工作时,有时需要快速启动功能性Hadoop集群来测试一些hadoop相关的项目及功能。
本文讲解如何基于docker,快速搭建一个功能性Hadoop集群,来测试验证一些功能。
使用的docker镜像
使用的docker镜像的源码地址是:hadoop-hive-3.1.x-postgres
对应的docker-compose.yml包含如下服务:
- namenode - Apache Hadoop NameNode
- datanode - Apache Hadoop DataNode
- resourcemanager - Apache Hadoop YARN Resource Manager
- nodemanager - Apache Hadoop YARN Node Manager
- historyserver - Apache Hadoop YARN Timeline Manager
- hs2 - Apache Hive HiveServer2
- metastore - Apache Hive Metastore
- metastore-db - Postgres DB that supports the Apache Hive Metastore
环境搭建
下载源码
git clone https://github.com/timveil/docker-hadoop.git
mv hadoop-hive-3.1.x-postgres hive
cd hive
修改配置
- 将core.env中的资源配置修改为:
YARN_CONF_yarn_nodemanager_resource_memory___mb=2048 - 修改docker-compose配置文件,主要是暴露namenode的9820及datanode的9866端口
修改后的docker-compose文件
version: "3.7"
services:
namenode:
image: timveil/docker-hadoop-namenode:3.2.x
container_name: namenode
hostname: namenode
environment:
- CLUSTER_NAME=hive-3.1.x
env_file:
- core.env
- yarn-remote.env
ports:
- "9870:9870"
- "9820:9820"
datanode:
image: timveil/docker-hadoop-datanode:3.2.x
container_name: datanode
hostname: datanode
environment:
- SERVICE_PRECONDITION=namenode:9870
env_file:
- core.env
- yarn-remote.env
ports:
- "9864:9864"
- "9866:9866"
resourcemanager:
image: timveil/docker-hadoop-resourcemanager:3.2.x
container_name: resourcemanager
hostname: resourcemanager
environment:
- SERVICE_PRECONDITION=namenode:9870 datanode:9864
env_file:
- core.env
- yarn-resource-manager.env
ports:
- "8088:8088"
nodemanager:
image: timveil/docker-hadoop-nodemanager:3.2.x
container_name: nodemanager
hostname: nodemanager
environment:
- SERVICE_PRECONDITION=namenode:9870 datanode:9864 resourcemanager:8088
env_file:
- core.env
- yarn-node-manager.env
ports:
- "8042:8042"
historyserver:
image: timveil/docker-hadoop-historyserver:3.2.x
container_name: historyserver
hostname: historyserver
environment:
- SERVICE_PRECONDITION=namenode:9870 datanode:9864 resourcemanager:8088
env_file:
- core.env
- yarn-timeline.env
ports:
- "8188:8188"
hs2:
image: timveil/docker-hadoop-hive-hs2:3.1.x
container_name: hs2
hostname: hs2
environment:
- SERVICE_PRECONDITION=metastore:9083
env_file:
- core.env
- yarn-remote.env
- hive.env
ports:
- "10000:10000"
- "10002:10002"
metastore:
image: timveil/docker-hadoop-hive-metastore:3.1.1
container_name: metastore
hostname: metastore
environment:
- SERVICE_PRECONDITION=namenode:9870 datanode:9864 metastore-db:5432
env_file:
- core.env
- yarn-remote.env
- hive.env
- metastore.env
depends_on:
- namenode
- datanode
- metastore-db
metastore-db:
image: timveil/docker-hadoop-hive-metastore-db:3.1.x
container_name: metastore-db
hostname: metastore-db
启动/停止
docker-compose up -d
docker-compose down
测试
显露的UI WEB
- Name Node Overview - http://localhost:9870
- Data Node Overview - http://localhost:9864
- YARN Resource Manager - http://localhost:8088
- YARN Node Manager - http://localhost:8042
- YARN Application History - http://localhost:8188
- HiveServer 2 - http://localhost:10002
命令行测试
测试hdfs
$ docker-compose exec namenode bash
# hdfs dfs -ls hdfs://namenode:9820/
# hdfs dfs -lsr hdfs://namenode:9820/
测试hive
$ docker-compose exec hs2 bash
# /opt/hive/bin/beeline -u jdbc:hive2://localhost:10000
> show databases;
> show tables;
> CREATE TABLE pokes (foo INT, bar STRING);
> LOAD DATA LOCAL INPATH '/opt/hive/examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
> SELECT * FROM pokes;
> !quit
测试其它功能
docker exec -ti namenode /bin/bash
docker exec -ti datanode /bin/bash
docker exec -ti resourcemanager /bin/bash
docker exec -ti nodemanager /bin/bash
docker exec -ti historyserver /bin/bash
docker exec -ti hs2 /bin/bash
docker exec -ti metastore /bin/bash
docker exec -ti metastore-db /bin/bash
JAVA代码测试
基本测试
- pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.cloud.coder</groupId>
<artifactId>hadoop-test</artifactId>
<version>1.0-SNAPSHOT</version>
<name>hadoop-test</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
- java源码
package org.cloud.coder;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import java.io.IOException;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class HDFSClientTest {
private static Configuration conf=null;
private static FileSystem fs=null;
//初始化方法,用于和HDFS集群建立连接
@Before
public void connect2HDFS() throws IOException {
//设置客户端的身份,以用于和HDFS集群建立连接
System.setProperty("HADOOP_USER_NAME","root");
//创建配置对象
conf = new Configuration();
//设置操作的文件系统时HDFS,并且指定HDFS操作地址
conf.set("fs.defaultFS","hdfs://localhost:9820");
//创建FileDSystem对象实例
fs = FileSystem.get(conf);
}
//测试:创建文件夹
@Test
public void mkdir() throws IOException {
//首先判断文件夹是否存在
if(!fs.exists(new Path("/test"))){
//创建文件夹
fs.mkdirs(new Path("/test"));
}
}
@Test
public void listDir() throws IOException {
RemoteIterator<LocatedFileStatus> list = fs.listFiles(new Path("/"),true);
while(list.hasNext()){
LocatedFileStatus fileStatus = list.next(); System.out.println(String.format("%s,%s,%s,%s",fileStatus.isDirectory(),fileStatus.getPath(),fileStatus.getLen(),fileStatus.toString()));
}
}
//关闭客户端和HDFS的连接
@After
public void close(){
//首先判断文件系统实例是否为null
if(fs!=null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
kerberos连接测试
- Java在访问Kerberos认证系统的HDFS时,需要用principal和生成的keytab文件,然后生成UserGroupInformation对象,保存生成的Ticket。
- 但是每次登陆的时候需要用到UserGroupInformation,但有时不需要也可以,因为UserGroupInformation中的Subject对象是绑定在当前的线程中
- 若不是同一个线程,则每次都需要重新登陆,但是通过
UserGroupInformation.doAs方法,它在验证的时候,会切换线判断是否登陆。
public class HDFSKerberosTest {
public static void main(String[] args) throws Exception {
//需要设置krb5.conf文件
System.setProperty("java.security.krb5.conf", "src/main/resources/krb5.conf");
String principal = "hdfs"; //Kerberos Principal,如果不然REALM,则使用krb5.conf默认的
String keytabFile = "src/main/resources/hdfs.keytab"; //KDC生成的keytab文件
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
conf.set("fs.defaultFS", "hdfs://localhost:9820"); //HDFS地址
//使用kerberos认证
// UserGroupInformation.loginUserFromKeytab(principal, keytabFile);
UserGroupInformation ugi = UserGroupInformation.getLoginUser();
//使用UserGroupInformation来获FileSystem
FileSystem fs = ugi.doAs(new PrivilegedExceptionAction<FileSystem>() {
@Override
public FileSystem run() throws Exception {
return FileSystem.get(conf);
}
});
FileStatus[] fileStatus = fs.listStatus(new Path("/"));
for (FileStatus fst : fileStatus) {
System.out.println(fst.getPath());
}
}
}
问题解决
启动hive metastore报错
启动hive metastore报如下错误:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
原因:
/opt/hadoop/share/hadoop/hdfs/lib/guava-27.0-jre.jar
/opt/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar
/opt/hive/lib/guava-19.0.jar
- 系统找不到相关jar包
- 同一类型的 jar 包有不同版本存在,系统无法决定使用哪一个
解决方案
删除hive中低版本的guava-19.0.jar包,将hadoop中的guava-27.0-jre.jar复制到hive的lib目录下即可。
具体操作如下:
docker run -it --rm timveil/docker-hadoop-hive-metastore:3.1.x bash
find / -name guava*
rm -rf /opt/hive/lib/guava-19.0.jar
cp /opt/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/hive/lib/
#然后docker commit
docker commit -m 'process java.lang.NoSuchMethodError' -a 'clouder' 容器ID timveil/docker-hadoop-hive-metastore:3.1.1
启动hive metastore后,立即退出
解决方案如下:
docker-compose run metastore bash
./run.sh
或
docker-compose run metastore /run.sh
文件上传下载 报错
在测试文件上传或下载时,可能会出现这样的错误提示:java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset。
原因:Hadoop访问windows本地文件系统,要求Windows上的本地库能正常工作,其中Hadoop使用某些Windows API来实现类似posix的文件访问权限,而这些功能需要hadoop.dll和winutils.exe来实现。
解决办法:下载Hadoop源码在windows平台编译,编译出windows本地库。然后配置Hadoop环境变量。
使用这里提供的 《hadoop-3.1.4_winutils.zip》(提取码:hadp ),配置好之后重启IDEA即可。具体配置方法如下:
将下载的压缩包解压放在一个名称为英文的目录下(例如D盘的softwares目录),然后在电脑的环境变量中做如下配置:
- HADOOP_HOME=D:\softwares\hadoop-3.1.4
- path=;%HADOOP_HOME%\bin
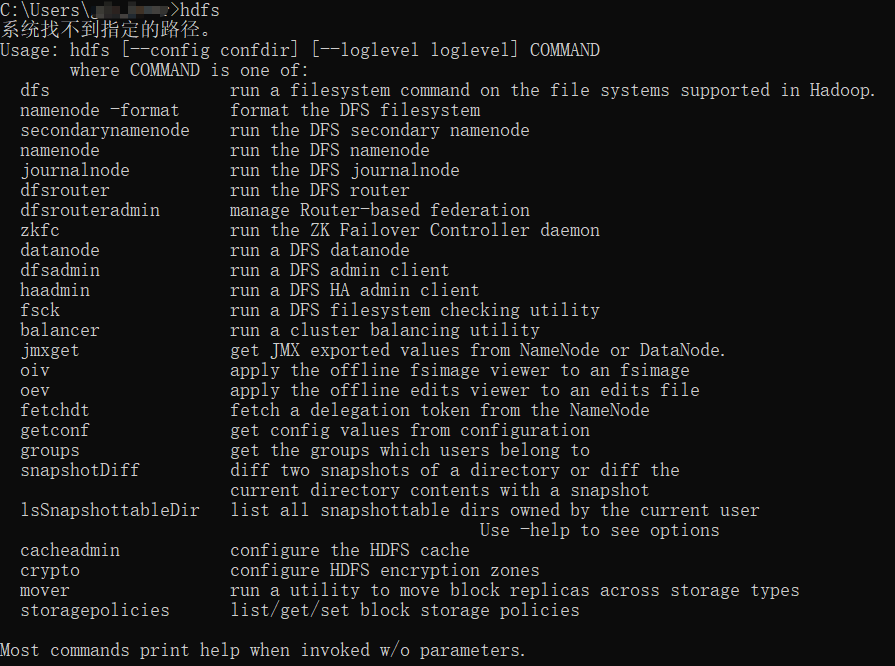
检查方法:在windows中的命令行模式下,输入命令hdfs,然后回车,如果出现以下结果,则说明配置成功。
参考
使用Java API访问HFDS
docker-hadoop-hive-metastore/blob/3.1.x/Dockerfile
hadoop-hive-3.1.x-postgres
![[附源码]Node.js计算机毕业设计高校宿舍管理系统Express](https://img-blog.csdnimg.cn/617b8c9f786244629d24b4e581dc787f.png)