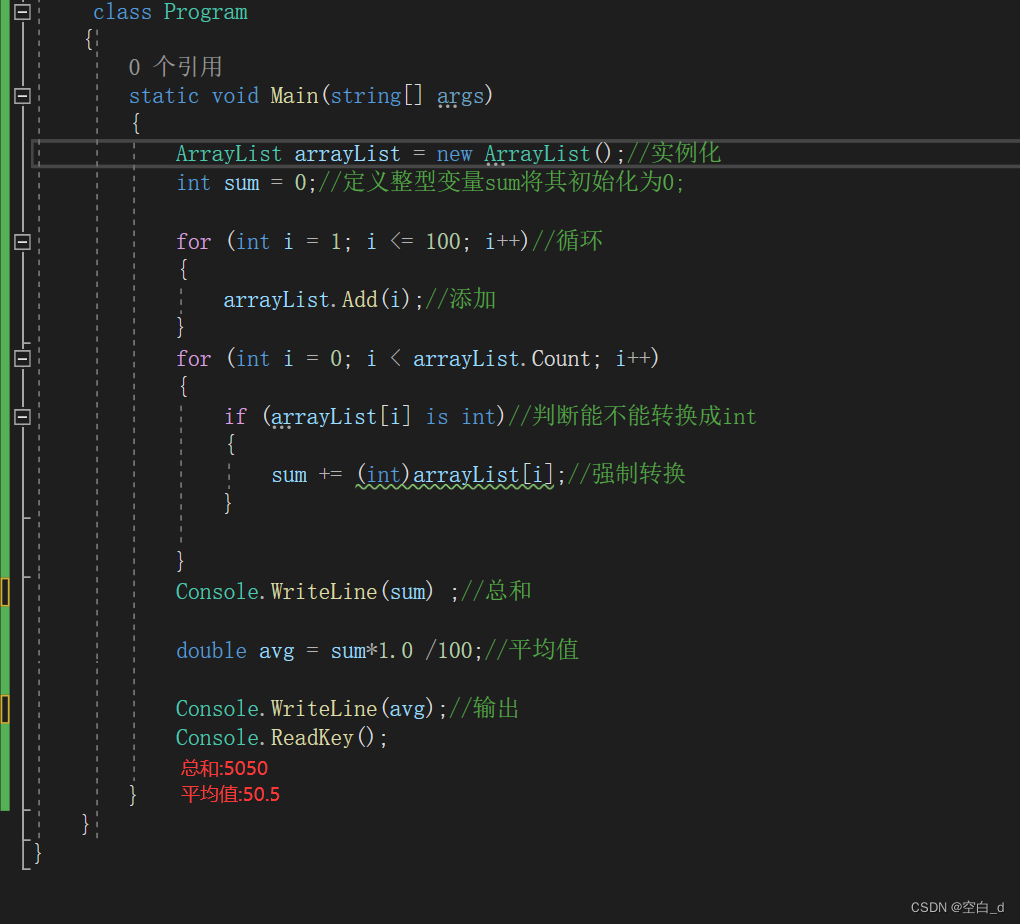
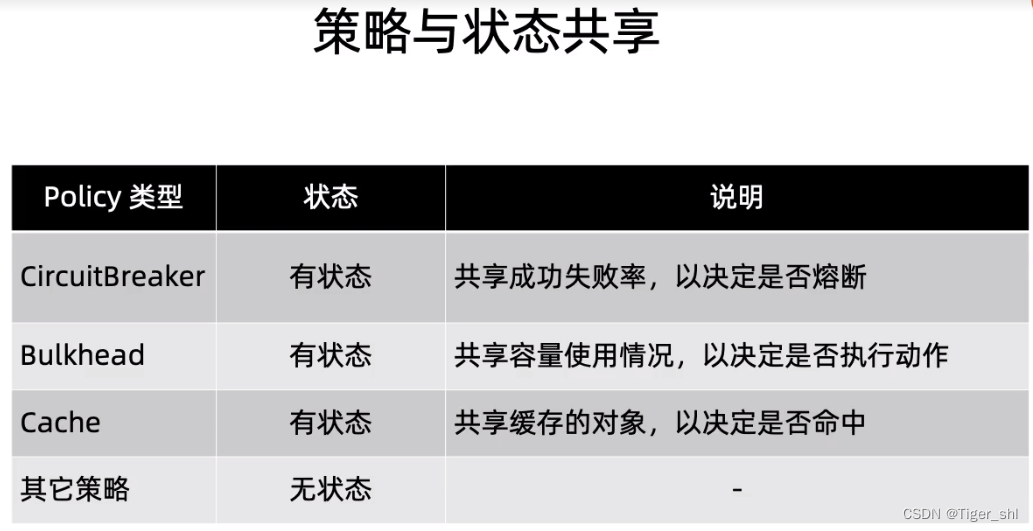
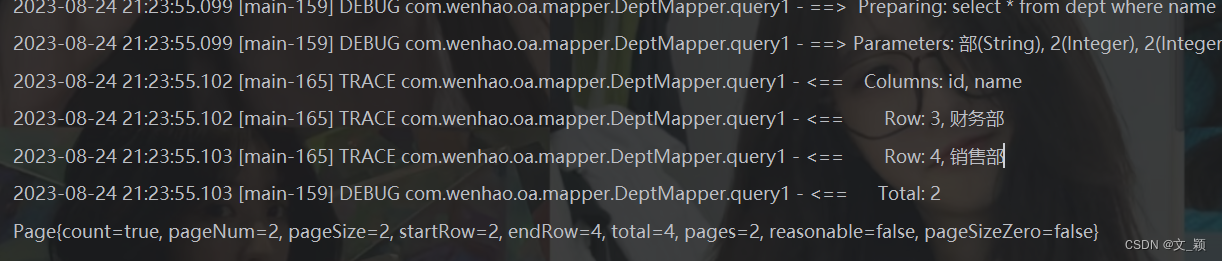
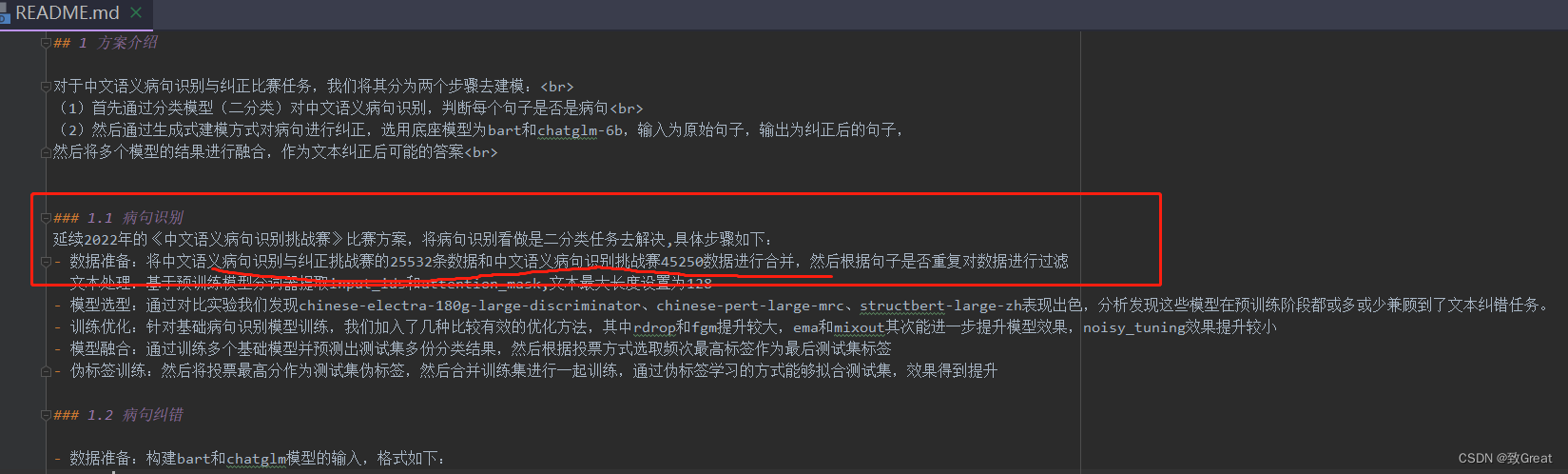
HuggingFace上提供了很多已经训练好的模型库,如果想针对特定数据集优化,那么就需要二次训练模型,并且HuggingFace也提供了训练工具。
一.准备数据集
1.加载编码工具
加载hfl/rbt3编码工具如下所示:
def load_encode():
# 1.加载编码工具
# 第6章/加载tokenizer
from transformers import AutoTokenizer
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\rbt3'
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path)
# 第6章/试编码句子
result = tokenizer.batch_encode_plus(
['明月装饰了你的窗子', '你装饰了别人的梦'],
truncation=True,
)
print(result)
输出结果如下所示:
{'input_ids': [[101, 3209, 3299, 6163, 7652, 749, 872, 4638, 4970, 2094, 102], [101, 872, 6163, 7652, 749, 1166, 782, 4638, 3457, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
2.准备数据集
ChnSentiCorp是谭松波收集整理了一个较大规模的酒店评论语料。7000多条酒店评论数据,5000多条正向评论,2000多条负向评论[3]。
def f1(data):
# 通过编码工具将文字编码为数据
from transformers import AutoTokenizer
from pathlib import Path
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\rbt3'
tokenizer = AutoTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'))
return tokenizer.batch_encode_plus(data['text'], truncation=True)
def f2(data):
# 过滤太长的句子
return [len(i) <= 512 for i in data['input_ids']]
def load_dataset_from_disk():
# 方法1:从HuggingFace加载数据集,然后本地保存
# from datasets import load_dataset
# dataset = load_dataset(path='seamew/ChnSentiCorp')
# print(dataset)
# dataset.save_to_disk(dataset_dict_path='./data/ChnSentiCorp')
# 方法2:从本地加载数据集
from datasets import load_from_disk
mode_name_or_path = r'L:\20230713_HuggingFaceModel\ChnSentiCorp'
dataset = load_from_disk(mode_name_or_path)
# 缩小数据规模,便于测试
dataset['train'] = dataset['train'].shuffle().select(range(2000))
dataset['test'] = dataset['test'].shuffle().select(range(100))
# batched=True表示批量处理
# batch_size=1000表示每次处理1000个样本
# num_proc=8表示使用8个线程操作
# remove_columns=['text']表示移除text列
dataset = dataset.map(f1, batched=True, batch_size=1000, num_proc=8, remove_columns=['text'])
return dataset
由于模型对输入文本的长度有限制,不能处理长度大于512词的文本,因此把长度超过512个词的句子过滤掉。过滤前的dataset为:
DatasetDict({
train: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 2000
})
validation: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1200
})
test: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 100
})
})
过滤后的dataset为:
DatasetDict({
train: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1982
})
validation: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1190
})
test: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 99
})
})
二.定义模型和训练工具
1.加载预训练模型
加载预训练模型代码如下所示:
def load_pretrained_mode():
"""
加载预训练模型
"""
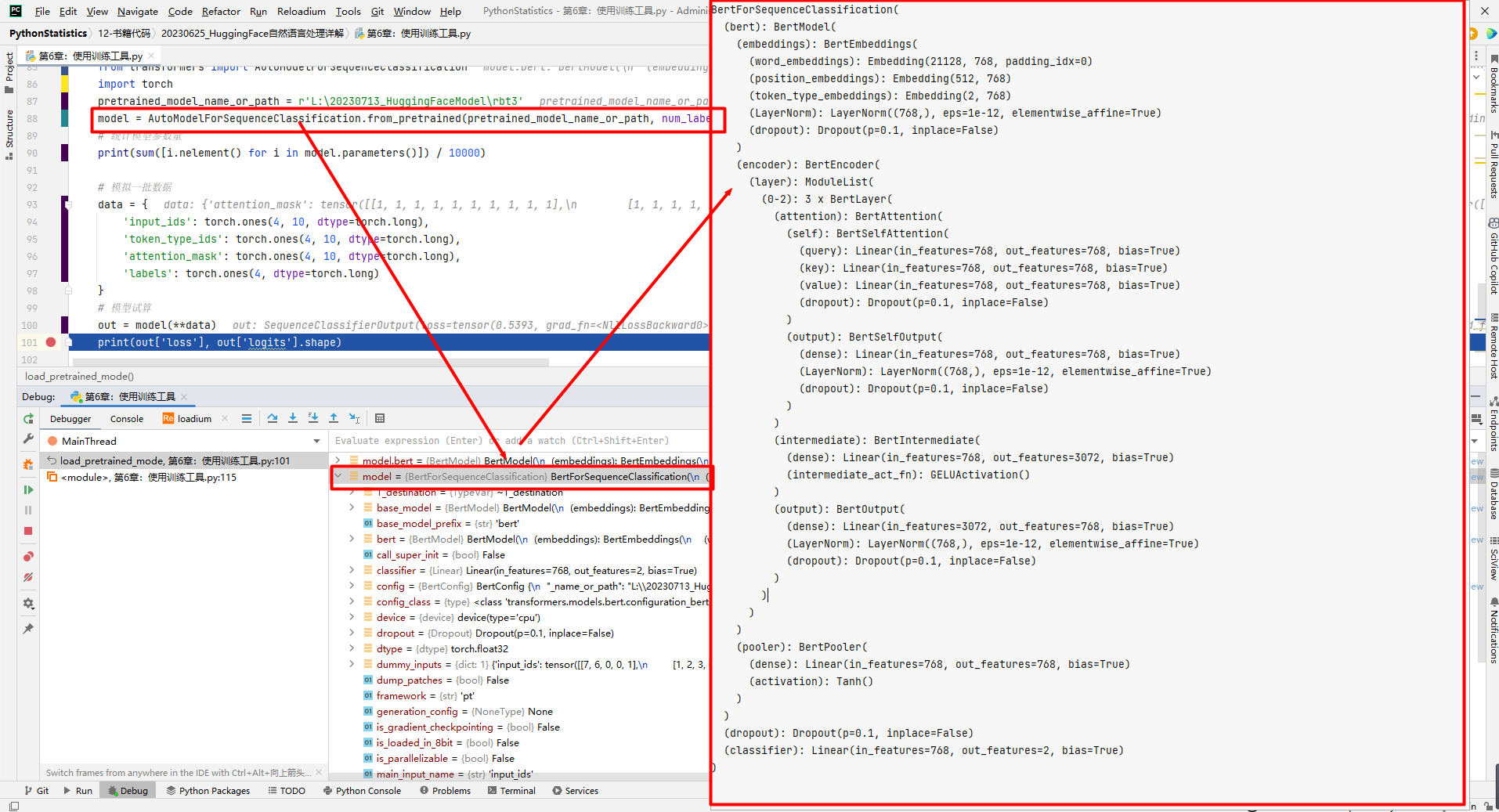
from transformers import AutoModelForSequenceClassification
import torch
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\rbt3'
model = AutoModelForSequenceClassification.from_pretrained(pretrained_model_name_or_path, num_labels=2)
# 统计模型参数量
print(sum([i.nelement() for i in model.parameters()]) / 10000)
# 模拟一批数据
data = {
'input_ids': torch.ones(4, 10, dtype=torch.long),
'token_type_ids': torch.ones(4, 10, dtype=torch.long),
'attention_mask': torch.ones(4, 10, dtype=torch.long),
'labels': torch.ones(4, dtype=torch.long)
}
# 模型试算
out = model(**data)
print(out['loss'], out['logits'].shape)
输出结果如下所示:
3847.8338
tensor(0.3911, grad_fn=<NllLossBackward0>) torch.Size([4, 2])
(1)hfl/rbt3模型
由哈尔滨工业大学讯飞联合实验室(HFL)基于中文文本数据训练的BERT模型。
(2)model数据结构
2.定义评价函数
定义评价函数代码如下所示:
def compute_metrics(eval_pred):
"""
定义评价函数
"""
from datasets import load_metric
metric = load_metric('accuracy')
logits, labels = eval_pred
logits = logits.argmax(axis=1)
return metric.compute(predictions=logits, references=labels)
if __name__ == '__main__':
# 定义评价函数
# 模拟输出
from transformers.trainer_utils import EvalPrediction
import numpy as np
eval_pred = EvalPrediction(
predictions=np.array([[0, 1], [2, 3], [4, 5], [6, 7]]),
label_ids=np.array([1, 1, 0, 1]),
)
accuracy = compute_metrics(eval_pred)
print(accuracy)
输出结果如下所示:
{'accuracy': 0.75}
3.定义训练超参数
可通过TrainingArguments对象来封装超参数:
#第6章/定义训练参数
from transformers import TrainingArguments
#定义训练参数
args = TrainingArguments(
#定义临时数据保存路径
output_dir='./output_dir',
#定义测试执行的策略,可取值为no、epoch、steps
evaluation_strategy='steps',
#定义每隔多少个step执行一次测试
eval_steps=30,
#定义模型保存策略,可取值为no、epoch、steps
save_strategy='steps',
#定义每隔多少个step保存一次
save_steps=30,
#定义共训练几个轮次
num_train_epochs=1,
#定义学习率
learning_rate=1e-4,
#加入参数权重衰减,防止过拟合
weight_decay=1e-2,
#定义测试和训练时的批次大小
per_device_eval_batch_size=16,
per_device_train_batch_size=16,
#定义是否要使用GPU训练
no_CUDA=True,
)
4.定义训练器
Trainer参数包括要训练的模型、超参数对象、训练和验证数据集、评价函数,以及数据整理函数。
from transformers import Trainer
from transformers.data.data_collator import DataCollatorWithPadding
#定义训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
compute_metrics=compute_metrics,
data_collator=DataCollatorWithPadding(tokenizer),
)
5.数据整理函数介绍
通过DataCollatorWithPadding对象把一个批次中长短不一的句子补充成统一的长度(对句子的尾部补充PAD),长度取决于这个批次中最长的句子有多长,如下所示:
def test_DataCollator(tokenizer, dataset):
"""
数据整理函数
"""
from transformers import DataCollatorWithPadding
# 第6章/测试数据整理函数
data_collator = DataCollatorWithPadding(tokenizer)
# 获取一批数据
data = dataset['train'][:5]
# 输出这些句子的长度
for i in data['input_ids']:
print(len(i))
# 调用数据整理函数
data = data_collator(data)
# 查看整理后的数据
for k, v in data.items():
print(k, v.shape)
if __name__ == '__main__':
from transformers import AutoTokenizer
from pathlib import Path
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\rbt3'
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=Path(f'{pretrained_model_name_or_path}'))
# 得到dataset
dataset = load_dataset_from_disk()
dataset = dataset.filter(f2, batched=True, batch_size=1000, num_proc=8)
test_DataCollator(tokenizer, dataset)
结果输出如下所示:
175
136
121
34
160
input_ids torch.Size([5, 175])
token_type_ids torch.Size([5, 175])
attention_mask torch.Size([5, 175])
labels torch.Size([5])
三.训练和测试
1.训练模型
评价和训练模型代码如下所示:
trainer.evaluate() #评价模型
trainer.train() #训练模型
在output_dir文件夹中可以找到4个文件夹,即checkpoint-30、checkpoint-60、checkpoint-90、checkpoint-120,分别是对应步数保存的检查点,每个文件夹中都有一个PyTorch_model.bin文件,这个文件就是模型的参数。每个文件夹包括文件如下所示:
config.json
optimizer.pt
pytorch_model.bin
rng_state.pth
scheduler.pt
trainer_state.json
training_args.bin
运行结果格式如下所示:
{'eval_loss': 0.48926153779029846, 'eval_accuracy': 0.8181818181818182, 'eval_runtime': 62.1286, 'eval_samples_per_second': 1.593, 'eval_steps_per_second': 0.113, 'epoch': 0.48}
如果模型在训练过程中断了,那么可以从中间检查点继续训练,如下所示:
trainer.train(resume_from_checkpoint='./output_dir/checkpoint-90')
2.模型的保存和加载
模型的保存和加载代码如下所示:
# 手动保存模型参数
trainer.save_model(output_dir='./output_dir/save_model')
# 手动加载模型参数
import torch
model.load_state_dict(torch.load('./output_dir/save_model/PyTorch_model.bin'))
3.使用模型预测
使用模型预测代码如下所示:
# 在模型的评估模式下,模型不再对输入进行梯度计算,并且一些具有随机性的操作(如Dropout)会被固定
model.eval()
for i, data in enumerate(trainer.get_eval_dataloader()):
data = data.to('cuda')
out = model(**data)
out = out['logits'].argmax(dim=1)
for j in range(8):
print(tokenizer.decode(data['input_ids'][j], skip_special_tokens=True))
print('label=', data['labels'][j].item())
print('predict=', out[j].item())
break
结果输出如下所示:
酒 店 有 点 偏 , ( 没 有 地 铁 站 ) , 19 : 30 后 就 没 有 shuttle bus 了 。 大 堂 很 小 , 也 没 有 什 么 设 施 。 不 过 , 房 间 很 好 , 也 有 海 景 。
label= 1
predict= 0
哈 哈 哈 哈..... 居 然 还 可 以 继 续 评 论 啊 那 就 给 满 分 了 下 次 去 了 继 续 住 忘 记 说 了, 有 房 内 按 摸 的 服 务 的 可 惜 没 时 间 去 试 了, 下 次 去 还 会 住 的......
label= 1
predict= 0
......
也 许 这 不 算 一 个 很 好 的 理 由, 但 是 我 之 所 以 喜 欢 读 书 而 不 是 看 网 上 的 资 料 什 么 的, 就 是 喜 欢 闻 着 书 香. 这 本 书 可 能 是 印 刷 的 油 墨 不 好 还 是 什 么 原 因, 感 觉 臭 臭 的 不 好 闻. 里 面 是 一 些 关 于 中 式 英 语 的 小 趣 闻, 有 些 小 乐 趣, 但 感 觉 对 于 有 浓 重 中 式 思 维 习 惯 说 英 说 的 人 来 说 才 比 较 有 点 用 处.
label= 0
predict= 0
参考文献:
[1]https://huggingface.co/datasets/seamew/ChnSentiCorp/tree/main
[2]文本数据集的下载与各种操作:https://blog.csdn.net/Wang_Dou_Dou_/article/details/127459760
[3]ChnSentiCorp:https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/ChnSentiCorp_htl_all/intro.ipynb
[4]https://github.com/ai408/nlp-daily-record/tree/main/20230625_HuggingFace自然语言处理详解