文章目录
- 缓存数据的处理流程是怎样的?
- 为什么要用 Redis/为什么要用缓存?
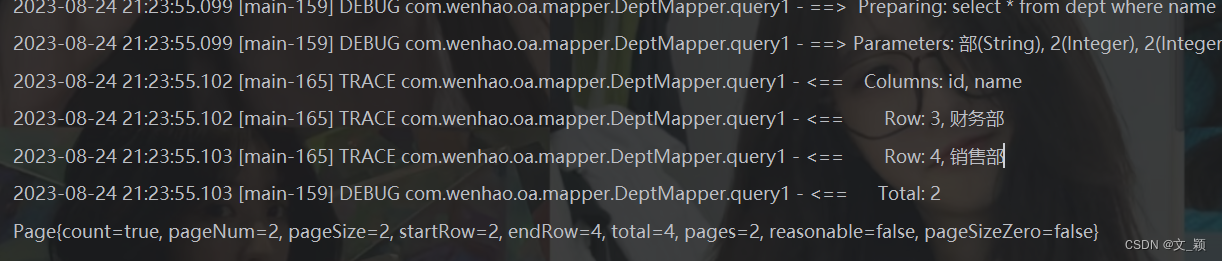
缓存数据的处理流程是怎样的?
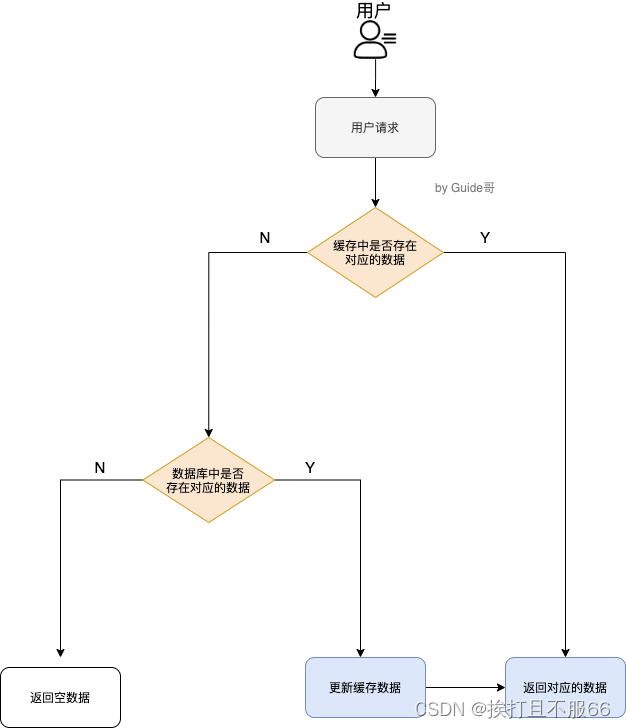
简单来说就是:
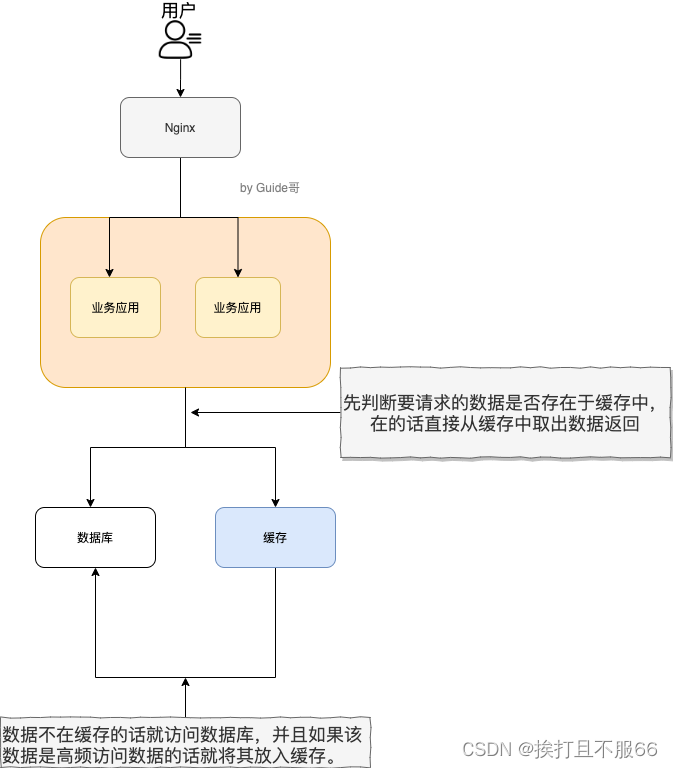
- 如果用户请求的数据在缓存中就直接返回。
- 缓存中不存在的话就看数据库中是否存在。
- 数据库中存在的话就更新缓存中的数据。
- 数据库中不存在的话就返回空数据。
为什么要用 Redis/为什么要用缓存?
使用缓存主要是为了提升用户体验以及应对更多的用户。
下面我们主要从“高性能”和“高并发”这两点来看待这个问题。
高性能 :
对照上面 👆 我画的图。我们设想这样的场景:
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
这样有什么好处呢? 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
不过,要保持数据库和缓存中的数据的一致性。 如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发:
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。
QPS(Query Per Second):服务器每秒可以执行的查询次数;
所以,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发。