一、目的
在kettle的转换任务以及共享资源库、Carte服务创建好后,需要对kettle的转换任务用海豚调度器进行调度,调度的前提的写好脚本。所以,这篇博客首先介绍在Linux上脚本运行kettle的转换任务
二、前提准备
(一)我的kettle任务为转换任务ktr,不是作业任务kjb
(二)ktr任务使用pan文件,kjb任务使用的是kitchen文件
注意:两种任务使用两种文件,它们使用是不同的文件
(三)这篇博客是在Linux上脚本运行kettle转换任务,不是在Windows本地脚本运行kettle转换任务
(四)下方这篇博客详细的介绍了转换执行器pan和作业执行器Kitchen的使用方法,所以我这边只展示转换执行器pan的使用方法,如果需要查看作业执行器Kitchen的使用方法,请自行查看下方的博客链接
http://t.csdn.cn/hc6SI![]() http://t.csdn.cn/hc6SI
http://t.csdn.cn/hc6SI
(五)kettle任务已保存到kettle共享资源库的目录文件里
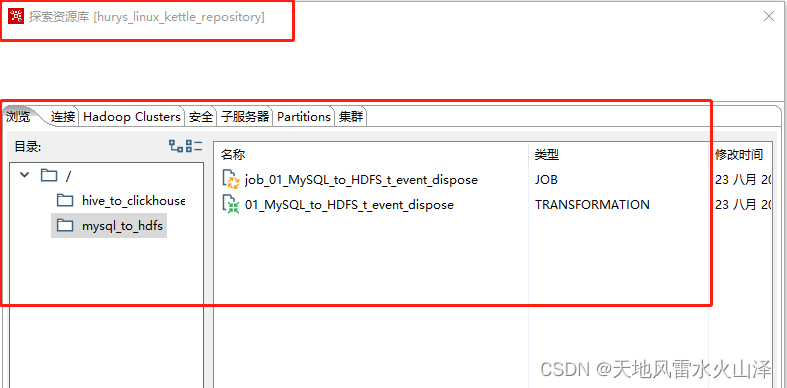
1、在资源库根目录右键——创建新目录,输入目录名,点击🆗
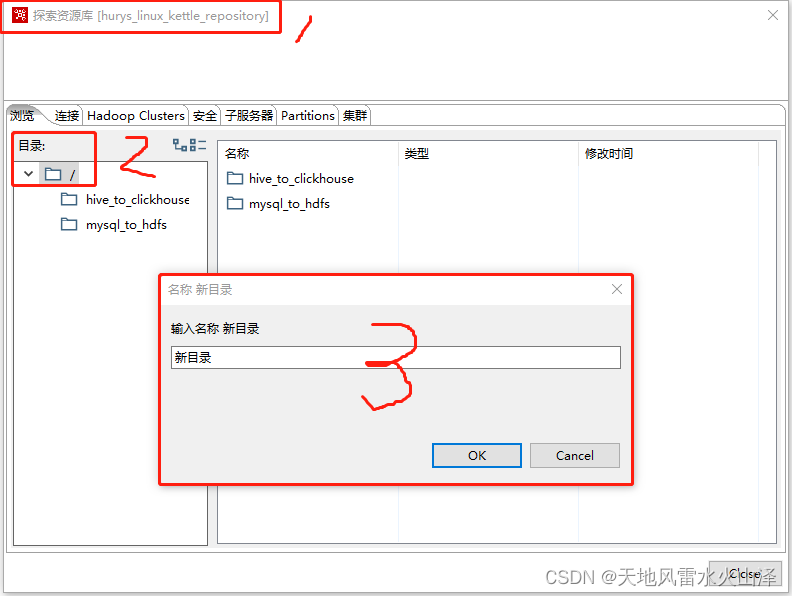
2、在保存kettle任务时,点击要保存到资源库的文件夹下

3、打开资源库的对应文件夹下查看转换1任务是否保存

如图所示,kettle任务样例转换1在资源库的mysql_to_hdfs文件夹下保存成功!
三、转换执行器pan介绍
(一)pan简介
pan是一个转换执行器,专门用来执行kettle的转换任务
(二)pan工具的官网文档
Use Command Line Tools to Run Transformations and Jobs - Hitachi Vantara Lumada and Pentaho Documentation
(三)pan在Linux上执行kettle转换任务命令语句(官网案例)
sh pan.sh -rep=initech_pdi_repo -user=pgibbons -pass=lumburghsux -trans=TPS_reports_2011

(四)pan在Windows本地执行kettle转换任务命令语句(官网案例)
pan.bat /rep:initech_pdi_repo /user:pgibbons /pass:lumburghsux /trans:TPS_reports_2011
(五)pan参数含义(非常重要!非常重要!非常重要!)
| 序号 | 参数名 | 参数含义 |
| 1 | rep | 资源库名称 |
| 2 | user | 用户名 |
| 3 | pass | 密码 |
| 4 | trans | 要启动的转换任务的名称 |
| 5 | dir | 资源库目录 |
| 6 | file | 如果调用的是本地ktr文件,则为文件名;如果不在本地目录中,则包括路径 |
| 7 | level | 日志级别(基本、详细、调试、行级别、错误、无)(Basic, Detailed, Debug, Rowlevel, Error, Nothing) |
| 8 | logfile | 将日志输出写入的本地文件名 |
| 9 | listdir | 列出指定资源库中的文件目录 |
| 10 | listtrans | 列出指定文件目录里的转换任务 |
| 11 | listrep | 列出可用的资源库 |
| 12 | exprep | 将所有存储库对象导出到一个 XML 文件 |
| 13 | norep | 防止 Pan(Kitchen)登录到存储库。如果您已经设置了 KETTLE_REPOSITORY、KETTLE_USER 和 KETTLE_PASSWORD 环境变量,那么这个选项将使您能够阻止 Pan( Kitchen)登录到指定的存储库,假设您要执行本地 KTR 文件 |
| 14 | safemode | 在安全模式下运行,可以进行额外检查 |
| 15 | version | 显示版本、修订和构建日期 |
| 16 | param | 以name=value 格式设置命名参数 。例如: -param:FOO=bar |
| 17 | listparam | 列出有关指定转换中定义的命名参数的信息 |
| 18 | maxloglines | PDI 内部保留的最大日志行数。设置为 0 以保留所有行(默认) |
| 19 | maxlogtimeout | 由 PDI 内部保留的日志行的最长期限(以分钟为单位)。设置为 0 以无限期地保留所有行(默认) |
注释:这19个pan的参数,除了红色标记的3个参数外,其余16个都是pan和kitchen的通用参数
另附kitchen的特有参数
| 序号 | 参数名 | 参数含义 |
| 1 | job | 要启动的作业任务的名称 |
| 2 | listjob | 列出指定资源库文件夹里的作业任务 |
(六)pan参数的语句案例
1、listrep(列出可用的资源库)
sh /opt/install/kettle9.2/data-integration/pan.sh -listrep

找到资源库:hurys_linux_kettle_repository
 2、listdir(列出指定资源库中的文件目录)
2、listdir(列出指定资源库中的文件目录)
sh /opt/install/kettle9.2/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -listdir

找到资源库的文件目录hive_to_clickhouse、mysql_to_hdfs

3、listtrans(列出指定文件目录里的转换任务)
sh /opt/install/kettle9.2/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/mysql_to_hdfs/ -listtrans

找到文件夹mysql_to_hdfs的转换任务01_MySQL_to_HDFS_t_event_dispose

(七)pan的运行状态码
1、官网文档截图

2、运行状态码及其含义
| 运行状态码 | 状态码含义 |
| 0 | 转换运行没有问题 |
| 1 | 处理过程中发生错误 |
| 2 | 加载/运行转换期间发生意外错误 |
| 3 | 无法准备和初始化此转换 |
| 7 | 无法从 XML 或存储库加载转换 |
| 8 | 加载步骤或插件时出错(主要是加载插件之一时出错) |
| 9 | 命令行使用打印 |
四、pan命令语句执行kettle转换任务
(一)在Linux中执行pan命令语句,运行转换任务,没有日志文件
1、在Linux中执行pan命令语句
sh /opt/install/kettle9.2/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/mysql_to_hdfs/ -trans=01_MySQL_to_HDFS_t_event_dispose

2、pan命令语句执行结果:转换成功
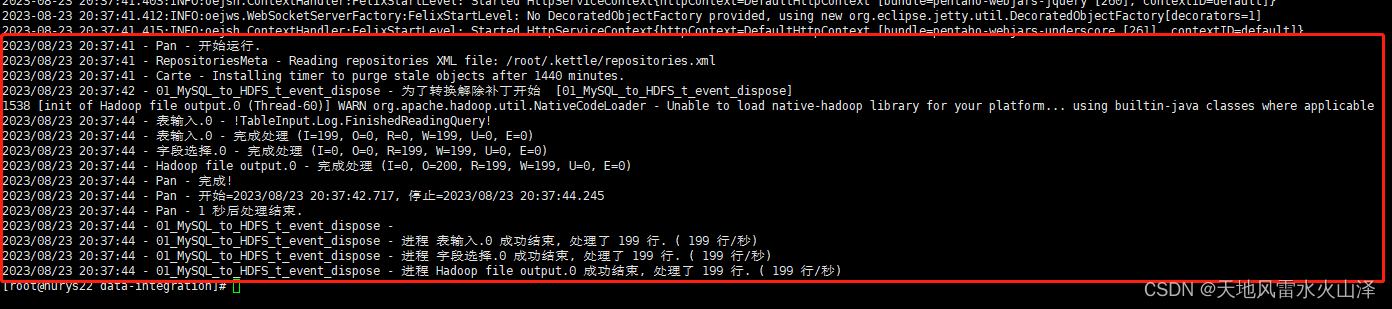
3、由于kettle任务是从MySQL到HDFS,所以还可以到Hadoop中验证一下文件

(二)在Linux中执行pan命令语句,运行转换任务,导出日志到文件
1、在Linux中执行pan命令语句
sh /opt/install/kettle9.2/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/mysql_to_hdfs/ -trans=01_MySQL_to_HDFS_t_event_dispose level=Basic >>/home/log/kettle/01_MySQL_to_HDFS_t_event_dispose_`date +%Y%m%d`.log
注意:提前创建好日志文件路径/home/log/kettle
2、pan命令语句执行结果:转换成功

3、由于kettle任务是从MySQL到HDFS,所以还可以到Hadoop中验证一下文件

4、由于pan语句导出日志到日志文件,因此可以查看日志文件
到/home/log/kettle路径下找到对应的日志文件,然后vi打开查看

# vi 01_MySQL_to_HDFS_t_event_dispose_20230824.log
可以看到日志中,kettle的转换任务执行成功!
五、Linux上脚本运行kettle的转换任务
(一)前提条件
1、Linux上kettle转换任务的存储位置

2、脚本文件存放目录下执行脚本(首先需要对脚本赋权)

脚本赋权后ll查看脚本

(二)不使用资源库,脚本运行Linux本地上的kettle转换任务
1、kettle脚本内容

#!/bin/bash
source /etc/profile
/opt/install/kettle9.2/data-integration/pan.sh -file=/opt/soft/kettle_job/01_mysql_to_hdfs_t_event_dispose.ktr >> /home/log/kettle/01_mysql_to_hdfs_t_event_dispose_`date +%Y%m%d`.log
2、sh执行脚本(注意 /root/.kettle/里的配置文件,不要有资源库文件)
sh test_no.sh
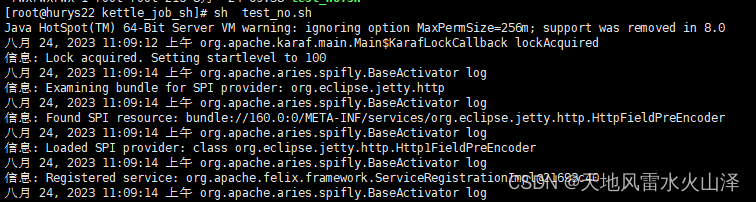
3、脚本执行结果(执行时间11:09:18)

4、 由于kettle任务是从MySQL到HDFS,所以还可以到Hadoop中验证一下文件
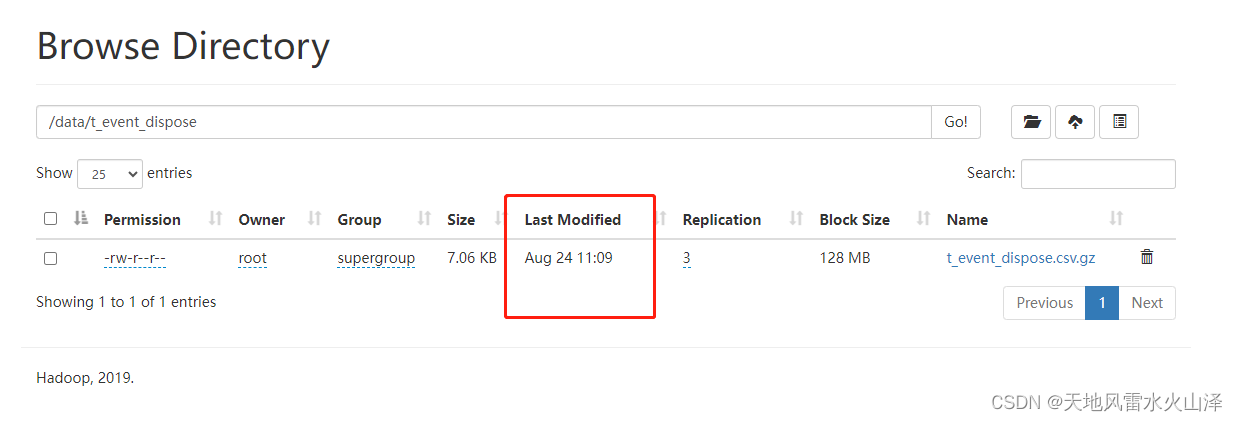
文件时间是11:09
5、 查看11:09 的日志文件

# vi 01_MySQL_to_HDFS_t_event_dispose_20230824.log
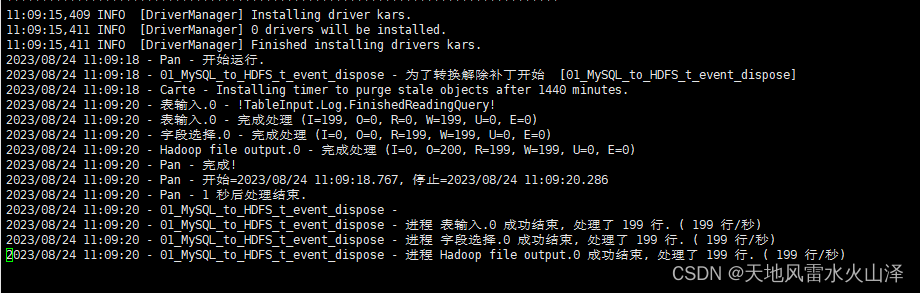
可以看到日志中,kettle的转换任务执行成功!
(三)使用资源库,脚本运行Linux上的kettle转换任务
1、kettle脚本内容
#!/bin/bash
source /etc/profile
/opt/install/kettle9.2/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/mysql_to_hdfs/ -trans=01_MySQL_to_HDFS_t_event_dispose level=Basic >>/home/log/kettle/01_MySQL_to_HDFS_t_event_dispose_`date +%Y%m%d`.log

2、sh执行脚本(注意 /root/.kettle/里的配置文件,一定要有资源库文件)
# sh test1.sh
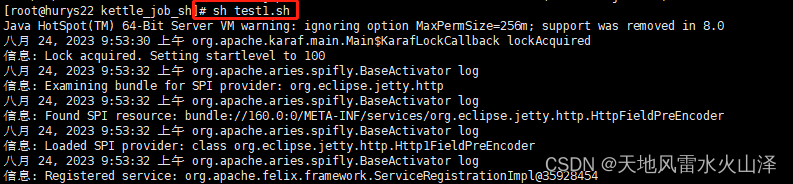
3、脚本执行结果(执行时间09:53)

4、 由于kettle任务是从MySQL到HDFS,所以还可以到Hadoop中验证一下文件
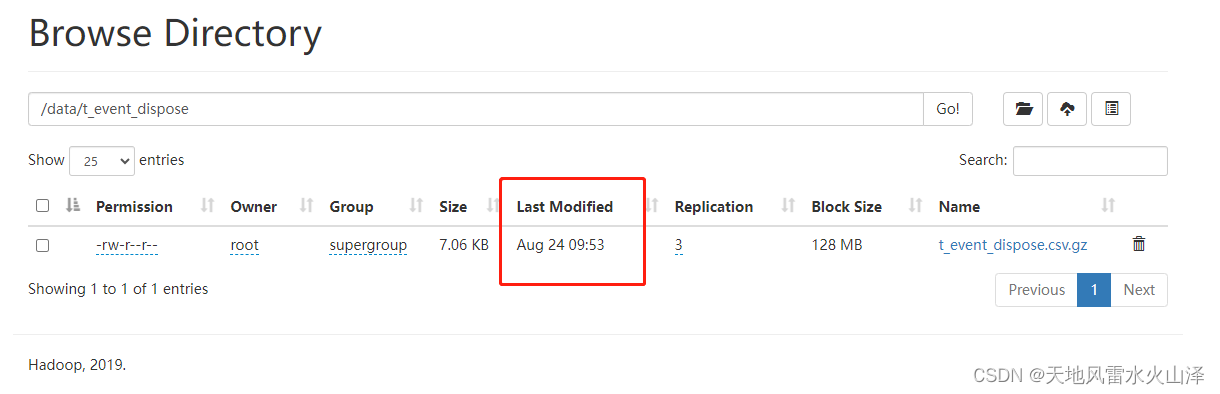
5、 查看09:53的日志文件
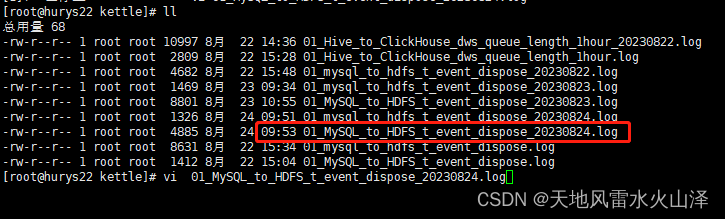
# vi 01_MySQL_to_HDFS_t_event_dispose_20230824.log
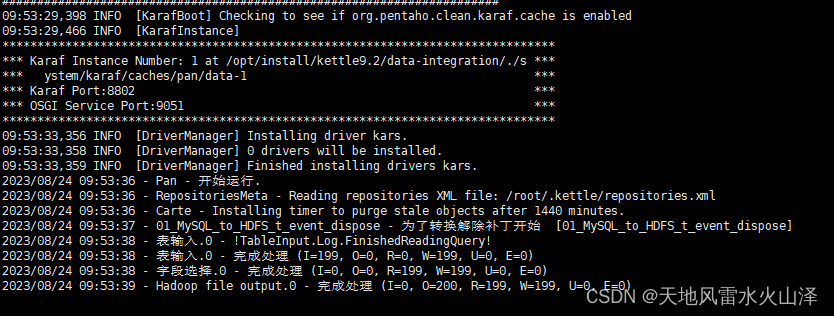
可以看到日志中,kettle的转换任务执行成功!
到这里,Linux上脚本运行kettle的转换任务就成功了,包括Linux本地和Linux资源库两种!
最要注意是转换任务的执行器pan,它的参数和kitchen是不太一样的。尤其pan的任务参数是trans,而kitchen的任务参数是job
至于在Windows本地执行kettle的转换任务pan命令语句请参考下面博客
http://t.csdn.cn/YGSSz![]() http://t.csdn.cn/YGSSz
http://t.csdn.cn/YGSSz
乐于奉献共享,帮助你我他!