1)关于切换场景加载耗时的优化问题
2)SpriteAtlas打包AssetBundle后运行时内存大小和什么有关系
3)手机上使用MRT的限制和兼容性
4)如何控制粒子系统组件数量的上限
这是第317篇UWA技术知识分享的推送。今天我们继续为大家精选了若干和开发、优化相关的问题,建议阅读时间10分钟,认真读完必有收获。
Loading
Q:在切场景时,为什么调整Application.backgroundLoadingPriority为High可以减少加载耗时呢?
A:Application.backgroundLoadingPriority这个API会限制主线程的集成的时间,默认设置是ThreadPriority.BelowNormal,也就是每一帧执行主线程集成的操作耗时不能超过4毫秒,这将会导致每一帧剩余的时间用于等待或者渲染,而这些等待和渲染的时间都是无意义的耗时。如果把这个设置改为ThreadPriority.High,那么每一帧执行主线程集成的操作耗时可以增加到50毫秒,大大减少了所需要的帧数。
这里主线程的集成时间体现在函数Application.Integrate Assets in Background上面,它会受到加载Texture、Mesh的Texture.AwakeFromLoad、Mesh.AwakeFromLoad的影响,另外对于比较复杂的Prefab(父子节点多,层数多)需要进行拼装,耗时也会体现在这个函数当中。
感谢龙粲@UWA问答社区提供了回答
AssetBundle
Q:SpriteAtlas打包AssetBundle后运行时内存大小和什么有关系?明明只有2张Atlas,2个纹理只有6MB,最终AssetBundle的内存却达到11.7MB。
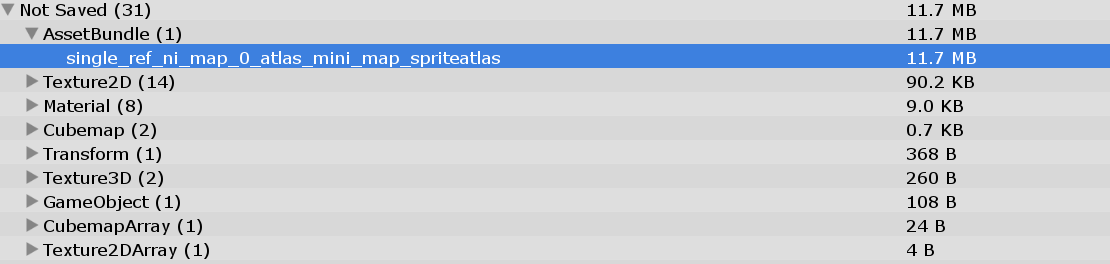
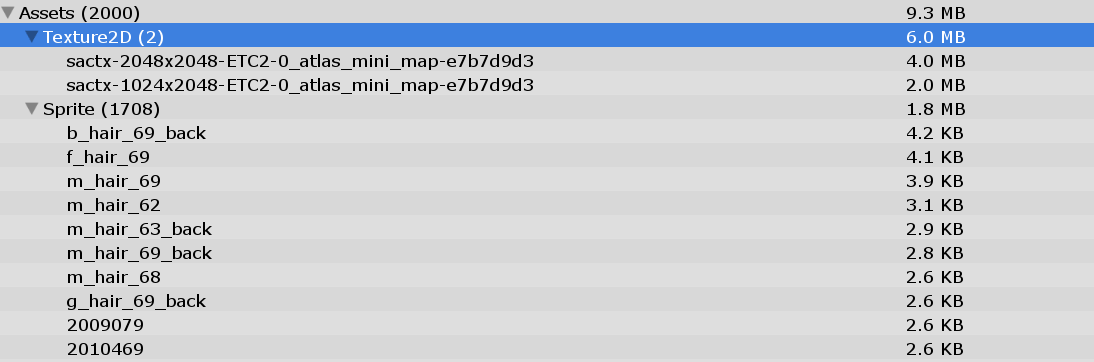
A:运行时AssetBundle大小会受到打包Sprite数量的影响,打包了1700个Sprite的情况下AssetBundle内存11.7MB。
测试了同样大小的SpriteAtlas,打包了6个1024*1024大小的Sprite,AssetBundle大小却只有4.9KB。

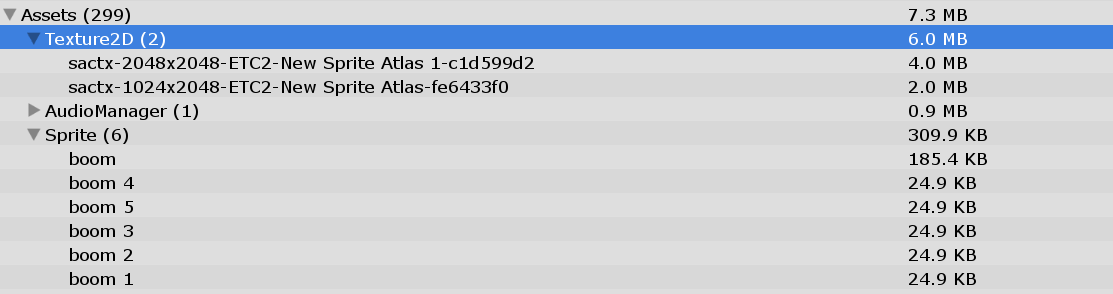
感谢宗卉轩@UWA问答社区提供了回答,
Rendering
Q:手机上使用MRT有什么限制吗,兼容性如何?
A:在支持OpenGL ES 3.0的手机上就支持MRT,可参考:
What's New in OpenGL ES 3.0 | Introduction to OpenGL ES 3.0 | InformIT
https://registry.khronos.org/OpenGL/specs/es/3.0/es_spec_3.0.pdf另外实测过,在红米4X这样非常低端的手机上,MRT也是可以正常运行的。红米4X的GPU是Adreno 505。
感谢Xuan@UWA问答社区提供了回答
Rendering
Q:项目Overdraw有点高,我们想做一个与MMO游戏里同屏角色数量上限类似的,粒子系统上限的功能。
也就是低端分档下,当粒子数量达到某个值以后,就不再往画面里画新的粒子了。但只对特效Prefab数量做限制还是比较模糊,毕竟不同特效的粒子数量不同,所以想精确到播放状态的粒子组件数量。
A1:用Find肯定很耗时,尽量用逻辑做。比如,粒子系统一般都做缓存池管理,可以直接把相关逻辑写在这里:做一个计数器C,某个特效E要实例化或出池时,同时传入它的子粒子数量A(提前配置好),加给C;入池再减掉A;对C作监控看是否在某个值内,否则停止所有实例化和出池操作。同理,给每个特效E挂一个触发器脚本,激活或隐藏的时候把子粒子数量A传给写在某处逻辑的计数器C即可。
另外实际做的时候,还可以给不同的粒子特效加上不同的计算影响系数,这样可以让某些特效(比如多人游戏中玩家角色的技能)出现的概率更高一些,而其他特效(其他玩家的技能)显示得少一些。
感谢Faust@UWA问答社区提供了回答
A2:提个思路,对于每一个特效Prefab,可以离线给这个Prefab做一个评分。对于场上存在的特效Prefab,记录总的特效评分,可以设置一个总的上限评分,超过就不显示。
这样问题就抛到了离线分析每个特戏Prefab评分上,评分参考维度可以参考:特效粒子发射器数量、特效overdraw、特效Batches、特效内存等等。
感谢范世青@UWA问答社区提供了回答
封面图来源于网络
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方问答社区:answer.uwa4d.com