文章目录
- 虚拟机设置
- HDFS 写数据测试
- HDFS 读数据测试
- 删除压测产生的数据
虚拟机设置
如果你是在虚拟机中使用集群,那你你需要先对每台服务器进行网络设置,模拟真实网络传输速率。
如下所示:
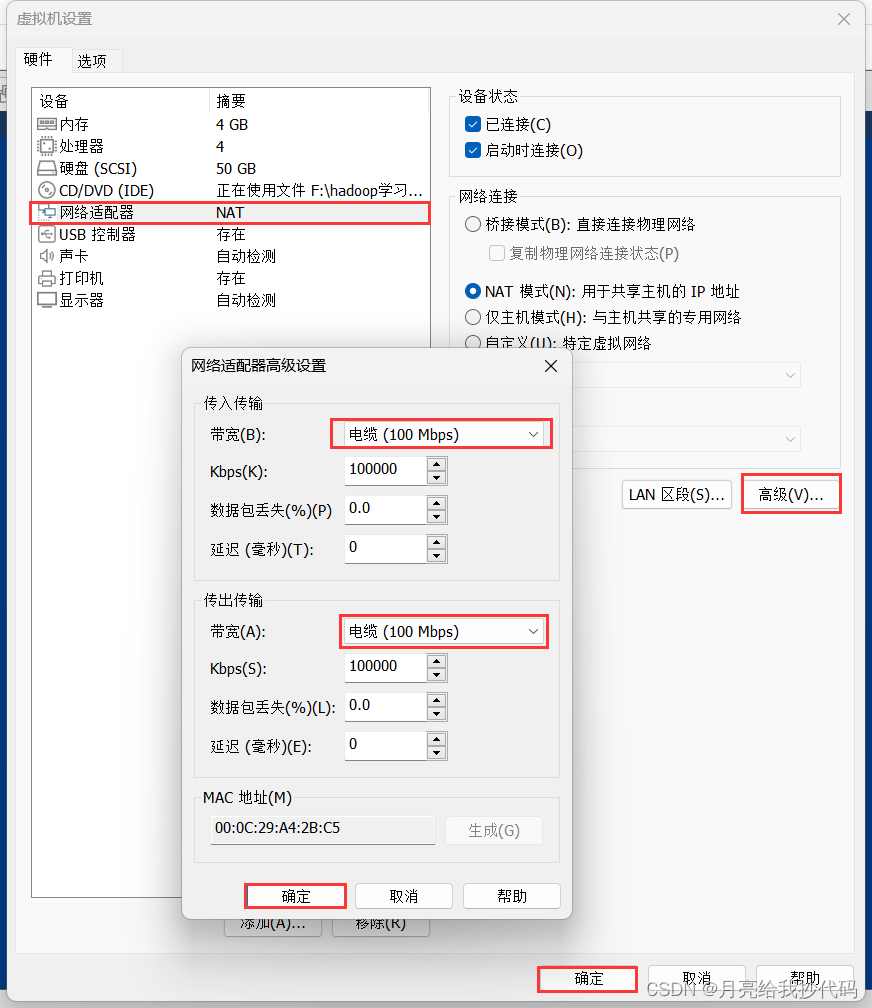
将其设置为百兆网,每台服务器都要进行设置哦。
HDFS 写数据测试
进行写数据测压,运行官方案例。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 11 -fileSize 128MB
参数解析:
-
官方测压 Jar 包:
hadoop-mapreduce-client-jobclient-3.1.3-tests.jar -
类名:
TestDFSIO -
操作类型:
-write -
指定操作文件数量:
-nrFiles 11,该参数设置为集群服务器总CPU核心数减 1 -
指定传输文件大小:
fileSize 128MB
写入测试结果分析:

-
Date & time:测试执行的日期和时间为 2023-08-25 22:23:39 CST。
-
Number of files:在测试中创建了 11 个文件。
-
Total MBytes processed:单个 map 总共处理了 1408 MB 的数据。
-
Throughput mb/sec:吞吐量,即每秒写入的数据量,为 3.86 MB/sec。这表示在测试期间,平均每秒写入了约 3.86 MB 的数据。
-
Average IO rate mb/sec:平均的IO速率,即数据写入的平均速率,为 4.3 MB/sec。这是所有写入操作的平均速率。
-
IO rate std deviation:IO速率的标准差,为 1.43。这个值衡量了IO速率的变化程度。较高的标准差可能表示写入速率在测试期间有较大的波动。
-
Test exec time sec:测试执行的时间为 137.46 秒。这表示整个测试的执行时间。
那么如何确定资源是否合理分配跑满了呢?
在上面,我们设置每台服务器的网速为 100Mbps(bit),换算成兆每秒结果为 12.5M/s(byte),因为 1byte = 8bit。
输出结果中显示平均速率为 3.86 M/s,三台服务器共传输了 3 * 11 个文件,所以实测速度为 3.86 * 33 = 127.38M/s,显然该速度远远大于 3 * 12.5M/s,所有资源传输速度都很快,网络资源已经拉满。
该测试结果会受到网速、硬盘传输速率的影响。
HDFS 读数据测试
进行读数据测压,运行官方案例。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 11 -fileSize 128MB
读测试结果如下:

由于这里的数据都在本地,所以拼的就是硬盘的传输速率,没有网络IO,速度很快。
删除压测产生的数据
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean