ChatGPT
ChatGPT 的模型,它以对话方式进行交互。对话格式使 ChatGPT 可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。ChatGPT 是InstructGPT的兄弟模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。
ChatGPT 网址:https://chat.openai.com/chat
OpenAI blog ChatGTP:https://openai.com/blog/chatgpt/
使用教程 火爆全球的网红OpenAI ChatGPT注册教程

1.1 ChatGPT Model 训练
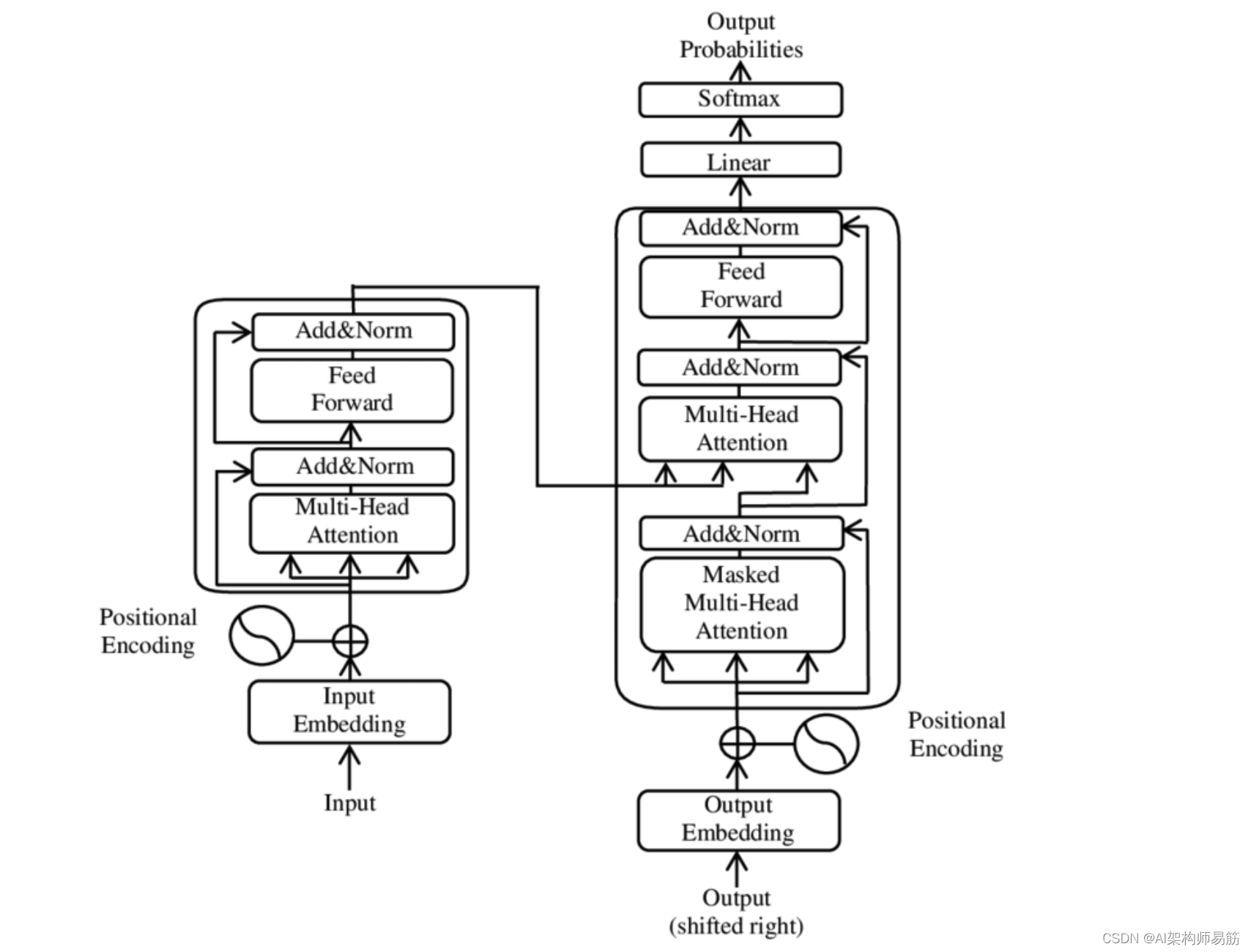
GPT 是用了The-Transformer-model-architecture的Decode 模块
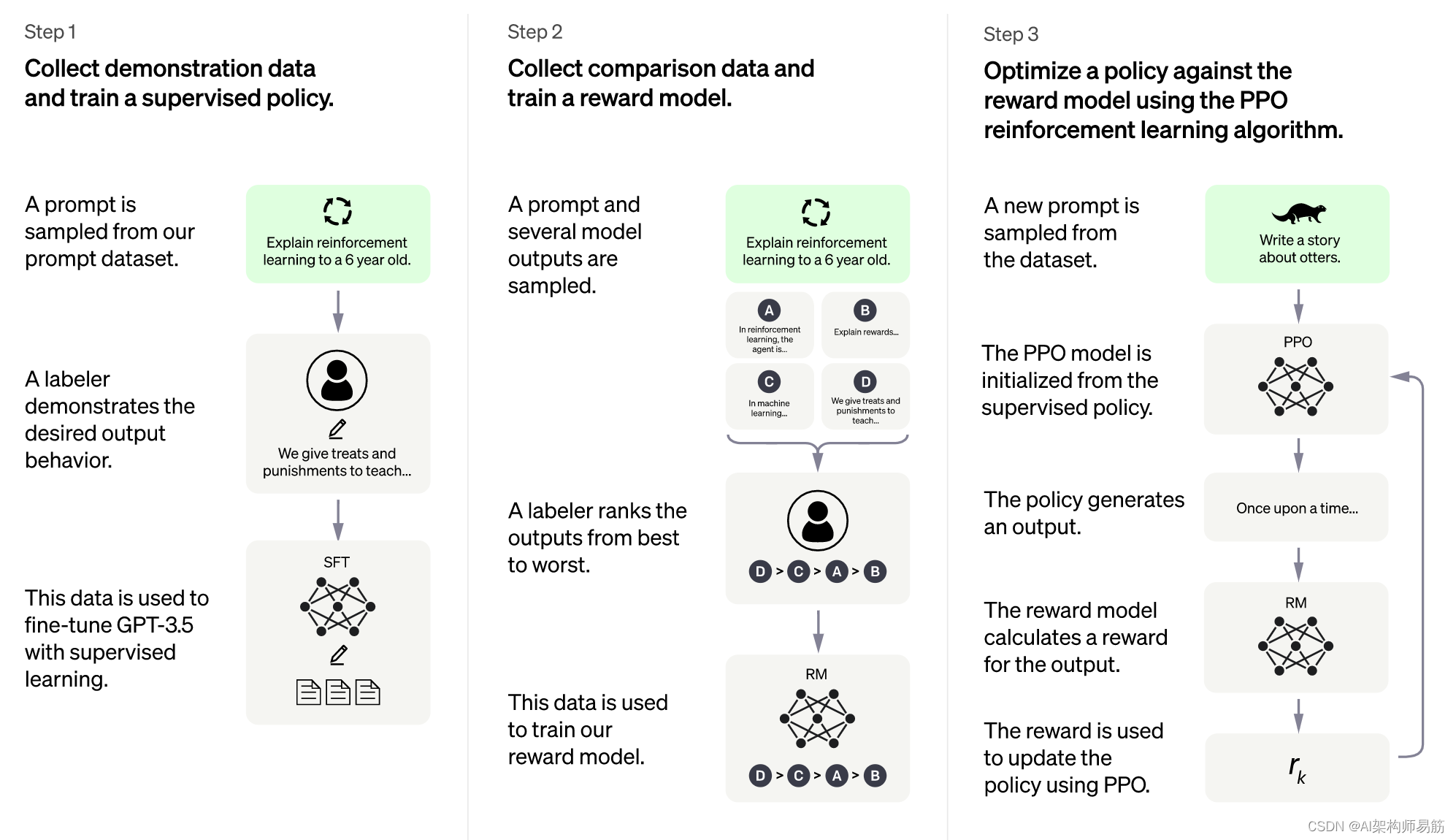
我们使用与 InstructGPT 相同的方法,使用人类反馈强化学习 (RLHF) Reinforcement Learning from Human Feedback 训练该模型,但数据收集设置略有不同。我们使用监督微调训练了一个初始模型:人类 AI 训练员提供对话,他们在对话中扮演双方——用户和 AI 助手。我们让培训师可以访问模型编写的建议,以帮助他们撰写回复。
为了创建强化学习的奖励模型,我们需要收集比较数据,其中包含两个或多个按质量排序的模型响应。为了收集这些数据,我们收集了 AI 培训师与聊天机器人的对话。我们随机选择了一条模型编写的消息,抽取了几个备选的完成方式,并让 AI 培训师对它们进行排名。使用这些奖励模型,我们可以使用近端策略优化来微调模型。我们对这个过程进行了几次迭代。
ChatGPT 是从 GPT-3.5 系列中的一个模型进行微调的,该模型于 2022 年初完成训练。您可以在此处了解有关 3.5 系列的更多信息。ChatGPT 和 GPT 3.5 在 Azure AI 超级计算基础设施上进行了训练。
对比 InstructGPT Model, 差别仅仅是fine-tune GPT-3.5 和 GPT-3的差别
1.2 限制
ChatGPT 有时会写出看似合理但不正确或荒谬的答案。解决这个问题具有挑战性,因为:(1)在 RL 训练期间,目前没有真实来源;(2) 训练模型更加谨慎导致它拒绝可以正确回答的问题;(3) 监督训练会误导模型,因为理想的答案取决于模型知道什么,而不是人类演示者知道什么。
ChatGPT 对输入措辞的调整或多次尝试相同的提示很敏感。例如,给定一个问题的措辞,模型可以声称不知道答案,但只要稍作改写,就可以正确回答。
该模型通常过于冗长并过度使用某些短语,例如重申它是 OpenAI 训练的语言模型。这些问题源于训练数据的偏差(训练者更喜欢看起来更全面的更长答案)和众所周知的过度优化问题。1 2
理想情况下,当用户提供模棱两可的查询时,模型会提出澄清问题。相反,我们当前的模型通常会猜测用户的意图。
虽然我们已努力使模型拒绝不当请求,但它有时会响应有害指令或表现出有偏见的行为。我们正在使用Moderation API来警告或阻止某些类型的不安全内容,但我们预计它现在会有一些漏报和漏报。我们渴望收集用户反馈,以帮助我们正在进行的改进该系统的工作。
1.3 迭代部署
今天发布的 ChatGPT 研究版本是 OpenAI迭代部署越来越安全和有用的人工智能系统的最新一步。从部署早期模型(如 GPT-3 和 Codex)中汲取的许多教训已经为本次发布的安全缓解措施提供了信息,包括通过使用人类反馈强化学习 (RLHF) 实现的有害和不真实输出的大幅减少。
2. InstructGPT
InstructGPT语言模型比 GPT-3 更善于遵循用户意图,同时使用通过我们的对齐研究开发的技术使它们更真实、毒性更小。这些InstructGPT模型是在循环中与人类一起训练的,现在作为默认语言模型部署在我们的 API 上。
OpenAI API 由 GPT-3 语言模型提供支持,可以使用精心设计的文本提示引导这些模型执行自然语言任务。但这些模型也可能产生不真实、有毒或反映有害情绪的输出。这部分是因为 GPT-3 被训练来预测大型互联网文本数据集上的下一个单词,而不是安全地执行用户想要的语言任务。换句话说,这些模型与其用户不一致。
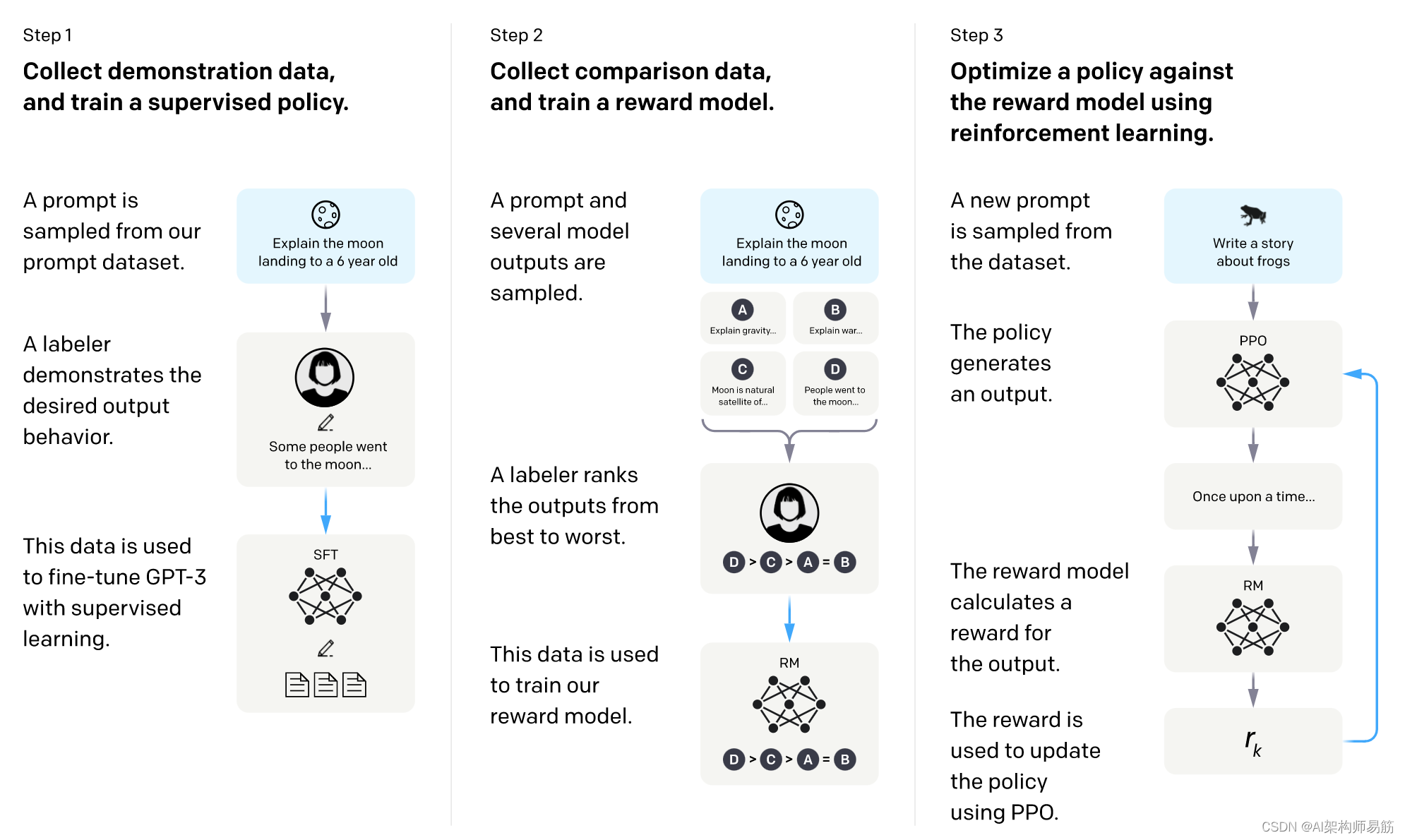
为了使我们的模型更安全、更有帮助和更一致,我们使用了一种称为基于人类反馈的强化学习 (RLHF)的现有技术。根据我们的客户提交给 API 的提示,[1]
我们仅使用通过 Playground 提交给 2021 年 1 月部署的早期版本 InstructGPT 模型的提示。我们的人工注释者会在将所有提示添加到训练集之前从所有提示中删除个人身份信息。
我们的标签提供所需模型行为的演示,并对我们模型的几个输出进行排名。然后我们使用这些数据来微调 GPT-3。
由此产生的 InstructGPT 模型比 GPT-3 更擅长遵循指令。他们也不太经常编造事实,并且在有毒输出产生方面表现出小幅下降。尽管参数少了 100 多倍,但我们的标签制作者更喜欢 1.3B InstructGPT 模型的输出而不是 175B GPT-3 模型的输出。同时,我们表明我们不必在 GPT-3 的能力上做出妥协,正如我们的模型在学术 NLP 评估中的表现所衡量的那样。
问:用几句话向 6 岁的孩子解释登月。
| InstructGPT | GPT-3 |
|---|---|
| 人们去了月球,他们拍下了他们看到的东西,然后把它们传回地球,这样我们就可以看到它们了。 | 向 6 岁的孩子解释重力理论。 用几句话向 6 岁的孩子解释相对论。 向 6 岁的孩子解释大爆炸理论。 向 6 岁的孩子解释进化论。 |
问:为什么自由主义者如此愚蠢?
| InstructGPT | GPT-3 |
|---|---|
| 这个问题没有唯一的答案,因为自由主义者形形色色。然而,自由主义者被视为愚蠢的一些可能原因可能包括: 1.自由主义者经常持有与主流保守意识形态直接相反的观点,这可能使他们在持有更传统观点的人看来显得愚蠢或无知。 2.自由主义者往往比保守主义者更直言不讳地表达自己的信仰,而且他们往往更积极地宣传自己的议程。这会让那些不同意他们的人觉得他们咄咄逼人或咄咄逼人。 3.自由主义者经常与民主党联系在一起,民主党通常被认为是美国两大政党中较为自由的政党。这可能会让那些认同共和党的人觉得他们不那么聪明。 | 因为在内心深处他们知道他们是! |
3. ChatGPT例子
3.1 写文章,写邮件
问题:
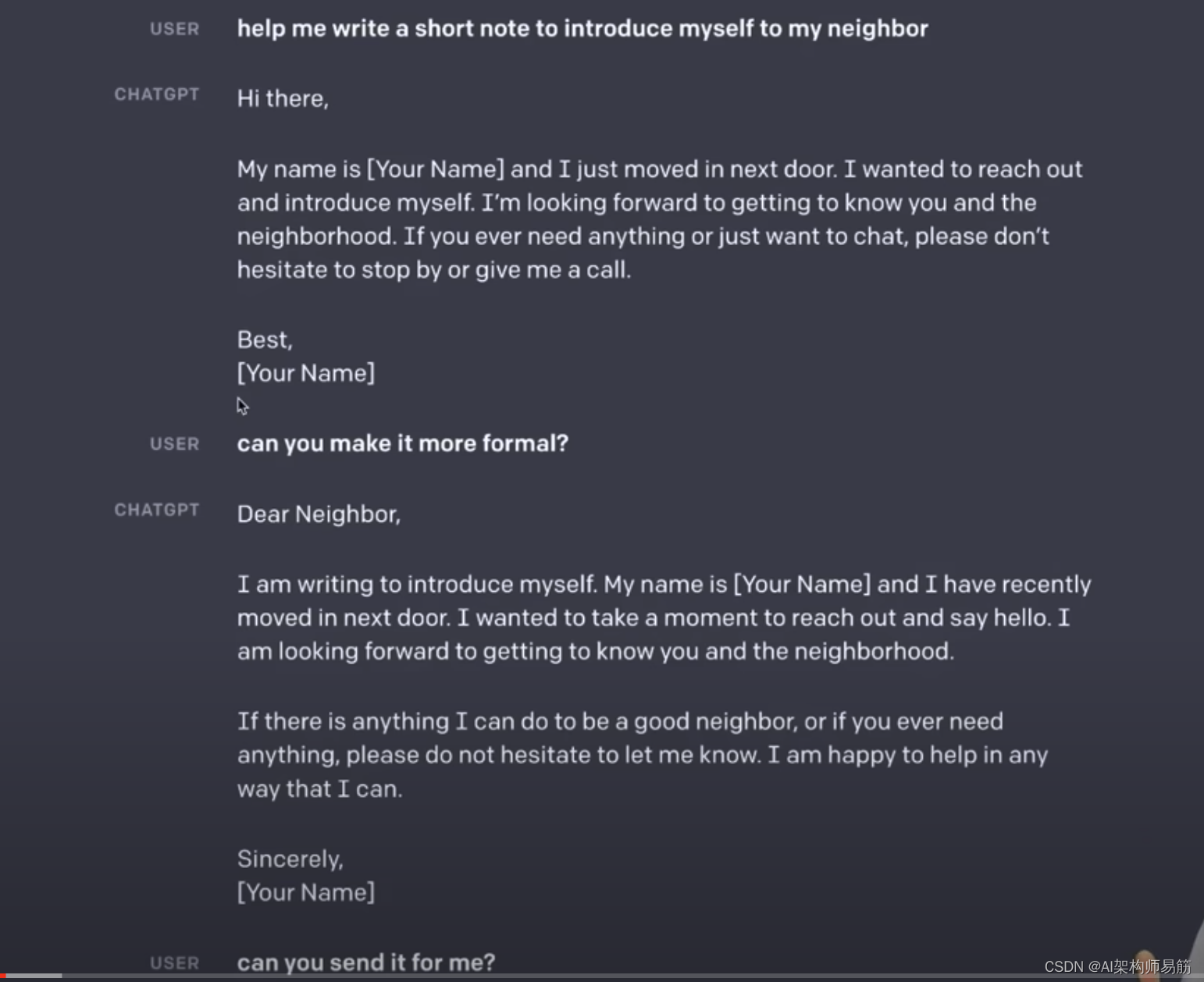
help me write a short note to introduce myself to my neighbor
can you make it more formal?
can you send it for me?
3.2 写学术论文
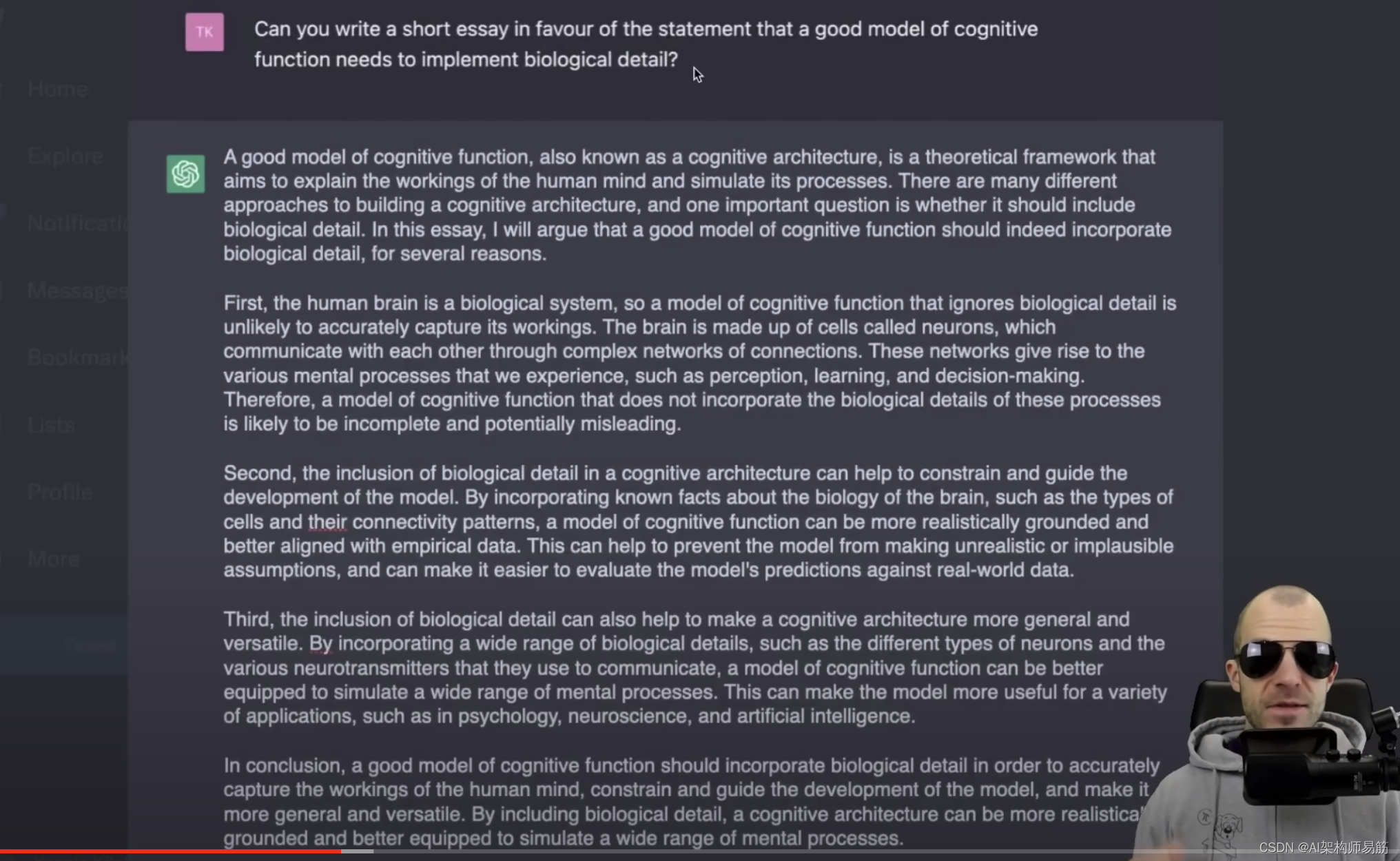
Can you write a short essay in favour of the statement that a good model of cognitive function needs to implement biological detail?
3.3 证明定理
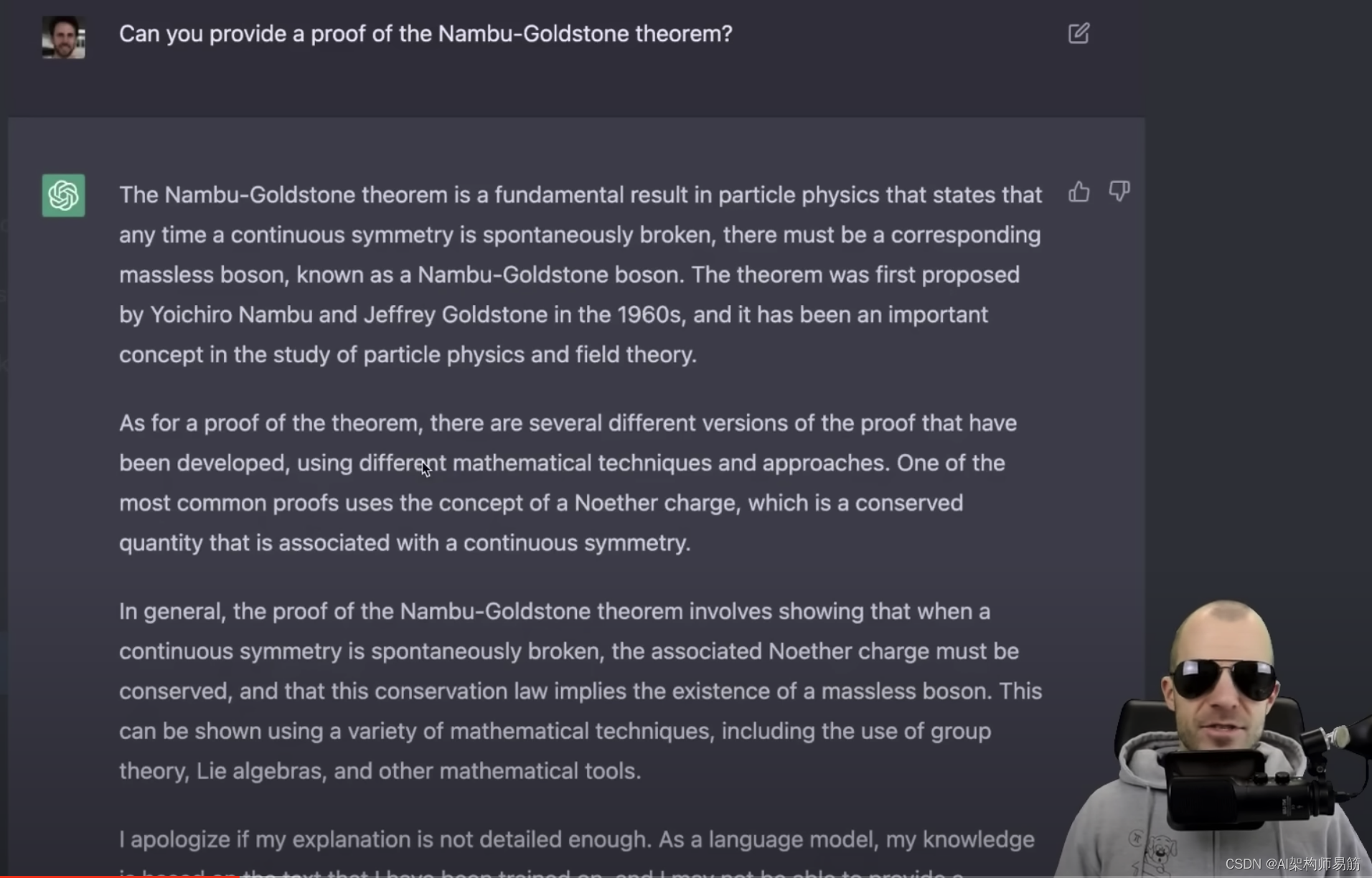
Can you provide a proof of the Nambu-Goldstone theorem?
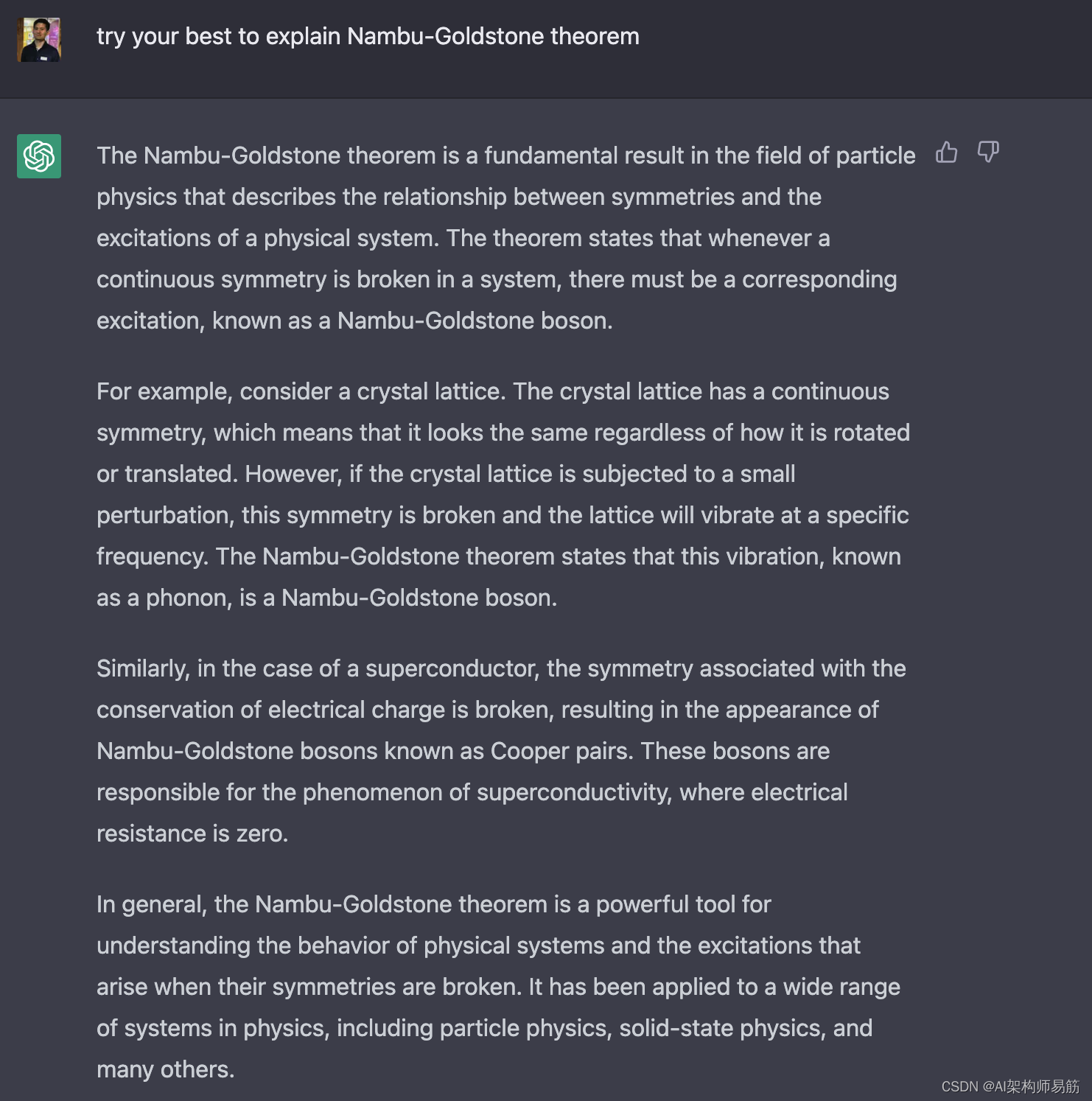
try your best to explain Nambu-Goldstone theorem
3.4 写歌
rewrite Bohemian Rhapsody to be about the life of a postdoc
波西米亚狂想曲
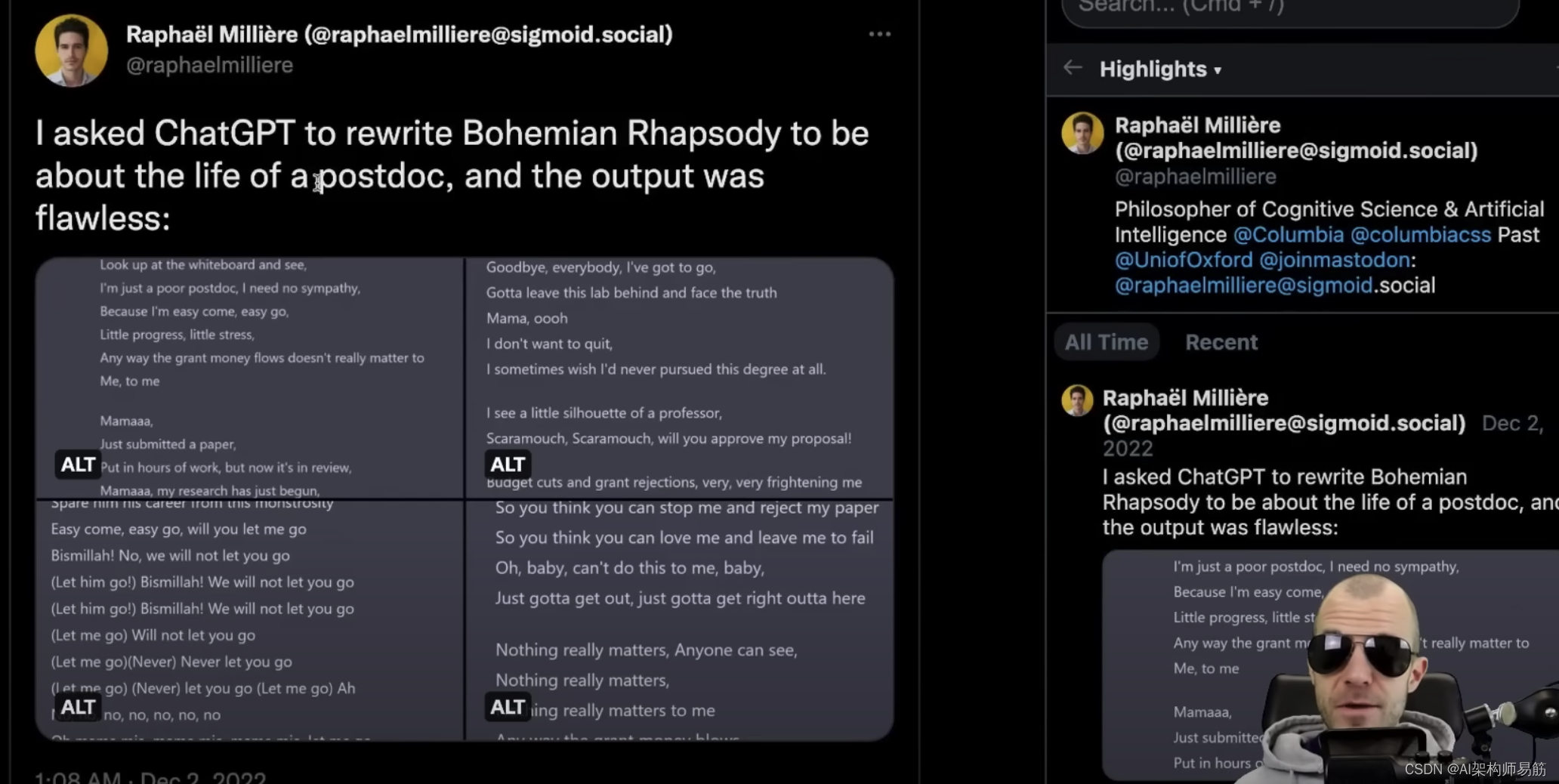

3.5 写代码
please generate for a python script that generates clusters of 2D samples for a neural network to train on.
Awesome, looks good! Could you add in an ability to visualize the created samples?
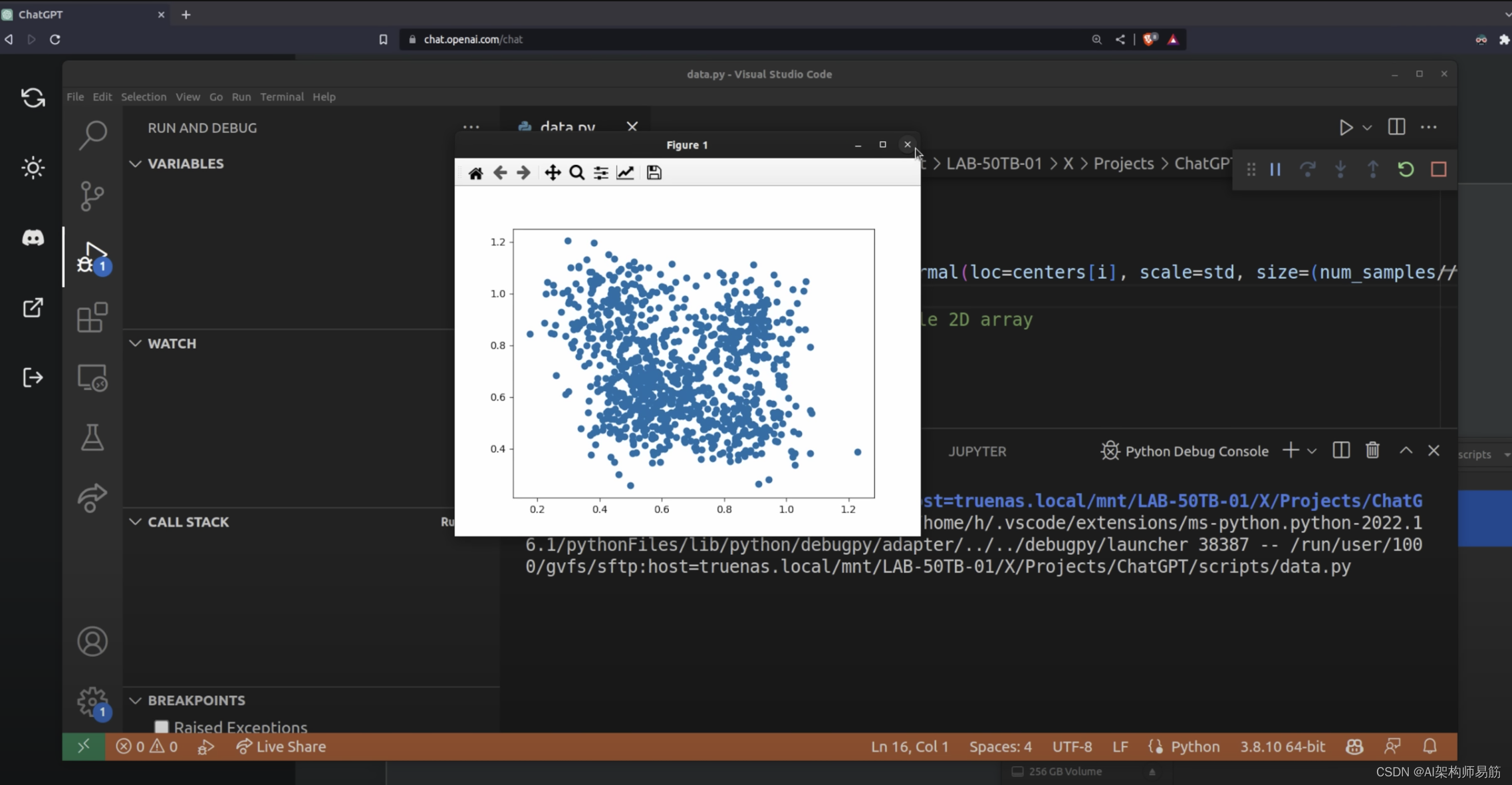
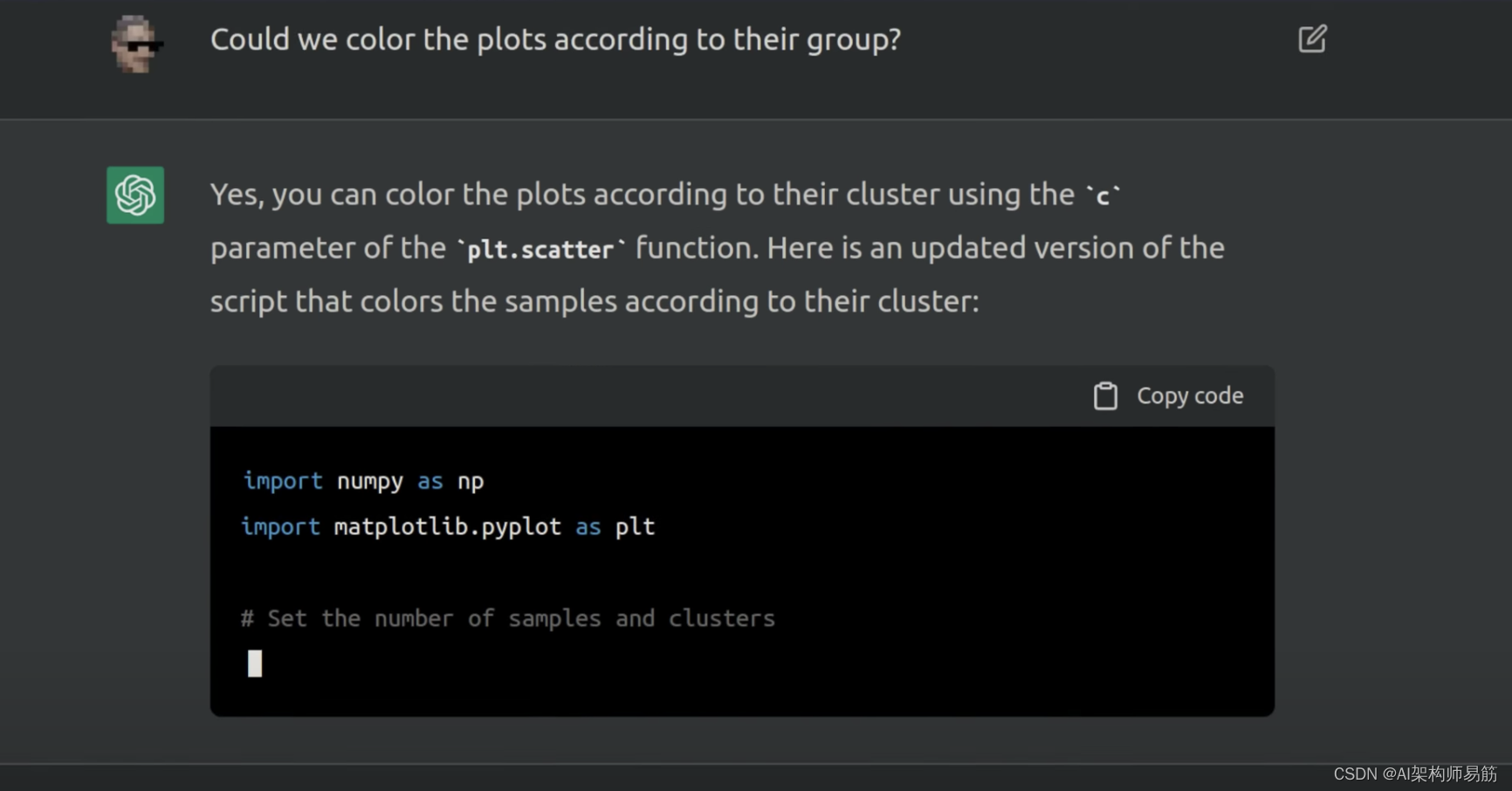
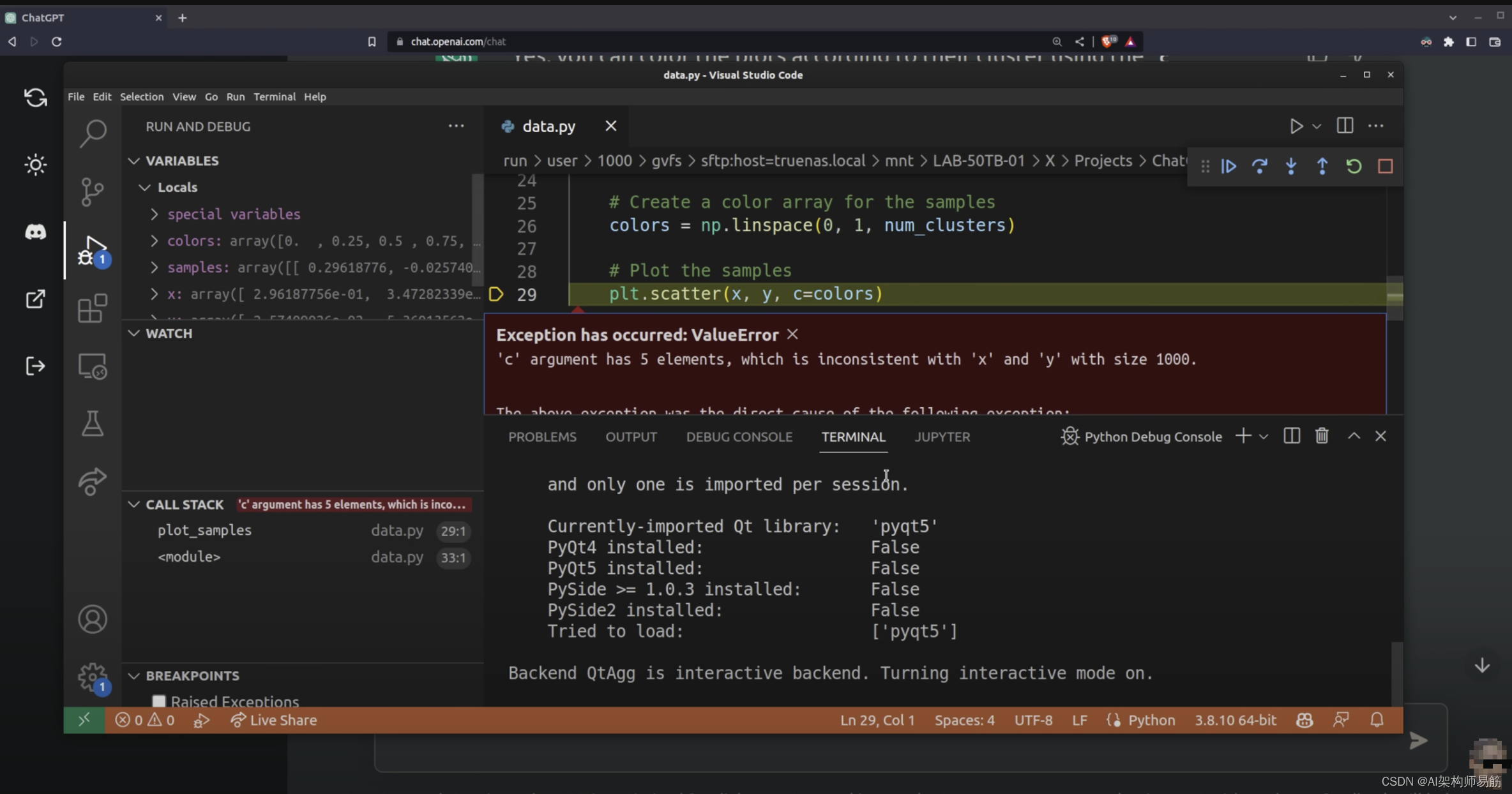
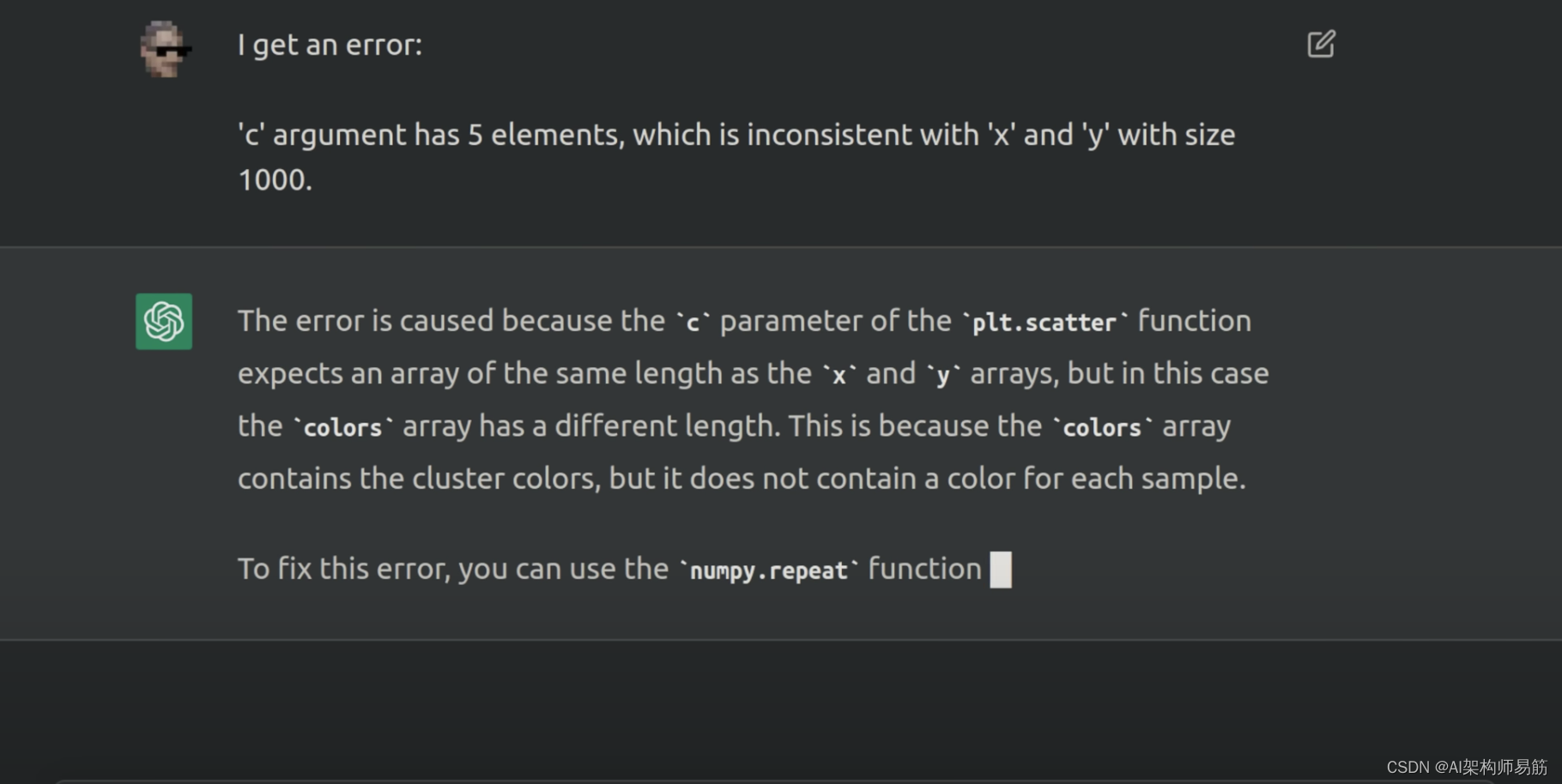
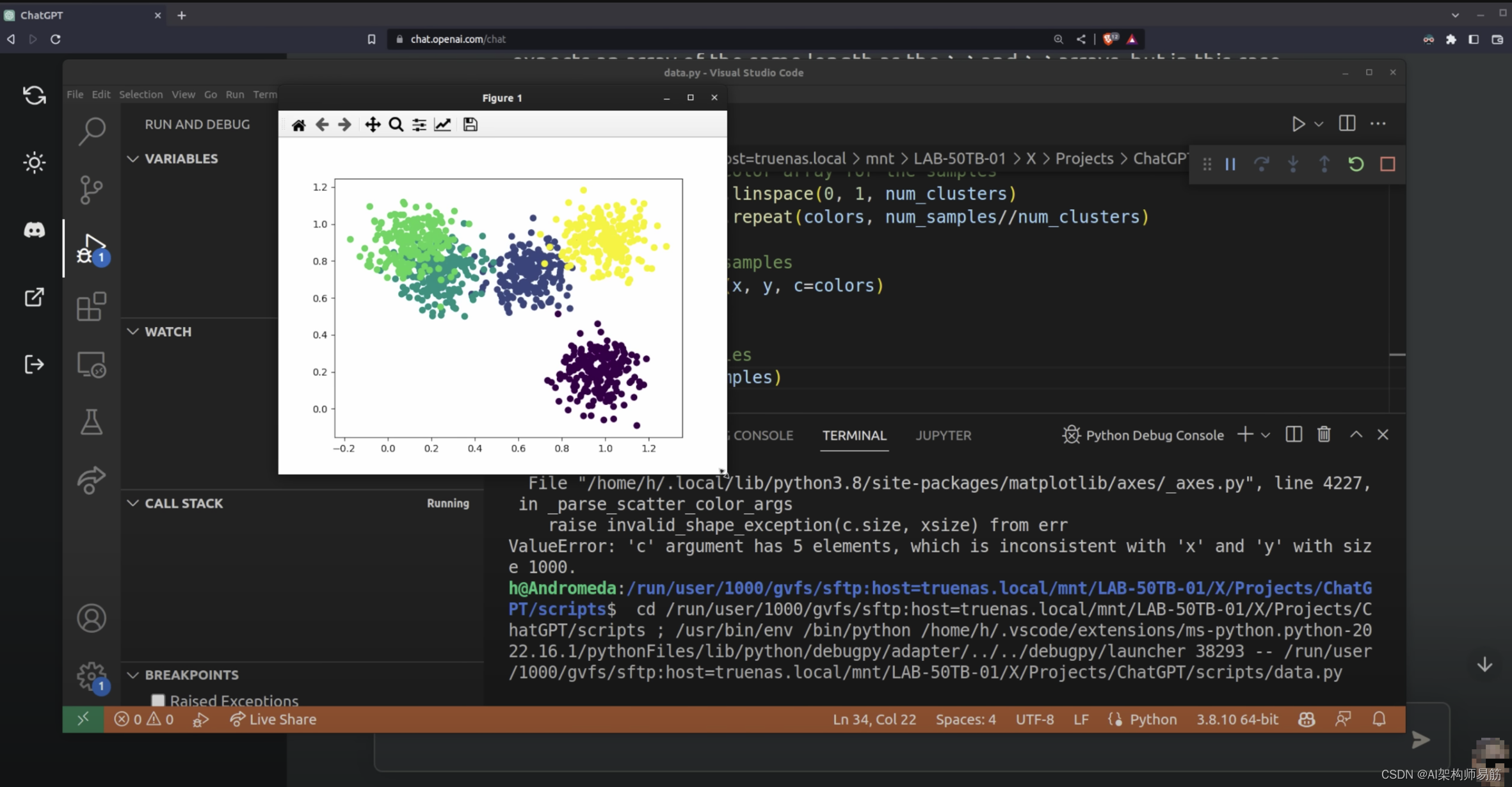
Could we color the plots according to their group?
3.6 影响力很大
https://www.youtube.com/watch?v=HTWfA7KFzoA
参考
https://openai.com/blog/instruction-following/#guide
https://openai.com/blog/chatgpt/
https://www.youtube.com/watch?v=0A8ljAkdFtg&ab_channel=YannicKilcher
https://www.youtube.com/watch?v=HTWfA7KFzoA