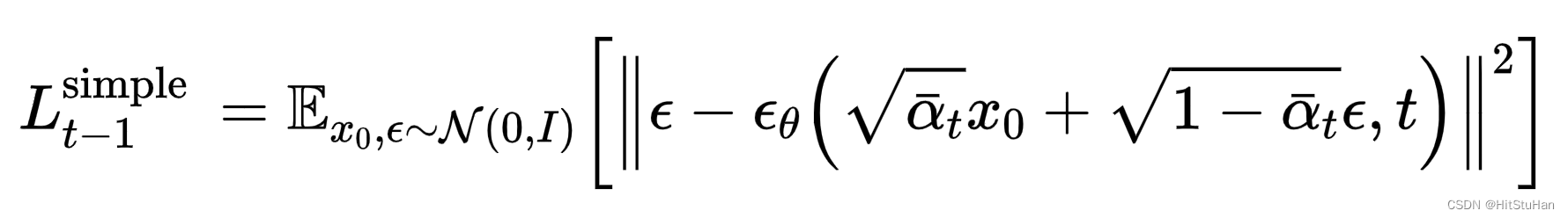什么要对数据库做读写分离优化。
存在下面两个问题,所以要进行数据库优化
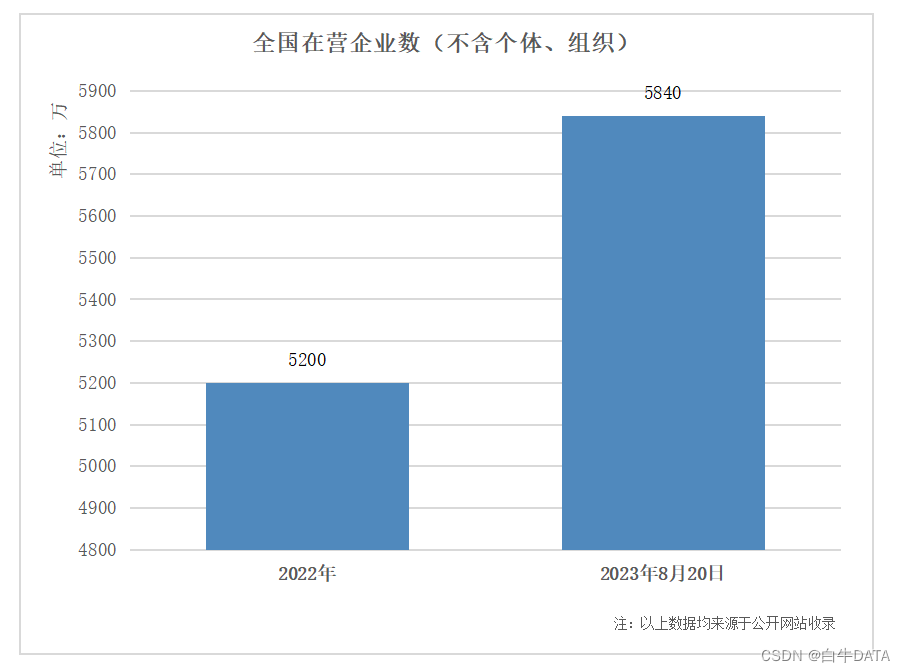
- 单表不能太大:mysql官方说法:单表2000万数据,就到达瓶颈了。,所以说为了保证查询效率,得让每张表的大小得到控制。
- 查询压力大:在项目中往往是 查询使用的频率 》 增删改的使用的频率,也就是,读的频率》 写的频率
读的使用频率大,写的使用频率小,所以我们可以考虑 读用一个数据库,写用一个数据库
MySQL支持的两主架构通常指的是主从复制(Master-Slave Replication)和主主复制(Master-Master Replication),它们都是用来实现数据库的数据备份、负载均衡和高可用性的方案。
主主模式

在主主复制中,有两个数据库充当主数据库,每个主数据库都可以处理写入和读取操作。这种架构常用于需要高可用性和负载均衡的场景。但是,主主复制需要更复杂的配置和处理冲突的机制,因为两个主数据库都可以同时进行写入操作,可能会导致数据冲突。
实现方式
读数据的时候,从两个主数据库中任意一个去查询
写数据得时候
第一种:一个数据库有变更数据,就自动同步到另一个数据库
第二种:双写,写完一个数据库的时候,再把另一个数据库也写了。
主主复制的特点:
- 高可用性:即使一个主数据库发生故障,另一个主数据库仍然可用。
- 负载均衡:两个主数据库共同处理写操作,有助于分散负载。
- 写入冲突:由于两个主数据库都可以写入数据,可能需要解决数据冲突问题
总结:因为它有可能会数据冲突,所以还是有缺陷,不推荐。
主从模式
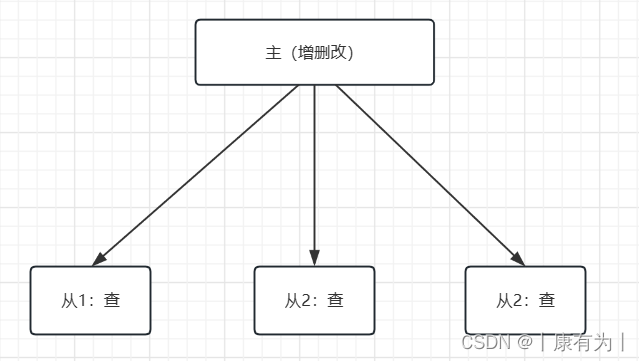
如上图所示,在主从复制中,有一个主数据库(Master)和一个或多个从数据库(Slave)。
主数据库负责处理写入操作(INSERT、UPDATE、DELETE等),而从数据库则复制主数据库的数据更改,通常用于读操作。
也就是 主数据库增删改的时候自动同步到从数据库
主从复制的特点:
- 读写分离:主数据库处理写操作,从数据库处理读操作,从而分担负载。
- 数据备份:从数据库可以用于灾难恢复和数据备份。
- 负载均衡:通过将读流量分散到多个从数据库,可以实现负载均衡。
- 自动晋升:在主数据库出现故障时,可以将一个从数据库提升为新的主数据库。
总结:只做到了缓解查询压力,但是没有解决数据库单表太大的问题,因为主库还是有全部的数据,没有其他库可以为它分担一些压力,所以还是不推荐。
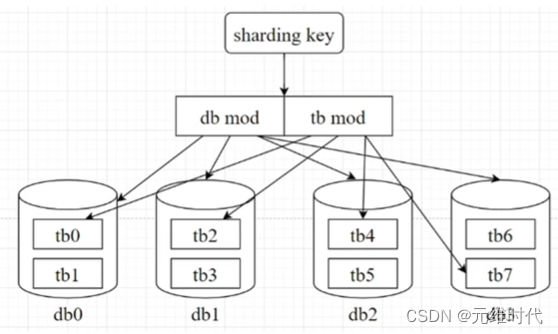
多主多从
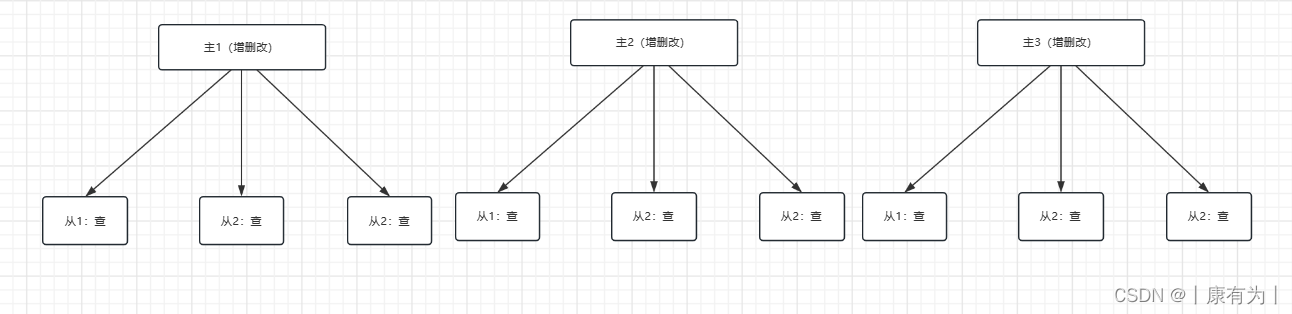
为了解决主从模式的问题,我们可以使用多主多重的模式。
将表拆开,拆成几个子表,然后分别使用主从模式,这样就解决了主从模式没有解决数据库单表太大的问题。
实现方式
具体怎么查分表?可以用取余的操作,如果你要拆分成3个子表,那就对3进行取余,余0一个表,余1一个表,余2一个表
程序在进行操作之前,先计算出来应该走哪个库
冷热分离
如果数据量再大,几亿的那种的时候,可以采取冷热分离的策略。
冷热分离(Hot-Cold Separation)是数据库优化中的一种策略,旨在通过将访问频率较低的数据(冷数据)和访问频率较高的数据(热数据)分开存储和管理,以提高数据库性能、降低成本,并优化查询效率。这种策略通常应用于大型数据库环境,其中数据集非常庞大且访问模式存在明显的变化。
- 热数据是指经常被访问的数据,如最近的数据或常用的数据。
- 冷数据则是相对不经常被访问的数据,比如历史数据或不常用的数据。
代码实现读写分离
mybatisPlus实现多数据源
多数据源 | MyBatis-Plus (baomidou.com)
1.引入dynamic-datasource-spring-boot-starter。
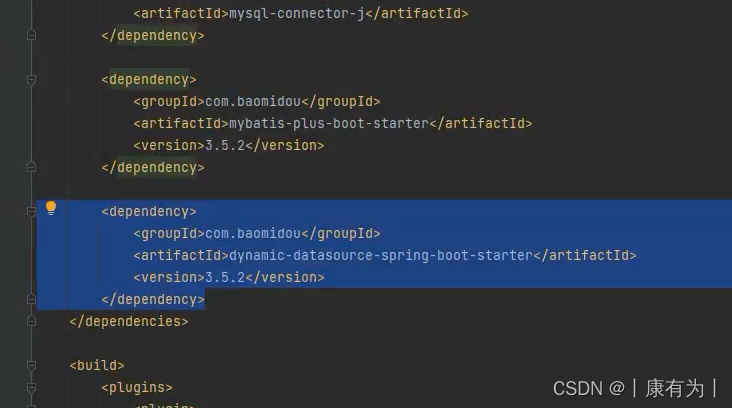
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>${version}</version>
</dependency>2.配置数据源。
在yaml配置文件中配置,master 就是主数据库,slave_1就是一个从数据库,也就是一个项目引入了多个数据库
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master
strict: false #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
datasource:
master:
url: jdbc:mysql://xx.xx.xx.xx:3306/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver # 3.2.0开始支持SPI可省略此配置
slave_1:
url: jdbc:mysql://xx.xx.xx.xx:3307/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
slave_2:
url: ENC(xxxxx) # 内置加密,使用请查看详细文档
username: ENC(xxxxx)
password: ENC(xxxxx)
driver-class-name: com.mysql.jdbc.Driver
#......省略
#以上会配置一个默认库master,一个组slave下有两个子库slave_1,slave_2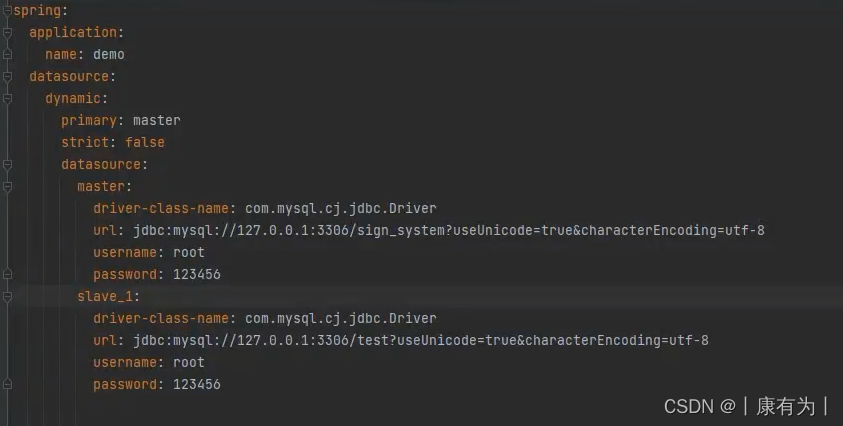
使用 @DS 切换数据源。
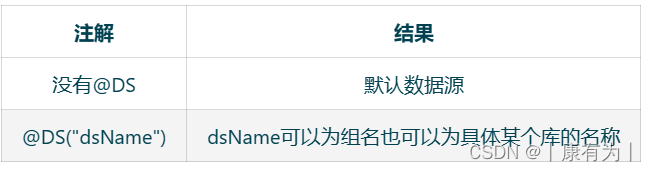
例如:不用的mapper可以通过注解连接不同的数据库
一个mapper连接master数据库
对应这配置文件中的
datasource:
master: 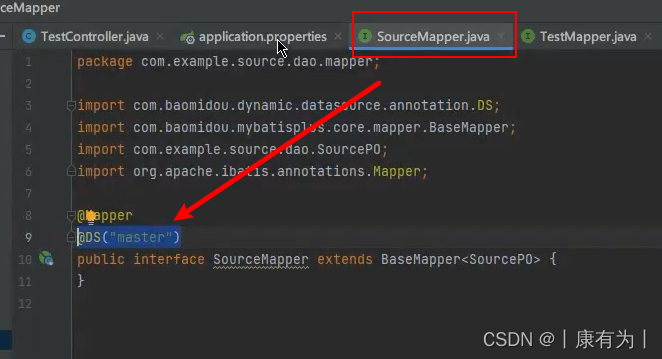

方法1:手动加注解(不推荐)
直接用mybatisPlus的这个注解
@DS 可以注解在方法上或类上,同时存在就近原则 方法上注解 优先于 类上注解。

我们就可以 让某个mapper里只有读操作给其加个注解,某个mapper里面只有增删改操作给其加个注解
或者直接查询方法上加注解走“查询库”,增删改的方法上加注解走“写库”
优点:
- 简单
缺点:
- 代码改动量太大了,很多地方都要加注解
- 用条件构造器的方法没办法指定
方法2:mybatis拦截器(不推荐)
通过拦截器来切换数据库,拦截所有的sql,出现insert、update、delete就走主库,出现select就走从库
优点:对代码侵入比较小
缺点:事务没办法保证
方法3:中间件
既能代码侵入小,又能保证事务,这样的最好
方案1:mycat
部署mycat,使用mycat进行数据源管理
MyCAT是一个强大的数据库中间件,不仅仅可以用作读写分离,以及分表分库、容灾管理,而且可以用于多租户应用开发、云平台基础设施,让你的架构具备很强的适应性和灵活性。
适用于有专门团队维护的大型企业,或者大团队。
太麻烦了,还得部署这里不推荐。
方案2:sharding-jdbc(推荐)
是一个类似mybatis的东西,我们可以不用部署其他中间件,也不需要改代码。
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零。
适用于中小企业,或者中小团队。
具体的用sharding-jdbc 实现读写分离,请看下集讲解。