Skip-Attention: Improving Vision Transformers by Paying Less Attention
这项工作旨在提高视觉transformer(ViT)的效率。
虽然 ViT 在每一层都使用计算昂贵的自我注意操作,但我们发现这些操作在各层之间高度相关——这是导致不必要的计算的关键冗余。基于这一观察结果,我们提出了SKIPAT,一种重用前一层的自我注意力计算来近似一个或多个后续层注意力的方法。
为了确保跨层重用自注意力块不会降低性能,我们引入了一个简单的参数函数,它的性能优于基线transformer的性能,同时计算速度更快。
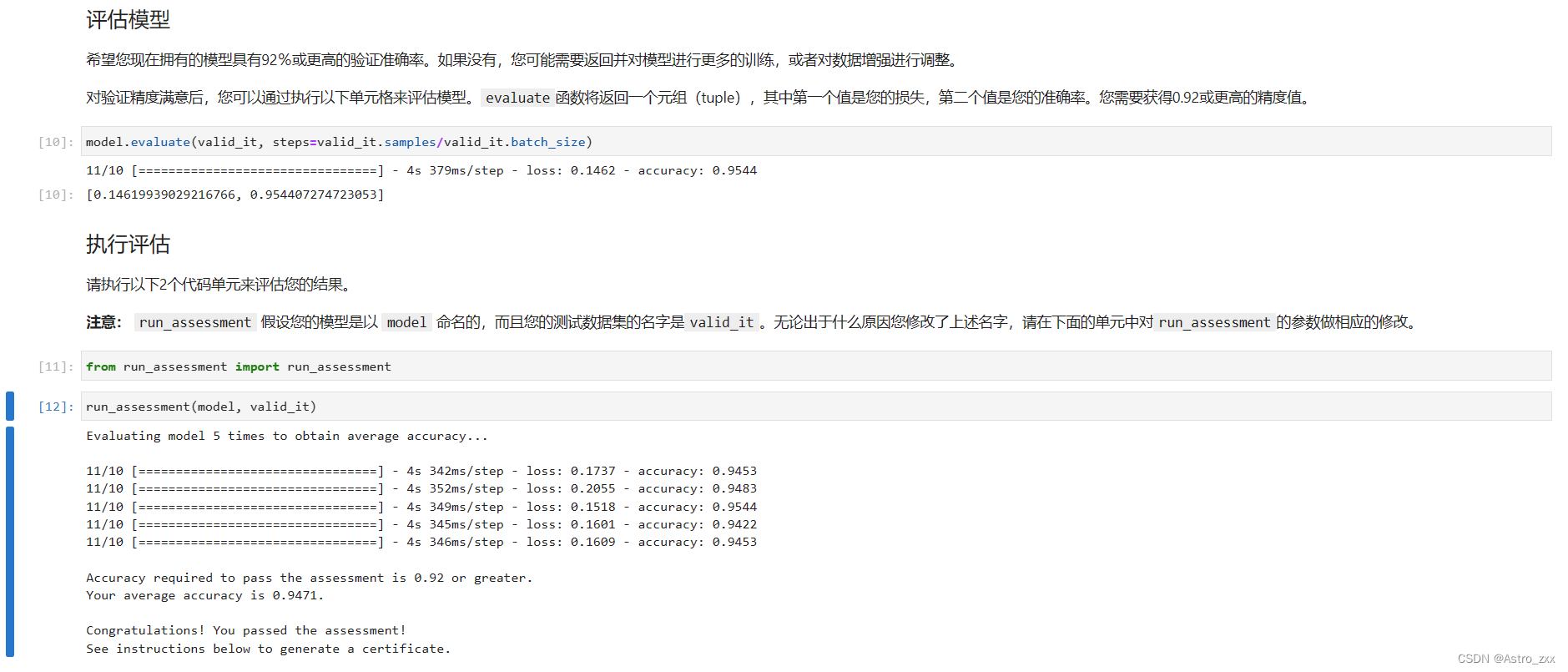
我们展示了我们的方法在ImageNet-1K上的图像分类和自监督学习,ADE20K上的语义分割,SIDD上的图像去噪和DAVIS上的视频去噪方面的有效性。我们在所有这些任务中以相同或更高的精度水平实现了更高的吞吐量。
主要贡献
- 我们提出了一种新颖的插件模块,可以在任何ViT架构中安装,以减少昂贵的O(n2)自我注意力计算
- 我们在ImageNet,Pascal-VOC2012,SIDD,DAVIS和ADE20K的吞吐量方面实现了最先进的性能,精度相同或更好(在后者中,我们获得了40%的加速)
- 我们通过减少26%的自监督预训练时间(无下游精度损失)和展示卓越的设备上延迟(进一步证明了我们方法的通用性。
- 最后,我们分析了性能提升的来源,并广泛消融了我们的方法,以提供一个可用于权衡准确性和吞吐量的模型系列
方法

3.2. 动机:层相关性分析
注意力图关联(Attention-map correlation)。ViT 中的 MSA 块将每个补丁与其他每个补丁的相似性编码为 n × n 个注意力矩阵。该运算符的计算成本很高,复杂度为 O(n2)。随着 ViT 的扩展,即随着 n 的增加,复杂性呈二次增长,并且此操作成为瓶颈。最近的NLP工作[51,52]表明,SoTA语言模型中相邻层之间的自我注意表现出非常高的相关性。这就提出了一个问题——是否值得在视觉transformer的每一层计算自我注意力?
为了解决这个问题,我们分析了ViT不同层之间自我注意图的相关性。如图 2 所示,来自类标记 A[CLS] 的自注意力映射表现出高度相关性,尤其是在中间层中。 和 之间的余弦相似度可以高达 0. 97。如图2中每个注意力图的底部所示。从其他token embeddings(嵌入)中也观察到类似的行为,我们在补充材料中对其进行了分析。我们通过计算每个 i,j ∈ L 之间的中心核对齐 (CKA) [12, 27] 来定量分析 ImageNet-1K 验证集所有样本的这种相关性 。CKA 测量从网络的中间层获得的表示之间的相似性,其中 CKA 的高值表示表示之间的高度相关性。从图 3(a)中,我们观察到ViT-T在A[CLS]之间具有很高的相关性,尤其是从第3层到第10层。
特征关联(Feature correlation)。在ViT中,高相关性不仅限于A[CLS],而且MSA块ZMSA的表示在整个模型中也显示出高相关性[42]。为了分析这些表示之间的相似性,我们计算了每个i,j∈L的Z iMSA和ZjMSA之间的CKA。我们从图3(b)中观察到,ZMSA在模型的相邻层之间也具有很高的相似性,特别是在早期层中,即从第2层到第8层。
3.3. 通过跳过注意力来提高效率
基于我们对transformer的MSA块之间高表示相似性的观察(小节3.2),我们建议利用注意力矩阵和MSA块表示之间的相关性来提高视觉transformer的效率。我们不是在每一层独立计算MSA操作(3),而是探索一种简单有效的策略来利用这些层的特征之间的依赖关系。
特别是,我们建议通过重用其相邻层的表示来跳过transformer的一个或多个层中的MSA计算。我们将此操作称为“跳过注意”或“SKIPAT”。由于跳过整个 MSA 块的计算和内存优势大于仅跳过自注意操作 (O(n2d+nd2) 与O(n2d)),在本文中,我们专注于前者。然而,我们不是直接重用特征,即将特征从源 MSA 块复制到一个或多个相邻的 MSA block,而是引入了参数函数。参数函数确保直接重用特征不会影响这些 MSA 块中的平移不变性和等方差,并充当强大的正则化器来改进模型泛化。


实验结果
图像分类
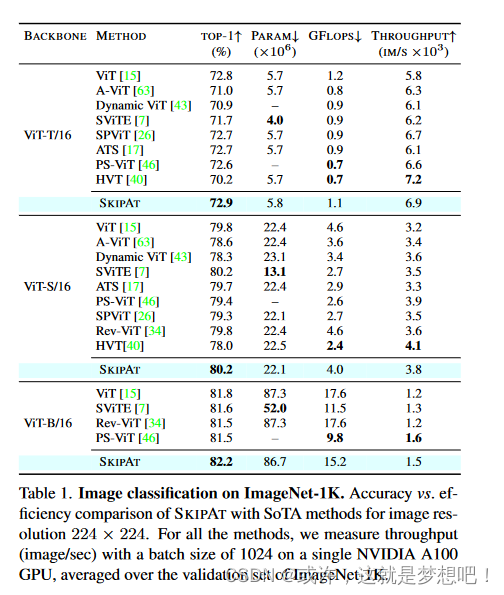
从表1中,我们观察到,与ViT不同变体上的所有SoTA方法相比,S KIPAT实现了最佳的准确性与效率权衡。值得注意的是,我们的性能分别比基线ViT-T、ViT-S和ViT-B高0.1%、 0.4%和0.4%,而SoTA方法的准确度较低或与基线相差无几。由于 SKIPAT 使用参数函数来跳过计算 MSA 块,因此我们在参数数量和 FLOP 方面的减少与 SoTA 相当。在通量方面,S KIPA T 分别比基线 ViT-T、ViT-S 和 ViT-B 快 19%、21% 和 25%。 德加尼等. [13] 强调使用吞吐量作为衡量模型效率的指标的重要性:因为 FLOP 的减少并不一定对应于延迟的改善,因为它没有考虑并行度或其他硬件细节。根据这一论点,我们观察到,虽然 ATS [17] 和 SPViT [26] 等 SoTA 方法实现了 FLOP 的大幅减少,但与 S KIP A T 相比,它们实际上具有较低的吞吐量。此外,HVT [40] 虽然在通量和 FLOP 方面都实现了更高的增益,但 top1 精度较差( ViT-T 下降 2.6%,ViT-S 下降 1.8%)。 因此,SKIPAT 展示了与 SoTA 方法相比同时提高准确性和通量的能力。
自监督学习
接下来,我们使用DINO [5]展示了SKIPA T作为其在自监督表示学习(SSL)骨干中的用途的通用性。由于SSL方法在预训练阶段的计算和训练时间方面非常昂贵,因此我们说明了SKIPAT实现了与使用ViT相当的性能,但训练时间更短。按照DINO [5]的实验设置,我们使用ViT-S/16 [15]作为我们的学生和教师网络,具有SKIPAT参数函数。我们使用DINO预训练基线和我们的100个epoch。我们观察到 SKIPAT 实现了与完全训练的 DINO 几乎相同的性能,训练时间减少了约 26%(96 GPU 小时为 73.3%,131 GPU 小时为 73.6%)。当在100个epoch上训练时,我们观察到SKIPAT比DINO高出0.5%(74.1%对73.6%)。我们在补充材料中展示了 S KIPAT 对下游任务的性能。

语义分割
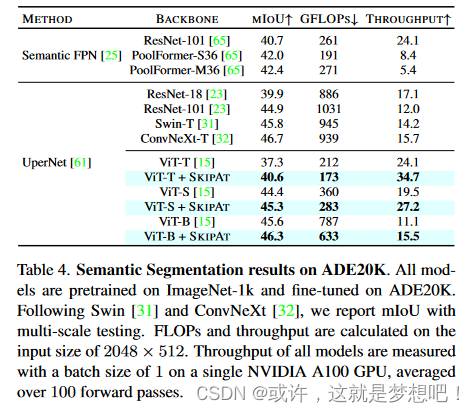
我们超越了分类,展示了 S KIPAT 对语义分割等密集预测任务的性能。我们遵循[31,32]中的实验设置,并使用MMSegmentation [11]在ADE20K[70]上评估SKIPAT 。我们从表4中观察到, SKIPAT 的性能始终优于所有 VIT 系列,FLOP 减少 15%,吞吐量提高 25%。 有趣的是,S KIP A T-S(ViT-S + SKIPA T)的mIoU高出8%, 同时比ViT-T快。此外,SKIPA T S 的 mIoU 与 Swin-T [31] 相当,同时 FLOP 少 3× 个,为 1。7×更快。与完全基于卷积的架构相比,S KIP A T-T(ViT-T + SKIPA T)在mIoU中与ResNet-18相当,同时有4个。 7× 更少的 FLOP 和 1.快 8×。
图像去噪
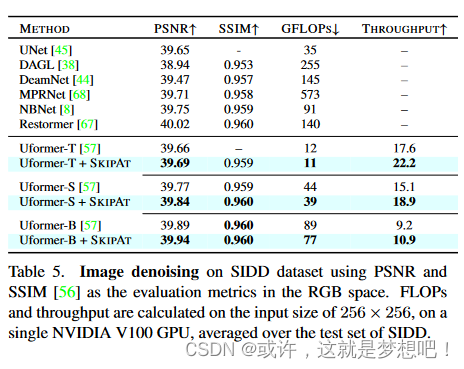
SKIPA T 还可以推广到低级任务,例如 SIDD [1] 上的图像去噪,它由具有真实世界噪声的图像组成。我们还证明了SKIPAT可以推广到其他transformer架构。特别是,我们在SoTA图像去噪模型Uformer [57]上应用了它。Uformer 是一个 U 形分层网络,以 Swin transformer块作为编码器和解码器,并跳过它们之间的连接。在 S KIP A T 中,我们通过 S KIPA T 参数函数重用相应编码器块的注意力,跳过每个解码器块中的窗口自注意 (WSA) 块。具体实施见补充材料。按照[57]中的实验设置,我们在表5中观察到,SKIPAT优于基线Uformer 变体,平均通量高出25%。此外,我们观察到S KIP A T-B(Uformer-B + SKIPAT)在PSNR和SSIM方面实现了与Restormer相当的性能[67],这是SoTA图像去噪方法,同时具有2×更少的FLOP。因此,我们展示了 SKIPAT 泛化到不同任务以及跨架构的能力。
视频去噪
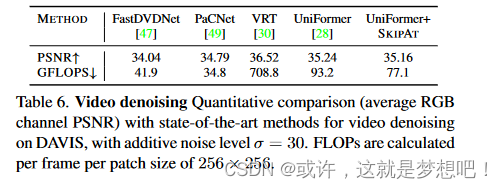
我们进一步将我们的模型应用于视频去噪的时间任务。作为编码器和解码器骨干,我们使用UniFormer [28],这是一种具有3D卷积和时空全局自注意力块的U形混合编码器-解码器架构 。补充材料中提供了详细的词条。与图像去噪类似,我们在解码器中跳过 MSA 块,但是,只需采用朴素的 SKIP A T,其中我们使用 Identity fu nction 重用相应编码器块的窗口自注意矩阵 A。我们凭经验观察到,重用注意力在这个任务中效果更好,并显示了我们的方法应用于不同场景的能力。我们遵循 [47] 中的实验设置,并在 DAVIS [41] 数据集上训练 SKIPAT。我们使用 Charbonnier 损失 [6] 在 7 × 128 × 128 的补丁上使用多输入多输出 (MIMO) 范式(即模型从 7 个输入帧输出 7 个重建帧)进行训练,噪声水平 σ = 30。从表6中,我们观察到SKIPAT的性能与基线均匀器相当,同时FLOP减少了17%。这表明 SKIPAT 可以泛化到时态任务。
结论
我们提出了SKIPAT,一个可以放置在任何ViT架构中的插件模块,以减少昂贵的自我注意力计算。SKIPAT 利用跨 MSA 块的依赖关系,并通过重用先前 MSA 块的注意力来绕过 att ention 计算。为了确保隐喻共享是关怀的,我们引入了一个简单而轻的参数函数,它不会影响MSA中编码的感应偏置。SKIPAT 函数能够处理跨令牌关系,并优于基线,同时在吞吐量和 FLOP 方面计算速度更快。我们将 SKIPAT 插入不同的transformer架构中,并展示了其在 7 个不同任务上的有效性。
reference
[1] VENKATARAMANAN S, GHODRATI A, ASANO Y M, 等. Skip-Attention: Improving Vision Transformers by Paying Less Attention[M/OL]. arXiv, 2023[2023-07-31]. http://arxiv.org/abs/2301.02240. DOI:10.48550/arXiv.2301.02240.