文章目录
- 架构要点
- 优势与应用
- 案例研究:基于云原生大数据平台的智能营销分析
- 未来展望:大数据与人工智能的融合
- 结论
🎈个人主页:程序员 小侯
🎐CSDN新晋作者
🎉欢迎 👍点赞✍评论⭐收藏
✨收录专栏:大数据系列
✨文章内容:云原生大数据
🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!🤗
在云计算环境中构建高性能的云原生大数据处理平台,结合人工智能技术来优化数据分析流程,是现代数据处理的一项关键任务。以下是针对这一主题的深入探讨:
架构要点
-
微服务架构与容器化: 基于微服务架构,将大数据处理平台的各个组件拆分成独立的微服务,并使用容器技术如Docker来实现容器化部署。这样可以提高部署速度、资源利用率和平台的弹性。
-
容器编排和自动化管理: 采用容器编排工具如Kubernetes,实现容器的自动化编排、部署、扩展和管理。这为平台的高可用性、伸缩性和稳定性提供了基础。
-
数据处理引擎: 选择适合云原生架构的数据处理引擎,如Apache Spark、Apache Flink等,以支持分布式数据处理和实时分析。
-
存储: 在云计算环境中,选择适合的分布式存储解决方案,如云对象存储、分布式文件系统等,以支持海量数据的存储和访问。
-
AI集成: 将人工智能技术融入大数据处理平台,例如使用机器学习模型对数据进行预测、分类、聚类等,优化数据分析流程。

优势与应用
-
弹性伸缩: 云原生架构的优势之一是平台可以根据负载自动伸缩。结合人工智能技术,平台可以根据预测的数据处理需求智能地调整资源的分配,实现资源的最优利用。
-
实时分析: 人工智能技术可以帮助优化实时数据分析流程,加速数据处理并减少延迟。例如,使用实时机器学习模型进行数据预测,可以实现更快速的反应和决策。
-
智能决策: 结合人工智能技术,平台可以根据数据分析结果自动做出智能决策,从而加速业务流程,提高效率。
-
自动化: 人工智能技术可以实现数据分析流程的自动化,减少人工干预。例如,自动化的数据清洗、特征提取和模型训练过程,可以节省时间和资源。
-
个性化体验: 基于人工智能分析结果,平台可以提供个性化的数据分析和报告,满足不同用户的需求,提升用户体验。
-
持续优化: 人工智能技术可以分析大量数据,并根据分析结果优化数据处理流程。这有助于发现并解决流程中的瓶颈和问题,持续提升性能。

案例研究:基于云原生大数据平台的智能营销分析
- 介绍一个实际案例,如何构建基于云原生大数据平台的智能营销分析系统。
- 使用人工智能技术对市场数据进行分析,预测市场趋势和用户行为。
- 展示该系统如何优化营销策略,提升销售业绩。
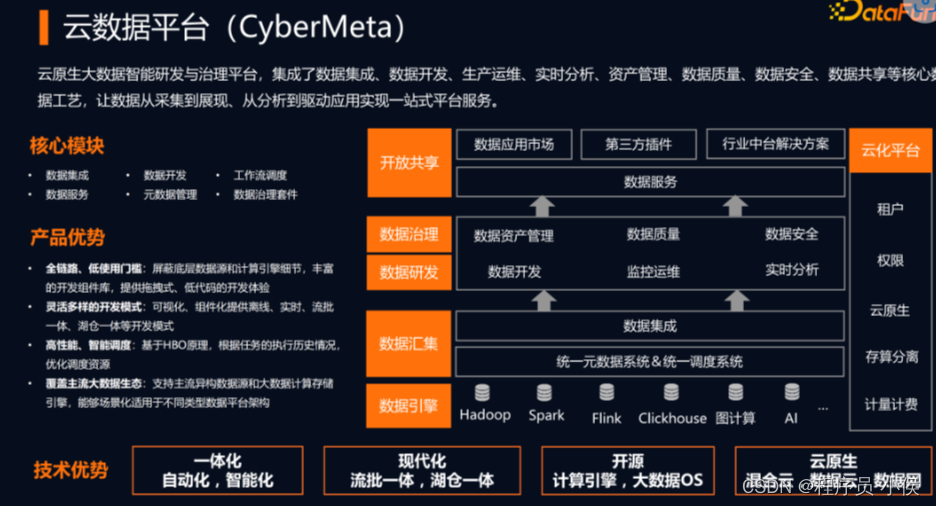
未来展望:大数据与人工智能的融合
- 探讨未来云原生大数据平台的发展趋势,以及人工智能在其中的进一步应用。
- 分析可能的创新,如深度学习在大数据分析中的角色,以及量子计算对大数据处理的影响。
结论
- 在云计算环境中构建云原生大数据处理平台,并结合人工智能技术进行优化,可以实现高性能、弹性伸缩、智能决策和自动化等优势。这种综合性的架构和应用有助于更好地满足日益增长的数据处理需求,推动业务创新和发展。
后记 👉👉💕💕美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!! 🌹🌹🌹