假设如果要启动ML项目,那么您需要做的第一件事也是最重要的事情是什么?这是无涯教程启动任何ML项目都需要加载的数据。关于数据,对于ML项目,最常见的数据格式是CSV(逗号分隔值)。
基本上,CSV是一种简单的文件格式,用于以纯文本格式存储表格数据(数字和文本),如电子表格。在Python中,可以通过不同的方式将CSV数据加载到其中,但是在加载CSV数据之前必须要注意一些注意事项。
加载CSV事项
CSV数据格式是ML数据中最常见的格式,但是在将其加载到ML项目中时,无涯教程需要注意以下主要注意事项。
文件头
在CSV数据文件中,标题包含每个字段的信息。必须对头文件和数据文件使用相同的定界符,因为头文件指定了应如何解释数据字段。
以下是与CSV文件标头有关的两种情况,必须考虑以下两种情况:
情况1 - 当数据文件具有文件头时 ,它将自动为数据的每一列分配名称。
情况2 - 当数据文件没有文件头时 ,需要为数据的每一列手动分配名称。
在这两种情况下都必须明确指定文件是否包含标头。
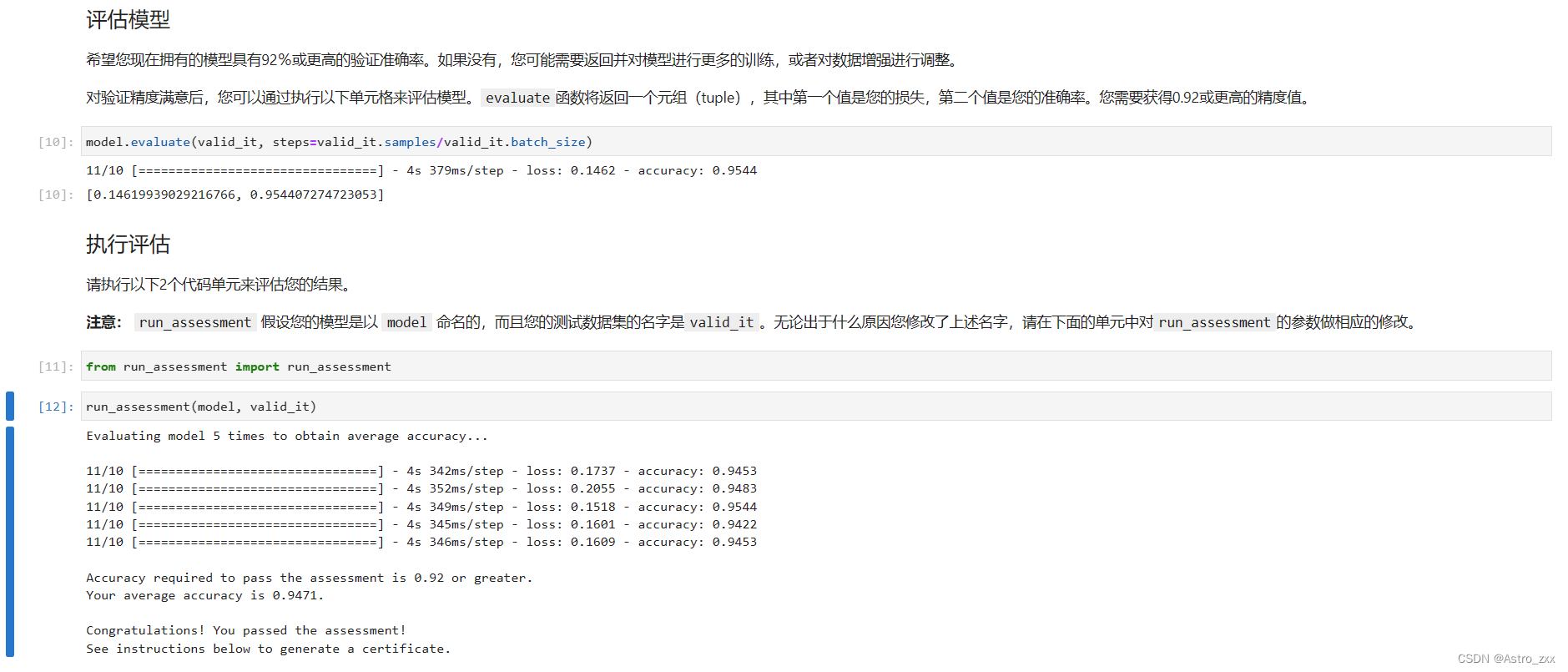
注释
任何数据文件中的注释都具有其重要性,在CSV数据文件中,注释在行的开头用井号(#)表示。在将CSV数据加载到ML项目中时需要考虑注释,因为如果文件中包含注释,则可能需要根据选择的加载方法进行指示。
分隔符
在CSV数据文件中,逗号(,)字符是标准分隔符,分隔符的作用是分隔字段中的值,在将CSV文件上传到ML项目中时,考虑分隔符的作用很重要,因为无涯教程还可以使用其他分隔符,如制表符或空白。但是在使用与标准分隔符不同的分隔符的情况下,必须必须明确指定它。
双引号
在CSV数据文件中,双引号("")是默认的引号字符,将CSV文件上传到ML项目中时,考虑引号的作用很重要,因为还可以使用双引号以外的其他引号字符。但是,如果使用的引号字符与标准引号字符不同,则必须明确指定它。
加载CSV方法
在处理ML项目时,最关键的任务是将数据正确加载到其中。机器学习项目中最常见的数据格式是CSV,它具有多种形式,并且解析起来也有不同的难度。在本节中,无涯教程将讨论有关Python中加载CSV数据文件的三种常见方法-
使用Python加载
加载CSV数据文件的第一个也是最常用的方法是使用Python标准库,该库为无涯教程提供了各种内置模块,即 csv模块和 reader函数。以下是借助它加载CSV数据文件的示例-
首先,需要导入Python标准库提供的csv模块,如下所示-
import csv
接下来,需要导入Numpy模块,以将加载的数据转换为NumPy数组。
import numpy as np
现在,提供包含CSV数据文件的文件的完整路径,该路径存储在本地目录中-
path=r"c:\iris.csv"
接下来,使用csv.reader()函数从CSV文件读取数据-
with open(path,r) as f: reader = csv.reader(f,delimiter = ,) headers = next(reader) data = list(reader) data = np.array(data).astype(float)
可以使用以下脚本行打印标题的名称:
print(headers)
以下行将打印数据的维度,即文件中的行数和列数-
print(data.shape)
下一个脚本行将给出数据文件的前三行-
print(data[:3])
[sepal_length, sepal_width, petal_length, petal_width] (150, 4) [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2]]
使用NumPy加载
加载CSV数据文件的另一种方法是 NumPy 和 numpy.loadtxt()函数,以下是借助它加载CSV数据文件的示例-
在此示例中,使用的是具有糖尿病患者数据的Pima Indians数据集,此数据集是没有标题的数字数据集,也可以将其下载到本地目录中,加载数据文件后,可以将其转换为 NumPy 数组,并将其用于ML项目,以下是用于加载CSV数据文件的Python脚本-
from numpy import loadtxt path = r"C:\pima-indians-diabetes.csv" datapath= open(path, r) data = loadtxt(datapath, delimiter=",") print(data.shape) print(data[:3])
(768, 9) [[ 6. 148. 72. 35. 0. 33.6 0.627 50. 1.] [ 1. 85. 66. 29. 0. 26.6 0.351 31. 0.] [ 8. 183. 64. 0. 0. 23.3 0.672 32. 1.]]
使用Pandas加载
加载CSV数据文件的另一种方法是通过 Pandas 和 pandas.read_csv()函数。这是一个非常灵活的函数,它返回一个pandas.DataFrame,可以立即将其用于绘图。以下是借助它加载CSV数据文件的示例-
在这里,无涯教程将实现两个Python脚本,第一个是使用带有标题的Iris数据集,另一个是使用 Pima Indians Dataset ,它是一个没有标题的数字数据集。这两个数据集都可以下载到本地目录中。
脚本1
以下是使用Iris 数据集上的 Pandas 加载CSV数据文件的Python脚本-
from pandas import read_csv path = r"C:\iris.csv" data = read_csv(path) print(data.shape) print(data[:3])
(150, 4) sepal_length sepal_width petal_length petal_width 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2
脚本2
以下是使用Pima Indians Diabetes数据集上的Pandas加载CSV数据文件以及提供标头名称的Python脚本-
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = [preg, plas, pres, skin, test, mass, pedi, age, class] data = read_csv(path, names=headernames) print(data.shape) print(data[:3])
(768, 9) preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1
借助给定的示例,可以轻松理解上面使用的三种加载CSV数据文件的方法之间的区别。
机器学习 - 数据加载 - 无涯教程网无涯教程网提供假设如果要启动ML项目,那么您需要做的第一件事也是最重要的事情是什么?这是无涯教程... https://www.learnfk.com/python-machine-learning/machine-learning-with-python-data-loading-for-ml-projects.html
https://www.learnfk.com/python-machine-learning/machine-learning-with-python-data-loading-for-ml-projects.html

![[论文分享]Skip-Attention: Improving Vision Transformers by Paying Less Attention](https://img-blog.csdnimg.cn/8dd7c24331874428ba5b4a727e324980.png)