目录
引言:keras与Tensorflow2.0结合
一、六步法
1.导入头文件:import
2.收集处理训练集和测试集:train, test:
3.描述各层网model = tf.keras.models.Sequential:
4.描述使用什么优化反向传播:model.compile
5.训练数据填入:model.fit
6.打印数据:model.summary
二、Sequential()
函数使用
过程1:拉直层
过程2:全连接层
过程3:卷积层
过程4:LSTM层
三、compile()
函数使用
Optimizer可选
loss可选
Metrics可选
四、fit()
函数使用
五、model.summary()
总结:
引言:keras与Tensorflow2.0结合
一、六步法
1.导入头文件:import
2.收集处理训练集和测试集:train, test:
3.描述各层网model = tf.keras.models.Sequential:
4.描述使用什么优化反向传播:model.compile
5.训练数据填入:model.fit
6.打印数据:model.summary
二、Sequential()
函数使用
model = tf.keras.models.Sequential ([ 网络结构 ])
过程1:拉直层
tf.keras.layers.Flatten( )
过程2:全连接层
tf.keras.layers.Dense(神经元个数, activation= "激活函数“ , kernel_regularizer=哪种正则化)
activation(字符串给出)可选: relu、 softmax、 sigmoid 、 tanh kernel_regularizer可选: tf.keras.regularizers.l1()、tf.keras.regularizers.l2()
过程3:卷积层
tf.keras.layers.Conv2D(filters = 卷积核个数, kernel_size = 卷积核尺寸, strides = 卷积步长, padding = " valid" or "same")
过程4:LSTM层
tf.keras.layers.LSTM()
三、compile()
函数使用
model.compile(optimizer = 优化器, loss = 损失函数 metrics = [“准确率”] )
Optimizer可选
‘sgd’ or tf.keras.optimizers.SGD (lr=学习率,momentum=动量参数)
‘adagrad’ or tf.keras.optimizers.Adagrad (lr=学习率)
‘adadelta’ or tf.keras.optimizers.Adadelta (lr=学习率)
‘adam’ or tf.keras.optimizers.Adam (lr=学习率, beta_1=0.9, beta_2=0.999)
loss可选
‘mse’ or tf.keras.losses.MeanSquaredError()
tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
Metrics可选
‘accuracy’ :y_和y都是数值,如y_=[1] y=[1]
‘categorical_accuracy’ :y_和y都是独热码(概率分布),如y_=[0,1,0] y=[0.256,0.695,0.048]
‘sparse_categorical_accuracy’ :y_是数值,y是独热码(概率分布),如y_=[1] y=[0.256,0.695,0.048
四、fit()
函数使用
model.fit (训练集的输入特征, 训练集的标签, batch_size= , epochs= , validation_data=(测试集的输入特征,测试集的标签), validation_split=从训练集划分多少比例给测试集, validation_freq = 多少次epoch测试一次)
五、model.summary()
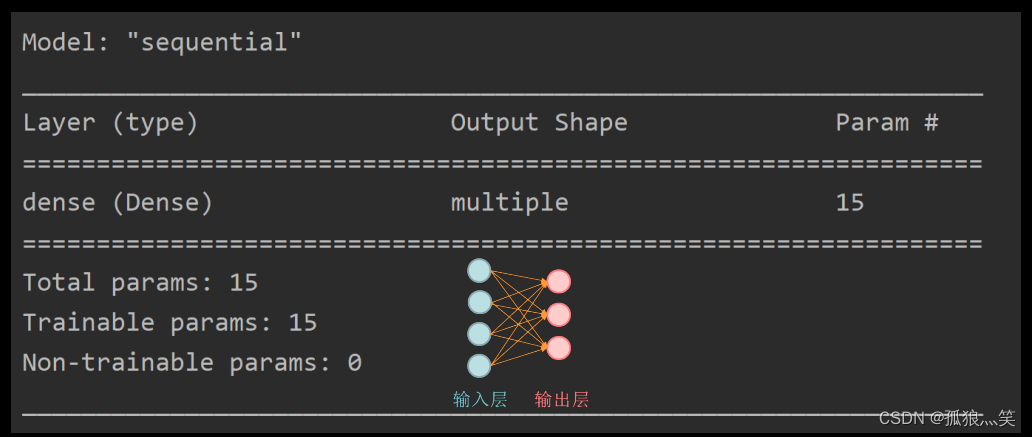
总结:
- 本文主要借鉴:mooc曹建老师的《人工智能实践:Tensorflow笔记》
- 第一个神经网络的搭建,利用tensorflow2.0
- 提醒:跑数据的时候经理用一个空电脑,不然跑不动,内存不够,电脑会坏掉
- 六步法牢记心中,每个网络都是这么搭建的,目前大家都是稍做了修改