动动发财的小手,点个赞吧!
这是有关分析和优化在 GPU 上运行的 PyTorch 模型主题的系列文章的第二部分。在第一篇文章中,我们演示了使用 PyTorch Profiler 和 TensorBoard 迭代分析和优化 PyTorch 模型的过程以及巨大潜力。在这篇文章中,我们将重点关注 PyTorch 中由于使用急切执行而特别普遍的特定类型的性能问题:模型执行部分对 CPU 的依赖。识别此类问题的存在和根源可能非常困难,并且通常需要使用专用的性能分析器。在这篇文章[1]中,我们将分享一些在使用 PyTorch Profiler 和 PyTorch Profiler TensorBoard 插件时识别此类性能问题的技巧。
吸引点
PyTorch 的主要吸引力之一是其执行模式。在 Eager 模式下,形成模型的每个 PyTorch 操作一旦到达就会独立执行。这与图模式相反,在图模式中,整个模型以最适合在 GPU 上运行并作为整体执行的方式预编译为单个图。通常,这种预编译会带来更好的性能(例如,请参见此处)。在急切模式下,编程上下文在每次操作后返回到应用程序,从而允许我们访问和评估任意张量。这使得构建、分析和调试 ML 模型变得更加容易。另一方面,它也使我们的模型更容易(有时是意外地)插入次优代码块。正如我们将演示的,了解如何识别和修复此类代码块会对模型的速度产生重大影响。
玩具示例
在以下块中,我们介绍将用于演示的玩具示例。该代码非常宽松地基于我们上一篇文章中的示例以及本 PyTorch 教程中定义的损失函数。
我们首先定义一个简单的分类模型。它的架构对于本文来说并不重要。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.models
import torchvision.transforms as T
from torchvision.datasets.vision import VisionDataset
import numpy as np
from PIL import Image
# sample model
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 8, 3, padding=1)
self.conv2 = nn.Conv2d(8, 12, 3, padding=1)
self.conv3 = nn.Conv2d(12, 16, 3, padding=1)
self.conv4 = nn.Conv2d(16, 20, 3, padding=1)
self.conv5 = nn.Conv2d(20, 24, 3, padding=1)
self.conv6 = nn.Conv2d(24, 28, 3, padding=1)
self.conv7 = nn.Conv2d(28, 32, 3, padding=1)
self.conv8 = nn.Conv2d(32, 10, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = self.pool(F.relu(self.conv5(x)))
x = self.pool(F.relu(self.conv6(x)))
x = self.pool(F.relu(self.conv7(x)))
x = self.pool(F.relu(self.conv8(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
return x
接下来,我们定义一个非常标准的交叉熵损失函数。这个损失函数将是我们讨论的主要焦点。
def log_softmax(x):
return x - x.exp().sum(-1).log().unsqueeze(-1)
def weighted_nll(pred, target, weight):
assert target.max() < 10
nll = -pred[range(target.shape[0]), target]
nll = nll * weight[target]
nll = nll / weight[target].sum()
sum_nll = nll.sum()
return sum_nll
# custom loss definition
class CrossEntropyLoss(nn.Module):
def forward(self, input, target):
pred = log_softmax(input)
loss = weighted_nll(pred, target, torch.Tensor([0.1]*10).cuda())
return loss
最后,我们定义数据集和训练循环:
# dataset with random images that mimics the properties of CIFAR10
class FakeCIFAR(VisionDataset):
def __init__(self, transform):
super().__init__(root=None, transform=transform)
self.data = np.random.randint(low=0,high=256,size=(10000,32,32,3),dtype=np.uint8)
self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist()
def __getitem__(self, index):
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self) -> int:
return len(self.data)
transform = T.Compose(
[T.Resize(256),
T.PILToTensor()])
train_set = FakeCIFAR(transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=1024,
shuffle=True, num_workers=8, pin_memory=True)
device = torch.device("cuda:0")
model = Net().cuda(device)
criterion = CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
# training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler(’./log/example’),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, data in enumerate(train_loader):
inputs = data[0].to(device=device, non_blocking=True)
labels = data[1].to(device=device, non_blocking=True)
inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5
if step >= (1 + 4 + 3) * 1:
break
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
prof.step()
经验丰富的 PyTorch 开发人员可能已经注意到,我们的示例在损失函数中包含许多低效的代码行。与此同时,它并没有什么明显的问题,而且这种类型的低效率现象并不少见。如果您想测试您的 PyTorch 熟练程度,请在继续阅读之前看看您是否能找到我们实现交叉熵损失的三个问题。在接下来的部分中,我们将假设我们无法自己找到这些问题,并展示如何使用 PyTorch Profiler 及其关联的 TensorBoard 插件来识别它们。
与我们之前的文章一样,我们将迭代地运行实验,识别性能问题并尝试修复它们。我们将在 Amazon EC2 g5.2xlarge 实例(包含 NVIDIA A10G GPU 和 8 个 vCPU)上运行实验,并使用官方 AWS PyTorch 2.0 Docker 映像。
初始性能结果
在下图中,我们显示了上述脚本的性能报告的“概述”选项卡。
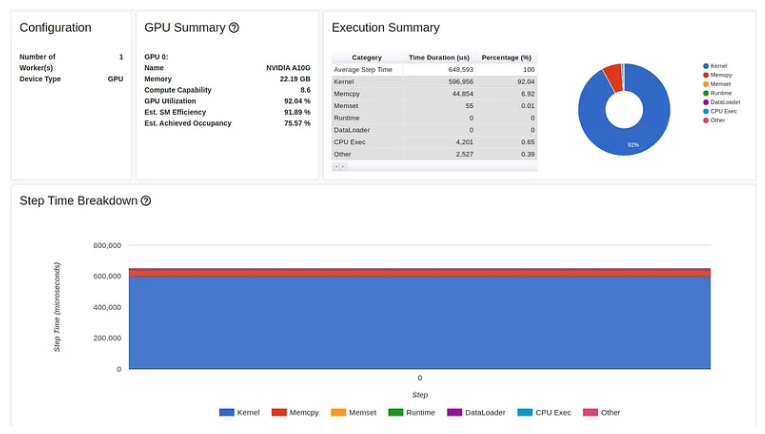
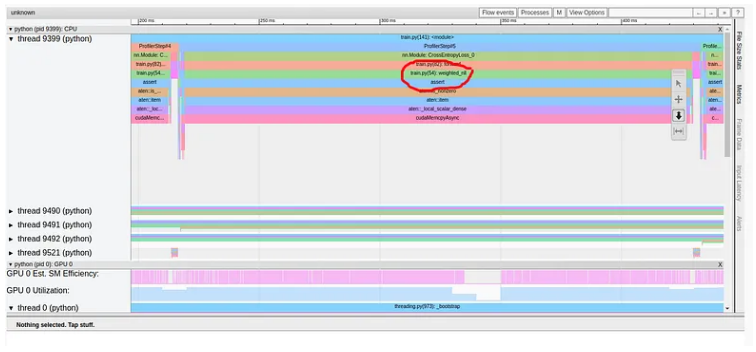
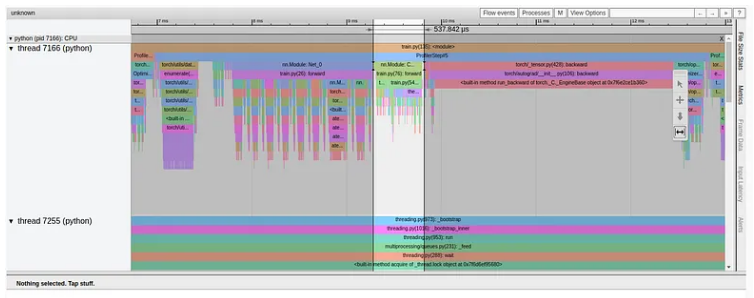
正如我们所看到的,我们的 GPU 利用率相对较高,为 92.04%,步长为 216 毫秒。 (正如我们之前的文章中一样,torch-tb-profiler 0.4.1 版本中的概述总结了所有三个训练步骤的步骤时间。)仅从这份报告中,您可能不会认为我们的模型有任何问题。然而,性能报告的跟踪视图讲述了一个完全不同的故事:
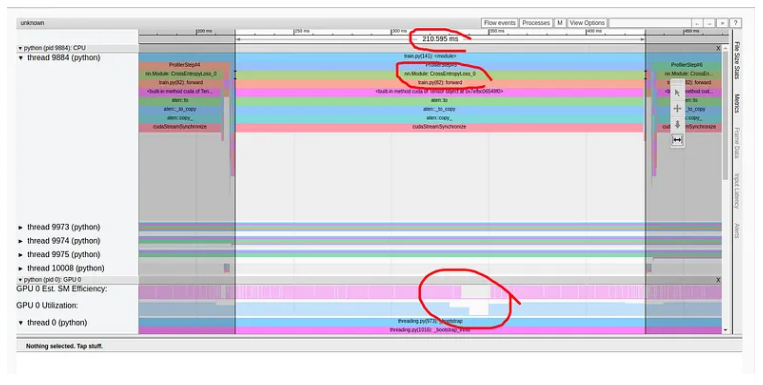
如上所述,仅交叉熵损失的前向传递就占用了训练步骤 216 毫秒中的 211 毫秒!这清楚地表明出现了问题。与模型相比,我们的损失函数包含少量计算,并且当然不应该占步骤时间的 98%。仔细观察调用堆栈,我们可以看到一些函数调用增强了我们的怀疑,包括“to”、“copy_”和“cudaStreamSynchronize”。这种组合通常表明数据正在从 CPU 复制到 GPU——我们不希望在损失计算过程中发生这种情况。在这种情况下,我们的性能问题也与 GPU 利用率的短暂下降相关,如图中突出显示的那样。然而,这并非总是如此。通常,GPU 利用率的下降与性能问题并不相符,或者可能根本看不到。
我们现在知道损失函数存在性能问题,并且很可能与将张量从主机复制到 GPU 有关。但是,这可能不足以确定导致问题的精确代码行。为了方便我们的搜索,我们将使用标记为 torch.profiler.record_function 上下文管理器的每行代码进行包装,并重新运行分析分析。
# custom loss definition
class CrossEntropyLoss(nn.Module):
def forward(self, input, target):
with torch.profiler.record_function('log_softmax'):
pred = log_softmax(input)
with torch.profiler.record_function('define_weights'):
weights = torch.Tensor([0.1]*10).cuda()
with torch.profiler.record_function('weighted_nll'):
loss = weighted_nll(pred, target, torch.Tensor([0.1]*10).cuda())
return loss
添加标签可以帮助我们识别权重定义,或者更准确地说,将权重复制到 GPU 中,作为有问题的代码行。
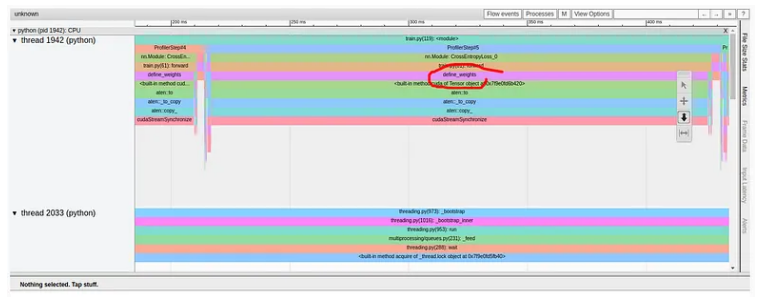
优化1:从训练步骤中删除冗余的主机到 GPU 副本
一旦我们确定了第一个问题,解决它就相当简单了。在下面的代码块中,我们在损失初始化函数中将权重向量复制到 GPU 一次:
class CrossEntropyLoss(nn.Module):
def __init__(self):
super().__init__()
self.weight = torch.Tensor([0.1]*10).cuda()
def forward(self, input, target):
with torch.profiler.record_function('log_softmax'):
pred = log_softmax(input)
with torch.profiler.record_function('weighted_nll'):
loss = weighted_nll(pred, target, self.weight)
return loss
下图显示了此修复后的性能分析结果:
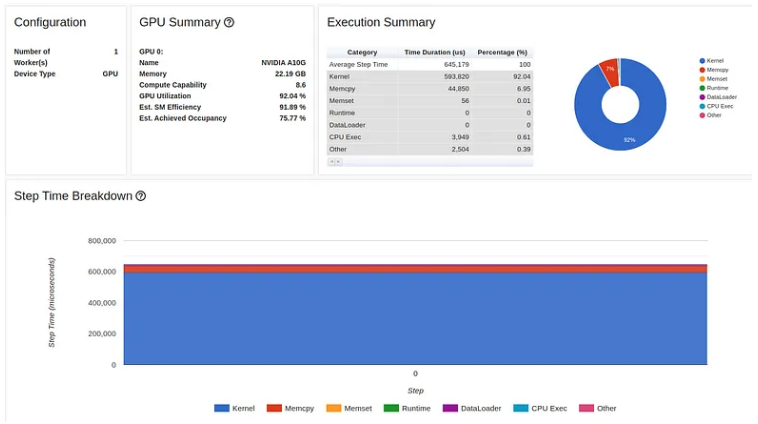
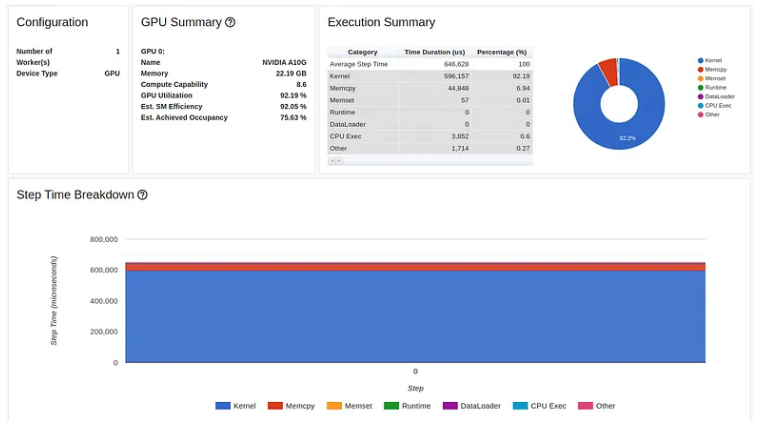
令人失望的是,我们的第一次优化对步骤时间的影响非常小。如果我们查看跟踪视图报告,我们可以看到我们有一个需要解决的新的严重性能问题。
我们的新报告表明我们的weighted_nll 函数存在问题。和以前一样,我们使用 torch.profiler.record_function 来识别有问题的代码行。在本例中,它是断言调用。
def weighted_nll(pred, target, weight):
with torch.profiler.record_function('assert'):
assert target.max() < 10
with torch.profiler.record_function('range'):
r = range(target.shape[0])
with torch.profiler.record_function('index'):
nll = -pred[r, target]
with torch.profiler.record_function('nll_calc'):
nll = nll * weight[target]
nll = nll/ weight[target].sum()
sum_nll = nll.sum()
return sum_nll
请注意,这个问题也存在于基础实验中,但被我们之前的性能问题隐藏了。在性能优化过程中,以前被其他问题隐藏的严重问题突然以这种方式出现的情况并不罕见。
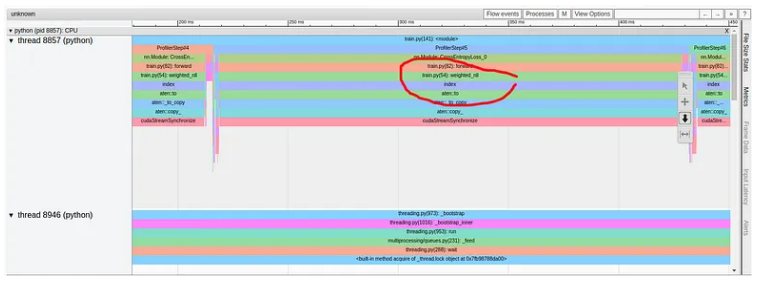
对调用堆栈的仔细分析显示了对“item”、“_local_scalar_dense”和“cudaMemcpyAsync”的调用。这通常表明数据正在从 GPU 复制到主机。事实上,我们在 CPU 上执行的断言调用需要访问驻留在 GPU 上的目标张量,从而调用效率极低的数据复制。
优化2:从训练步骤中删除冗余的 GPU 到主机副本
虽然验证输入标签的合法性可能是有必要的,但其方式应该不会对我们的训练性能产生如此负面的影响。在我们的例子中,解决问题很简单,只需在将标签复制到 GPU 之前将断言移动到数据输入管道即可。删除断言后,我们的性能仍然基本保持不变:
重要提示:虽然我们的目标通常是尝试减少前向传播中主机和 GPU 之间的副本,但有时这是不可能的(例如,如果我们需要 GPU 不支持的内核)或不受欢迎的(例如,如果在 CPU 上运行特定内核会提高性能)。
分析跟踪视图向我们介绍了下一个性能问题:
我们再次看到之前的优化发现了一个新的严重性能问题,这次是在索引我们的 pred 张量时。索引由 r 和目标张量定义。虽然目标张量已经驻留在 GPU 上,但上一行定义的 r 张量却没有。这再次触发低效的主机到 GPU 数据复制。
优化3:用 torch.arange 替换 range
Python 的 range 函数在 CPU 上输出一个列表。训练步骤中任何列表的存在都应该是一个危险信号。在下面的代码块中,我们用 torch.arange 替换 range 的使用,并将其配置为直接在 GPU 上创建输出张量:
def weighted_nll(pred, target, weight):
with torch.profiler.record_function('range'):
r = torch.arange(target.shape[0], device="cuda:0")
with torch.profiler.record_function('index'):
nll = -pred[r, target]
with torch.profiler.record_function('nll_calc'):
nll = nll * weight[target]
nll = nll/ weight[target].sum()
sum_nll = nll.sum()
return sum_nll
本次优化的结果如下所示:
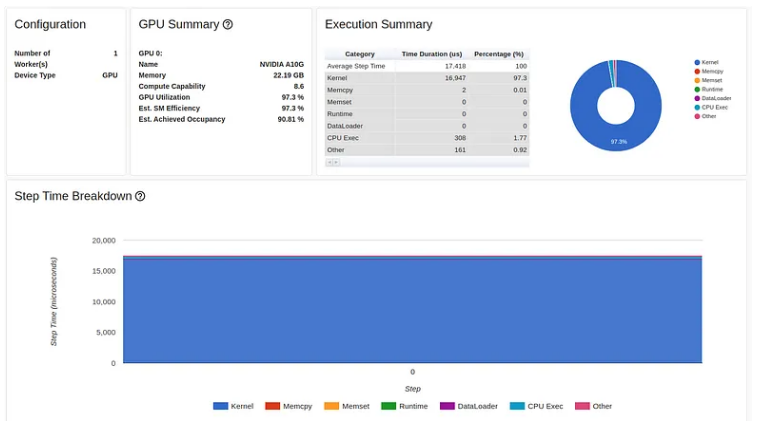
现在我们正在说话!!我们的步长时间已降至 5.8 毫秒,性能提升了 3700%。
更新后的跟踪视图显示损失函数已降至非常合理的 0.5 毫秒。
但仍有改进的空间。让我们仔细看看weighted_nll函数的跟踪视图,它占据了损失计算的大部分。
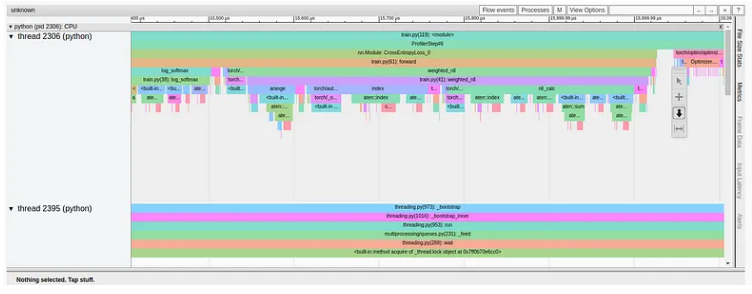
从跟踪中我们可以看到,该函数由多个小块组成,每个小块最终映射到一个单独的 CUDA 内核,该内核通过 CudaLaunchKernel 调用加载到 GPU 上。理想情况下,我们希望减少 GPU 内核的总数,从而减少 CPU 和 GPU 之间的交互量。一种方法是尽可能选择更高级别的 PyTorch 运算符,例如 torch.nn.NLLLoss。此类函数被认为将底层操作“融合”在一起,因此需要较少数量的总体内核。
优化5:避免在训练步骤中初始化对象
在下面的代码块中,我们修改了损失实现,以便在 init 函数中创建 torch.nn.NLLLoss 的单个实例。
class CrossEntropyLoss(nn.Module):
def __init__(self):
super().__init__()
self.weight = torch.Tensor([0.1]*10).cuda()
self.nll = torch.nn.NLLLoss(self.weight)
def forward(self, input, target):
pred = log_softmax(input)
loss = self.nll(pred, target)
return loss
结果显示步骤时间进一步改善,现在为 5.2 毫秒。
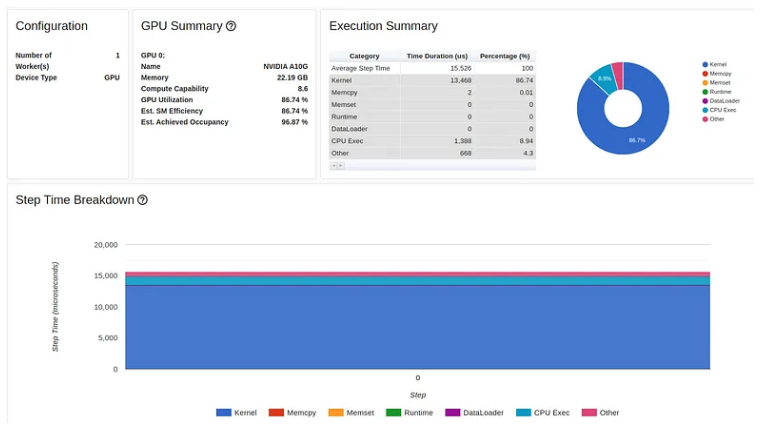
优化6:使用 torch.nn.CrossEntropyLoss 而不是自定义损失
PyTorch 包含一个内置的 torch.nn.CrossEntropyLoss,我们现在对其进行评估并与我们的自定义损失实现进行比较。
criterion = torch.nn.CrossEntropyLoss().cuda(device)
由此产生的步长时间达到了 5 毫秒的新低,整体性能提升了 4200%(与我们开始时的 216 毫秒相比)。
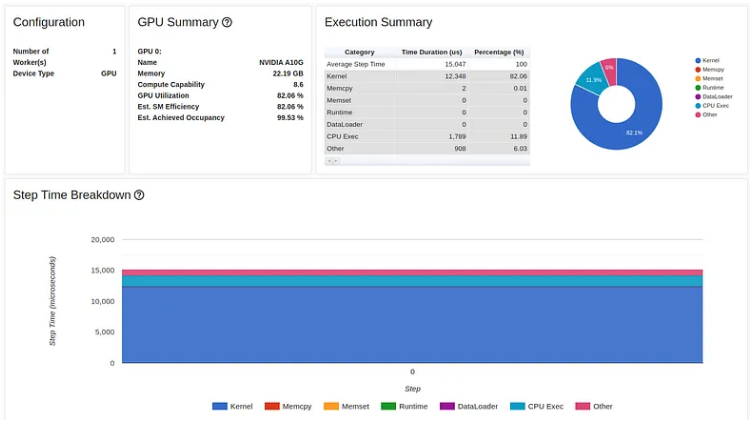
损失计算的前向传递的性能提升更加显着:从 211 毫秒的起始点,我们一路下降到 79 微秒(!!),如下所示:
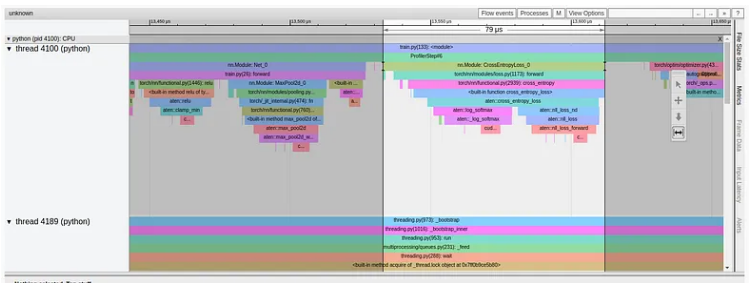
优化7:编译损失函数
对于我们的最终优化尝试,我们将使用 torch.compile API 将损失函数配置为在图形模式下运行。正如我们在本文中详细讨论并在本文前传中演示的那样,torch.compile 将使用内核融合和乱序执行等技术,以以下方式将损失函数映射到低级计算内核:最适合底层训练加速器。
criterion = torch.compile(torch.nn.CrossEntropyLoss().cuda(device))
下图显示了该实验的 Trace View 结果。
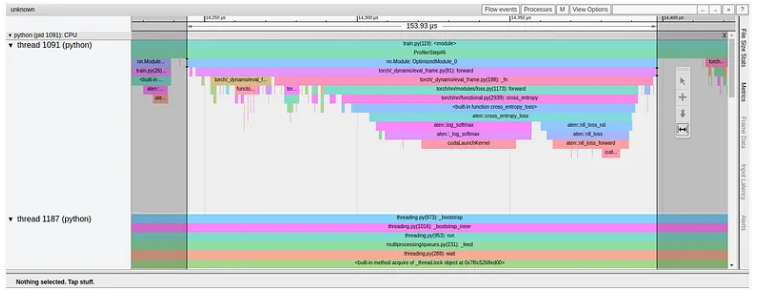
我们首先看到的是包含“OptimizedModule”和“dynamo”的术语的出现,它们表明了 torch.compile 的使用。我们还可以看到,在实践中,模型编译并没有减少损失函数加载的内核数量,这意味着它没有识别任何额外内核融合的机会。事实上,在我们的例子中,损失编译实际上导致损失函数的前向传递时间从 79 微秒增加到 154 微秒。看来 CrossEntropyLoss 还不够丰富,无法从这种优化中受益。
您可能想知道为什么我们不能将 torch 编译应用于我们的初始损失函数并依靠它以最佳方式编译我们的代码。这可以省去我们上面描述的逐步优化的所有麻烦。这种方法的问题在于,尽管 PyTorch 2.0 编译(截至撰写本文时)确实优化了某些类型的 GPU 到 CPU 交叉,但某些类型会使图形编译崩溃,而另一些类型将导致创建多个小图而不是单个大图。最后一类会导致图表中断,这从本质上限制了 torch.compile 功能提高性能的能力。 (解决此问题的一种方法是调用 torch.compile,并将 fullgraph 标志设置为 True。)
结果
在下表中,我们总结了我们运行的实验的结果:
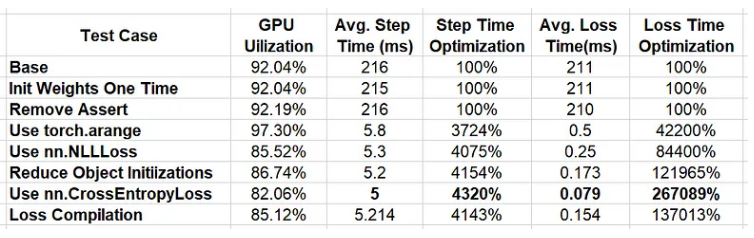
我们的连续优化带来了令人惊叹的 4143% 性能提升!回想一下,我们从一个看起来很无辜的损失函数开始。如果没有对应用程序的行为进行深入分析,我们可能永远不会知道有什么问题,并且会继续我们的生活,同时支付比我们需要的多 41 倍(!!)的费用。
您可能已经注意到,在我们的最终试验中,GPU 利用率显着下降。这表明进一步性能优化的巨大潜力。虽然我们的示威已接近尾声,但我们的工作还没有完成。
总结
让我们总结一下我们学到的一些东西。我们将摘要分为两部分。首先,我们描述了一些可能影响训练性能的编码习惯。在第二部分中,我们推荐一些性能分析技巧。请注意,这些结论基于我们在本文中分享的示例,可能不适用于您自己的用例。机器学习模型的属性和行为差异很大。因此,强烈建议您根据自己项目的细节来评估这些结论。
Reference
Source: https://towardsdatascience.com/pytorch-model-performance-analysis-and-optimization-part-2-3bc241be91
本文由 mdnice 多平台发布