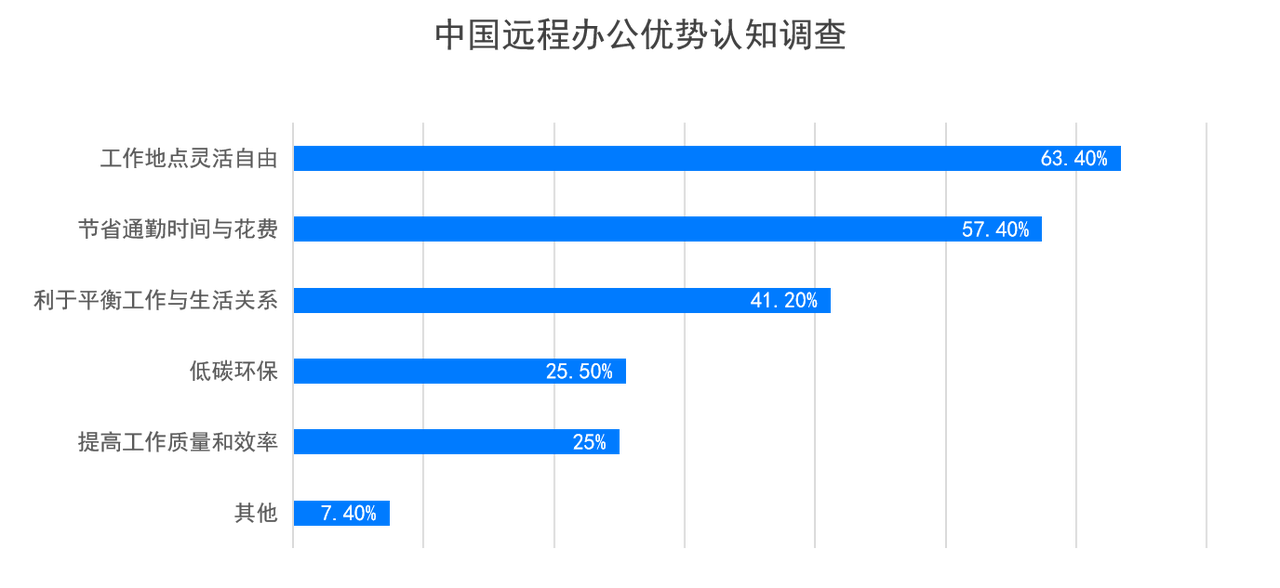
mysql日志篇
1、Undo-log 撤销日志
Undo即撤销的意思,大家通常也习惯称它为回滚日志。如果大家有仔细研究过 MySQL 的日志,应该会发现 Undo-log 并不存在单独的日志文件,也就是磁盘中并不会存在 xx-undo.log 这类的文件,那 Undo-log 存在哪儿呢?InnoDB 默认是将 Undo-log 存储在 xx.ibdata 共享表数据文件当中,默认采用段的形式存储。
也就是当一个事务尝试写某行表数据时,首先会将旧数据拷贝到 xx.ibdata 文件中,将表中行数据的隐藏字段:roll_ptr 回滚指针会指向 xx.ibdata 文件中的旧数据,然后再写表上的数据。实际上当一个事务需要回滚时,本质上并不会以执行反 SQL 的模式还原数据,而是直接将 roll_ptr 回滚指针指向的 Undo 记录,从 xx.ibdata 共享表数据文件中拷贝到 xx.ibd 表数据文件,覆盖掉原本改动过的数据。
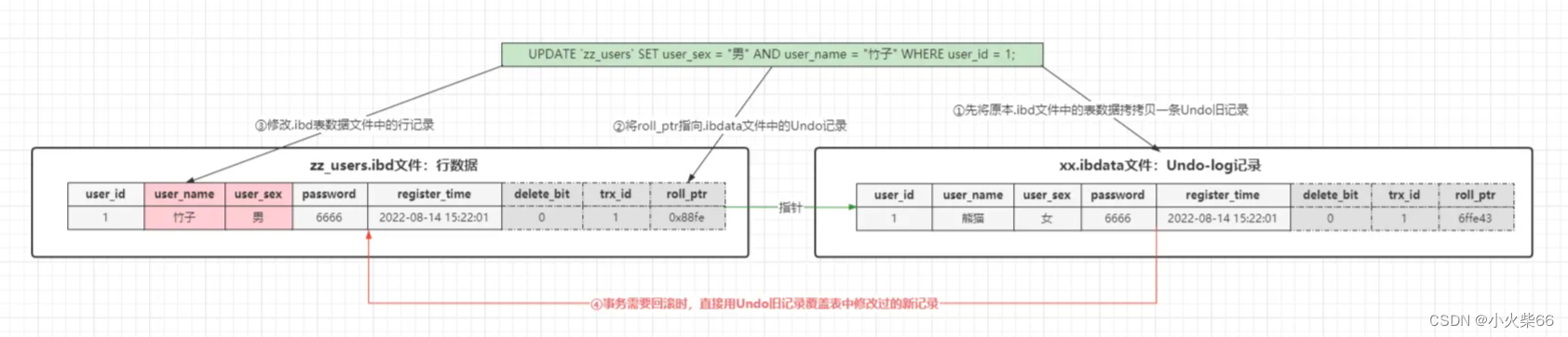
备注:如果是 insert 操作,由于插入之前这条数据都不存在,那么就不会产生 Undo 记录,此时回滚时如何删除这条记录呢?因为插入操作不会产生 Undo 旧记录,因此隐藏字段中的 roll_ptr=null,因此直接用 null 覆盖插入的新记录即可,这样也就实现了回滚的效果
Undo-log 中记录的旧数据并不仅仅只有一条,一条相同的行数据可能存在多条不同版本的 Undo 记录,内部会通过 roll_ptr 回滚指针,组成一个单向链表,而这个链表则被称之为 Undo 版本链,案例如下:
-- 事务T1:trx_id=1(两次修改同一条数据)
UPDATE `zz_users` SET user_name = "竹子" WHERE user_id = 1;
UPDATE `zz_users` SET user_sex = "男" WHERE user_id = 1;
Undo-log 中的旧数据版本链示意图大致如下:
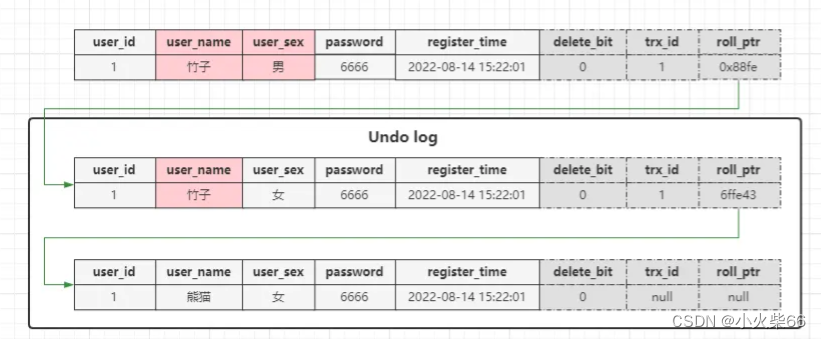
InnoDB 在 MySQL 启动时,会在内存中构建一个 BufferPool,而这个缓冲池主要存放两类东西,一类是数据相关的缓冲,如索引、锁、表数据等,另一类则是各种日志的缓冲,如 Undo、Bin、Redo… 等日志。而当一条写 SQL 执行时,不会直接去往磁盘中的 xx.ibdata 文件写数据,而是会写在 undo_log_buffer 缓冲区中,因为工作线程直接去写磁盘太影响效率了,写进缓冲区后会由后台线程去刷写磁盘。
2、Redo-log 重做日志
详细聊明白了 Undo-log 后,紧接着再来看看它的同胞兄弟:Redo-log 日志,为啥说它两是同胞兄弟呢?因为这两日志都是 InnoDB 引擎独有的,Undo-log 主要用于实现事务回滚和 MVCC 机制,而 Redo-log 则用来实现数据的恢复。众所周知,MySQL 绝大部分引擎都是是基于磁盘存储数据的,但如若每次读写数据都走磁盘,其效率必然十分低下,因此 InnoDB 引擎在设计时,当 MySQL 启动后就会在内存中创建一个 BufferPool,运行过程中会将大量操作汇集在内存中进行,比如写入数据时,先写到内存中,然后由后台线程再刷写到磁盘。因为数据写到内存后mysql宕机了就会有数据丢失风险,这明显违背了事务 ACID 原则中的持久性,所以 Redo-log 的出现就是为了解决该问题。Redo-log 是一种预写式日志,即在向内存写入数据前,会先写日志,当后续数据未被刷写到磁盘、MySQL 崩溃时,就可以通过日志来恢复数据,确保所有提交的事务都会被持久化。
⚠️注意: 工作线程执行 SQL 前,写的 Redo-log 日志,也是写在了内存中的 redo_log_buffer 缓冲区。既然 Redo-log 日志也是先写内存,那 Redo-log 有没有丢失的风险呢?这跟 Redo-log 的刷盘策略有关。
2.1、Redo-log 刷盘策略
- 间隔一段时间,然后再刷写一次日志到磁盘(性能最佳)。
- 每次提交事务时,都刷写一次日志到磁盘(性能最差,最安全,默认策略)。
- 有事务提交的情况下,每间隔一秒时间刷写一次日志到磁盘。
默认是处于第二个级别,也就是每次提交事务时都会刷盘,这也就意味着一个事务执行成功后,相应的 Redo-log 日志绝对会被刷写到磁盘中,因此无需担心会出现丢失风险。
再来思考一个问题:既然 Redo-log 要写磁盘,那为何不在写日志的时候,直接把数据写到磁盘里面去呢?先刷写一次 Redo-log 日志到磁盘,后台线程再根据 Redo-log 日志把数据落盘,这个动作似乎看起来有些多余对吧?但实际上这样做好处很大:
①日志比数据先落入磁盘,因此就算 MySQL 崩溃也可以通过日志恢复数据。
②写日志时是以追加形式写到末尾,而写数据时则是计算数据位置,随机插入。
对于第一点好处就不多说了,重点来聊一聊第二点,因为写日志的时候,只需要将记录追加到日志文件的尾部即可,这是按顺序写入,但写入表数据时,还需要先先计算数据的位置,比如修改一条数据时,需要先判断这条数据在磁盘文件中的那个位置,找到了位置再写入,这是随机写入,顺序写入的速度会比随机写入快很多很多。
3、Bin-log 变更日志
Bin-log 日志也被称之为二进制日志,作用与 Redo-log 类似,主要是记录所有对数据库表结构变更和表数据修改的操作,对于 select、show 这类读操作并不会记录。bin-log 是 MySQL-Server 级别的日志,也就是所有引擎都能用的日志,而 redo-log、undo-log 都是 InnoDB 引擎专享的,无法跨引擎生效。下面看一下sql语句的执行流程图:
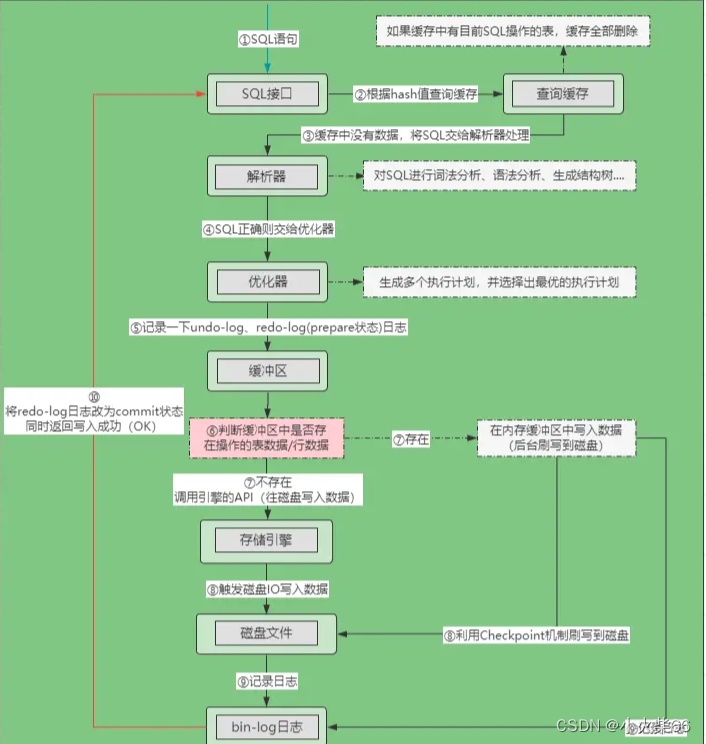
重点观察里面的第⑨步,无论当前表使用的是什么引擎,实际上都需要完成记录 bin-log 日志这步操作,和之前分析的两种日志相同,bin-log 也由内存日志缓冲区 + 本地磁盘文件两部分组成,这也就意味着:写 bin-log 日志时,也会先写缓冲区,然后由后台线程去刷盘。
3.1、Bin-log 缓冲区
为啥要单独把 bin-log 的缓冲区拎出来讲呢?因为它跟 redo-log、undo-log 的缓冲区并不同,前面分析的两种日志缓冲区,都位于 InnoDB 创建的共享 BufferPool 中,而 bin_log_buffer 是位于每条线程中的,关系图如下:
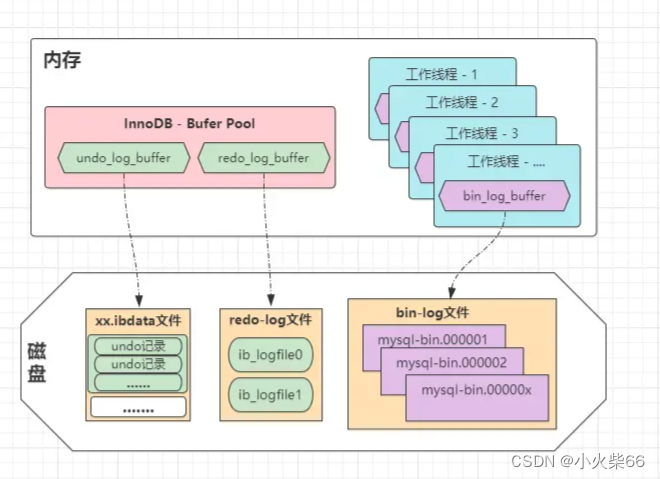
也就是说,MySQL-Server 会给每一条工作线程,都分配一个 bin_log_buffer,而并不是放在共享缓冲区中,这是为啥呢?因为 MySQL 设计时要兼容所有引擎,直接将 bin-log 的缓冲区,设计在线程的工作内存中,这样就能够让所有引擎通用,并且不同线程 / 事务之间,由于写的都是自己工作内存中的 bin-log 缓冲,因此并发执行时也不会冲突!
在 bin-log 的本地文件中,其中存储的日志记录共有 Statment、Row、Mixed 三种格式,分别是啥意思呢?
-- 查询一次用户表数据,如下:
SELECT * FROM `zz_users`;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
| 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 |
| 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 |
| 4 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:59 |
| 9 | 黑竹 | 男 | 9999 | 2022-09-28 22:31:44 |
+---------+-----------+----------+----------+---------------------+
-- 将用户表中所有 ID>3的密码重置
update `zz_users` set `password` = "1111" where user_id > 3;
3.1.1 Statment
Statment:每一条会对数据库产生变更的 SQL 语句都会记录到 bin-log 中;比如上述这个事务执行时,MySQL 会将第二条 update 语句记录在 bin-log 日志中,但对于 select 语句则不会记录(在记录 SQL 时,还会记录一下 SQL 的上下文信息,如执行时间、事务 ID、日志量…)。这种方式的优势很明显,由于只记录对数据库产生变更操作的 SQL,所以不会产生太大的日志量,节约空间,恢复数据时因为数据量小,所以磁盘 IO 次数少,因此性能会比较不错。同时做主备等高可用架构时,数据同步也会较小,因此比较节省带宽。但虽然优势不小,但缺点页很明显,即恢复数据、主从同步数据时,有时会出现数据不一致的情况,如 SQL 中使用了 sysdate()、now() 这类函数,比如举个简单的例子:
insert into `zz_users` values(11,"棕熊","男","3333",sysdate());
比如这条插入语句,由于对用户表产生了变更操作,所以会被记录到 bin-log 中,但当主从架构之间做数据同步时,假设将这条 SQL 同步到从机上执行,此时问题就来了,sysdate() 函数会获取机器的当前时间,但主机和从机执行这条 SQL 显然不是同一时间,因此就会导致 ID=11 的这条数据,在主机和从机的用户表中,注册时间会出现不一致。
3.1.2 Row
Row:这种模式就是为了解决 Statment 模式的缺陷,Row 模式中不再记录每条造成变更的 SQL 语句,而是记录具体哪一个分区中的、哪一个页中的、哪一行数据被修改了。这又怎么理解呢?还是以前面的重置密码的例子来说:
-- 将用户表中所有 ID>3的密码重置(ID=4、9的两条数据会被重置)
update `zz_users` set `password` = "1111" where user_id > 3;
在这种模式下,就不会记录这条 update 语句,而是记录发生改变的行数据,即 ID=4、9 的两条用户数据,会将其更改后的值记录到 bin-log 日志中。这种方式因为不记录 SQL,而是记录修改后的值,因此有个很大的好处是:当主从同步数据时,复制的是主机上的数据,因此不会出现主从数据不一致的情况。但缺陷同样很明显,比如表中有 800W 数据,现在我对 ID<600W 的所有数据进行了修改操作,哪也就意味着会有 600W 条记录写入 bin-log 日志,这个数据量可想而知,其磁盘 IO、网络带宽开销会很高。
3.1.3 Mixed
Mixed:这种被称为混合模式,即 Statment、Row 的结合版,因为 Statment 模式会导致数据出现不一致,而 Row 模式数据量又会很大,因此 Mixed 模式结合了两者的优劣势,对于可以复制的 SQL 采用 Statment 模式记录,对于无法复制的 SQL 采用 Row 记录。这样即保留了 Statment 模式的数据量小,又具备 Row 模式的数据精准性,如果比较熟悉 Redis4.x 版本的小伙伴应该会有种熟悉感,Redis 的 RDB、AOF 持久化模式,正好对应 MySQL 的 Statment、Row 模式,而 Redis4.0 引入了混合持久化机制,MySQL5.1 版本也引入了混合日志模式。
4、总结
4.1、Redo-log、Bin-log 两者的区别
- 生效范围不同,Redo-log 是 InnoDB 专享的,Bin-log 是所有引擎通用的。
- 写入方式不同,Redo-log 是用两个文件循环写,而 Bin-log 是不断创建新文件追加写。
- 文件格式不同,Redo-log 中记录的都是变更后的数据,而 Bin-log 会记录变更 SQL 语句。
- 使用场景不同,Redo-log 主要实现故障情况下的数据恢复,Bin-log 则用于数据灾备、同步。
4.2、误删了大量数据,用 Redo-log还是Bin-log恢复数据更合适呢?
答案是 Bin-log,因为 Redo-log 采用循环写的方式,一边写会一边擦,里面无法得到完整的数据,而 Bin-log 是追加写的模式,你不去主动删除磁盘的日志文件,并且磁盘的空间还足够,一般 Bin-log 日志文件都会在本地,因此当你删库后,可以直接去本地找 Bin-log 的日志文件,然后拷贝出来一份,再打开最后一个文件,把里面删库的记录手动移除,再利用 mysqlbinlog 工具导出 xx.SQL 文件,最后执行该 SQL 文件即可恢复删库前的数据。
4.3、为了保证数据的一致性,mysql采用两阶段提交
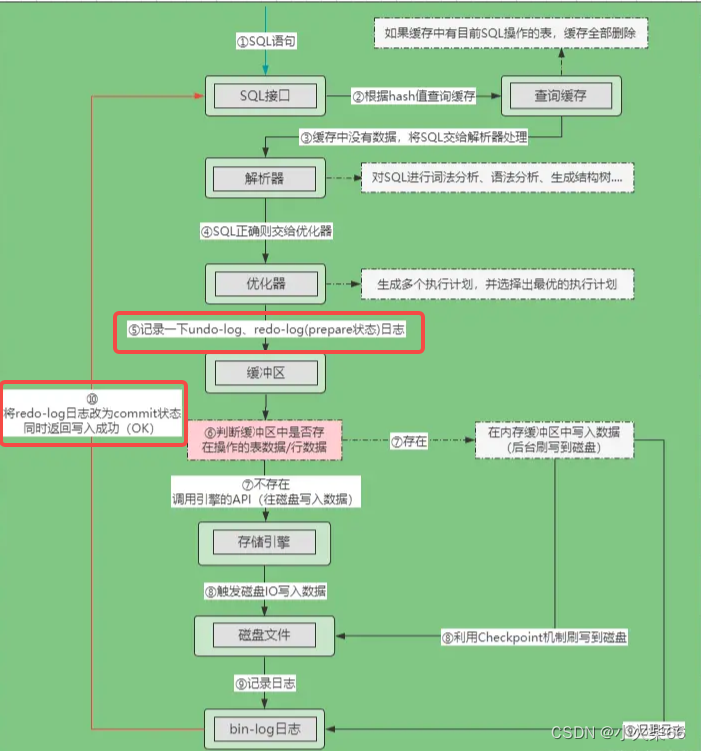
其中第⑤、⑩步,分别会写两次 Redo-log 日志,这个日志的作用前面讲的很明白了,主要用来做崩溃恢复,但为什么要分两次写呢?写一次不行嘛?如果只写一次的话,那到底先写 bin-log 还是 redo-log 呢?
先写 bin-log,再写 redo-log:当事务提交后,先写 bin-log 成功,结果在写 redo-log 时断电宕机了,再重启后由于 redo-log 中没有该事务的日志记录,因此不会恢复该事务提交的数据。但要注意,主从架构中同步数据是使用 bin-log 来实现的,而宕机前 bin-log 写入成功了,就代表这个事务提交的数据会被同步到从机,也就意味着从机会比主机多出一条数据。
先写 redo-log,再写 bin-log:当事务提交后,先写 redo-log 成功,但在写 bin-log 时宕机了,主节点重启后,会根据 redo-log 恢复数据,但从机依旧是依赖 bin-log 来同步数据的,因此从机无法将这个事务提交的数据同步过去,毕竟 bin-log 中没有撒,最终从机会比主机少一条数据。
经过上述分析后可得知:如果 redo-log 只写一次,那不管谁先写,都有可能造成主从同步数据时的不一致问题出现,为了解决该问题,redo-log 就被设计成了两阶段提交模式,设置成两阶段提交后,整个执行过程有三处崩溃点:
- redo-log(prepare):在写入准备状态的 redo 记录时宕机,事务还未提交,不会影响一致性。
- bin-log:在写 bin 记录时崩溃,重启后会根据 redo 记录中的事务 ID,回滚前面已写入的数据。
- redo-log(commit):在 bin-log 写入成功后,写 redo(commit) 记录时崩溃,因为 bin-log 中已经写入成功了,所以从机也可以同步数据,因此重启时直接再次提交事务,写入一条 redo(commit) 记录即可。
通过这种两阶段提交的方案,就能够确保 redo-log、bin-log 两者的日志数据是相同的,bin-log 中有的主机再恢复,如果 bin-log 没有则直接回滚主机上写入的数据,确保整个数据库系统的数据一致性。


![[附源码]Node.js计算机毕业设计高校宿舍管理系统Express](https://img-blog.csdnimg.cn/617b8c9f786244629d24b4e581dc787f.png)