = ZipUtil.zlib(sb.toString(), CharsetUtil.UTF_8, 1);
System.out.println("压缩后:" + compressedBytes.length);
String str = ZipUtil.unZlib(compressedBytes, CharsetUtil.UTF_8);
System.out.println("压缩还原:" + str.getBytes().length);
压缩前:2890
压缩后:1518
压缩还原:2890
12. 减少服务之间的依赖
依赖越多,不但会给服务的稳定性、可靠性造成影响,同时也会成为性能提升的瓶颈,因此我们在设计之初就应当充分考虑到这个问题,通过合理的手段来减少服务之间的依赖。
链路治理
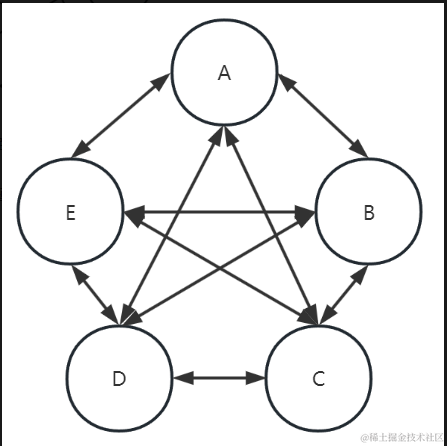
通过合理的微服务划分,可以有效的减少链路上的依赖,链路调用之间要避免出现重复调用,循环依赖,以及上、下层级互相调用的情况。
重复调用

循环依赖

服务上、下层级混乱,互相调用
数据冗余
数据冗余是指将非自身维护的数据通过某种手段保存下来,以便在之后使用时避免多次发起数据请求,从而实现减少服务依赖的手段。
常见的方式如:通用的基础数据,字典数据等各个需求方可复制一份存在本地;建立宽表,冗余部分数据,减少关联查询。
结果缓存
将需要频繁使用的结果存储在缓存服务中,也是有效减少服务依赖的方式之一。
消息队列
消息队列天然就有简化系统复杂性的作用,它通过异步的方式将任务与任务之间的关系进行解耦,也就达到了减少服务之间依赖的效果。