上一篇我们了解了 GenericSource 需要依赖 IMediaExtractor 完成 demux 工作,这一篇我们就来学习 android media 框架中的第二个服务 media.extractor,看看 IMediaExtractor 是如何创建与工作的。
1、MediaExtractorService
media.extractor 和 media.player 是属于同一层级的 binder service,都用于提供媒体播放支持,media.player 用于提供播放器功能,而 media.extractor 主要用于本地文件播放的解封装工作。
MediaExtractorService 相关代码位于:
frameworks/av/services/mediaextractor
frameworks/av/media/libmedia
frameworks/av/media/libstagefright
media.extractor 中提供服务的主体是 MediaExtractorService ,创建 IMediaExtractor 需要借助 MediaExtractorService 的力量,这一点和 media.player 的设计是一致的,创建 IMediaPlayer 需要借助 MediaPlayerService 的力量。这两个 service 起着创建和管理实际工作实例的功能。
MediaExtractorService 所继承的 BnMediaExtractorService 由 aidl 文件生成,IMediaExtractorService.aidl 在 libmedia 目录下,总共有3个方法可供使用:
interface IMediaExtractorService {
IMediaExtractor makeExtractor(IDataSource source, @nullable @utf8InCpp String mime);
IDataSource makeIDataSource(in FileDescriptor fd, long offset, long length);
@utf8InCpp String[] getSupportedTypes();
}
接下来看 MediaExtractorService 中到底包含哪些内容。首先来看构造函数:
MediaExtractorService::MediaExtractorService() {
MediaExtractorFactory::LoadExtractors();
}
构造函数调用了 MediaExtractorFactory::LoadExtractors 将平台上所有的 extractor lib 加载到 MediaExtractorService 进程:
void MediaExtractorFactory::LoadExtractors() {
Mutex::Autolock autoLock(gPluginMutex);
std::shared_ptr<std::list<sp<ExtractorPlugin>>> newList(new std::list<sp<ExtractorPlugin>>());
RegisterExtractors("/apex/com.android.media/lib"
#ifdef __LP64__
"64"
#endif
"/extractors", &dlextinfo, *newList);
} else {
ALOGE("couldn't find media namespace.");
}
RegisterExtractors("/system/lib"
#ifdef __LP64__
"64"
#endif
"/extractors", NULL, *newList);
RegisterExtractors("/system_ext/lib"
#ifdef __LP64__
"64"
#endif
"/extractors", NULL, *newList);
newList->sort(compareFunc);
gPlugins = newList;
for (auto it = gPlugins->begin(); it != gPlugins->end(); ++it) {
if ((*it)->def.def_version == EXTRACTORDEF_VERSION_NDK_V2) {
for (size_t i = 0;; i++) {
const char* ext = (*it)->def.u.v3.supported_types[i];
if (ext == nullptr) {
break;
}
gSupportedExtensions.push_back(std::string(ext));
}
}
}
}
lib 加载总共分为2步:
- 到
/apex/com.android.media/lib/extractor/system/lib/lib/system_ext/lib这三个目录下寻找名字中包含 extractor.so 的 lib,打开这些 lib 并用 dlsym 找到 lib 中的GETEXTRACTORDEF函数,最后将 libHandle,GETEXTRACTORDEF 的返回值ExtractorDef以及 path 封装成一个 ExtractorPlugin 存到 list 当中; - 遍历 ExtractorPlugin 读取 ExtractorDef 中定义的可以支持的扩展名,存储到一个列表中。
初学的时候看这里觉得晕晕乎乎的,一层套一层让人很难理解,但是从框架的角度来看就很清除很多。
所有的 extractor 都要遵循设计规则,实现 GETEXTRACTORDEF 函数,函数的返回值是一个 ExtractorDef 对象,ExtractorDef 声明在 MediaExtractorPluginApi.h 中:
struct ExtractorDef {
// version number of this structure
const uint32_t def_version;
// A unique identifier for this extractor.
// See below for a convenience macro to create this from a string.
media_uuid_t extractor_uuid;
// Version number of this extractor. When two extractors with the same
// uuid are encountered, the one with the largest version number will
// be used.
const uint32_t extractor_version;
// a human readable name
const char *extractor_name;
union {
struct {
SnifferFunc sniff;
} v2;
struct {
SnifferFunc sniff;
// a NULL terminated list of container mime types and/or file extensions
// that this extractor supports
const char **supported_types;
} v3;
} u;
};
以下是结构体中成员的含义:
def_version:这个结构体的版本;extractor_uuid:当前 extractor 独一无二的 id,可以使用constUUID方法来生成 ,使用方法查看该方法注释;extractor_version:extractor 的版本,如果两个 extractor uuid 相同,那么加载时只会存储高版本的那个;extractor_name:extractor 的名字,同样可以由我们自己定义;u:它是一个联合体,我们只关注 v3,v3 中有一个 SnifferFunc,这就是后面选择 extractor 的依据;supported_types 表示当前 extractor 所支持的 mine type 或者 文件后缀,必须要以 NULL结尾。
MediaExtractorFactory::LoadExtractors 那么多步骤核心就是或者每个 extractor lib 所定义的 ExtractorDef。
使用 dumpsys media.extractor 查看服务的信息,可以看到加载到的 extractor 的名称,版本,路径和支持解析的文件类型,这些都是从 ExtractorDef 中获取到的。
generic_x86:/ $ dumpsys media.extractor
Available extractors:
AAC Extractor: plugin_version(3), uuid(4fd80eae03d24d729eb948fa6bb54613), version(1), path(/apex/com.android.media/lib/extractors/libaacextractor.so), supports: aac
AMR Extractor: plugin_version(3), uuid(c86639c92f3140aca715fa01b4493aaf), version(1), path(/apex/com.android.media/lib/extractors/libamrextractor.so), supports: amr awb
FLAC Extractor: plugin_version(3), uuid(1364b048cc454fda9934327d0ebf9829), version(1), path(/apex/com.android.media/lib/extractors/libflacextractor.so), supports: flac fl
MIDI Extractor: plugin_version(3), uuid(ef6cca0af8a243e6ba5fdfcd7c9a7ef2), version(1), path(/apex/com.android.media/lib/extractors/libmidiextractor.so), supports: imy mid midi mxmf ota rtttl rt
x smf xmf
MP3 Extractor: plugin_version(3), uuid(812a3f6cc8cf46deb5293774b14103d4), version(1), path(/apex/com.android.media/lib/extractors/libmp3extractor.so), supports: mp2 mp3 mpeg mpg mpga
MP4 Extractor: plugin_version(3), uuid(27575c6744174c548d3d8e626985a164), version(2), path(/apex/com.android.media/lib/extractors/libmp4extractor.so), supports: 3g2 3ga 3gp 3gpp 3gpp2 m4a m4r
m4v mov mp4 qt
MPEG2-PS/TS Extractor: plugin_version(3), uuid(3d1dcfebe40a436da574c2438a555e5f), version(1), path(/apex/com.android.media/lib/extractors/libmpeg2extractor.so), supports: m2p m2ts mts ts
Matroska Extractor: plugin_version(3), uuid(abbedd9238c44904a4c1b3f45f899980), version(1), path(/apex/com.android.media/lib/extractors/libmkvextractor.so), supports: mka mkv webm
Ogg Extractor: plugin_version(3), uuid(8cc5cd06f772495e8a62cba9649374e9), version(1), path(/apex/com.android.media/lib/extractors/liboggextractor.so), supports: oga ogg opus
WAV Extractor: plugin_version(3), uuid(7d61385858374a3884c5332d1cddee27), version(1), path(/apex/com.android.media/lib/extractors/libwavextractor.so), supports: wav
看到这里我会有一些疑问:为什么 MediaExtractor 要以服务的形式提供呢?
我想到的可能有这些:
- 如果要有一个进程要使用 extractor,按照 MediaExtractorFactory 的加载方法,每个进程都要加载所有的 lib,这是很耗费时间的。放到 MediaExtractorService 一个地方加载,其他地方就都可以使用了。
- 创建的所有的 IMediaExtractor 都可以用 MediaExtractorService 管理;
- 如果要新增 extractor,只要按照设计规则实现,编译push到指定目录下就可以生效,不用修改加载部分的代码;
但是,我觉得 extractor 不需要以服务的形式存在,以服务的形式提供反而会损失性能,按照 ffmpeg 的方式,用一个函数指针列表来存储 ExtractorDef 效率应该也很高。
带着这个问题我们一起来看下面的内容。
2、MediaExtractorFactory
我们在上文已经对 MediaExtractorFactory 有了部分解,接下来我们将继续了解它的其他作用:
- 在 service 进程搜索加载所有的 extractor lib;
- 提供 Create 方法给 client 进程,封装 binder 调用;
- 帮助 service 进程创建 IMediaExtractor 实例;
第一点我们在上文已经了解过了,主要是通过 LoadExtractors 方法来加载 lib,获取 lib 中的GETEXTRACTORDEF 函数,这里就不再多做了解。
接下来回到 GenericSource 中看 Create 方法是如何使用的:
status_t NuPlayer::GenericSource::initFromDataSource() {
sp<IMediaExtractor> extractor;
sp<DataSource> dataSource;
{
Mutex::Autolock _l_d(mDisconnectLock);
dataSource = mDataSource;
}
extractor = MediaExtractorFactory::Create(dataSource, NULL);
}
可以发现,并没有直接调用 MediaExtractorService::makeExtractor 来创建 IMediaExtractor 对象,而是调用的 MediaExtractorFactory::Create:
sp<IMediaExtractor> MediaExtractorFactory::Create(
const sp<DataSource> &source, const char *mime) {
// 1. 在调用进程创建 extractor
if (!property_get_bool("media.stagefright.extractremote", true)) {
// local extractor
ALOGW("creating media extractor in calling process");
return CreateFromService(source, mime);
} else {
// 2. 创建远程 extractor
// remote extractor
ALOGV("get service manager");
sp<IBinder> binder = defaultServiceManager()->getService(String16("media.extractor"));
if (binder != 0) {
sp<IMediaExtractorService> mediaExService(
interface_cast<IMediaExtractorService>(binder));
sp<IMediaExtractor> ex;
mediaExService->makeExtractor(
CreateIDataSourceFromDataSource(source),
mime ? std::optional<std::string>(mime) : std::nullopt,
&ex);
return ex;
} else {
ALOGE("extractor service not running");
return NULL;
}
}
return NULL;
}
Create 方法提供了创建 extractor 的两种方式:
- 本地 extractor:在调用进程创建 IMediaExtractor;
- 远程 extractor:调用 MediaExtractorService 创建远程 IMediaExtractor。
第一点说明我们在上一节最后的猜想是多余的,Android 已经提供了在调用进程创建 MediaExtractor 的方式,但是可能为了更方便管理,默认使用远程的版本。
两种模式的选择使用 media.stagefright.extractremote 属性来控制,若值为空 或者 true 就创建远程 extractor,否则创建本地 extractor。
这里还要提一下 DataSource,在 GenericSource::onPrepareAsync 中,如果上层传下来的是 url 不为空,那么就创建本地 DataSource;如果传递的是 fd,要用是远程 extractor 就创建远程 DataSource,否则创建本地 DataSource。
接下来我们只去关注平时用的比较多的情况:extractor 为远程创建,datasource 为本地创建。
回到 MediaExtractorFactory 中来,Create 方法最后会调用 MediaExtractorService 的 makeExtractor 创建远程 IMediaExtractor 对象:
::android::binder::Status MediaExtractorService::makeExtractor(
const ::android::sp<::android::IDataSource>& remoteSource,
const ::std::optional< ::std::string> &mime,
::android::sp<::android::IMediaExtractor>* _aidl_return) {
ALOGV("@@@ MediaExtractorService::makeExtractor for %s", mime ? mime->c_str() : nullptr);
sp<DataSource> localSource = CreateDataSourceFromIDataSource(remoteSource);
MediaBuffer::useSharedMemory();
// 1、创建 Extractor
sp<IMediaExtractor> extractor = MediaExtractorFactory::CreateFromService(
localSource,
mime ? mime->c_str() : nullptr);
ALOGV("extractor service created %p (%s)",
extractor.get(),
extractor == nullptr ? "" : extractor->name());
// 2、存储 Extractor
if (extractor != nullptr) {
registerMediaExtractor(extractor, localSource, mime ? mime->c_str() : nullptr);
}
*_aidl_return = extractor;
return binder::Status::ok();
}
makeExtractor 又会回到 MediaExtractorFactory 的调用,但是这时候已经进到到 Service 进程当中,CreateFromService 很简单,就是遍历加载的内容,调用 sniff 函数选择最合适的 extractor。
ExtractorDef.u.v3.sniff 函数返回的是函数指针,并不是一个具体的 extractor 对象。这是因为执行 sniff 函数会返回置信度,遍历完成后会选择置信度最高的那个 extractor,如果 sniff 执行完就返回一个具体的对象,那么遍历一次就会创建多个对象,创建多个对象再释放,这样的效率是很低的。
IMediaExtractor 创建完成后会调用 registerMediaExtractor 注册到一个容器中,以弱引用的形式存储,不会影响实例的生命周期。这个容器存储有最近十次播放用到的 extractor 信息,我们可以用 dumpsys media.extractor 来查看,如果对象没有释放那么 extractor 和 track 会输出 active,否则输出 deleted。
console:/ # dumpsys media.extractor
......
Recent extractors, most recent first:
08-07 04:01:43: MPEG4Extractor for mime NULL, source TinyCacheSource(CallbackDataSource(486->490, RemoteDataSource(FileSource(fd(/storage/42BA-A9CA/Video/cd1.mp4), 0, 263428780)))), pid 490: active
track {trID: (int32_t) 2, srte: (int32_t) 44100, mxBr: (int32_t) 40268, mime: (char*) audio/mp4a-latm, lang: (char*) und, inpS: (int32_t) 416, esds: (unknown type 1702061171, size 30), dura: (int64_t) 2601842358, aaot: (int32_t) 2, #chn: (int32_t) 2} : active
track {widt: (int32_t) 1280, trID: (int32_t) 1, nfrm: (int32_t) 65041, mime: (char*) video/avc, lang: (char*) und, inpS: (int32_t) 79222, heig: (int32_t) 720, frmR: (int32_t) 25, dura: (int64_t) 2601640000, dWid: (int32_t) 1280, dHgt: (int32_t) 720, avcc: (unknown type 1635148643, size 46)} : active
3、IDataSource
我们都知道要通过 binder 传递对象,这个对象必须要实现 binder 接口(Bp/Bn那套)。由于 GenericSource 中创建的 DataSource 只是一个普通对象,所以是不能通过 binder 传递的。为了让 MediaExtractorService 进程能够使用这个 DataSource对象,MediaExtractorFactory 帮我们做了一层封装。
sp<IMediaExtractor> MediaExtractorFactory::Create(
...
mediaExService->makeExtractor(CreateIDataSourceFromDataSource(source), mime ? std::optional<std::string>(mime) : std::nullopt, &ex);
...
}
MediaExtractorFactory 调用 CreateIDataSourceFromDataSource 把 DataSource 封装到 RemoteDataSource 中,再将 RemoteDataSource 通过 binder 传递给 MediaExtractorService。
sp<IDataSource> CreateIDataSourceFromDataSource(const sp<DataSource> &source) {
if (source == nullptr) {
return nullptr;
}
return RemoteDataSource::wrap(source);
}
先来看 IDataSource 声明的接口(声明与实现均位于 libmedia):
class IDataSource : public IInterface {
public:
DECLARE_META_INTERFACE(DataSource);
virtual sp<IMemory> getIMemory() = 0;
virtual ssize_t readAt(off64_t offset, size_t size) = 0;
virtual status_t getSize(off64_t* size) = 0;
virtual void close() = 0;
virtual uint32_t getFlags() = 0;
virtual String8 toString() = 0;
};
getIMemory:获取缓冲区地址;readAt:从指定偏移位置读取数据;getSize:获取读取文件的大小;close:减少 DataSource 和 缓冲区对象 的引用;getFlags:获取 DataSource 的标志位;toString:获取当前 DataSource 的名称;
这里抛出一个疑问,为什么 IDataSource 要开 getIMemory 接口呢?
我们平时使用 binder 调用时一般只会传递几个参数,并且这些参数需要的内存比较小。如果我们需要通过 binder 传递大量数据,比如这里用 DataSource 读取大量数据传递给 IMediaExtractor 解析,要怎么办呢?
Android 已经为我们提供了共享内存类 IMemory,用这个类就可以让两个进程访问同一块内存,实现不同进程的数据拷贝,这里的 getIMemory 就是让远程代理获取本地对象创建的共享内存对象。
explicit RemoteDataSource(const sp<DataSource> &source) {
Mutex::Autolock lock(mLock);
mSource = source;
sp<MemoryDealer> memoryDealer = new MemoryDealer(kBufferSize, "RemoteDataSource");
mMemory = memoryDealer->allocate(kBufferSize);
if (mMemory.get() == nullptr) {
ALOGE("Failed to allocate memory!");
}
mName = String8::format("RemoteDataSource(%s)", mSource->toString().string());
}
RemoteDataSource 的构造函数中使用 MemoryDealer 创建了共享内存对象 Allocation,共享内存大小为 64 KB。
RemoteDataSource 是在 GenericSource 所在进程中创建的,所以 GenericSource 所在的 MediaPlayerService 进程为 server,调用者 MediaExtractor 所在的 MediaExtractorService 进程为 client。数据读取的流程如下:
- client 进程调用 readAt方法;
- server 进程将数据写到共享内存;
- client 将数据从共享内存拷贝出来,完成一次 readAt 读取。
继续往下看,MediaExtractorService 收到传递过来的 IDataSource 对象后,会对他进行封装:
::android::binder::Status MediaExtractorService::makeExtractor(
...
sp<DataSource> localSource = CreateDataSourceFromIDataSource(remoteSource);
...
}
sp<DataSource> CreateDataSourceFromIDataSource(const sp<IDataSource> &source) {
if (source == nullptr) {
return nullptr;
}
return new TinyCacheSource(new CallbackDataSource(source));
}
从 CreateDataSourceFromIDataSource 可以看到对 IDataSource 进行了两层封装,第一层是 CallbackDataSource,第二层是 TinyCacheSource。
CallbackDataSource 是直接调用 IDataSource 的,由于共享内存大小有限,一次最多读取 64 KB,如果我们要一次读取更多的数据,就要多次调用 IDataSource.readAt 方法,CallbackDataSource 的 readAt 方法帮助我们完成了多次读取调用的封装。
ssize_t CallbackDataSource::readAt(off64_t offset, void* data, size_t size) {
......
size_t totalNumRead = 0;
size_t numLeft = size;
const size_t bufferSize = mMemory->size();
while (numLeft > 0) {
size_t numToRead = std::min(numLeft, bufferSize);
ssize_t numRead =
mIDataSource->readAt(offset + totalNumRead, numToRead);
// A negative return value represents an error. Pass it on.
if (numRead < 0) {
return numRead == ERROR_END_OF_STREAM && totalNumRead > 0 ? totalNumRead : numRead;
}
// A zero return value signals EOS. Return the bytes read so far.
if (numRead == 0) {
return totalNumRead;
}
if ((size_t)numRead > numToRead) {
return ERROR_OUT_OF_RANGE;
}
CHECK(numRead >= 0 && (size_t)numRead <= bufferSize);
memcpy(((uint8_t*)data) + totalNumRead, mMemory->unsecurePointer(),
numRead);
numLeft -= numRead;
totalNumRead += numRead;
}
return totalNumRead;
}
第二层封装 TinyCacheSource 从名字就可以知道是做缓冲区的作用,读取的数据会存到缓冲区中,使用时优先从缓冲区中读取,如果数据不够再真正去读取,这里就不再粘贴代码了。
再回到 MediaExtractorFactory 创建 IMediaExtractor 的地方:
sp<IMediaExtractor> MediaExtractorFactory::CreateFromService(
const sp<DataSource> &source, const char *mime) {
......
CMediaExtractor *ret = ((CreatorFunc)creator)(source->wrap(), meta);
......
}
调用 sniff 返回的函数指针时,向下传的 DataSource 又做了一层C语言风格的封装变成 CDataSource,这一层完全可以不不看,如果想学习C语言风格的面向对象编程可以了解一下。
我们以 MPEG2TSExtractor 为例,看看 sniff 返回的函数指针是什么:
return [](
CDataSource *source,
void *) -> CMediaExtractor* {
return wrap(new MPEG2PSExtractor(new DataSourceHelper(source)));};
调用这个函数指针最终会进入到真正的 extractor 构造函数中,这里又对 CDataSource 进行了封装,成为了 DataSourceHelper。
DataSourceHelper 就不仅仅只封装了,它还扩充了一些便利的方法,例如 getUInt16、getUInt24、getUInt32、getUInt64,用来一次读取 2bytes、3bytes、4bytes、8bytes。
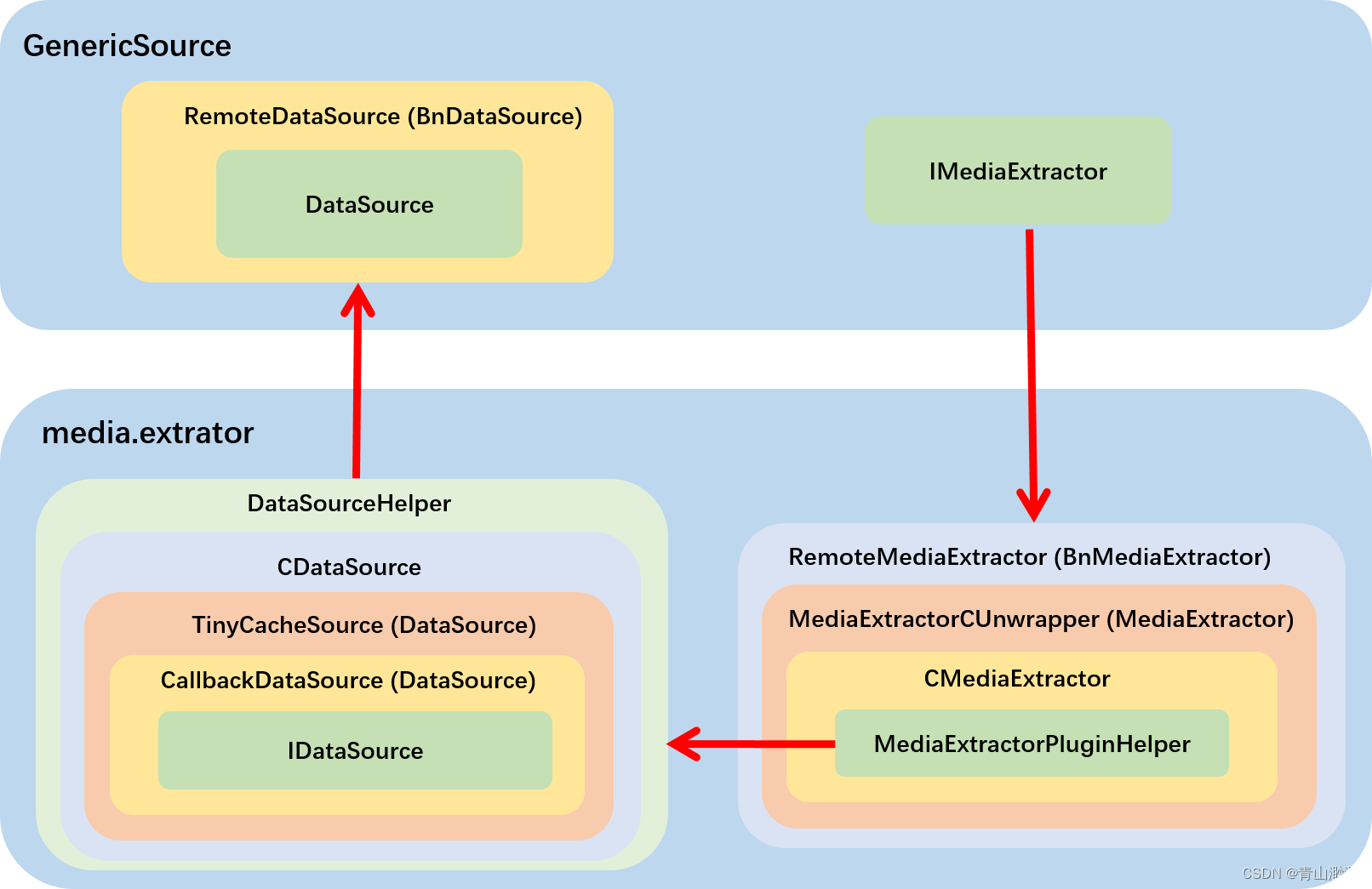
到这里 DataSouce 就阅读完毕了,如果用时序图来表达调用顺序,这么多层的嵌套画出来的时序图估计别人一看就晕了。
我这里依旧用框架图来表示他们的层级结构:
4、IMediaExtractor
IMediaExtractor 的层级结构在上面的图中已经画出来了,它比 IDataSource 要简单很多,CMediaExtractor 和 MediaExtractorCUnwrapper 这两层完全可以忽略,只是接口封装而已,IMediaExtractor 就不再做过多了解。
5、IMediaSource
MediaExtractor 会解析出当前播放码流中的 track, 调用 getTrack 方法会为指定 track 创建 IMediaSource,调用 IMediaSource 读取的数据就是该 track 所包含的数据。
每个 extractor 都有自己的 MediaSource,它们都继承于 MediaTrackHelper,但是内部实现各不相同。我们这里不会关注 MediaSource 具体是如何实现的,重点是了解 IMediaSource 的框架。
以下是我绘制的 IMediaSource 的框架图:
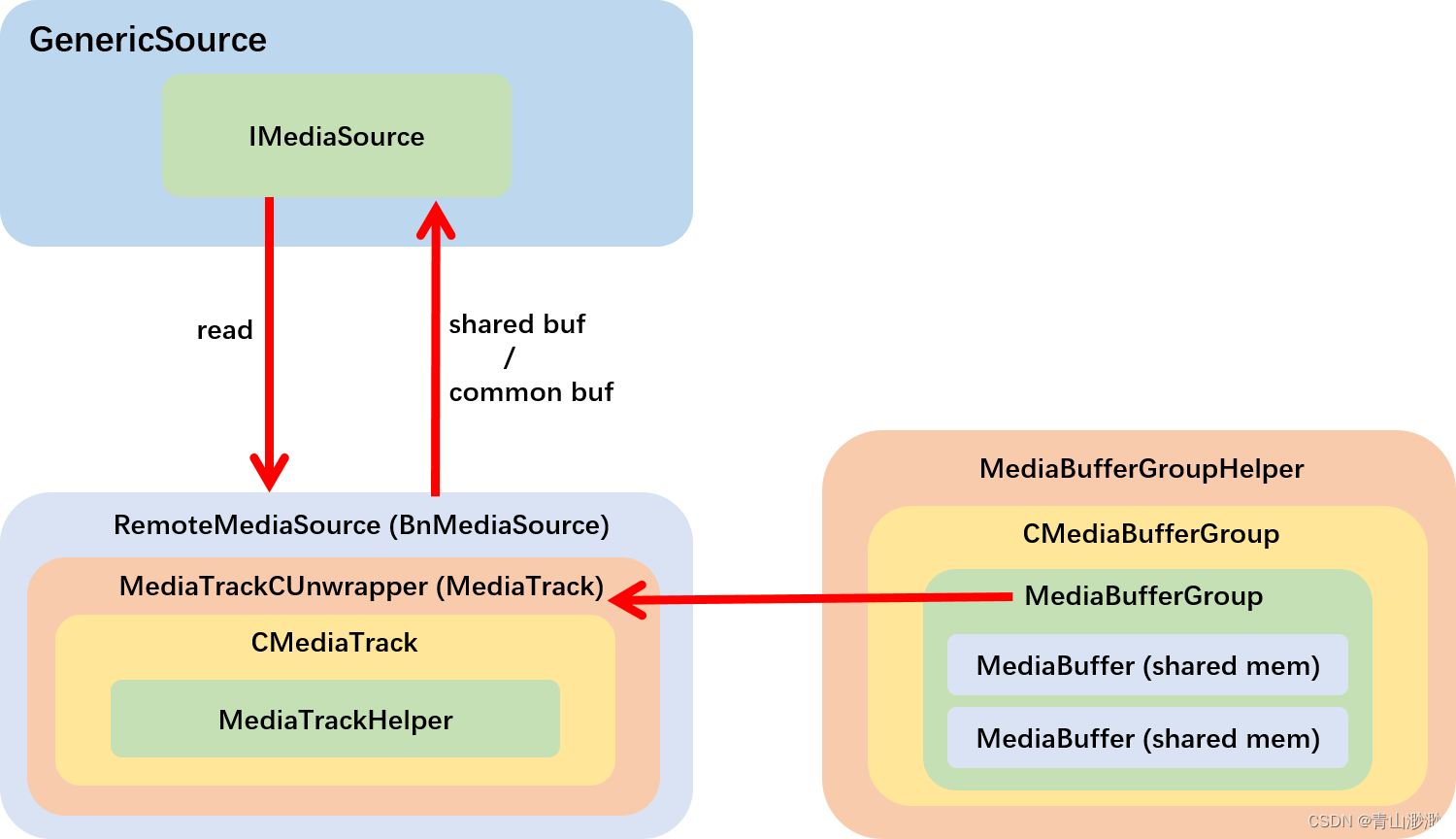
RemoteMeiaSource 封装了 MediaTrack,最内部的实现是 MediaTrackHelper。MediaTrackHelper 中有一个成员 MediaBufferGroupHelper,这个成员需要通过 MediaTrackHelper 的构造函数设定,在它的外层 MediaTrack 的 start 方法中创建并设定下去:
status_t MediaTrackCUnwrapper::start() {
if (bufferGroup == nullptr) {
bufferGroup = new MediaBufferGroup();
}
return reverse_translate_error(wrapper->start(wrapper->data, bufferGroup->wrap()));
}
wrapper->start = [](void *data, CMediaBufferGroup *bufferGroup) -> media_status_t {
if (((MediaTrackHelper*)data)->mBufferGroup) {
// this shouldn't happen, but handle it anyway
delete ((MediaTrackHelper*)data)->mBufferGroup;
}
((MediaTrackHelper*)data)->mBufferGroup = new MediaBufferGroupHelper(bufferGroup);
return ((MediaTrackHelper*)data)->start();
};
MediaBufferGroup 其实是一个 BufferPool,里面储存着一个个 MediaBuffer 对象,MediaBuffer 封装有 shared memory(IMemory)或者是普通 memory,这里的设计应该是为了内存复用,并且减少拷贝次数,接下来们来看具体是如何实现的。
在 extractor 中会调用 MediaBufferGroup 的 init 方法,设定内部 MediaBuffer 的数量,以及内部 buffer size 的大小,同时分配这些buffer:
void MediaBufferGroup::init(size_t buffers, size_t buffer_size, size_t growthLimit) {
mInternal->mGrowthLimit = growthLimit;
if (mInternal->mGrowthLimit > 0 && buffers > mInternal->mGrowthLimit) {
ALOGW("Preallocated buffers %zu > growthLimit %zu, increasing growthLimit",
buffers, mInternal->mGrowthLimit);
mInternal->mGrowthLimit = buffers;
}
#if !defined(NO_IMEMORY) && !defined(__ANDROID_APEX__)
if (buffer_size >= kSharedMemoryThreshold) {
ALOGD("creating MemoryDealer");
// Using a single MemoryDealer is efficient for a group of shared memory objects.
// This loop guarantees that we use shared memory (no fallback to malloc).
size_t alignment = MemoryDealer::getAllocationAlignment();
size_t augmented_size = buffer_size + sizeof(MediaBuffer::SharedControl);
size_t total = (augmented_size + alignment - 1) / alignment * alignment * buffers;
sp<MemoryDealer> memoryDealer = new MemoryDealer(total, "MediaBufferGroup");
for (size_t i = 0; i < buffers; ++i) {
sp<IMemory> mem = memoryDealer->allocate(augmented_size);
if (mem.get() == nullptr || mem->unsecurePointer() == nullptr) {
ALOGW("Only allocated %zu shared buffers of size %zu", i, buffer_size);
break;
}
MediaBuffer *buffer = new MediaBuffer(mem);
buffer->getSharedControl()->clear();
add_buffer(buffer);
}
return;
}
#else
(void)kSharedMemoryThreshold;
#endif
// Non-shared memory allocation.
for (size_t i = 0; i < buffers; ++i) {
MediaBuffer *buffer = new MediaBuffer(buffer_size);
if (buffer->data() == nullptr) {
delete buffer; // don't call release, it's not properly formed
ALOGW("Only allocated %zu malloc buffers of size %zu", i, buffer_size);
break;
}
add_buffer(buffer);
}
}
如果 buffer size 大于 4KB,那么给 MediaBuffer 分配共享内存,如果 buffer size 小于 4KB,那么就分配普通内存。当调用 IMediaSource 的 read 或者 readMultiple 方法时,会调用 MediaBufferGroup acquire_buffer 获取一个 buffer,并将 demux 后的数据写入到这个 buffer 当中。
为什么 IMediaSource read 不用一块共享内存来传递,而要用多块 MediaBuffer 来传递呢?这是因为 demux 后的数据是以 帧 为单位存储的,我们希望每次拷贝都是一帧,用单独的 MediaBuffer 管理会更方便。
回到 IMediaSource.cpp,这里是 IMediaSource 的 Bn 实现,我们来看 readMultiple 是如何做的:
case READMULTIPLE: {
// 1、读取一帧数据
ret = read((MediaBufferBase **)&buf, useOptions ? &opts : nullptr);
// Even if we're using shared memory, we might not want to use it, since for small
// sizes it's faster to copy data through the Binder transaction
// On the other hand, if the data size is large enough, it's better to use shared
// memory. When data is too large, binder can't handle it.
//
// TODO: reduce MediaBuffer::kSharedMemThreshold
MediaBuffer *transferBuf = nullptr;
const size_t length = buf->range_length();
size_t offset = buf->range_offset();
// 2、如果数据长度大于阈值,并且使用的是共享内存
if (length >= (supportNonblockingRead() && buf->mMemory != nullptr ?
kTransferSharedAsSharedThreshold : kTransferInlineAsSharedThreshold)) {
if (buf->mMemory != nullptr) {
ALOGV("Use shared memory: %zu", length);
transferBuf = buf;
}
}
// 3、将 buffer 返回
if (transferBuf != nullptr) { // Using shared buffers.
uint64_t index = mIndexCache.lookup(transferBuf->mMemory);
if (index == 0) {
index = mIndexCache.insert(transferBuf->mMemory);
reply->writeInt32(SHARED_BUFFER);
reply->writeUint64(index);
reply->writeStrongBinder(IInterface::asBinder(transferBuf->mMemory));
} else {
reply->writeInt32(SHARED_BUFFER_INDEX);
reply->writeUint64(index);
}
reply->writeInt32(offset);
reply->writeInt32(length);
buf->meta_data().writeToParcel(*reply);
transferBuf->addRemoteRefcount(1);
if (transferBuf != buf) {
transferBuf->release(); // release local ref
} else if (!supportNonblockingRead()) {
maxNumBuffers = 0; // stop readMultiple with one shared buffer.
}
} else {
reply->writeInt32(INLINE_BUFFER);
reply->writeByteArray(length, (uint8_t*)buf->data() + offset);
buf->meta_data().writeToParcel(*reply);
inlineTransferSize += length;
if (inlineTransferSize > kInlineMaxTransfer) {
maxNumBuffers = 0; // stop readMultiple if inline transfer is too large.
}
}
// 5、释放本地 buffer
buf->release();
}
这里的代码有点长,但是逻辑并不复杂:
- 调用 read 方法将 demux 后的数据读到 MediaBuffer 中;
- 如果数据长度短,用内存拷贝会更快,如果数据长则用共享内存会快,另一方面如果数据长度过长,binder 将无法处理;
- 返回数据时会判断数据长度,如果用了共享内存,但是数据长度短,接下来将 buffer 返回时还是会以拷贝的方式返回;
- 以共享内存的方式返回时,需要增加远程的引用计数,防止 MediaBuffer 被重复使用。
- 释放本地 buffer,将本地 buffer 返回到 MediaBufferGroup;
我们要注意的是 MediaBuffer 里面使用了引用计数,但是并没有继承于 RefBase。在这里,调用 MediaBuffer 的 release 方法,让他的引用计数为 0 时,会有 Callback 发到 MediaBufferGroup,通知有空闲的 buffer 可以使用。buffer 可用的条件是 远程和本地 的引用计数之和为 0,所以上层将 buffer 拷贝完成之后需要调用 release,将远程的引用计数减一。
到这儿 IMediaSource 的了解就结束了,它内部维护了一套生产者-消费者机制,这边讲的可能不是那么详细,但是了解了大致框架,相信其他内容就很容易看懂了。